改进型协同过滤的图书推荐算法
2020-06-30王维高伊腾周国栋李云云唐宁孙媛媛
王维 高伊腾 周国栋 李云云 唐宁 孙媛媛
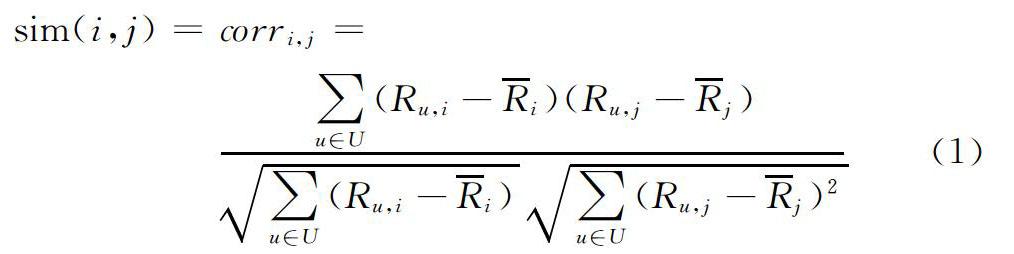
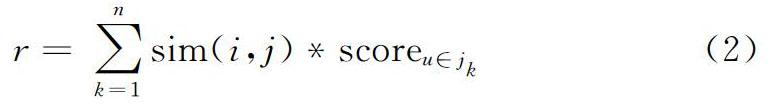
摘 要: 针对用户从海量图书中选择喜欢图书较难的问题,提出一种基于图书属性分组的改进协同过滤算法。该算法首先根据用户喜欢的图书类型去选择相似用户,缩小数据集,再根据基于用户的协同过滤算法寻找最近邻居集合,然后根据项目推荐值的方法向用户推荐感兴趣的图书序列。实验结果表明:在同一数据量下,该算法在推荐数据量以及覆盖率方面均优于同类算法。
关键词: 协同过滤; 用户分组; 用户相似度
中图分类号: TG 4 文献标志码: A
A Book Recommendation Algorithm Based on Improved Collaborative Filtering
WANG Wei, GAO Yiteng, ZHOU Guodong, LI Yunyun, TANG Ning, SUN Yuanyuan
(Department of Computer Science, Xianyang Normal University, Xianyang, Shanxi 712000, China)
Abstract:
In order to solve the problem that users are difficult to select their favorite books from a large number of books, a collaborative filtering algorithm based on book attribute grouping is proposed. The method first selects similar users according to the type of books users like, then reduces the data set, and then finds the nearest neighbor set according to the collaborative filtering algorithm based on users. Then according to the project recommended value method to recommend the user interested in the sequence of books. The experimental results show that the proposed algorithm is superior to the same algorithm in the recommended data volume and the accuracy under the same data volume. The algorithm improves the user satisfaction.
Key words:
collaborative filtering; user packet; user similarity
0 引言
互联网规模的迅速发展带来了信息超载问题,由于信息量过大,使得人们在网上搜索信息时降低了信息的使用率,图书信息也是如此。网络上的图书资源越来越丰富,为了充分利用信息资源,解决用户复杂的需求和庞大图书信息之间的矛盾,协同过滤算法因此产生。
目前,协同过滤算法包括基于物品的协同过滤算法和基于用户的协同过滤算法[1]。基于物品的协同过滤算法是根据商品属性进行推荐的,不过它需要透彻的内容分析,只能推荐内容相似的物品,并且存在用户冷启动问题[2],不能给用户带来惊喜。基于用户的协同过滤算法在所有用户中找出与目标用户相似的用户,然后根据这些用户对项目的不同评分,产生相似用户,继而通过相似用户集合给目标用户推荐书籍,虽然协同过滤推荐算法在信息过滤方面体现出了极大的优势,但由于用户对项目的评分较少,数据冷启动问题严重,并且随着信息量的不断增加,这种方法耗时耗力。总体来讲,算法在不同领域中的应用存在以下3种问题:① 冷启动问题;② 最初评价问题;③ 稀疏性问题。
为解决这些问题,文献[3]中通过利用用户注册信息或者选择适当物品以启动用户兴趣来解决。针对物品冷启动问题,可以通过利用物品的内容信息来计算物品间的相似度,进而对新物品产生关联。对于新系统,则可以通过对物品进行多维度的特征标记来计算更为准确的物品相似度以减少系统冷启动的影响。文献[4]中提出了一种递归预测算法,该算法让那些最近邻的用户加入到预测处理中。即使他们没有对给定的项目进行评分,但对项目评分值不明确的用户,可以预测它的递归,整合到预测过程中。此方法用另一种方式缓解了矩阵稀疏对推荐质量的影响,提供了推荐精度。文献[5]中分析了基于项目评分预测的协同过滤推荐算法存在的问题,继而采用了修正的条件概率方法计算项目之间的相似性,使得數据稀疏性对计算结果的负面影响变小。
本文算法通过分析项目属性从而对数据集缩小,得到粒度较粗但相似度较高的用户集合,以及使用皮尔逊相关系数计算用户相似度,之后采用本文提出的图书推荐值计算方法对用户进行推荐,最终的实验测试结果符合预期效果。
1 改进型协同过滤的图书推荐算法
1.1 简述
基于用户的协同过滤算法的主要步骤是寻找各用户的邻居用户,并根据邻居用户对目标用户未评分项目的评分进行预测,邻居是和目标用户相似度最高的k个用户,k的具体数目由系统的特性决定,实际中往往会通过实验来确定。在确定邻居用户后,需要根据邻居已评分且目标用户未评分的项目的评分值进行评分预测。
本文改进型协同过滤推荐算法通过获取目标用户所喜欢图书的所属类别,然后在所有用户数据集中大致寻找出和目标用户喜欢同种类书籍的用户群体,这样极大的增加了用户群体中包含较多与目标用户相似度高的概率,可以方便快速解决数据稀疏性问题。将这些用户构造成一个用户集合,采用皮尔逊相关系数计算方法,依次计算目标用户与该集合中每一个用户的相似度,使用图书推荐值公式计算用户集合内每一本图书的图书推荐值,最后通过实验分析确定一个合适的参量rc,将加权推荐值大于等于rc的图书推荐给目标用户。
1.2 用户集合的获取
由于图书推荐中图书的数量和用户很多,但用户选择的图书数量却很少,如果直接使用协同过滤算法将面临严重的数据稀疏性问题。因此本文首先根据目标用户所选择图书的类别,确定对目标用户进行推荐的用户集合,缩小了使用协同过滤的数据集,并在一定程度上缓解了数据稀疏性问题,具体执行过程如下:
(1) 统计目标用户所加入的图书种类;
(2) 在所有用户集合寻找与目标用户加入相同图书种类的用户。
1.3 计算用户相似度
用户相似度的度量方法是算法的核心,常使用的方法包括皮尔逊相关系数、夹角余弦相似度和Jaccard系数等[6]。本文采用皮尔逊相关系数作为用户相似度的测量,如式(1)所示。
其中,sim(i,j)表示用户i与用户j的相似度,Ri与Rj分别表示用戶i和j收藏的每一个项目的评分,Ri与Rj分别表示用户i,j的收藏项目评分的平均值。
1.4 计算图书推荐值
通过皮尔逊相关系数计算出的用户相似度,能够找出与目标用户相似的用户,为了向目标用户推荐系统预测的项目,采用图书推荐值的计算方法,如式(2)所示。
r为图书推荐值,scoreu∈jk为用户j收藏的每本图书的评分,n为与目标用户相似的用户集合的数量。
1.5 获取推荐结果
为了筛选出准确度较高的图书,设置一个参数——项目推荐临界值rc,将图书推荐值大于rc的图书推荐给用户,其中参数rc的取值通过实验测试得来,最终得到向目标用户推荐的项目集合。
1.6 算法整体执行步骤
Step1.获取目标用户的用户集合资源:查找与目标用户所收藏图书种类相同的用户,构成用户集合资源。
Step2.分别计算目标用户与用户集合中每一个用户的相关系数。在用户集合资源中,使用皮尔逊相关系数计算用户的相似性,得到的结果保存在二维数组中。
Step3.计算每一本图书的图书推荐值。使用用户相似度数据及每本图书对应的评分,带入图书推荐值计算公式中,将每一本图书的图书推荐值再次保存在二维数组中。
Step4.获取推荐结果。使用步骤3中的数据,将图书推荐值大于rc的图书推荐给用户。
2 数据测试及结果分析
2.1 数据源的获取
由于目前在电商网站上获取用户个人信息比较困难,为了收集数据顺利进行数据分析,我们采用了目前大多数数据分析人员普遍采用的方法——数据仿真模拟,创建nUsers表,包含用户的姓名、性别、年级、学院、专业、书名、评分、书类等七个字段列。数据模拟采用以下3种方式:
(1) 从校图书馆获取2015级、2016级、2017级学生的姓名、性别、年级、学院、专业,仿真模拟的各年级的学生人数、学院、专业,数据量依据实际各学院对应的学生人数、性别所占比例、专业人数等同比例缩小。
其中学院及其包含的专业有:计算机学院(所属专业有:计科、软件、物联),资历学院(所属专业有:地理科学、历史学),建筑学院(所属专业有:建筑学、城乡规划、城市规划),经管学院(所属专业有:经济学、财务管理、经管学)。
(2) 书籍名称以及书籍类别通过当当图书网站来爬取。
(3) 利用随机方法生成书籍的评分。
采用以上3种数据获取方式,能够最大限度的模拟和描述真实电商网络的应用情景,尽管实际电商网络应用场景比实验描述的要复杂,但以上实验数据的获取基本接近实际电商网络的基本情况,因此使用仿真模拟的数据同样能够反映出算法的特点。通过算法之间的比较可以体现算法的各种数据特征,进而通过分析结果来证明算法的可用性,本文选取基于用户的协同过滤图书推荐算法与本文的改进型协同过滤图书推荐算法进行比较。
2.2 推荐系统中的评价指标
(1) 精确度如式(3)。
C,+表示积极、成功的互动,C表示所有互动,生成的候选集中积极、成功的互动数量占总互动的比重称作推荐的准确度[7]。P值范围是[0,1],当P值越大时,精确度越高,推荐的结果效果越好。
(2) 覆盖率如式(4)。
其中,集合N是指为目标用户分组后所得到的用户集合,n(N)是用户数量;集合M是用户集合N中相关系数大于等于0.8的用户集合,n(M)是用户集合M的数量,相关系数大于等于0.8的用户数量占总用户集合的比重称作覆盖率[7]。K值范围是[0,1],当K值越大,分组用户集合中的高度相关的用户所占的比重越大,寻找的用户集合稀疏性越低。
(3) 成功率如式(5)。
成功率是候选集中成功互动的数量占总互动数量的比重[7]。SR值范围是[0,1],当SR值越大,推荐的图书质量越高。
2.3 实验内容与实验结果
2.3.1 rc参数选取
一般来讲rc越高,被推荐的图书越精确,但与此同时,图书数量会变少,为了解决推荐准确度与推荐数量的不平衡问题,我们提出rc*n计算公式,其中n为向目标用户推荐的图书数量,n是向所有目标用户推荐的图书数量的平均值。
实验一:下列折线图中横坐标代表用户数量,纵坐标为rc*n。实验开始之前,有目的的寻找6个目标用户,目标用户需要满足得到的用户集合数量分别是10,20,30,40,50,60。采用二分法来获取本次实验数据集的rc值:实验开始时,我们找出较准确的rc值介于5和11之间。
采用二分法比较rc=5,rc=8,rc=11,观察图1,可知rc*n依次大小为rc=8>rc=5>rc=11;
再次查找rc=5,rc=6.5,rc=8;观察图2,可知rc*n依次大小为rc=8>rc=6.5>rc=5;
再次查找rc=8,rc=7.25,rc=6.5;观察图3,可知rc*n依次大小为rc=6.5>rc=7.25>rc=8;
再次查找rc=8,rc=7.625,rc=7.25;观察图4,可知rc*n依次大小为rc=7.25>rc=7.625>rc=8;
当继续二分时,绘制出来的折线图变化趋势以及折线间的紧密程度变化不大,因此取rc=7.625。
实验1图示中随着用户集合数量的增加,rc*n折線图呈现不规则的下降与升高,属于实验测试时的正常现象。实验表明当rc=7.625时,可以保持rc*n呈较高水平,即目标用户推荐的图书准确率高且图书数量不会因为高准确率而降低。
2.3.2 算法的覆盖率比较
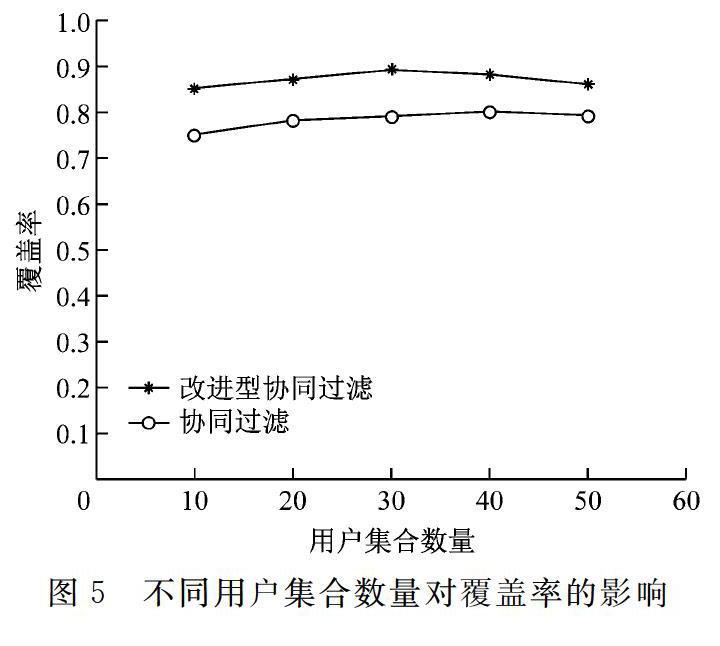
实验二:使用覆盖率作为度量标准,一反面可以反映出数据集中相似度较高的用户所占总集合的比重,另一方面间接性体现出数据集中的数据稀疏性。我们选取6组目标用户,每一组有两个目标用户,并且使得每组中两个目标用户中用户集合的数量相等,这两个目标用户分别采用改进型协同过滤图书推荐算法与基于用户的协同过滤算法。测试内容为:目标用户覆盖率随用户集合数量的变化。如图5,其中横轴代表用户集合的数量,纵轴代表目标用户覆盖率,如图5所示。
实验2表明,随着用户数量的递增,覆盖率的值趋于平缓,总体上改进型协同过滤图书推荐算法优于基于用户的协同过滤算法。
4 总结
本文提出了改进型协同过滤图书推荐算法,首先在所有用户中以较短的时间筛选出合适的用户集合与目标用户进行相似度计算,其次采用图书推荐值的计算方法,其数值可以反映出目标图书借阅次数即受欢迎程度。在研究数据稀疏时,算法采用了分组的思想,即将相似度高的用户分为一组,从中找到合适的推荐项目。下一步将研究关联规则算法下的纸质图书推荐、新图书的推荐等问题。
参考文献
[1] 罗文.协同过滤算法综述[J].科技传播,2015,7(7):115.
[2] Francesco Ricci, Lior Rokach, Bracha Shapira, et al. Recommender systems handbook[M]. Berlin:Springer,2011:461-462.
[3] 王春才,邢晖,李英韬.个性化推荐系统冷启动问题研究[J].现代计算机(专业版),2015 (29):36-38.
[4] ZHANG J Y,PEARL P.A recursive prediction algorithm for collaborative filtering recommender systems[C]//Proceedings of the 2007 ACM Conference on Recommender Systems. ACM,2007:57-64.
[5] 周军锋,汤显,郭景峰.一种优化的协同过滤推荐算法[J].计算机研究与发展,2004,41(10):1842-1847.
[6] 覃玉冰,邓春林,杨柳.基于皮尔逊相关系数的网络舆情评估指标体系构建研究[J].情报探索,2018(10):15-19.
[7] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014(2):16-24.
(收稿日期: 2019.07.04)
