河北省主要树种单木和林分生长率模型研建
2020-07-02曾伟生曹迎春陈新云赵连清
曾伟生,曹迎春,陈新云,赵连清
(1 国家林业和草原局调查规划设计院,北京 100714;2河北省林业调查规划设计院,石家庄 050051)
森林是陆地生态系统的主体,是人类生存发展的重要生态保障。十八大以来,党中央、国务院高度重视林业,将生态文明建设纳入五位一体的战略布局。原来唯GDP的考核模式逐渐被打破,《生态文明建设目标评价考核办法》已经开始实施,森林覆盖率和蓄积量成为了国家经济社会发展的约束性指标,国家要求开展年度评价和5年定期考核。因此,不论是国家决策层面还是社会公众层面,对森林资源数据的时效性要求越来越高。但我国现行的森林资源调查体系,国家森林资源连续清查(简称一类清查)5年开展一次,森林资源规划设计调查(简称二类调查)一般10年才开展一次,无法满足新时期对年度数据的需求。因此,如何实现森林资源年度出数,一直成为业内人士不断探索的问题[1-3]。
由于森林生长的长周期性及经济技术条件的局限性,将森林资源的调查监测周期缩短至1年是不现实的。因此,基于定期调查数据开展年度更新是一条可行的途径。目前,已有不少森林资源数据更新方面的研究成果[4-13],而各种数据更新方法都以数学模型尤其是生长率模型作为基础支撑。关于生长率模型的建立方法,各领域研究人员也已发表了不少研究成果[14-22],其中多数模型都是基于一类清查的固定样地数据而建立的。本文利用河北省最近4期的一类清查固定样地数据,就单木和林分水平,分别建立各主要树种(组)的胸径和材积生长率模型,以期为河北省基于二类调查成果开展森林资源年度数据更新提供依据。
1 数据与方法
1.1 数据资料
本文所用数据为第六次至第九次全国森林资源清查河北省2001,2006,2011,2016年4个年度的固定样地调查数据,包括单木水平的保留木前后期胸径、材积数据,以及林分水平的固定样地前后期蓄积数据。为了保证有足够的样本量,将3期动态数据(2001—2006,2006—2011,2011—2016年)全部合并为一套建模数据,按单木和林分水平数据,分树种(组)进行建模前的数据预处理。
1.1.1单木数据处理
单木数据分为云杉(Piceaspp.)、落叶松(Larixspp.)、樟子松(Pinussylvestrisvar.mongolica)、油松(Pinustabulaeformis)、柏木(Cupressusspp.)、栎类(Quercusspp.)、白桦(Betulaplatyphylla)、枫桦(Betulacostata)、胡桃楸(Juglansmandshurica)、榆树(Ulmusspp.)、刺槐(Robiniapseudoacacia)、其他硬阔、椴树(Tiliatuan)、杨树(Populusspp.)、山杨(Populusdavidiana)、柳树(Salixspp.)、白蜡树(Fraxinuschinensis)、其他软阔等18个树种组,处理过程如下:
1) 形成数据文件。提取3期全部保留木数据,整理成包括样地号、样木号、立木类型、检尺类型、树种、本期胸径、前期胸径、本期材积、前期材积等因子的数据文件。
2) 剔除异常样木。按树种(组)、前期胸径排序,首先剔除生长量小于等于0的样木;然后按复利式计算年均胸径生长率,绘制散点图,剔除生长率明显过大的异常样木,最后参与建模的数据为155 086条记录。
3) 进行数据合并。考虑到单木数据量过大(如,落叶松、油松、栎类、白桦、杨树的建模数据量均在1万以上),且按径阶的分布极不均匀,将前期胸径相同(按0.1cm)的单木数据合并,其胸径生长量采用算术平均数,然后再计算相应的生长率。18个树种(组)的单木数据建模样本量及胸径和年龄(样地平均年龄)的上限范围如表1所示。
1.1.2林分数据处理
林分数据分为油松、落叶松、柏木、栎类、桦木、刺槐、榆树、其他硬阔、杨树、椴树、其他软阔、混交类等12个树种组,其中杨树再分山区和平原2个类型。提取全部3期乔木林固定样地动态数据,整理成包括样地号、优势树种、本期平均胸径、前期平均胸径、本期平均年龄、前期平均年龄、本期样地材积、前期样地材积、保留木生长量、材积生长率等因子的数据文件。考虑到样地进界生长的复杂性,本研究只考虑保留木生长量及其对应的生长率,即假定“本期样地材积-进界木生长量=前期样地材积+保留木生长量”,并以此为基础计算材积生长率。通过对比分析,按普雷斯勒式计算的生长率比按复利式计算的生长率稳定性好,故林分水平的材积生长率数据均按普雷斯勒式计算[23]。剔除异常数据后,参与建模的数据为3 083条记录(含3期动态数据),12个树种组的建模样本量及平均胸径和平均年龄的上限范围如表2所示。

表1 单木数据基本情况表Tab.1 General situation of tree-level data

表2 林分数据基本情况表Tab.2 General situation of stand-level data
注:1)油松含樟子松,落叶松含云杉,其他硬阔含胡桃楸、白蜡树等,其他软阔含柳树、泡桐等,混交类含针叶混、阔叶混和针阔混;2)杨树山区包括冀北高原区、冀北山地区、冀西北黄土沟壑区、冀西山地区4个区,平原包括中南平原区、滨海平原区2个区。
1.2 研究方法
1.2.1单木模型建立
单木生长率模型按一元和二元模型可分别表述如下[14,23]:
P=a×Db+ε
(1)
P=a×Db×Ac+ε
(2)
式中:P为胸径或材积生长率(%);D为林木胸径(cm);A为年龄(a);a,b,c为模型参数;ε为误差项,假定其服从均值为0的正态分布。
1.2.2林分模型建立
一元和二元林分生长率模型分别表述如下:
PV=a×Db+ε
(3)
PV=a×Db×Ac+ε
(4)
式中:PV为材积生长率(%);D为平均胸径(cm);A为平均年龄(a);a,b,c为模型参数;ε为误差项,假定其服从均值为0的正态分布。
由于生长率是相对数,其异方差性不明显,因此,式(1)—式(4)的参数求解都采用普通最小二乘法,进行非线性回归估计[24]。
1.2.3模型评价
对于单木和林分生长率模型,除了采用常规的确定系数(R2)和估计值的标准差(SEE)来评价外,还采用总体相对误差(TRE)、平均系统误差(ASE)、平均预估误差(MPE)和平均百分标准误差(MPSE)4项误差指标进行综合评价。其表达式如下[25-26]:
(5)
(6)
(7)
(8)
(9)
(10)
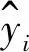
按照传统建模方法,一般应该把样本分为建模样本和检验样本两部分,用第一部分样本建立模型,再用第二部分样本作独立性检验或适用性检验。对这一检验的必要性,已经有不少学者提出质疑[26-29],但尚未达成共识。目前较倾向于采用K折检验法或留一检验法[30],其中10折交叉检验法又最常用,即:将样本等分成10份,用其中的9份建模,1份检验,如此重复10次,每一份子样本都参与检验,再用全部的检验结果来对模型进行评价。
2 结果与分析
2.1 单木生长率模型
利用全部18个树种组的单木平均数据,拟合一元和二元胸径生长率和材积生长率模型式(1)、式(2),再基于全部单木数据,用式(5)—式(10)计算模型的评价指标,其结果如表3所示。可以看出,单木生长率模型的平均预估误差(MPE)基本都在3%以内,而平均百分标准误差(MPSE),胸径生长率模型大多都在10%以内,材积生长率模型基本在20%左右。需要注意的一点是,由于一类清查数据并没有每株样木的年龄信息,表3中二元模型的年龄采用的是林分平均年龄,导致其相关性降低。因此,有部分树种(如白桦、枫桦和白蜡树)的二元模型,其年龄参数c的估计值为0,说明平均年龄在二元模型中没有统计学意义。
作为对比,利用樟子松单木数据(n=515)按10折交叉检验法进行检验。即:将樟子松的515组数据按胸径大小排序后,机械分成10份,建10次一元胸径生长率模型,每次用其中9份建模,用另外1份检验,再用全部样本的检验结果计算前述6项指标。从结果可知,10个模型参数估计值的平均数(平均模型:a=22.054,b=-0.69096)与利用全部样本的建模结果(总体模型:a=22.011,b=-0.69075)非常接近,表4也显示3套模型计算的评价指标几乎没有差别,所以其他模型不再开展10折交叉检验。

表3 单木生长率模型拟合结果及评价指标Tab.3 Fitting results and evaluation indices of tree-level growth rate models
(续表)

树种组生长率模型参数估计值 a b c评价指标 R2 SEE TRE/% ASE/% MPE/% MPSE/%其他硬阔Other hardwood broadleaved椴树 Tilia tuan杨树 Populus spp.山杨 Populus davidiana柳树 Salix spp.白蜡树Fraxinus chinensis其他软阔Other softwood broadleaved胸径材积胸径材积胸径材积胸径材积胸径材积胸径材积胸径材积(1)12.10-0.7058—0.93740.980.040.090.207.96(2)29.60-0.6539-0.28630.94090.95-0.81-0.890.207.79(1)72.18-1.0685—0.96000.00880.230.240.5422.04(2)148.7-0.8837-0.32980.96240.0085-1.09-0.660.5221.09(1)8.776-0.5656—0.92810.97-0.030.040.308.03(2)35.95-0.4600-0.47070.93210.95-1.41-1.500.297.67(1)57.98-0.9736—0.93840.00880.220.260.7921.98(2)242.9-0.8547-0.48520.94170.0086-2.99-4.200.7720.62(1)86.30-1.0889—0.69193.54-0.90-0.910.4119.62(2)116.1-0.8690-0.30500.77013.06-5.71-6.720.3616.08(1)396.1-1.2837—0.77450.0676-0.90-1.911.0050.51(2)552.1-1.0419-0.33310.80100.0635-14.74-21.490.9439.90(1)19.48-0.8016—0.94281.14-0.25-0.370.378.51(2)43.36-0.6220-0.35900.94631.10-0.88-1.130.368.09(1)87.99-1.008—0.96900.01840.35-0.650.9423.85(2)176.2-0.8450-0.31120.97140.0177-0.68-2.600.9022.62(1)33.54-0.8529—0.89512.700.560.721.4516.66(2)89.42-0.9210-0.28030.91912.37-2.03-3.451.2814.15(1)129.1-1.0106—0.93820.04092.205.902.8545.31(2)389.6-1.1119-0.29610.94680.0380-1.86-9.262.6534.20(1)7.160-0.5251—0.94470.620.100.250.745.88(2)7.160-0.5251-0.00000.94470.620.100.250.745.88(1)48.62-0.9658—0.95820.00440.080.312.0216.47(2)48.62-0.9658-0.00000.95820.00440.080.312.0216.47(1)11.40-0.6080—0.92921.19-0.08-0.140.267.92(2)23.22-0.5075-0.28320.93591.13-0.63-0.800.257.75(1)47.09-0.7795—0.94620.01900.280.010.7922.06(2)95.67-0.6781-0.28310.95160.0180-0.82-2.010.7521.37
注:R2是基于用生长率计算的后期胸径或材积计算的,SEE的单位分别为cm和m3。

表4 樟子松不同一元胸径生长率模型的评价指标对比Tab.4 Comparison of evaluation indices of different one-variable dbh growth rate models for Pinussylvestris
2.2 林分生长率模型
利用12个树种组的林分水平材积生长率数据,拟合一元和二元林分材积生长率模型,再用式(5)—式(10)计算模型的评价指标,其结果如表5所示。可以看出,除了杨树模型和刺槐的一元模型以外,其他模型的确定系数(R2)都在0.9以上,平均预估误差(MPE)在5%以内;而平均百分标准误差(MPSE)均在25%以内。相当于用这些模型开展森林蓄积量年度更新工作,不同优势树种林分的总蓄积量基本能达到95%以上的预估精度,落实到小班蓄积量的精度也基本能达到80%左右。杨树模型尤其是平原地区的杨树模型效果较差,可能是因为该树种生长快、前后期变化大,所以对后期的预测结果精度会低些。

表5 林分材积生长率模型拟合结果及评价指标Tab.5 Fitting results and evaluation indices of stand-level volume growth rate models
3 结论与讨论
利用第六次至第九次全国森林资源清查河北省2001,2006,2011,2016年4个年度的固定样地调查数据,建立了主要树种的单木和林分水平的生长率模型,其中建立单木生长率模型的数据达到15万余组,建立林分生长率模型的数据也达到3千组以上。从模型评价指标看,单木生长率模型的平均预估误差(MPE)基本都在3%以内,而平均百分标准误差(MPSE),胸径生长率模型大都在10%以内,材积生长率模型基本在20%左右;林分生长率模型的平均预估误差(MPE)基本都在5%以内,平均百分标准误差(MPSE)大都在25%以内。相当于用这些模型开展森林蓄积量年度更新工作,不同优势树种林分的总蓄积量基本能达到95%以上的预估精度,落实到小班蓄积量的精度也基本能达到80%左右。因此,本文所建模型可为河北省基于2018年二类调查成果开展森林资源年度更新提供依据。
本文主要基于一类清查数据来建模,尽管数据量很大,但不同树种(组)之间的建模样本量差异也很大,导致所建模型的预估精度存在较大差异。如,林分生长率模型的建模样本量在43~658份之间,平均预估精度(MPE)在0.87%~6.14%之间,平均百分标准误差(MPSE)在10.24%~39.20%之间。另外,由于没有每株样木的年龄信息,单木生长率模型中的年龄采用的是林分的平均年龄,从而影响模型的预估效果,部分模型中的年龄参数为0,表明将平均年龄引入单木模型无意义。随着河北省森林资源年度监测工作的不断推进,应当设置一些典型样地开展定期调查,通过不断积累样地调查资料,今后再对本文所建模型作改进和修正。
