基于卷积神经网络的粗粒度数据分布式算法
2020-07-18骆焦煌
骆 焦 煌
(闽南理工学院 信息管理学院, 福建 泉州 362000)
以文本信息为主体的网络信息主要存储于各级数据库中, 基于数据表的大小、 类别和用途归类, 将数据库中的信息分为粗粒度信息和细粒度信息[1]. 粗粒度表示类别级, 即仅考虑对象的类别, 不考虑对象的某个特定实例. 粗粒度文本信息在本文中被称为粗粒度数据, 是一种不具特定实例的信息或数据. 在现实数据库系统中粗粒度信息较难获得, 而在很多场景下粗粒度信息在综合信息评价方面用途较广, 因此对粗粒度信息的分类、 评价与应用, 已成为当前大数据挖掘与应用领域的研究热点之一. 数据库中的粗粒度信息与细粒度信息具有紧密的关联性, 粗粒度数据的挖掘还要基于不同粒度数据库表之间的权重和关联关系.
关于粗粒度文本数据挖掘、 分类及计算的传统方法主要包括基于决策树与基于不同粒度数据之间关联度的计算方法, 存在召回率较低和泛化误差较高等问题. 近年来, 随着人工智能技术和机器学习算法的发展, 人工神经网络被应用于粗粒度数据的分布式计算中, 人工神经网络方法具有强大的泛化能力与学习能力, 能集中处理和训练海量不确定性的大数据集. 随着文本数据规模的不断扩大及数据结构差异化程度的提高, 已有数据库中通常包含结构数据、 非结构数据和半结构混合数据, 且数据库中各种信息的均衡度不同, 给文本数据的分类挖掘带来很大难度. 以人工神经网络为代表的机器学习方法在计算效率、 计算复杂度等方面都需提高和改善. 因此, 本文在原有一维卷积粗粒度数据计算模式基础上, 提出一种基于卷积神经网络的粗粒度数据分布式算法, 利用卷积神经网络强大的后馈性能和泛化性能[2], 更精确地提取网络文本中的粗粒度数据信息, 提高系统的分布式运算能力.
1 卷积神经网络模型构建
在数据库表的分析与处理, 尤其是文本信息的拆分与使用中, 为提高数据类的复用性和计算机语言的功能性, 常将功能更复杂的粗粒度信息拆分成若干细粒度信息. 在数据库设计中, 为减少文本数据库表的复杂度, 常会减少数据库表之间的连接关系, 进而获取数据库文本数据的粗粒度信息. 与传统神经网络模型相比, 卷积神经网络的输入数据要经过卷积层、 池化层和全连接层, 再经过神经元的模拟计算输出[3], 卷积神经网络模型的框架结构如图1所示.
在自然语言处理中, 由于文本文件无法直接作为输入数据使用, 因此在处理文本文件时先将自然语言转换为数值型数据. 卷积层是模型的中心结构, 输入经过处理和转换的数据在卷积层要经过叠加和加权处理, 完成特征的归类和提取[4]. 卷积层包括多个不同大小的滤波器[5], 输入经过卷积计算复杂度能得到控制, 也简化了神经元系统的运算流程. 池化层主要负责对输入数据进行多维度采样[6], 以增强网络泛化能力, 经池化后的数据进入神经网络模型全连接, 并完成对文本数据的分类或聚类. 卷积神经网络模型在结构设计上优于传统的神经网络模型, 因为加入了卷积计算和数据的池化环节, 故在数据粒度划分方面更有效. 卷积神经网络提升了神经元的局部连接性能[7], 因此不受传统人工神经网络模型最多神经元数量容纳的限制, 提高了神经网络的容纳深度. 网络局部连接性能的提升主要得益于网络结构汇总卷积层的引入, 若在卷积神经网络结构中的第n层含有5个基础神经元, 则在第(n+1)和(n-1)层的局部连接方式如图2所示. 由图2可见, 当增加网络层数时, 神经元层相对于输入层中感受野的值也会增大, 这种结构具有更强大的过滤性能, 减少网络参数设定的复杂度. 随着网络层数的增加, 神经元的泛化能力会拓展到全局, 并实现权值的共享与分配. 与传统人工神经网络方式相比, 卷积神经网络的训练效率更高[8], 在对粗粒度文本信息处理中, 特征提取的准确率也更有优势.

图1 卷积神经网络模型结构
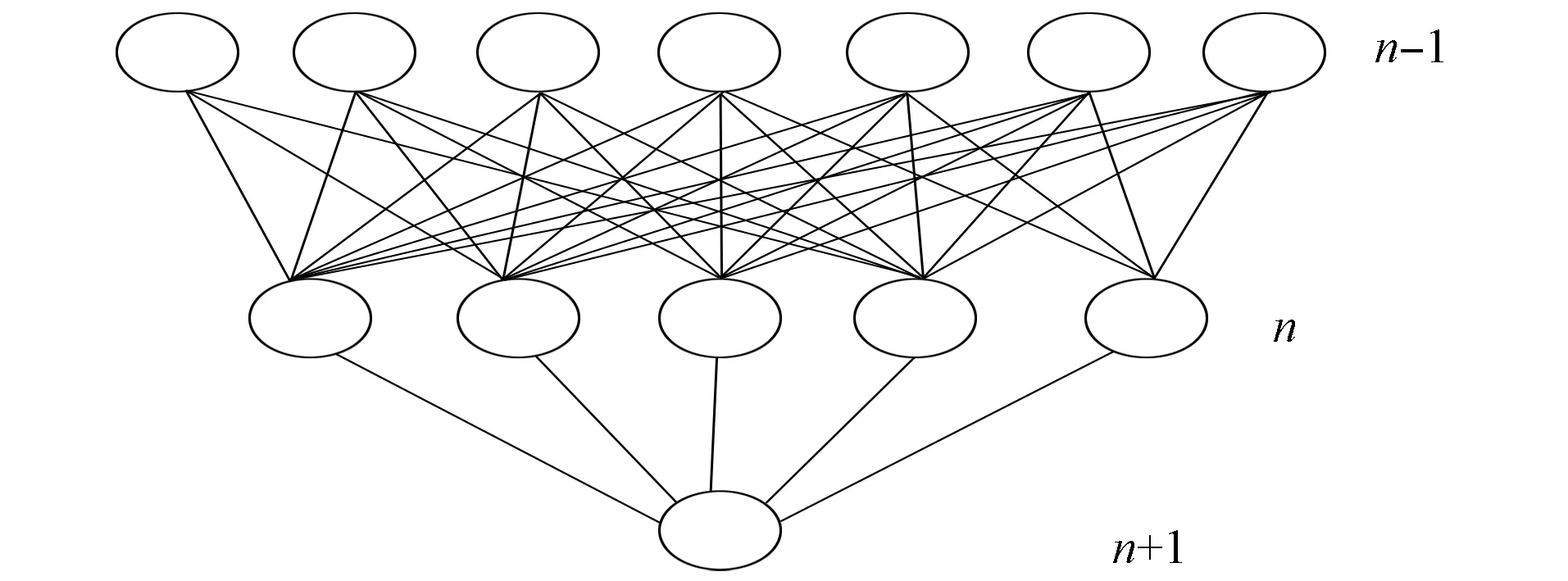
图2 神经元局部连接示意图
2 基于卷积神经网络模型的粗粒度数据训练与池化
本文用于粗粒度数据计算的卷积神经网络模型包括卷积层、 池化层、 连接层和激活层, 其中卷积层是最关键部分, 大量分布在底层网络中的卷积核构成了卷积层, 该层的功能是提取粗粒度集的文本数据特征, 更适用于文本数据特征的提取与存储, 相对于传统神经网络模型在分布式运算中的处理能力更强.
算法描述如下:
步骤1) 初始化各隐藏层和输出层的Weight,bias值为随机值;
步骤2) for iter from 1 to Max;
步骤3) forj=1 tom;
步骤4) 将Convolutional Neural Network输入a1设置为xi对应的张量;
步骤5) fork=2 toL-1;
步骤6) 如果当前层是全连接层, 则aj,k=σ(wkai,k-1+bl);
步骤7) 如果当前是卷积层, 则ai,k=σ(wk*ai,k-1+bl);
步骤8) 如果当前层是池化层, 则ai,k=pool(ai,k-1);
步骤9) 对于输出层ai,k=softmax(zi,k);
步骤10) 通过损失函数计算输出δi,k;
步骤11) fork=L-1 to 2;
步骤12) 如果当前层是全连接层, 则δi,k=(wk+1)Tδi,k+1⊙σ′(zi,k);
步骤13) 如果当前层是卷积层, 则δi,k=δi,k+1*rot180(wk+1)T⊙σ′(zi,k);
步骤14) 如果当前层是池化层, 则δi,k=upsample(δi,k+1)⊙σ′(zi,k);
步骤15) fork=2 toL;
步骤16) 更新当前全连接层或卷积层;
步骤17) 如果所有更新后的Weight和bias值都小于停止迭代阈值ε, 则跳出迭代循环.

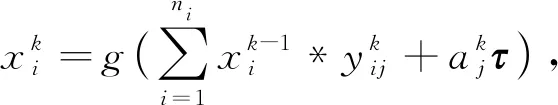
(1)
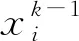
g(x)=(1+ex)-1,
(2)
而非Sigmoid型函数的变换区间为[-1,1], 其值域区间定义为
g(x)=tanh(x)=(1-e-2x)/(1+e-2x).
(3)
由于非Sigmoid型函数的值域范围更广, 因此应用范围也更广, 在模型梯度优化和调整过程中, 非Sigmoid型函数激活卷积层的神经元细胞, 并调整网络权值, 直至模型梯度函数中数据扩散现象消除. 粗粒度文本数据在经过卷积函数处理后, 提高了特征分布的均匀度, 有利于数据的分类、 聚类和特征输出, 同时也减轻了数据库过度细分带来的运算压力.
卷积处理后的文本数据维度仍较高, 池化层主要负责对高维粗粒度数据的降维处理和数据采样, 并提取出粗粒度文本数据的固有特征. 池化采样包括最大池化和平均池化两个过程, 按照一定的顺序和规则池化窗在数据间移动, 并输出池化特征. 传统最大池化和平均池化过程效率较低, 过程冗余, 因此本文模型中将两种池化方法相结合, 采用一种混合池化方法处理卷积激活后的文本数据:

(4)
其中: 参数λ为(0,1)内的随机变量; |Mij|为池化池中的全部数据个数. 卷积与池化参数列于表1.
给定一个训练集A={(xi,yj)|i,j=1,2,…,n,yj∈{1,2,…,k}}, 其中yj为文本数据xi所对应的函数值, 在粗粒度数据计算中需先确定损失函数. 采用随机梯度算法以保证不影响模型的收敛速度[11], 每次迭代中仅保证一小部分样本数据参与, 以获得更快的模型收敛速度. 为保证评估模型的可靠性, 将全部样本数据平均分成若干小组计算均值, 并优化参数, 确保粗粒度数据分布式计算的效率和准确率.

表1 卷积与池化参数
3 参数优化与粗粒度数据的分布式运算
用粒度梯度下降法求解模型的最小损失函数, 并持续更新权值, 在参数更新中为保证损失函数迭代过程的稳定, 采用如下参数优化与更新策略:
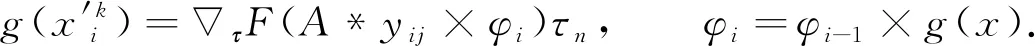
(5)
卷积网络模型的训练包括前馈操作和反向操作两个过程[8], 前馈操作从卷积层开始依次传递到池化层、 神经网络层, 非Sigmoid型函数的工作模式可描述为
g(x)ypre=gn[gn-1ωn(gn-2ωn-1+c1)+…+cn],
(6)


(7)
训练后获得的梯度函数为

(8)

图3 基于卷积神经网络分布式运算的实现过程
经过多次迭代确定阈值范围后满足粗粒度数据模态处理的要求, 还可保证权值之和为1, 方便后续模型的训练与测试. 卷积神经网络模型下的分布式计算方法以模型并行和数据并行两种方法为主, 并实现了两种分布式计算方法的融合. 在模型运行中卷积神经网络包含的各种神经元, 将粗粒度数据均匀划分到各节点, 各节点协调工作, 共同完成训练任务. 分布式运算的处理方式避免了过多的网络开销, 在粗粒度数据并行处理过程中, 转换后的输入数据被分成若干小型的数据块[13], 再将数据块分发到Hadoop网络集群中实现对初始数据的并行化处理. 卷积和池化处理后的文本数据维度降低, 提高了训练精度. 在Hadoop网络结构模式下, 并行的数据结构实现模式如图3所示.
Hadoop网络具有强大的并行计算能力, 借助Hadoop网络结构, 卷积神经网络模型将卷积和池化后的数据分成了m个数据块, 并将处理后的数据传递到神经网络节点. 在相同条件下, 每个独立的网络节点单独训练网络数据, 但这种模式效率较低, 卷积神经网络模型将局部神经元连接成一体, 形成一个链状的网络结构, 并赋予结构不同的权重, 与传统神经网络模型相比效率更高. 同时, 交叉链状结构与Hadoop网络结构的兼容性更好, 也可更好地发挥Map函数的分类和聚类功能. 当训练完成后, Reduce函数重新将分散加工的节点数据聚合, 并重新计算权重值, 直到迭代后满足设定的阈值. 卷积神经网络在传统人工神经网络模型中增加了卷积层和池化层[14], 不仅提高了模型的海量数据处理能力, 还提升了数据运算效率, 在网络层和中间隐含层中, 基于权重确定了神经元之间的内在关联度, 从而保证了粗粒度文本数据处理的效率和准确率.
4 算法性能分析
4.1 实验设置
为提升实验验证应用结果的普遍性, 样本数据集包含中文数据集和英文数据集两类. 其中中文数据集以某高校中文系教学实验数据为研究样本, 具体类别包含经济、 科技、 社会、 体育4个类别的15 250个样本; 英文数据采用美国加州大学欧文分校Iris数据集中的14 750个样本. 实验环境: CPU为Core i7 3.6 GHz, RAM为16 GB, ROM为2 TB, 采用Hadoop 2.8.0, 编程语言为Python 2.8. 参数配置: 中、 英文数据各占1/2, 数据维度为50, 训练倍数为20, 分块数为10.
4.2 实验设计
在Hadoop网络框架下, 将卷积神经网络模型与分布式网络框架相结合, 运行步骤如下:
1) 利用卷积神经网络模型的卷积层训练全部的粗粒度文本词条, 并将样本转换成二维矩阵的模式, 格式转换后的粗粒度数据输入神经网络模型;
2) 将输入神经网络系统的文本数据矩阵模型按高斯分布初始化处理, 并逐层验证卷积神经网络模型在数据特征归类中的有效性;
3) 利用Hadoop网络框架模型对输入系统的分布式特征数据降维, 并基于神经网络中隐含神经元训练粗粒度文本数据, 用分布式计算方法提高模型训练效率, 获得最优的分类计算结果.
4.3 实验结果与分析

图4 单机模式下各算法的分布式计算效率对比

图5 集群环境下各算法的分布式计算效率
以全部30 000个中英文混合数据为训练样本, 并将全部样本数据分成10个区块. 首先考察在单机条件下卷积神经网络算法的训练效率. 为使训练对比结果更直观, 与传统基于决策树的算法和一维卷积算法进行对比, 单机模式下不同算法的分布式计算效率如图4所示. 由图4可见, 随着迭代次数的增加, 卷积神经网络分布式算法对训练耗时的控制效果更好, 当迭代次数为140次时, 训练时间控制在1.34 h内, 显著优于传统基于决策树的分布式算法和一维卷积算法. 这主要是由于卷积神经网络中将输入的文本数据叠加及加权处理, 提高了分类器的数据处理能力, 而文本数据的池化环节将50维的高维数据降至10维以下, 更有助于混合数据的聚类和分类处理, 效率更高. Hadoop网络框架结构的应用, 能提高单机操作模式下的粗粒度数据分布效率, 在Hadoop2.8.0集群环境下不同算法的计算效率如图5所示. 由图5可见, 在Hadoop2.8.0集群环境下, 基于卷积神经网络的粗粒度文本计算效率十分稳定, 随着迭代次数的变化稳定性更强; 决策树算法和一维卷积算法相对于单机模式下计算效率也有改善.
下面对决策树算法、 一维卷积算法和卷积神经网络算法进行对比, 检验各算法对中英文混合数据集的处理性能及在相同环境下粗粒度数据的分布式处理性能. 将30 000个中英文混合数据划分为10个区块, 分别测试不同算法对粗粒度数据的分类准确率、 召回率、 训练时间和测试时间, 3种算法在相同的数据分块和Hadoop集群环境进行测试, 统计结果分别列于表2~表4.

表2 决策树算法性能评估

表3 一维卷积算法性能评估

表4 卷积神经网络算法性能评估

图6 不同算法的泛化误差对比
由表2~表4可见, 卷积神经网络分布式算法文本数据的分类准确率和召回率更高, 与决策树算法相比, 两个指标的平均值分别提高了6.91%和7.58%; 在训练时间和测试时间方面, 卷积神经网络算法分别节省了0.629 h和1.649 h. 与一维卷积算法相比, 两个指标的平均值分别提高了8.59%和12.01%; 在训练时间和测试时间方面, 卷积神经网络算法分别节省了1.48 h和2.46 h. 分布式运算效率得到了明显提高和改善.
泛化能力是衡量算法性能的重要指标之一, 通常对泛化误差的控制能力越强, 表明算法的泛化能力越强. 图6为11个数据区块范围内粗粒度数据处理的泛化误差边界范围. 由图6可见, 卷积神经网络算法误差控制在±0.01内, 优于决策树网络和一维卷积的算法性能, 因此本文算法具有更强的泛化能力及分布式数据处理能力.
综上所述, 本文针对传统粗粒度文本数据计算方法及一维卷积算法在数据训练和测试中存在的问题, 提出了一种基于卷积神经网络的粗粒度数据分布式算法. 由于在神经网络模型中加入了卷积函数运算和池化降维环节, 因此算法的性能和泛化能力得到了显著改善.
