基于波动择时绩效的高维波动率估计量与预测模型研究
2020-06-23瞿慧,张壹
瞿 慧,张 壹
(南京大学工程管理学院,江苏 南京 210093)
1 引言
金融资产的高收益往往伴随着高风险,投资者经常通过构建包含多个资产的投资组合,达到分散风险和提高收益的目的。通过预测投资组合的协方差矩阵,投资者可以不断调整自己的资产配置,从而提高投资效益,这种动态的投资策略也称为是波动择时策略。Merton[1]指出,收益是难以预测的,而更为精确有效的是对多资产的协方差矩阵进行预测,因此对波动(协方差)估计量的构建及其预测模型研究十分重要。
在波动率的估计方面,Barndorff-Nielsen和Shephard[2]提出利用日内高频数据的已实现协方差矩阵(Realized Covariance, RC)。但是多维资产协方差的估计存在市场微观结构噪声、非同步交易以及协方差矩阵正定性等问题。目前能解决这三个问题的估计量包括Christensen等[3]提出的基于预平均方法的调整已实现协方差矩阵(Modulated Realized Covariance, MRC),及Barndorff-Nielsen等[4]提出的多元已实现核估计量(Multivariate Realized Kernel, MRK)。然而,上述估计量为了解决非同步交易问题,在资产维数较高且资产之间存在较大流动性差异时,会损失大量的数据信息。而Corsi等[5]新提出的卡尔曼滤波-期望最大化(Kalman Smoother and Expectation Maximization, KEM)算法,不但解决上述问题,而且能够利用所有的日内高频数据,信息利用效率较高。但Corsi等[5]主要数值验证了KEM估计量在统计意义精确度方面的优越性,对其应用于投资实务可获得的经济效益则没有详细分析。
目前在高维协方差矩阵预测中得到较多应用的,是估计较为简单的多元异质自回归模型(MultivariateHeterogeneous Autoregressive, MHAR)[6-7]和指数加权移动平均(Exponentially Weighted Moving Average, EWMA)模型[8-9]。实现最为简单,仅需对历史值进行算术平均的移动平均模型(Moving Average, MA)却并未得到足够的重视。仅Corsi等[5]利用单日MA模型预测KEM等估计量,比较了不同估计量用于最小方差投资组合的经济效益,但并未对MA模型本身的优劣进行实证检验。
在针对中国股市的协方差矩阵估计量研究中,赵树然等[10]通过对A股市场5只股票的实证,肯定了MRK和MRC估计量的降噪效果。在对(>2)资产的协方差矩阵估计量建模方面,刘丽萍[11]对沪深300指数6只大盘股的实证研究表明,MHAR模型在7种损失函数下都具有最优的预测能力,且显著超越使用日数据的DCC和BEKK模型;刘丽萍等[12]采用12只股票的实证研究也发现,该模型在统计和经济意义下都较优。瞿慧和纪萍[13]采用引入联跳的MHAR模型对上证50指数中5只不同行业的高流动性个股进行了协方差矩阵预测,发现同时引入联跳强度和联跳指示变量的模型在统计和经济意义上都是最优模型。
总的说来,目前国内对于高频数据下的波动率研究主要集中在一维,对于多维资产协方差矩阵估计和预测的研究还比较少。多维的研究也集中在较低的维数,和实务界构建高维资产组合的应用需求并不匹配。其主要原因还是前面提及的,现有协方差矩阵估计量在高维情况下,由于资产流动性的差异造成的数据大量丢弃、信息利用效率低下。因此,本研究从实务界构建高维资产组合的实际需求出发,以波动择时策略的绩效作为评价指标,对高维协方差估计量和预测模型的适用性进行研究。具体的,在协方差估计量的选择方面,首次将能够充分利用组合中各资产所有日内价格信息的KEM算法引入中国股市,构建高维协方差矩阵的KEM估计量。作为比较的估计量,则选择和KEM估计量一样,能够对非同步交易以及市场微观结构噪声稳健、确保协方差矩阵正定性的MRC估计量和MRK估计量。其次,考虑到协方差矩阵维度较高,预测模型选择实现较为简单的MHAR模型、EWMA模型,以及短、中、长期MA模型。本研究的创新之处,不仅在于KEM估计量在中国股市的首次应用,更在于首次从波动择时投资组合策略的绩效出发,对KEM估计量以及MA模型的优越性进行了实证分析。研究表明,KEM估计量统计意义上的精确度并不能完全对应到经济效益上的优越性。在各种市场情况下,使用KEM估计量都可以较MRC估计量和MRK估计量实现更低的成本,但仅在低波动情况下也可以实现最高的收益。研究也首次揭示,长期MA模型在各种市场情况下都是高维协方差估计量建模的最优选择,可以实现最高的收益和最低的成本。研究采用三种基于风险的投资组合策略,验证了上述结论的稳健性,并对不同市场情况下的最优波动择时方案(投资组合策略&协方差估计量&预测模型)做出了评价。
2 模型与方法
2.1 协方差矩阵估计量
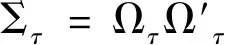
1)MRC估计量
Christensen等[3]提出的基于预平均方法的调整已实现协方差定义为:
(1)
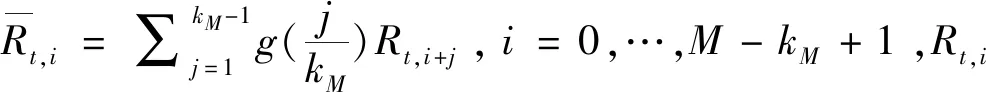
2)MRK估计量
Barndorff-Nielsen等[4]提出的多元已实现核估计量定义为:
(2)
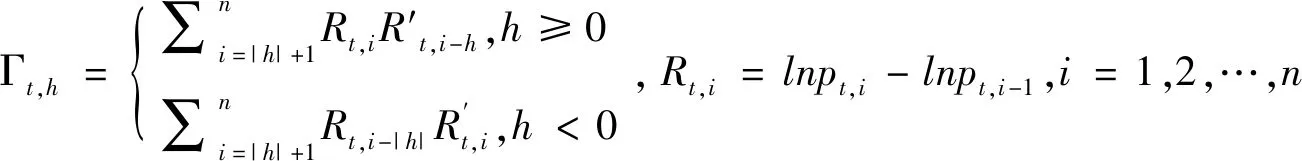
3)KEM估计量
假设布朗半鞅过程的漂移项μτ为0,则可以将布朗半鞅过程变换为状态空间模型:
Xτ=Xτ-1+ετετ~N(0,Q)
(3)
Yτ=Xτ+ητητ~N(0,C)
(4)
可利用EM算法结合卡尔曼滤波迭代,求解噪声矩阵C和瞬时协方差矩阵Q。其思想是利用极大似然法对模型中的未知参数进行迭代估计,最终在似然函数值趋于稳定时得到参数估计值。本文将迭代的初始值设置为单位矩阵,需要说明的是,初值选取只会影响程序收敛的速度,不会影响最终的收敛值。第k+1次迭代的参数估计值为[5]:
(5)
(6)
2.2 协方差矩阵预测模型
本文采用三种易于实现的协方差矩阵预测模型,MHAR模型、EWMA模型和MA模型,它们都能在不施加约束条件的情况下保证预测矩阵的正定性。
1)多元异质自回归(MHAR)模型
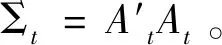
(7)
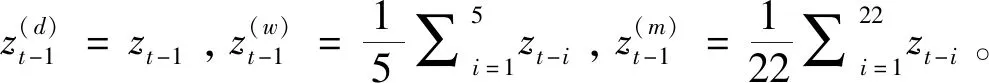
2)指数加权移动平均(EWMA)模型
该模型由Fleming等[16]提出,通过当期预测值与真实值的加权得到下一期预测值:
(8)
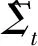
3)简单移动平均(MA)模型
这一模型属于最简单的预测模型,它将一段历史时期内协方差矩阵的算术平均值作为下一投资日的协方差预测值,不需要进行参数估计。按照历史区间长度可以分为长期、中期和短期移动平均模型:
(9)
其中h可以取1,5,22,分别对应单日(短期)、一周(中期)、一月(长期)移动平均。
2.3 基于风险的投资组合策略
采用三种基于风险的投资组合评价协方差预测效果,分别为等风险贡献(Equal Risk Contribution,ERC)投资组合、最小方差投资组合(Global Minimum VariancePortfolio, GMVP)以及最大化分散投资组合(Most DiversifiedPortfolio, MDP)。
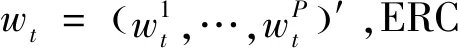
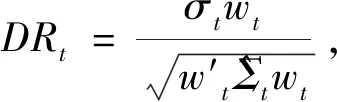
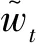
3 数据与实证
实证采用上证50指数20只不同流动性成分股的逐笔数据。样本区间为2014年1月2日至2018年8月31日,共1121个交易日。其中样本外预测区间为2015年1月5日至2018年8月31日,共885个交易日。采用一步向前滚动窗估计,第一个估计窗为2014年1月2日至2014年12月31日,共236个交易日。
3.1 数据处理
首先对逐笔交易数据进行数据清洗,具体步骤为:(1)删除交易时刻在9:30~11:30及13:00~15:00范围之外的数据,删除交易价格为0的数据;(2)如果同一个时间戳有多个交易数据记录,则采用中位数价格;(3)对数据进行1秒采样;(4)对交易价格取对数,计算对数收益率并将位于其均值加减三倍标准差区间外的观测值识别为跳跃并剔除。
在此基础上,构建三种协方差估计量。鉴于篇幅限制,本文仿照Corsi等[5],节选协方差矩阵中的部分元素,对KEM、MRC和MRK估计量的走势进行画图比较。为不失结果的一般性,选取两只流动性较好的股票(中信证券和中国平安)和流动性较差的股票(光大证券和贵州茅台)。分别画出流动性好的股票中信证券的方差走势图、流动性差的股票贵州茅台的方差走势图、流动性好的股票中信证券和中国平安的协方差走势图、流动性差的股票光大证券和贵州茅台的协方差走势图以及流动性好的股票中信证券和流动性差的股票贵州茅台的协方差走势图,结果见图1至图5。
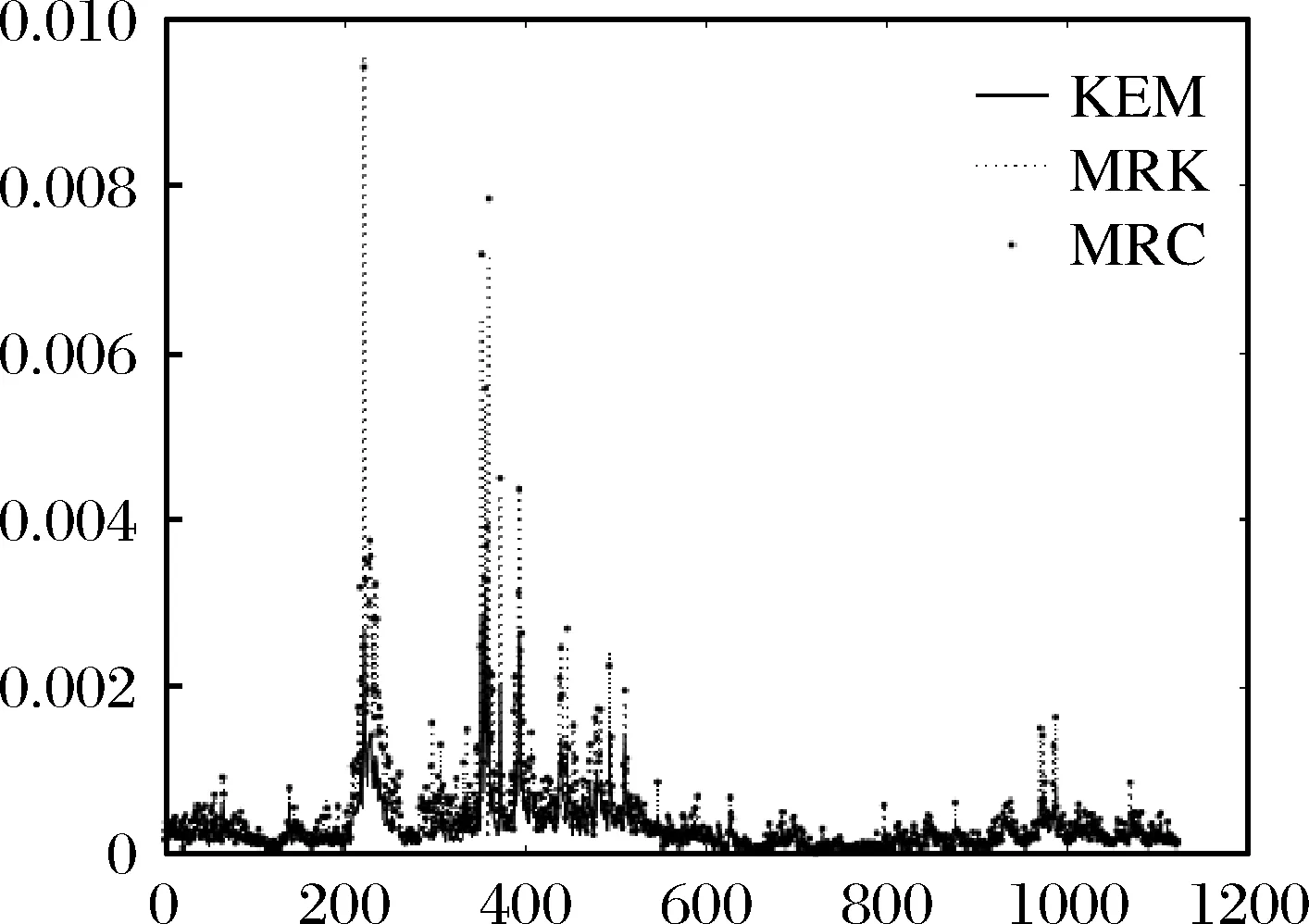
图1 中信证券的方差走势图
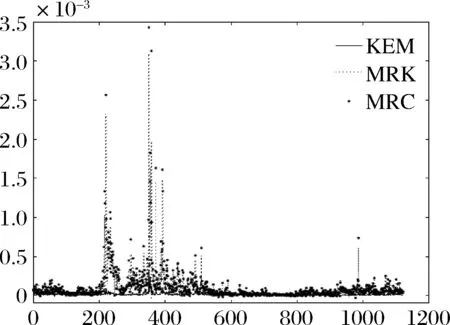
图2 中信证券和中国平安的协方差走势图
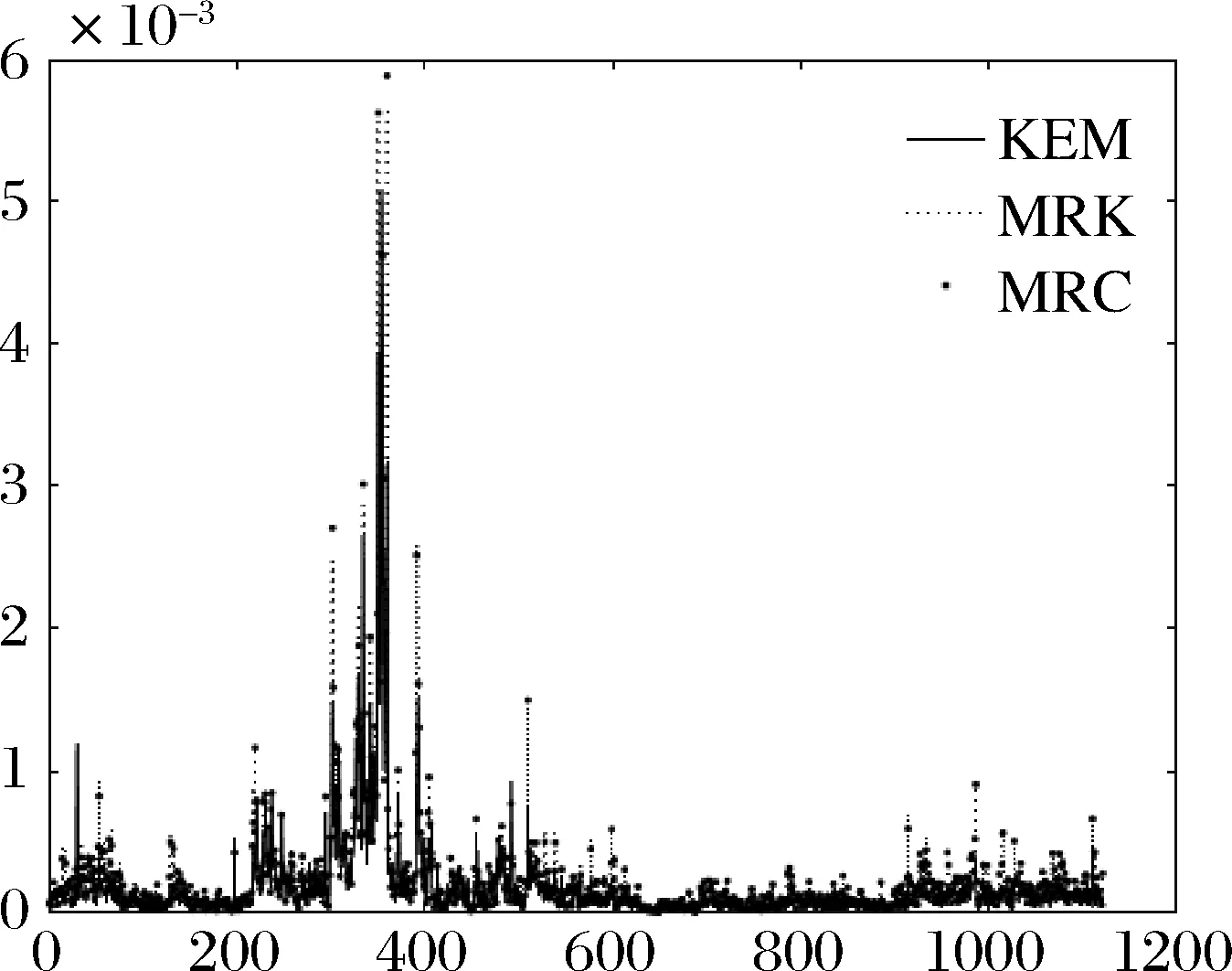
图3 贵州茅台的方差走势图

图4 贵州茅台和光大证券的协方差走势图
可以看到,在各种情况下,MRK和MRC估计量的走势基本相同,而相比之下,KEM估计量则更为平滑,尤其是协方差元素部分。这一结果也与Corsi等[5]在美国市场的结果一致。因此,在波动走势较为平稳的低波动区间,MRK和MRC估计量相较于KEM估计量可能存在高估波动水平的情况,而在波动水平较高的高波动区间,KEM估计量则可能存在低估波动水平的情况。我们因此预期,在市场平稳时期,KEM估计量能更恰当地反映波动走势,运用于预测模型构建时也有更好的绩效;而在市场剧烈震荡期,MRC和MRK估计量则更为合适。
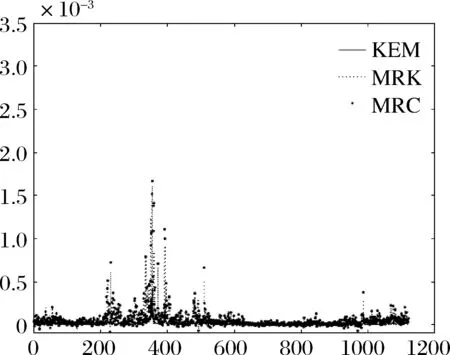
图5 中信证券和贵州茅台的协方差走势图
3.2 经济意义评价
分别将三种协方差矩阵估计量运用于MHAR模型、EWMA模型和短、中、长期移动平均模型,在2015年1月5日至2018年8月31日的样本外区间进行一步向前预测。得到协方差矩阵的样本外预测值后,利用三种投资组合策略,计算每日的投资组合权重,进而计算相应的经济效益指标,汇总于表1中。
从估计量来看,无论采用何种预测模型,无论采用何种投资组合方法,KEM估计量得到的平均周转率都最低,但是组合净收益率均值和夏普率并不总是占优。周转率指标衡量了对投资组合进行调仓的程度,决定着成本大小。Pooter等[9]指出波动择时策略需要每日调整组合权重,因此交易成本是其中需要重点考虑的一个因素。
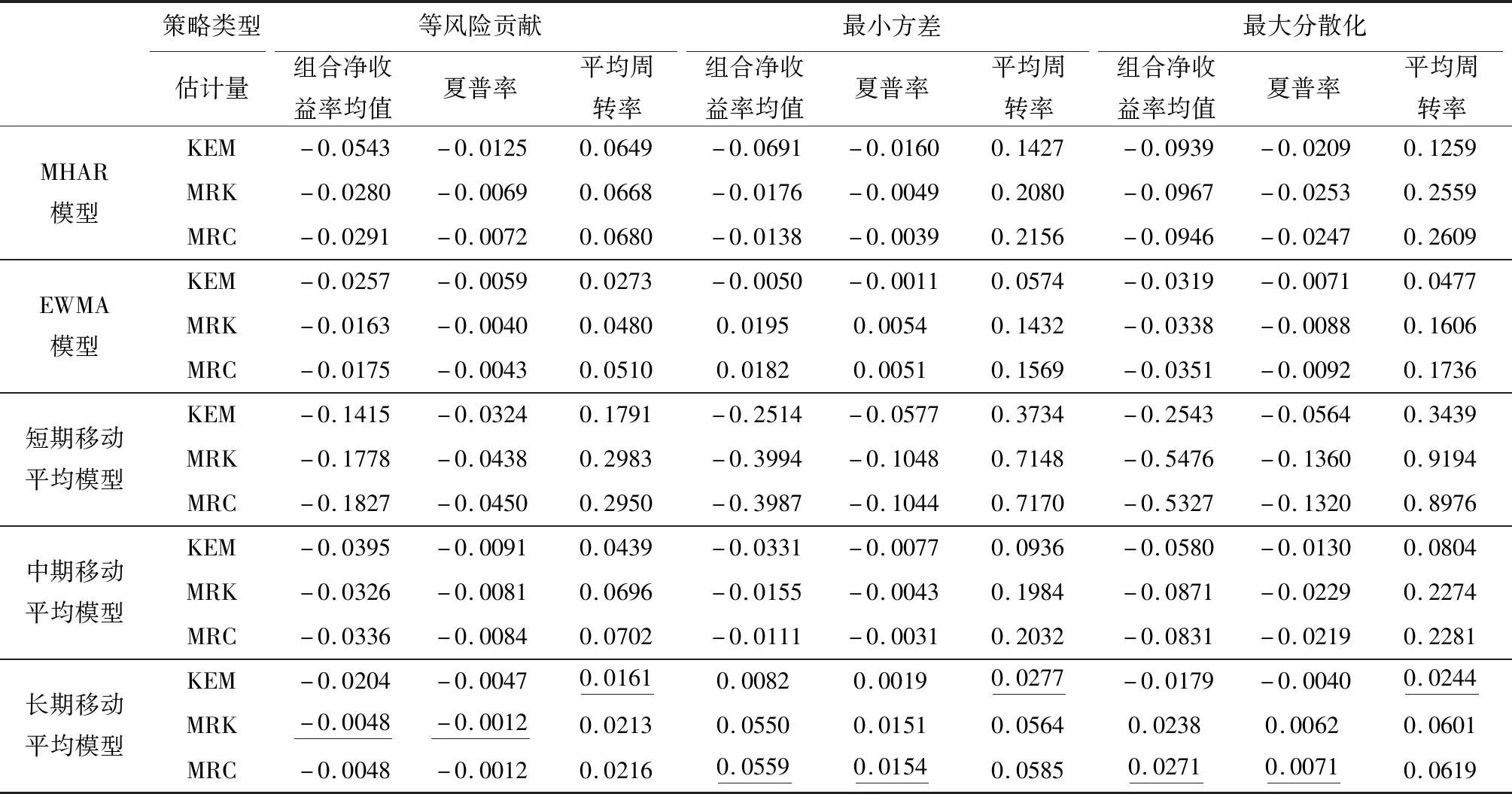
表1 完整区间样本外预测的投资组合策略绩效
从预测模型来看,无论采用何种投资组合方法,无论采用何种估计量,长期移动平均模型得到的组合净收益率均值和夏普率明显最高、周转率明显最低。因此在五种预测模型中,长期移动平均模型占显著优势。这也与Clements和Silvennoinen[17]对美国市场三资产的实证结论一致,即长期移动平均模型可以得到与复杂的时间序列模型相近的经济效益结果。
此外,比较不同投资组合策略下的最优绩效可以发现,最高的组合净收益率均值和最高的夏普率都是在采用最小方差投资组合时实现的,采用的是MRC估计量和长期移动平均模型;最低的平均周转率则是在采用等风险贡献投资组合时实现的,采用的是KEM估计量和长期移动平均模型。
3.3 稳健性检验
为检验上述结论在不同市场情况下的稳健性,利用Ross等[18]提出的非参数变动点模型(Nonparametric Change Point Model, NPCPM)将样本外预测区间进行分段,并进行分区间检验。具体的,用NPCPM对上证50指数在预测区间的已实现波动进行断点识别,区分为2015年1月5日至2016年5月19日的高波动区间和2016年5月20日至2018年8月31日的低波动区间,其中高波动区间包含了2015年的股灾。图6给出了上证50指数已实现波动在预测区间的走势图和断点识别结果。接着,分别在高波动区间和低波动区间内进行检验,结果见表2和表3。
图6 上证50指数已实现波动2015年1月5日至2018年8月31日的走势图

表2 高波动区间(2015.1.5-2016.5.19)样本外预测的投资组合策略绩效
由表2可见,在高波动区间,从估计量来看,无论采用何种预测模型,无论采用何种投资组合方法,KEM估计量得到的平均周转率几乎都是最低,但是组合净收益率均值和夏普率几乎不占优。这是因为相较于MRK估计量和MRC估计量,KEM走势更为平滑,无法在高波动情况下更好地捕捉波动的变化。
从预测模型来看,无论采用何种投资组合方法,无论采用何种估计量,依然是长期移动平均模型得到的组合净收益率均值和夏普率最高、平均周转率最低。因此在五种预测模型中,长期移动平均模型占显著优势。
此外,比较不同投资组合策略下的最优绩效可以发现,最高的组合净收益率均值和最高的夏普率都是在采用最小方差投资组合时实现的,采用的是MRC估计量和长期移动平均模型;最低的平均周转率则是在采用等风险贡献投资组合时实现的,采用的是KEM估计量和长期移动平均模型,这和表1的结论是一致的。

表3 低波动区间(2016.5.20-2018.8.31)样本外预测的投资组合策略绩效
由表3可见,在低波动区间,从估计量来看,无论采用何种预测模型,无论采用何种投资组合方法,KEM估计量得到的平均周转率都是最低的,而且比起高波动区间,KEM估计量的组合净收益率均值和夏普率在大部分情况下都优于MRK估计量和MRC估计量,具有明显优势。这说明从波动择时绩效来看,KEM估计量更适用于较为平稳的市场。这与我们基于图1-图5的分析是一致的,其原因在于KEM估计量的走势更为平滑,能够更好地反映市场平稳时期的实际波动情况。
从预测模型来看,无论采用何种投资组合方法,无论采用何种估计量,依然是长期移动平均模型得到的组合净收益率均值最高、夏普率最高、平均周转率最低。因此在五种预测模型中,长期移动平均模型占显著优势,这与完整区间以及高波动区间的结论一致。
此外,比较不同投资组合策略下的最优绩效可以发现,最高的组合净收益率均值和最高的夏普率仍都是在采用最小方差投资组合时实现的;最低的平均周转率还是在采用等风险贡献投资组合时实现的。且这些最优波动择时方案使用的都是KEM估计量和长期移动平均模型。
总体来看,无论是在市场剧烈震荡期(高波动区间)还是市场平稳时期(低波动区间),长期移动平均模型都是高维协方差估计量预测建模的最优选择,在应用于各种波动择时策略时都可以实现最低成本和最高收益。在市场平稳时期,KEM估计量是高维协方差估计的最优选择,应用于各种波动择时策略时基本都可以实现最低成本和最高收益。在市场剧烈震荡期,使用KEM估计量进行波动择时仍然可以在成本方面保持优势,但在收益上并不占优。此外,无论是在市场剧烈震荡期还是市场平稳时期,最低的成本都是在采用等风险贡献投资组合时实现的,而最高的收益则都是在采用最小方差投资组合时实现的。
4 结语
考虑到针对中国股市的高维波动率估计及预测研究较为缺乏,无法指导投资者构建高维资产组合的实务应用这一问题,提出从波动择时策略绩效的角度,对高维协方差估计量和预测模型的适用性进行研究。具体的,将信息利用效率较高的KEM估计量引入中国市场,并将同样能够对非同步交易以及市场微观结构噪声稳健、确保协方差矩阵正定性的MRC估计量和MRK估计量纳入比较。考察三种协方差估计量与实现较为简单的MHAR模型、EWMA模型,及短、中、长期移动平均模型结合,应用于三种基于风险的投资组合策略下实现的经济意义指标。研究发现:
①无论采用何种投资组合策略及协方差估计量,无论市场处于平稳亦或震荡时期,长期移动平均模型下得到的经济意义指标在五种预测模型中都是显著最优。可见高维协方差矩阵的预测未必要使用复杂的时间序列模型,无须参数估计的长期移动平均模型在中国股市更具实用性。
②在低波动市场环境下,无论采用何种投资组合策略及预测模型,采用KEM估计量都可以实现明显更优的成本和收益。可见KEM估计量在市场平稳时期是高维波动率估计的最优选择。而在高波动市场环境下,采用KEM估计量虽然仍能确保实现更优的成本,但在收益方面相比于采用MRK估计量和MRC估计量并不占优。这也表明协方差估计量统计意义上的精确度并不能完全对应到经济效益上的优越性,本文基于波动择时策略绩效视角的研究以及区分市场波动情况的分析具有实际意义。
本文在高频数据下进行高维协方差矩阵估计和预测的初步研究,以此为基础可以进一步拓展的研究方向包括:(1)鉴于更新时间采样方法在高维资产下数据信息丢失的问题,采用Hautsch等[19]提出的分块正则化方法对高维矩阵进行处理,进而与KEM估计量进行比较;(2)在MHAR模型中加入联跳强度等外生变量,进而与长期移动平均模型进行比较。这是我们下一步的研究方向。
