藏文自动组卷系统中试题消重方法研究
2020-06-04德格加
德格加

摘 要: 在计算机自动组卷系统中,试卷中试题的互异性是评价自动组卷系统性能的一个重要指标,而试题的互异性或相似度是由多个参数共同决定的。根据藏文试题的结构特点,提出了一种试题相似度的计算方法,力求提升自动组卷系统的组卷性能。
关键词: 自动组卷; 藏文试题; 相似度; 组卷性能
Abstract: In the automatic test paper system, the test paper's mutuality is an important index to evaluate the performance of the system, and the test paper's mutuality or similarity is determined by multiple parameters. According to the structural characteristics of test paper in Tibetan, a method of calculating the similarity of questions in test paper is proposed to strive to improve the performance of automatic test paper system.
Key words: automatic generating of test paper; test question in Tibetan; similarity; performance of test paper generating
0 引言
随着计算机技术的迅速发展,各种计算机辅助教学软件相继开发问世,作为教学辅助系统中最重要的组成部分,试题管理和组卷系统是人们研究的重要领域之一,在日常教学活动中发挥着积极的作用[1]。而评价一个组卷系统的性能不仅考虑整个系统的组卷效率、试卷的适应度,系统的健全性和可扩展性,还需考虑一个最重要的指标,即试卷中试题的互异性。
1 重复试题的消重法
理工科类试题的题型具有多样性,有纯文字叙述,有图形,有表格,以及多种形式混合等多种出题形式。文字叙述中以数学式子和专业符号居多,而且数学式子和符号是用专用的软件编辑的[2],这对利用计算机处理该类试题增加了很大难度。在自动组卷系统中试题之间的相似性是通过试题的各属性的相似度来综合评定的,本文通过试题关键词的相似度、试题所含知识点和题型三个指标的相似度来综合评定试题的相似度,具体计算公式如下:
2 试题关键词的相似度Txtsim的计算方法
2.1 试题题干预处理
试题关键词的相似度计算中首先對试题中的文字描述性内容进行分词处理,文章中所采用的分词算法是基于字典的机械分词算法—双向匹配分词方法,该分词算法的优点是分词效率高,易于实现,而缺点也是很明显的,分词准确性依赖于分词字典,字典的完备性直接影响分词性能[3],所以传统的分词字典已无法满足对这类文本的分词要求,需要用专用的分词词典或对分词词典进行扩充。根据该方法对“
双向分词中如果正向和逆向的分词结果一致,则选用其中任意一个结果作为该词串的最终分词结果。若正向和逆向的分词结果不相同时,采用最大概率的方法计算P(W1)和P(W2)后,选用其中较大概率的分词结果,即。具体概率计算公式如下:
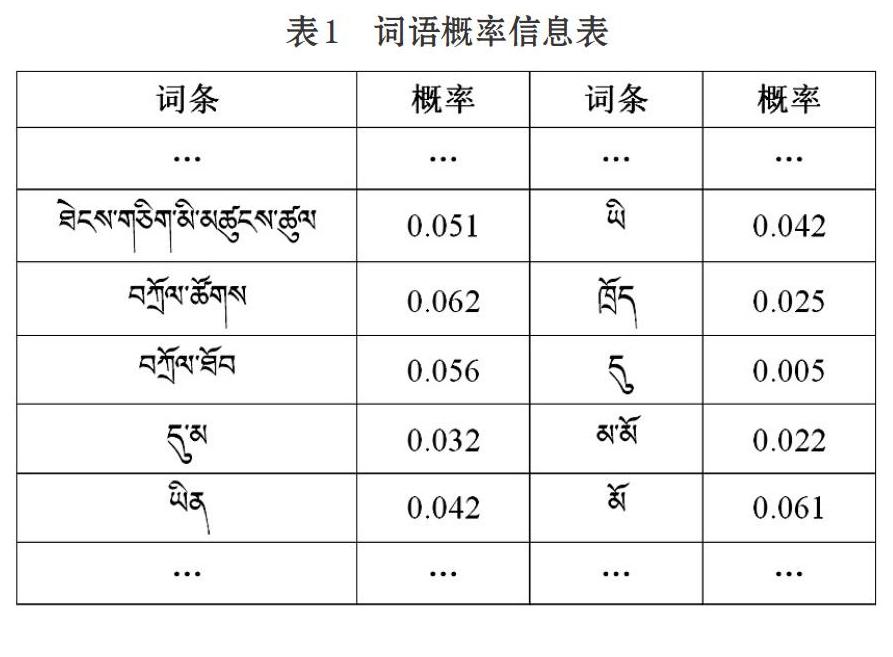
根据式⑷计算字典中各词条的频率,将计算结果存入词典中,即分词词典中不仅包含各词条(包括扩充的词条),还包含各词条的频率,分词词典的结构见表1。
2.2 试题相似度技术分析
公式⑸计算两文本的相似性时只考虑了特征词的频率,有时候得出的相似度结果不准确,如表2中所列出的试题的关键词为例,通过该公式计算得出试题Q2和Q3的相似度约为0.95,但这两道题的关键词分布极不均衡,只有一个公共关键词,计算结果与实际差距较大,因此为了避免出现此类情况,在对传统的相似度计算公式稍作了修改了改进。
其中表示试题Q1和Q2中共有的关键词个数,表示试题Q1和Q2中关键词较少的试题的关键词个数,,这样新公式中增加了乘项,也就是公式⑹在计算两试题的相似度时既考虑关键词的词频,也考虑了关键词分布对文本相似性的影响因素。通过新公式计算表2中的试题Q2和Q3的相似度为0.47,这个结果跟实际更接近一些。
3 试题知识点相似度KPsim的计算方法
一般而言,试题的相似度不仅跟试题中的关键词有关,也跟试题中知识点的相似度有关,如果两个试题中所考的知识点完全一样,则即使题型,关键词不同,我们都将其划为同类试题。本文通过式⑺来计算试题知识点的相似度,若两个试题q1和q2中所含知识点的集合分别为Q1和Q2,则两个的相似度用两个集合的交集和并集的比值来衡量,即:
4 小结
本章分析了藏文试题自动组卷系统中所涉及到的最底层的处理技术,为了保证组卷的质量和性能,避免在同一试卷中出现相同试题的情况,在组卷过程中计算机对选中的试题间进行相似性的比较,所以本章主要分析了试题相似性检验所用到的分词和试题相似度的计算方法。分词中采用了基于字典的分词方法,为了分词结果更准确,符合数学等专业等学科的分词标准,文中对分词词典做了相应的扩充。试题相似度计算中采用向量模型的文本相似度计算方法,并对传统的文本计算公式中增加了特征词分布影响因素,得到了一个新的计算试题相似性的计算公式,该公式能有效避免相似度低的试题干扰。
参考文献(References):
[1] 王友仁.题库系统智能成卷理论和组卷方法研究[J].电子科技大学学报,2014.6.
[2] 才项俄日,张有谊.藏语文试卷的智能生成研究与实现[J].电脑与信息,2015.6.
[3] 祁坤钰.藏文分词与标注研究[M].甘肃民族出版社,2015.
[4] 洛桑嘎登.藏文自动分词与词性标注研究[D].中央民族大学硕士论文,2016.
[5] 李连,朱爱红,苏涛.一种改进的基于向量空间文本相似度算法的研究与实现[J].计算机应用于软件,2012.2.
[6] 邬明强.基于分段融合的藏文文本相似度计算方法研究[D].西北民族大学,2016.
