基于多层级联融合网络的糖网病检测
2020-08-03唐奇伶刘志梅符玲玲张彗彗夏先富
唐奇伶,刘志梅,符玲玲,张彗彗,夏先富
(中南民族大学 生物医学工程学院,武汉430074)
糖尿病分为两型,在糖尿病达到一定年限后,有一定的发病率最终出现糖尿病视网膜病变.Ⅰ型糖尿病患者发病率近乎达到百分之百,Ⅱ型糖尿病发病率则达到了百分之六十.而糖尿病视网膜病变分为三种,背景型视网膜病变、黄斑型视网膜病变发病和增生型视网膜病变.目前用于筛查糖网病的重要成像方法包括两种,光学相干层析成像技术与眼底的图像可视化.本文主要使用光学相干层析成像技术.
光学相干层析成像技术(Optical Coherence Tomography,OCT)是一种基于低相干光干涉原理[1]新型的医学影像技术.随着光学相干层析成像技术越来越成熟,开始广泛的运用在各个医学领域,尤其是眼科,牙科和皮肤表层组织[2].OCT技术用于拍摄并诊断视网膜的疾病、测量视网膜结构,对虹膜、视网膜、晶状体等结构进行高分辨成像,具有操作简单、无损伤、非接触、高分辨率等优点.通过检测视网膜层的微小变化,判断糖网病、黄斑变质、青光眼等眼部疾病早期的症状,进而得以确诊[3].
几年前,在神经网络技术还未成熟的情况下,K.NARASIMHAN等人[4]提出的‘一种使用支持向量机与贝叶斯分类器从病理图像检测糖网病的自动有效系统’,作者仅使用训练样本与测试样本各50组,获得的AUC的值为0.95,糖网病的检测准确率为0.92.从近几年动辄用上万张图片对大型的神经网络模型进行训练的背景下,这种结果必然是不准确,在实际应用中的意义也不大.如今大多数糖网病检测的研究都是基于眼底图像数据,但要做到对疾病预防就必须在疾病发病初期检查出来;早诊断,早治疗,才有较好的治疗效果.而眼底图像在发病初期的病灶特征没有那么的明显,而OCT图像特征较为明显,特别是在发病早期,技术特性决定了其较高的灵敏度,医生容易做出判断.
近几年,已经能在一些期刊与会议上看到通过使用算法检测OCT图像而达到辅助诊断糖网病为目的的文章.OSCAR和SEBASTIAN等人[5]提出了一种用卷积神经网络对OCT的图像做自动分类方法.AWAIS等人[6]使用了VGG16结构对OCT图像的采样,然后将特征图送入到KNN与决策树算法中得出分类结果,其中DME图像的分类正确率达到93%.KARRI等人[7]使用了迁移学习的方法,采用已经训练过的深度卷积神经网络模型 Google Net基于Image Net数据库,微调了部分参数,正常、AMD、DME三种类型的OCT图像被模型正常区别,并且在实验后,得出一定的结果,表明了该算法比较优秀的分类表现,三类图像的灵敏度分别为99%、89%和 86%.这一系列的实验结果证明了神经网络对OCT图像分类的可行性.
本文提出的基于多层级联融合网络的糖网病检测方法,采用了OCT的数据集,用于训练神经网络模型,可以在早期检测糖网病的严重程度.通过一些网络上的改进来适应医学图像的特殊性,如采用多层级联融合的方法,对数据集进行多层采样后,融合每层的采样结果.并使用了空间金字塔结构对多层的特征图做归一化,提高了模型对数据的适应性,解决采样过程中,特征图大小不一致的问题,提高了算法的准确性.
1 多层级联融合网络的算法模型
1.1 多尺度特征学习的边缘分割检测网络
与神经网络有关的研究很早就开始了,今天,深度学习已形成为一个多学科交叉的庞大研究领域[8].而神经网络目前很重要的一个类别是监督学习.不久前,XIE[9]提出了一种基于FCNN的深度监督网络的边缘检测算法(Holistically-Nested Edge Detection,HED),该网络输入整个的图片,输出图片对应的是边缘分割结果.它的创新点有两个重要的方面:一方面是图片的整体训练和预测,另一方面是多尺度的特征提取并学习.Holistically-nested方法将几种使用了不同尺度的深度学习结构进行了对比说明.分析多尺度学习的两个方面:网络内部形成多尺度的原因是由于降采样得到特征图大小在不断变小,外部网络形成多尺度的原因是输入图像的尺寸不一致.五种情况下的多尺度深度学习模型,如图1所示.
由图1可看出:(a)网络,输入的图像进入多个网络,每个网络的层数和参数不同,得到的特征图大小不同,反应网络多尺度结构,网络的最后一层利用特定的卷积核将所有输出的结果合并,得到最后的输出结果.(b)网络,输入图像后提取每个卷积层生成的特征图融合一起后再通过一个卷积层得到输出结果.(a)和(b)差异在于(a)通过不同的网络的不同卷积层,(b)是在同一网络的不同卷积层提取特征图融合,但是他们都是使用一个loss函数进行回归训练.(c)网络是通过外部使尺度不同,即输入图像的大小不一致,但是通过相同的卷积核,得到的输出特征图也不一致.(d)网络是由(a)演化过来,相同的图像通过不同的独立网络,每个网络的深度和输出损失函数都不一致,不同的网络预测结果也不一致.将最后的结果综合分析,能得出更好结论.唯一的缺陷是需要比其它模型更多的数据量.(e)网络是HED综合前面的方法提出的,同样的输入图像大小,经过不同的卷积层,每一个卷积层的生成的特征图都不一致,保存特征图作为第一个结果,将后面的特征图做反卷积后,与之前的特征图相融合,融合后再通过一个卷积核就能得到第二个输出,结合了的两个输出结果就是模型最终的结果.
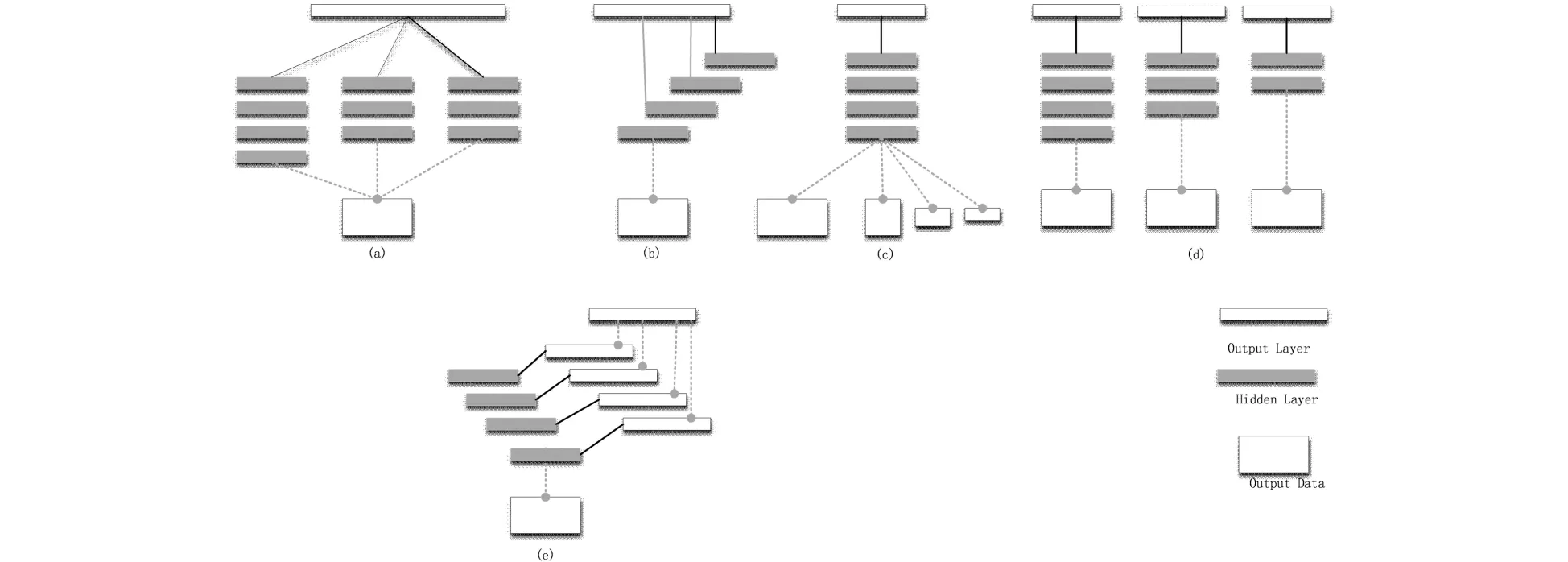
图1 不同多尺度深度学习架构配置说明
HED论文中利用一个“权重混合层”解决每侧输出结果混合的问题,让整个模型学习混合权重.混合权重层的损失函数定义如公式 (1)所示:
(1)
L(I,G,W,w)=Lside(I,G,W,w)+Lfuse(I,G,W,w).
(2)
1.2 空间金字塔池化结构
在考虑使用HED网络的核心思想时,出现了一个问题,分割和分类网络存在一些差异.上面提到的方法是对最后的特征图做一层层的反卷积,并将反卷积结果与第一层融合来产生分割效果,每一层池化前得到的特征图是大小不一致的,为了解决这个问题,以下提出了一个解决方案,即利用空间金字塔池化结构去解决特征图大小不一致的问题.
空间金字塔池化结构是HE Kaiming提出的一个用于解决图片输入大小不一致的方法, 如图2所示.当图片强行归一化的时候,会扭曲图片,从而丢失图片携带的信息.空间金字塔池化结构原理简单,即将图片分块,每个块提取特征向量,这样对任意尺寸的特征图,都可以从中提取固定大小的特征向量,这样就兼容了多尺度的特征,最后将这些多尺度特征拼接成一个固定维度特征,与全连接层相连.

图2 空间金字塔池化结构示意图
1.3 多层级联融合网络的整体结构
1.3.1 基于HED和VGG模型的扩展结构
VGG模型在自然图像中使用非常广泛,也得到非常好的效果,于是参考HED网络建立一个基于VGG模型的多层级联融合网络(HED-VGG-net,HV-net).应用该网络的原因在于HED网络融合能获得非常好的分割效果,证明了融合多个卷积层得到的特征图,提高了采样的效果.本文的网络构建方式是在每个池化层前,引出一个分支结构,即引出每一层卷积完后得到的特征图,再将每一层的特征图经过空间金字塔池化结构进行归一化,生成五个多维的向量,最后对这五个多维的向量使用融合函数融合.由于两个全连接层的参数量过大,硬件设备的内存不允许设置两个维度过高的全连接层,所以在建立模型之前,对融合后的值进行了简单的计算,最后决定在原本的VGG模型的基础上将两个全连接层删减为一个,维度设置为1024最优,也有对维度设置为512及更小的值进行训练,实验发现模型不稳定,偶尔出现不收敛的情况.详细结构如图3所示.

图3 HED-VGG-net结构
1.3.2 基于HED和KA-net模型的扩展结构
参考HED网络也建立一个了基于KA-net模型的多层级联融合网络(HED-KA-net, HK-net).也对每个池化层前的卷积层做了一个分支结构出来,用空间金字塔池化对特征图归一化,生成多维的向量再融合.两个模型的大致结构一致,区别在于输入图像大小不一致,KA-net每个分支结构输出的特征图比VGG模型的特征图大,所以在最后融合完成之后进入全连接层之前的参数量比VGG模型多 ,因此在最后两个全连接层,本文沿用了VGG的全连接层结构.详细结构如图4所示.

图4 HED-KA-net结构
2 实验结果与分析
2.1 光学相关断层扫描图像数据集描述
研究的数据集来自Kaggle比赛,这是一组质量非常高的数据集,共有83484张图像,OCT图像的数据集的数据量比较充足,分为四种类别,分别为络膜新生血管(CNV)、糖尿病性视网膜黄斑水肿(DME)、与年龄相关的黄斑变异(AMD)和正常人(NORMAL).每一类的数据量比较均衡,不存在需要做数据扩充的问题,非常适合用于神经网络的训练.这四类图像的数据分布,如表1所示.

表1 OCT图像数据分布
下面是从数据集中随机抽取的四张图像作为实例,如图5所示.从示例图片中(a)、(b)、(c)中都是早期可以看到三种病变,图像上有明显的的病变特征.

(a)DME (b) CNV (c) DRUSEN (d) NORMAL
2.2 性能度量标准
评估模型的泛化误差是需要通过数据集的实验.通过筛选,选定一个测试集,该测试集一方面要与训练集保持互斥的关系,另一方面也需要从真实样本中独立采样.本文使用了两种测试方法,包括“留出法”和“交叉验证法”.留出法就是将数据集分为两个集合,一个训练集和一个测试集,同时两个集合保持互斥关系.为防止数据不均衡产生的偏差而影响测试结果,使用的训练集和测试集对应的每个类别的数据分布保持一致.因为训练集包含大多数样本,测试集样本较少,也根据别的研究人员的方法用4/5的样本训练,剩余样本用于测试.相反交叉验证法适用于数据量不充足的情况,具体做法是先对数据集D进行划分,划分后存在k个大小的互斥子集,将每个子集设为d,这些子集都保持原本数据集分布的一致性.然后取k-1个子集,将这些自己合并用来训练,余下的自己合并用来测试.即最终训练集和测试集加起来一共有k组,统计这k个集合测试结果的均值.
分类模型中常用的性能度量,如精度,非常适用于多分类模型 ,精度的定义为分类正确的样本数占总样本数的比例.如下公式(3)所示:
(3)
精确度是常用的标准,但是有些任务需求并不能满足,所以本文还会使用其他的性能度量.如二分类问题,可将样例根据其真实类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative)四种情形,令TP、FP、TN、FN分别表示其对应的样例,分类结果的“混淆矩阵”如表2所示.

表2 分类结果混淆矩阵
在医学图像中,灵敏度(sensitivity)表示实际患病(阳性)而被正确诊断为患病(阳性)的比例.如下公式(4)所示:
(4)
2.3 实验分析
2.3.1 学习率参数对模型的影响
研究的实验硬件环境为NVIDIA Quadro M5000,Intel Xeon CPU E5-2650 V4,软件环境为Windows 10专业版,Anaconda 3.5,Cudnn 8.0,Tesnsorflow 1.6,Keras 2.1.5.
在训练网络时,考虑到不同的学习率对模型收敛存在一定的影响,我们不断实验寻找了最优的学习率.本节用OCT数据集对HED-VGG-net和HED-KA-net做训练,迭代次数为20次,batchsize为30.调整四组初始学习率,分别为0.01、0.05、0.1、0.5.模型loss值随着迭代次数收敛的情况如图6与图7所示.

图6 HED-VGG-net收敛曲线

图7 HED-KA-net收敛曲线
2.3.2 网络模型性能分析
在自然图像的处理中,大多数经典模型都有很好的效果,实际上在医学图像上效果并不是很理想.在查阅文献时,有一种利用VGG模型使用迁移学习的方法,主要做法是将中间部分层固定住,仅训练尾部的全连接层.从文献的结果来看,这种方法也得到了很好的结果. 但是单个模型的准确率不能体现效果,所以希望通过多种经典网络模型和本文构建的模型进行对比实验,验证模型效果的优良性.使用OCT数据集对模型进行训练,训练完成后,生成四组对比折线图.epoch为50,学习速率初始值为0.01.横坐标为迭代次数,纵坐标为准确率,验证方法为交叉验证.由于四组模型收敛速度不一样,这里取了每五组迭代的准确率,一共30次,用来生成准确率随迭代次数变化的折线图.四组模型的准确率变化曲线如图8所示.

图8 网络模型分类准确率变化曲线图
由图8我们可以看见模型在迭代20个epoch之后,准确率趋于稳定,所以这里统计了20至50个epoch中间四个模型的准确率,结果如表3所示.几个模型准确率存在一定的波动是交叉验证会出现的正常情况. 本文将每个模型在迭代时准确率的最大值统计出来,其直方图如图9所示.可以看见HED-VGG-net准确率在最高时表现好于HED-KA-net,但HED-KA-net准确率变化趋势更小,更稳定.

表3 网络模型在OCT数据集上的分类结果(平均值±标准差)

图9 网络模型在OCT数据集上准确率对比(最大值)
基于上面的交叉验证结果,通过更具体的性能对模型进行分析.这里又使用了留出法的验证方法,测试集共有968张图像用于验证HED-VGG-net和HED-KA-net的性能,每一类为242张,表4和表5是使用多层级联网络对968张图像做预测的混淆矩阵结果.实验数据为OCT图像数据集,batch size为30,epoch为50,学习速率初始值为0.01.

表4 HED-VGG-net混淆矩阵

表5 HED-KA-net混淆矩阵

图10 模型对应灵敏度
从灵敏度角度上,DME图像的灵敏度较高,其它两类的灵敏度都低于DME图像。从测试集随机抽取部分样本,将三类病变与正常类的样本作对比.
在测试集中,随机抽取DME、NORMAL、DRUSEN和CNV四个类别中各16张图像,如图11所示.DME、CNV和NORMAL的特征差异大,但DRUSEN和NORMAL的特征差异较小,这也是这几组数据的出现灵敏度差异的原因之一.

图11 四类图像抽样对比
从另外两个类别观察图像,同一类的图像共有特征明显机器更容易区分,如DME类中间有类似于空腔的结构、CNV类有像多次扭曲的层结构.从神经网络采样的角度上看,这种图像上明显的特征会是分类效果更好.
2.3.3 与其他算法的比较
基于Kaggle数据库,表6显示了文献中对OCT图像分类结果的比较.

表6 不同分类算法在Kaggle数据库上的结果比较
SAMRA等人[10]利用了相干张量对糖尿病性黄斑水肿(DME)进行分类,VENHUIZEN等人[11]使用基于词袋模型的方法来分类OCT图像,OSCAR等人[5]出了一种基于CNN的OCT-NET模型,用于OCT体积的自动分类.RONG[14]等人提出了一种基于CNN自动分类视网膜OCT图像的替代辅助分类方法.结果表明基于神经网络是一种非常高效的分类模型.本实验最终分类结果,证明其效果优于同类型的分类算法.
3 结语
糖网病检测是医学图像分析中非常具有实际应用意义的一个问题,针对这个问题,我们提出了基于经典网络模型的改进模型.使用多组学习率训练模型,测试几组学习率对模型收敛的影响.通过将构建的两个模型与经典网络的分类结果进行对比,体现了多层级联融合分类模型的效果在医学图像检测中优于经典网络模型.最后,对两个模型用混淆矩阵和灵敏度来做评估,分析了出现灵敏度差异的原因.综上结果发现,我们提出的基于多层级联融合的分类模型是一种高效、合理、性能好的算法. 作者将继续尝试多层级联融合网络结合其它算法框架的更有效信息,进一步提升性能,更好的检测糖网病的病理图像.
