机器学习算法在高分辨率遥感影像土地覆被分类中的对比分析
2020-07-15邢瑾
邢 瑾
(兰州大学 资源环境学院,甘肃 兰州 730000)
机器学习作为遥感界研究的一个热点[1],对于解决遥感数据量庞大、传统的目视解译费时费力等问题具有重要意义。与一些传统的统计分类器相比,机器学习分类器具有更多的优势[2],尤其是对具有更多地表空间结构等细节信息的高分辨率遥感影像进行面向对象分类时优势更加明显,现已经成为土地覆被分类研究的主要方法[3,4]。多年来,众多学者对现有的较为热门的机器学习分类器进行了对比研究[5-9]。Duro等[5]完成参数调优后对比分析了决策树、随机森林和支持向量机三种机器学习算法,表明随机森林和支持向量机在农业景观分类方面较有优势;谷晓天等[7]针对复杂地形区土地利用/土地覆被分类的情况,采用人工神经网络、决策树、支持向量机和随机森林四种机器学习方法进行对比分析,研究结果表明:随机森林和决策树的分类精度明显高于支持向量机和人工神经网络;林卉等[8]使用高分辨率遥感影像基于eCognition软件对5种面向对象分类方法(经过多次试验完成分类参数设置)进行了对比研究,试验结果表明,支持向量机(Support Vector Machine,SVM)、决策树(Decision Tree,DT)和随机森林(Random Forest,RF)的分类速度快精度高。
然而,已有的机器学习分类器对比研究中,对比结果不尽一致,且没有对各种分类器超参数的选取进行一个系统的说明与评价,因此不同方法在其最优超参数设置条件下对高分辨率遥感影像土地覆被分类效果的影响并不明确。WEKA作为一个公开的数据挖掘工作平台,集合了大量能承担数据挖掘任务的机器学习算法库,为各种机器学习技术提供了一个统一的环境[10]。其中,广受关注的随机森林(RF)、深度神经网络 (Deep Neural Network,DNN)、支持向量机(SVM)和决策树(DT)机器学习分类器在WEKA上均有对应的算法库。本文以宁夏回族自治区中卫市WordView3高分辨率多光谱影像为研究数据,在WEKA软件平台的统一环境下,对不同机器学习分类器:随机森林(RF)、深度神经网络(DNN)、支持向量机(SVM)和决策树(DT)的超参数选取与寻优进行了系统说明与评价,并对四种分类器在最优模型下的分类结果进行对比分析,探讨了不同的机器学习算法对高分辨率影像土地覆被分类效果的影响。
1 研究区与数据
1.1 研究区概况
中卫市位于宁夏回族自治区中西部,宁夏、内蒙古、甘肃三省区交汇处,是黄河中上游第一个自流灌溉市,其引黄灌溉区7.4万hm2,是西北地区重要的商品粮、水产品和设施蔬菜生产基地。本文从WordView3影像上选取1个试验研究区,其位于中卫市以西18km的腾格里沙漠东南边缘。研究区尺寸为1113×1092像素,区域范围约为4.86km2(图 1(a))。该研究区土地覆被类型较为丰富,根据2007年国家标准《土地利用现状分类》可分为7个一级类:耕地、园地、林地、住宅用地、交通运输用地、水域及水利设施用地和其他用地,13个二级类:水田、水浇地、休耕地、果园(由于本研究区存在两种类型的果园,故将其分为果园1和果园2)、其他林地、农村宅基地、公路用地、农村道路、沟渠、坑塘水面、水库水面、空闲地和裸土地(表1)。
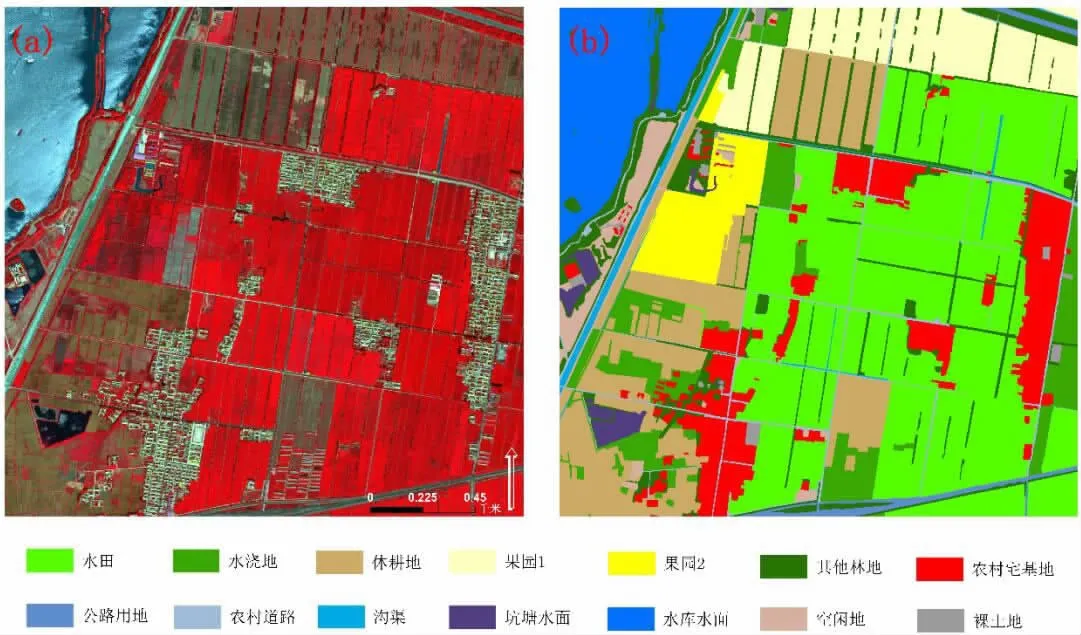
图1 (a)研究区WordView3影像,(b)目视解译结果

表1 研究区分类系统及训练样本数
1.2 数据介绍与预处理
该研究选取的WordView3多光谱影像数据获取日期为2016年7月8日,是识别植被的理想季节。该影像的8个多光谱波段(海岸蓝、蓝、绿、黄、红、红边、近红外1、近红外2),空间分辨率为2m。在进行试验之前,使用FLAASH对影像进行辐射定标和大气校正。由于该区位于黄河冲积平原,地势平坦,因此未对该影像进行正射校正。
本文使用eCognition商业软件中的分型网络演化算法(Fractal Net Evolution Approach,FNEA)完成研究区影像的多尺度分割,基于Liu等[11]提出的不一致评价法分割参数优选模型,确定影像的最优分割参数组合,尺度因子:50、形状因子:0.9、紧凑度因子:0.8,得到的2542个影像对象。
分类器的训练和客观的精度评价结果需要合适的训练和验证数据集。因此,本文在研究区中生成600个随机点,将随机点所在位置的对象作为训练样本,各类地物的训练样本个数见表1。并将影像目视解译结果作为分类精度的验证数据集 (图1(b))。采用Relief F[12]和PSO[13]混合特征选择算法进行特征优选,优选出研究区地物的最优特征组合,包括12种光谱特征、7种几何特征、12种纹理特征和5种自定义光谱特征。
2 分类器算法
目前,在面向对象影像土地覆被分类研究中最常用的机器学习算法是前面提到的四种机器学习分类器。机器学习模型的超参数是模型外部的配置,是在开始学习之前设置的参数。通常情况下,需要对超参数进行优化,给机器学习选择一组最优超参数,以提高学习的性能和效果。表2列出了四种分类器需要输入的超参数。

表2 四种机器学习算法的超参数
2.1.1 深度神经网络(DNN)
神经网络是一种分类器算法,它模拟人类神经突触传递信号并将其转化为信息[14]。DNN由输入层、输出层和两个及两个以上隐含层组成的神经网络[15],其中,输入层中的每个神经元表示训练数据中的一个特征;输出层中的每个神经元表示一种类别。结构上层与层之间是全连接的,将上一层的输出作为下一层的输入进行学习,原始特征经过多个层的逐层非线性变换,将初始样本的特征空间转化到另一个特征空间,来实现对现有特征更好地特征表达[16]。形式上,第 i+1层输出的激活函数 α(i+1)由输入层导出:

i指特定的层,wi和 b(i)为i层的权重和偏置,σ代表激活函数,本文将采用线性整流函数Relu作为激活函数。
2.1.2 随机森林(RF)
随机森林(RF)是由Breiman[17]提出的一种集成分类和回归树(CART)的分类器。该算法的核心思想就是:假设N个具有M个特征的训练样本,通过自助法(Bootstrap)重采样技术从N个原始训练样本集中有放回地重复随机抽取一定数量的样本生成新的训练样本集合,然后根据新生成的样本集合建立P个决策树,在数据分割每个内部节点的过程中,只有M个特征中的K个被随机选择并被用于区分不同的类,最后根据所建立的这些决策树的分类结果采用多数投票法将所有决策树得到的分类结果进行综合从而得到最终的分类结果[18]。
2.1.3 支持向量机(SVM)
支持向量机(SVM)算法是Vapnik等人在20世纪60年代提出并在90年代开始迅速发展并逐渐完善和成熟的一种机器学习算法[19]。其核心思想就是将样本向量通过采用非线性核函数的方式映射到更高维的特征空间中,继而在高维空间中寻找一个满足分类要求的最优分类超平面,能够使划分两个类的超平面的间隔最大化。
2.1.4 决策树(DT)
决策树(DT)是一种分类算法,其思想是基于从上到下、递归的分治策略,选择某个属性放置在根节点,为每个可能的属性值产生一个分支,将实例分成多个子集,每个子集对应一个根节点的分支,然后在每个分支上递归地重复这个过程。当所有实例有相同的分类时,停止。本文将使用比较成熟的C4.5进行试验。
3 实验与分析
针对研究区数据集,采用十折交叉验证方法作为四种机器学习分类器最优超参数组合的选择依据。选择交叉验证正确率最高的超参数组合作为该分类器的最优超参数组合。
为了保证所有机器学习分类结果具有可比性,在相同的影像分割,训练样本集,特征提取下,本文所采用的四种机器学习分类器均基于WEKA平台。由于DNN需要最多的用户输入超参数,若为DNN分类器测试所有的超参数组合是不现实的,所以本文采用三阶段由粗到细的方式分别对四种算法筛选最优超参数,表3中依次列出了四种机器学习分类器在三阶段筛选中各自超参数的范围。
3.1 DNN
对于DNN分类器,第一阶段,关于正则化系数、迭代次数和学习率三种超参数,采用Ng提出的迭代测试和指数式修改超参数的方法[20]。考虑到优选超参数组合过程中时间和内存空间的限制,DNN的结构应该相对简单,因此,隐含层数选择2、3、4层。Ng提出每一隐含层神经元的数量应该大于或等于输入特征的数量,这样才能构造更好的DNN[20],本文数据集优选的特征数量为36,最终分类结果为14类,因此,我们采用 14、36、72(特征数量的2倍)作为隐含层的神经元数,并采用网格搜索法遍历不同隐含层的DNN结构。第一阶段共检测1191个超参数排列。第二阶段,以下情况中,交叉验证的正确率高于其他超参数组合:隐含层数为4,各隐含层的神经元数为[72-36-14-72],正则化系数从0.0000001到0.00001,迭代次数从3到30,学习率从0.0003到0.001。第二阶段中,确定隐含层数为4,隐含层的神经元数为[72-36-14-72],其他超参数的变化如下:正则化系数从0.0000001到0.0000003,增量为0.0000002,从 0.000001到 0.000009,增量为0.000001;迭代次数从4到29,增量为1;学习率从0.0003到0.001,增量为0.0001。第二阶段共检测2002个超参数排列。第三阶段,在交叉验证的正确率高于其他组合的情况下,隐含层数和隐含层神经元数同第二阶段一致,确定迭次数为18,学习率为0.01,正则化系数从 0.0000001到 0.0000009,在此阶段中,正则化系数的变化增量为0.0000001。第三阶段共检测9个超参数排列,经过三阶段的搜索,找出适合本研究区数据集的DNN最优超参数组合为:隐含层数4,各隐含层节点数[36-72-14-72],正则化系数0.0000003,迭代次数18,学习率0.01。
3.2 RF
对于RF,测试它的两个超参数,树木的数量(P)和每次分裂的特征数量(K)。第一阶段:P从1到481,481为训练样本的总数,以50为增量,K从1到36,36为优选特征数,以1为增量。第二阶段:P从350到450,以10为增量,K从1到36,以1为增量。第三阶段:P从420到440,以1为增量,K为4。经过812个超参数检测,确定RF的最优超参数组合为:树木的数量424,每次分裂的特征数量4。
3.3 SVM
SVM采用和DNN相同的策略寻找最优的超参数组合,测试参数见表3,经过220次超参数组合确定最终的超参数组合为:惩罚系数94,伽马系数0.03。
3.4 DT
对于DT,测试它的两个超参数的组合,所需实例的最小数量(最小样本数)和置信系数。最小样本数按照RF的超参数P的找寻策略,置信系数按照DNN的策略寻找最优的超参数组合。经过262个超参数检测,确定DT的最优超参数组合为:最小样本数16,置信系数0.01。
3.2 分类结果分析

表3 分类器的超参数搜索

图3 分类结果图(左上:DNN分类结果,右上:RF分类结果,左下:SVM分类结果,右下:DT分类结果)
依据所确定的最优超参数组合得到四种机器学习分类器的最优模型,从而对研究区进行土地覆被分类。四种分类器的分类结果如图2所示。
对比四种分类结果,从整体效果上观察,四种分类器得到的分类结果大致相似,但RF、DNN和SVM的分类结果要明显好于DT的分类结果。从DT分类生成的分类图中可以观察到DT分类图左上方水库旁边的部分其他林地被分成果园2,这可能是由于其他林地和果园2具有相似的光谱和纹理特征造成的。在RF、DNN和SVM三种分类图中,水库水面上方有三块明显被分类为坑塘水面,但DT将其正确分类,这可能是由于这三块与坑塘水面的光谱特征较为相似,使得RF、DNN和SVM三种分类器未能找到合适的区分特征将其区分。
将四种分类结果与图1(b)的目视解译结果作比较,可以发现,四种分类器得到的分类结果与实际地物基本吻合,但用不同的机器学习分类器均存在一些错分现象,且错分对象不完全一致,这可能是由于不同机器学习算法对不同地物的识别特征不一致。水浇地和裸土地的错分情况比较严重,四个分类图中右侧和中间下侧的水浇地大部分被误分成水田。右侧的农村宅基地被错分成裸土地。还存在一些其他类别之间的错分现象,例如,水田与果园2、农村宅基地与农村道路、森林与果园2等。大部分错分现象主要是因为光谱和纹理相似性,比如说在标准假彩色的影像中,水浇地内部的一些对象与水田和果园2都呈现鲜红色;森林与果园2在纹理方面都较为粗糙,且光谱上也表现为红色;农村宅基地与农村道路和裸土地都高亮显示在影像上。
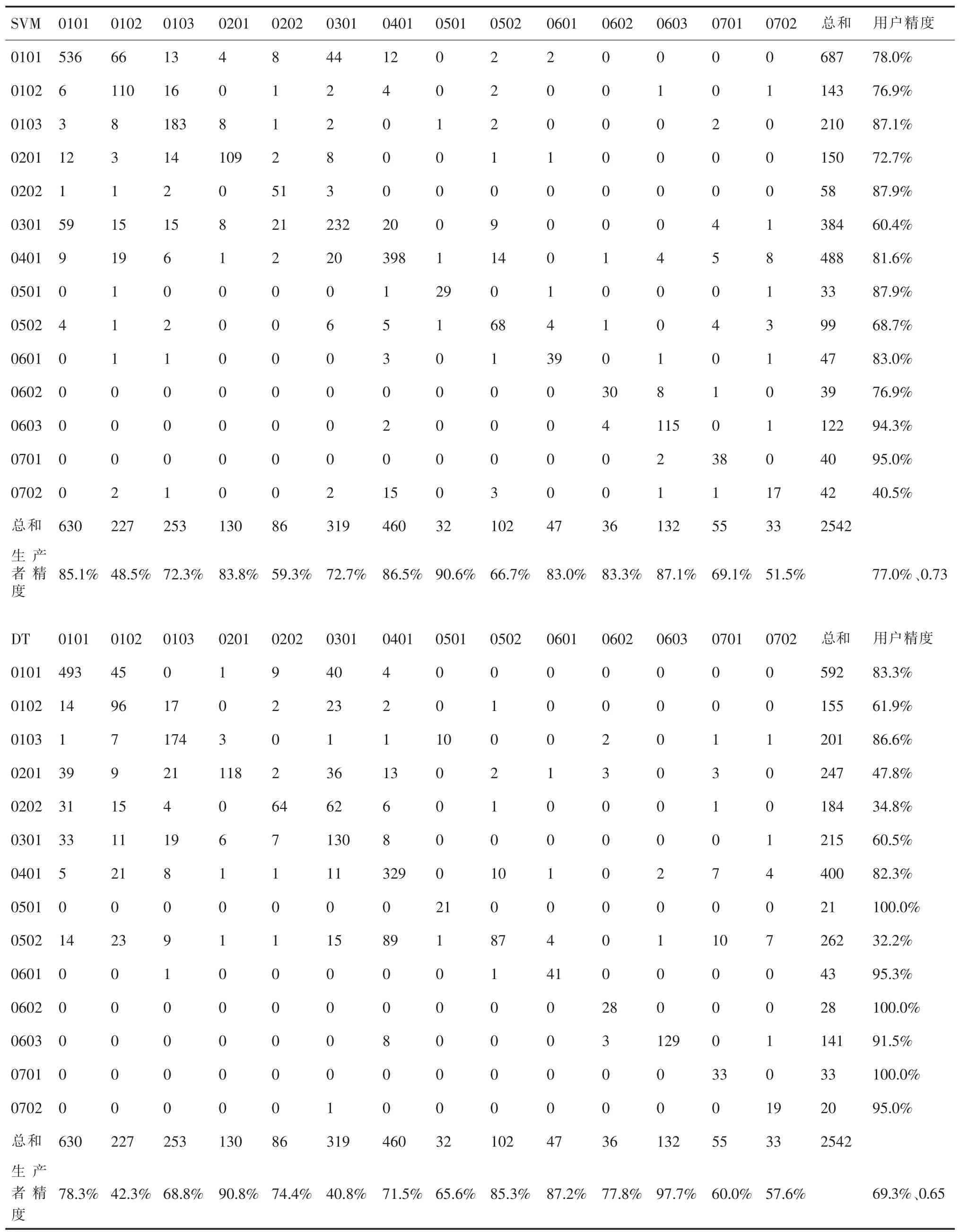
为了定量评价四种机器学习分类器的分类效果,采用总体精度、卡帕系数,混淆矩阵、用户精度和生产者精度来客观评价四种分类器的分类效果,评价结果如表4所示。总体精度方面除DT的分类精度较低外,其它三种机器学习分类器的分类精度都达到了77%以上。RF的分类精度最高,为80.8%,DNN次之,为77.5%,SVM为77.0%。除DT的卡帕系数在0.7以下,RF、DNN和SVM的卡帕系数分别为0.78、0.74和0.73,随机森林的卡帕系数最高。
为了检测每种土地覆被类型的分类精度,分析了各分类图的混淆矩阵以及由此产生的用户精度和生产者精度。可以发现,各分类器的大部分土地类型的分类精度高低走势大致一致,例如,沟渠和水库水面的类别精度均较高,生产者精度和用户精度均在81%以上;,水浇地、农村道路和裸土地的分类精度都较低,最低者接近40%。总体来看,生产者精度和用户精度同时高于80%的类别,DNN和RF均有6种,SVM有4种,而DT只有2种,除个别地物DT的分类精度较高外,例如,DT分类结果中水库水面的生产者精度高于其他三种分类结果,达到97.7%,其他类别的分类精度都较低,例如,其他林地的生产者精度低于另外三种分类结果,仅有40.8%,所以DT的总体精度和卡帕系数均低于其他三种分类器的分类精度。除去这些个别情况外,各类地物的精度均RF的分类精度最高,DNN次之,SVM略低于DNN,DT最低,所以在本研究区的机器学习分类器的对比试验中,无论是定性分析还是定量分析,RF的分类结果均最佳。
5 结论
针对不同机器学习分类器在最优超参数组合下对分类结果的影响并不明确的问题。本文基于Wordview3多光谱遥感影像数据,完成随机森林(RF)、深度神经网络(DNN)、支持向量机(SVM)和决策树(DT)四种机器学习分类器在土地覆被分类研究中的系统分步指导和对比分析。系统的讨论了四种机器学习分类器在选取最优超参数组合的详细过程,从分类效果和分类精度方面对比分析了在最优超参数组合下四种机器学习分类器的分类结果。对比结果表明:四种机器学习分类器均可以将研究区的各类地物区分开,并且得到不错的分类效果;在相同的影像分割,训练样本集,特征提取下,使用不同的机器学习分类器均存在一些错分现象,且错分对象不完全一致;从分类图效果和总体分类精度上,RF,DNN和SVM的分类效果和分类精度明显优于DT,其中RF的分类精度最高,总体精度达到80.8%,卡帕系数达到0.78,见表4。

表4 四种机器学习分类器精度评价表
SVM 0101 0102 0103 0201 0202 0301 0401 0501 0502 0601 0602 0603 0701 0702 总和 用户精度0101 536 66 13 4 8 44 12 0 2 2 0 0 0 0 687 78.0%0102 6 110 16 0 1 2 4 0 2 0 0 1 0 1 143 76.9%0103 3 8 183 8 1 2 0 1 2 0 0 0 2 0 210 87.1%0201 12 3 14 109 2 8 0 0 1 1 0 0 0 0 150 72.7%0202 1 1 2 0 51 3 0 0 0 0 0 0 0 0 58 87.9%0301 59 15 15 8 21 232 20 0 9 0 0 0 4 1 384 60.4%0401 9 19 6 1 2 20 398 1 14 0 1 4 5 8 488 81.6%0501 0 1 0 0 0 0 1 29 0 1 0 0 0 1 33 87.9%0502 4 1 2 0 0 6 5 1 68 4 1 0 4 3 99 68.7%0601 0 1 1 0 0 0 3 0 1 39 0 1 0 1 47 83.0%0602 0 0 0 0 0 0 0 0 0 0 30 8 1 0 39 76.9%0603 0 0 0 0 0 0 2 0 0 0 4 115 0 1 122 94.3%0701 0 0 0 0 0 0 0 0 0 0 0 2 38 0 40 95.0%0702 0 2 1 0 0 2 15 0 3 0 0 1 1 17 42 40.5%总和 630 227 253 130 86 319 460 32 102 47 36 132 55 33 2542生产者精度85.1%48.5%72.3% 83.8% 59.3% 72.7% 86.5% 90.6% 66.7% 83.0% 83.3% 87.1% 69.1% 51.5% 77.0%、0.73 DT 0101 0102 0103 0201 0202 0301 0401 0501 0502 0601 0602 0603 0701 0702 总和 用户精度0101 493 45 0 1 9 40 4 0 0 0 0 0 0 0 592 83.3%0102 14 96 17 0 2 23 2 0 1 0 0 0 0 0 155 61.9%0103 1 7 174 3 0 1 1 10 0 0 2 0 1 1 201 86.6%0201 39 9 21 118 2 36 13 0 2 1 3 0 3 0 247 47.8%0202 31 15 4 0 64 62 6 0 1 0 0 0 1 0 184 34.8%0301 33 11 19 6 7 130 8 0 0 0 0 0 0 1 215 60.5%0401 5 21 8 1 1 11 329 0 10 1 0 2 7 4 400 82.3%0501 0 0 0 0 0 0 0 21 0 0 0 0 0 0 21 100.0%0502 14 23 9 1 1 15 89 1 87 4 0 1 10 7 262 32.2%0601 0 0 1 0 0 0 0 0 1 41 0 0 0 0 43 95.3%0602 0 0 0 0 0 0 0 0 0 0 28 0 0 0 28 100.0%0603 0 0 0 0 0 0 8 0 0 0 3 129 0 1 141 91.5%0701 0 0 0 0 0 0 0 0 0 0 0 0 33 0 33 100.0%0702 0 0 0 0 0 1 0 0 0 0 0 0 0 19 20 95.0%总和 630 227 253 130 86 319 460 32 102 47 36 132 55 33 2542生产者精度78.3%42.3%68.8% 90.8% 74.4% 40.8% 71.5% 65.6% 85.3% 87.2% 77.8% 97.7% 60.0% 57.6% 69.3%、0.65
