基于nGram2vec与词义演化的词相似度计算方法
2020-05-25汪玉珠王永滨
汪玉珠 王永滨


摘 要:词相似度计算在文本分类等自然语言处理众多任务中有广泛应用,为了提高准确率并将其应用于文本分类任务中,提出基于知网与同义词林以及基于nGram训练大规模语料相结合的方法,通过词义演化技术检测词义变化确定两种方法的权重,利用皮尔逊相关系数对比人工定义词语相似度。通过实验将该方法与基于知网和同义词林的方法进行对比,根据随时间改变而词义有无变化选取15对词语进行测试,结果表明后者比前者提高了28%。由此可以看出,基于语料与语义词典的方法明显比单纯基于语义词典的方法好,但仍有较大改进空间。
关键词:词相似度;nGram2vec;同义词林;知网;词义演化
DOI:10. 11907/rjdk. 192354 开放科学(资源服务)标识码(OSID):
中图分类号:TP301文献标识码:A 文章编号:1672-7800(2020)002-0096-04
英标:Word Similarity Calculation Method Based on nGram2vec and Word Meaning Evolution
英作:WANG Yu-zhu1,2,WANG Yong-bin1,2
英单:(1. School of Computer and Cyberspace Securit, Communication University of China;2. Key Laboratory of Smart Fusion Media of Ministry of Education,Communication University of China,Beijing 100024,China)
Abstract: Word similarity calculation is widely used in many tasks such as text classification and natural language processing. In order to improve the accuracy and apply it in text classification tasks, this paper proposes a method which combines of HowNet and synonym forest and nGram training based on large-scale corpus. The word meaning evolution technique is used to detect the change of word meaning to determine the weight of the two methods. The Pearson correlation coefficient is used to compare the similarity of the word. The experiment compares the method based on HowNet and the same word forest and the method proposed in this paper. The experiment tests 15 pairs of words according to the change of meaning with time. The result shows that the latter is increased by 0.28 than the former. It can be seen that the method based on corpus and semantic dictionary is obviously better than the method solely based on semantic dictionary, but there is still much room for improvement.
Key Words: word similarity; nGram2vec; synonym forest; HowNet; word meaning evolution
0 引言
詞语相似度方法被广泛应用于信息检索、词义消歧、机器翻译等自然语言处理(Natural Language Processing,NLP)任务中。词是NLP任务的最小词义单位,词义理解是NLP任务中最为基础的研究,自然语言的词语之间有很复杂的关系,而词语相似度是对词语间复杂关系的量化。目前,词语相似度计算方法主要分为两类[1-3]:①基于语义资源的方法,其根据知网等语义词典的结构设计算法计算词相似度,是词相似度计算的重要依据[4-7];②基于统计的方法,其借助包含有词的语境的大规模语料库,根据词间信息量或词共现频率计算词语相似度[8-9],这种方法假设语义相似的词语之间具有相似的上下文信息,比较客观。
基于语义资源的方法,虽然经过语言专家确定,但受主观影响大,有时不能反映客观事实,虽然几乎包含了所有能用到的词,但是更新比较缓慢,而且随着信息时代的发展,会出现很多新词或者有的词义发生变化,这是同义词林和知网不能及时捕捉的。而基于语料库的方法,可以很容易捕捉到已经发生变化的词义(可能是部分变化也可能是完全变化)并能获取与之相似的词,这种方法由于语料的限制不可能统计到所有的词,但能获取经常用到的词,并且能捕捉到新词。基于此,本文提出基于nGram2vec[10]与基于同义词林和知网相结合的方法,将它们以权重方式结合,而权重设定的主要依据是词义演化技术得到词义变化与词的使用频率。主要思路是根据这两种方法分别求出词相似度,然后通过词义演化技术检测词义变化,以确定两种方法的权重,考虑词义可能完全变化、完全没有变化、部分变化(词义的义项增加或减少了),以及通过统计得到词的使用频率,通过使用频率可以知道一些发生部分词义变化的词,并发现哪种词义使用更多。
具体方法分4步:①根据朱新华等[5]基于知网和同义词林求相似度的方法,其思路是赋予两种方法权重,权重之和为1,如果词在某一词典中,则基于此词典的方法权重为1,如果都存在,权重都为0.5,如果都不存在,则表明词不存在,直接返回相似度为0;②采用Zhao等[10]提出的nGram2vec模型训练词向量,实验表明在语义相似度方面其性能和准确性较已知的Word2vec[9]等效果更好;③通过Hamilton等[12]提出的动态词嵌入模型训练得到词义演化过程,进而发现词义变化;④通过词义变化和词频共同权重最终求出词语相似度。实验结果表明,两种方法结合比单独求出的结果有很大提升,在本文对比实验中提升了28%。
1 相关工作
基于语料库的方法比较客观,但依赖训练的语料库,受数据稀疏和噪声影响较大,基于语义资源的方法虽然简单有效但受主观影响较大,且更新缓慢,不能及时展现快速变化的词义,目前也有一些研究者将两种方法相结合进行研究。魏韡等[13]提出有向无环图和内在信息量相结合的方法,其主要是从量上加以考虑;蔡东风等[14]提出基于语境和知网的词语相似度算法,通过计算词语上下文信息的模糊重要度,对数据噪声加以改进;詹志建等[15]提出了基于百度百科的计算方法,将其既作为语义资源又作为语料,通过基于词典的方法和基于语料库的常用方法空间向量模型计算相似度。通过分析,将这两种方法结合,能在一定程度上弥补各自不足,得到与客观实际符合程度更大的词语相似度。提出将语义资源和语料库与词义演变过程相结合。通过这种方式可以从更细粒度上提升准确度,包括未被收录的、词义发生各种变化(词义范围扩大缩小、词义色彩变化、新词义出现旧词义消失)的词语,可从多方面计算词相似度。
2 方法
2.1 基于知网
知网中最主要的概念是义原,描述概念的基本单位,一般一个义原有多种解释,每种解释就是一个词义,即义项,每种词义也有多个义原,知网描述了每个词义多个义原间的关系,是一部非常详尽的语义词典。基于知网的上述优势,部分学者进行了基于知网的词相似度计算[16-18]。
根据文献[5]将义项相似度计算转换为对独立义原集合、关系义原特征结构与关系符号义原特征结构的相似度计算,义项相似度计算如式(1)所示。
其中,参数[βi(1i3)]是可调节的,且满足:[β1+β2+][β3=1,][β1β2β3],[βi]值按照文献[5]设置。有的词会有多个义项,两个词的最终相似度如式(2)所示。
2.2 基于同义词词林(词林)
词林参考了多部词典,人民日报语料库中的词频虽然只保留了频度超过2的部分词语,但能够提供较多的同义词语,是一部具有汉语大词表的词林,采用基于类构建的分层结构[19]。文献[5]提出了一个以词语距离[d]为主要影響因素、以分支节点数[n]和分支间隔[k]为调节参数的词相似度计算公式,如式(3)所示。
将不属于同一个大类的词语间的距离都处理为18,同时按从底层到高层的顺序,将连接上、下两层的四大类边分别赋予一个权重[Wi(1i4)],且满足:[0.5W1W2][W3W45,W1+W2+W3+W410]。
2.3 Ngram2vec
深度学习方法已经在一系列NLP任务上取得了最新成果[20],其中最基础的工作之一是词嵌入,经过训练的单词嵌入能够反映单词语义和句法信息。其不仅有助于揭示词汇语义,还可用作各种下游任务的输入以获得更好的性能。Word2vec以其惊人的效率而广受欢迎。Levy等[21]进一步揭示了词嵌入的特性,发现其并不局限于Word2vec等神经网络模型,使用传统基于计数的方法(PPMI矩阵和超参数调整)表示单词,也获得了良好效果。由于Ngram是语言建模的重要组成部分,因此Zhao等[10]受到启发,提出了一种构建Ngram共生矩阵的新方法。该方法尽可能地减少了磁盘I/O,大大减轻了Ngrams带来的成本,并获得了更好的性能。他们将Ngrams引入SGNS(负抽样的Word2vec/skip-gram),在文本相似度任务上取得了较好的效果。
2.3.1 SGNS
其输入是原始语料[T={w1,w2,?,wT}],设[W]和[C]表示单词与上下文词汇,[θ]是待优化参数。SGNS的参数包括两部分:字嵌入矩阵和上下文嵌入矩阵。嵌入[w∈Rd]时,参数总数为[(|W|+|C|)?d]。SGNS的目标函数是最大化中心词上下文的条件概率,如式(4)所示。
其中,[C(wt)={w,t-winit+win and i≠t},win]表示窗口大小。负采样(Negative Sampling) 用来近似表示条件概率,如式(5)所示。
其中,[σ]表示Sigmoid函数,[c1,c2,?,ck]是[k]个样本,从上下文分布提取。
2.3.2 SGNS with nGram
其与SGNS的区别在于采用不一样的[C(w)],如式(6)所示。
其中,[wi:i+n]表示nGram[wiwi+1...wi+n-1]N是上下文nGram顺序,使用词与nGram 远端单词之间的距离表示中心词和上下文nGram之间的距离。此模型允许词与nGram重叠,在重叠情况下,nGram用作上下文,即使包含中心词,在非重叠情况下,这些Ngrams也被排除在外。在训练期间,中心Ngrams(包括单词)预测它们周围的Ngrams,中心词nGram预测上下文nGram,如式(7)所示。
[C(wt:t+nw)]的定义如式(8)所示。
因此,模型中词嵌入不仅受上下文nGram的影响,而且间接受语料库中nGram类型共现统计影响。
2.4 词义演化
词义随着时代发展而不断变化和丰富,词义演化技术有助于更好了解词义的演化过程,包括词义褒贬色彩变化、新词义出现和旧词义消亡、词义范围扩大和缩小等[22],比如“粉丝”一词之前表示一种食品,后来增加了一个义项,表示追星族。Hamilton等[12]提出了一种用于量化语义变化的方法,通过评估单词嵌入(PPMI、SVD、SGNS即Word2vec)揭示语义演化的统计规律,文中使用6种历史语料库,涵盖4种语言(中文、英语、德语、法语),跨越两个世纪,做了大量对比试验,最终选择使用SGNS 嵌入,它能更好地估计频率和语义变化之间的关系。
有两种方法量化语义变化:①测量成对词语相似性如何随时间变化;②测量单个词的嵌入如何随时间变化。
3 實验
3.1 数据集
nGram2vec训练语料是百度百科,它已经收录了近 1 600万个词条,相比通常所用的训练语料维基百科量级要大,几乎涵盖了所有已知知识领域。词义演化部分的语料除文献中包含1950-1990年的语料外[23],还有新闻语料[24],新闻内容跨度为2014-2016年,涵盖了6.3万个媒体。其中涉及1998年人民日报语料[25],它是由北京大学计算语言学研究所和富士通研究开发中心有限公司共同制作的标注语料库,此外还包括最有可能产生新词义的新浪微博与今日头条,抓取数据时间段为2017-2019年。
3.2 实验与分析
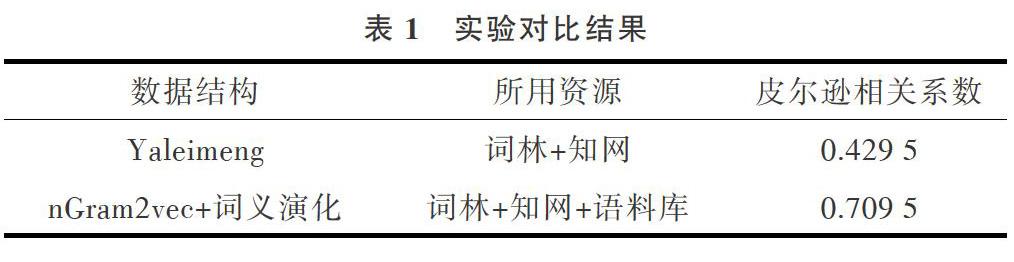
将本文方法与文献[5]方法进行对比。实验流程为:①将获取的百度百科语料、微博、今日头条数据合并用Jieba进行分词,然后统计词频;②用nGram2vec训练语料得到词向量与词相似度a;③获取基于词林和知网的词相似度b;④用文献[12]训练含时间的数据得到随时间变化的词向量与词间相似度;⑤根据词频与随时间变化的词向量,确定a和b的权重,计算最终词相似度;⑥计算各种方法与本文方法的皮尔森相关系数。
测试的词包含词义基本未变、部分变化、完全变化、现在不怎么使用,以及新产生的词,共选取15对词进行测试。
表1中的Yaleimeng[26]是实现文献[5]的方法,其项目中用词林+知网时得到的皮尔森系数是0.885,因为所用的测试词的词义基本未发生变化。在本试验中基于词典的方法结果仅为0.429 5,原因是词典中很多词的词义都没有,导致本该很相似的词用此种方法计算相似度很低。Yaleimeng项目一直在更新词库,但是其并不统计每种词义下的词频,基于词典的方法本身默认每种词义使用频率相同,但事实上某些词的词义用得更频繁,该特性在基于统计的模型中容易实现,这也使得本文方法在基于词典的基础提升了28%。
nGram2vec是一个概率模型,一句话(一个词的上下文)出现的概率越大就越接近人类语言,相似词在同一上下文出现的概率越相近,两个词的词义就越相似,这一点弥补了上文提到的基于词典的缺陷。在现代信息环境下,词义变化基本上都能在互联网中被发现,nGram2vec模型就很容易捕捉到,但知网等语义词典不具备上述功能。
词义演化模型将两者优势结合起来,可以检测出变化词义的词,如果词义未发生变化,则直接赋予基于词典计算出的相似度权重为1,如果词义完全变化或者是新产生的词,其权重为0。但本实验结果显示皮尔逊相关系数并不太高,因为本文方法只是通过权重将两种方法结合在一起,还有很多改进之处。
4 结语
本文通过词义演化技术计算词义变化,并结合基于语义资源和语料库的方法计算词语相似度,充分利用了语义资源在绝大部分词义方面的专业性,弥补了语料库中很多非常用词的缺陷,充分利用基于语料库的方法计算新词、词义有变化词的词义相似度,得到了更为准确与合理的结果。本实验将两大类方法通过权重方式相结合,权重由词义变化和词的各词义使用频率确定,但是融合得不够完美,使模型看起来不太坚固。未来将使用仍在改进且已经被应用于各NLP任务中的贝叶斯,将语义资源作为先验知识嵌入到基于语料库的方法中,这样可以使模型更坚固,并且更符合人类的贝叶斯理论思维习惯。
参考文献:
[1] 李慧. 词语相似度算法研究综述[J]. 现代情报,2015,35(4):172-177.
[2] 刘萍,陈烨. 词汇相似度研究进展综述[J]. 现代图书情报技术,2012,28(7):82-89.
[3] 韩普,王东波,王子敏. 词汇相似度计算和相似词挖掘研究进展[J]. 情报科学,2016,34(9):161-165.
[4] 刘群,李素建. 基于《知网》的词汇语义相似度计算[J]. 中文计算语言学,2002.
[5] 朱新华,马润聪,孙柳,等. 基于知网与词林的词语语义相似度计算[J]. 中文信息学报,2016, 30(4).
[6] 吕立辉,梁维薇,冉蜀阳. 基于词林的词语相似度的度量[J]. 现代计算机(下半月版),2013(1):3-6.
[7] 吴思颖,吴扬扬. 基于中文WordNet的中英文词语相似度计算[J]. 郑州大学学报(理学版), 2010, 42(2):66-69.
[8] 吕亚伟,李芳,戴龙龙. 基于LDA的中文词语相似度计算[J]. 北京化工大学学报(自然科学版), 2016,43(5):79-83.
[9] MIKOLOV,TOMAS.Efficient estimation of word representations in vector space[DB/OL]. https://arxiv.org/abs/1301.3781,2013.
[10] ZHAO Z, LIU T, LI S,et al.Ngram2vec: learning improved word representations from ngram co-occurrence statistics[C]. Conference on Empirical Methods in Natural Language Processing,2017.
[11] PETERS M E,NEUMANN M,IYYER M,et al. Deep contextualized word representations[DB/OL]. https://arxiv.org/abs/1802.05365,2018.
[12] HAMILTON W L,LESKOVEC J,JURAFSKY D. Diachronic word embeddings reveal statistical laws of semantic change[C]. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics,2016.
[13] 魏韡,向阳,陈千. 计算术语间语义相似度的混合方法[J]. 计算机应用, 2010,30(6):1668-1670.
[14] 蔡东风,白宇,于水,等. 一种基于语境的词语相似度计算方法[J]. 中文信息学报, 2010,24(3):24-29.
[15] 詹志建,梁丽娜,杨小平. 基于百度百科的词语相似度计算[J]. 计算机科学, 2013,40(6):199-202.
[16] 朱征宇,孙俊华. 改进的基于《知网》的词汇语义相似度计算[J]. 计算机应用,2013,33(8):2276-2279.
[17] 朱新华,郭小华,邓涵. 基于抽象概念的知网词语相似度计算[J]. 计算机工程与设计,2017(3):664-670.
[18] 张波,陈宏朝,朱新华,等. 基于多重继承与信息内容的知网词语相似度计算[J]. 计算机应用研究,2018,35(10):101-105.
[19] 彭琦,朱新华,陈意山,等. 基于信息内容的词林词语相似度计算[J]. 计算机应用研究, 2018(2):400-404.
[20] HEATON,J. Ian goodfellow, yoshua bengio,and aaron courville: deep learning[J]. Genetic Programmingand Evolvable Machines, 2017:s10710-017-9314-z.
[21] LEVY, OMER, YOAV GOLDBERG, IDO DAGAN. Improving distributional similarity with lessons learned from word embeddings[J]. Transactions of the Association for Computational Linguistics,2015(3):211-225.
[22] 王洪俊,施水才,俞士汶,等. 词义演化的计算方法[J]. 广西师范大学学报(自然科学版),2006,24(4):183-186.
[23] YAO Z,SUN Y,DING W,et al. Dynamic word embeddings for evolving semantic discovery[DB/OL]. https://arxiv.org/abs/1703.00607,2017.
[24] Large scale chinese corpus for NLP[EB/OL]. https://github.com/brightmart/nlp_chinese_corpus.
[25] PeopleDaily1998[EB/OL]. https://github.com/chenhui-bupt/PeopleDaily,1998.
[26] Final_word_Similarity[EB/OL]. https://github.com/yaleimeng/Final_ word_Similarity.
(責任编辑:孙 娟)
