基于粗糙集的容器云系统健康度评价建模
2020-04-30张可颖龙士工吕尚青吕晓丹
张可颖,龙士工,吕尚青,吕晓丹
(1.贵州大学 大数据与信息工程学院,贵州 贵阳 550025;2.贵州大学 贵州省公共大数据重点实验室,贵州 贵阳 550025;3.贵州大学 计算机科学与技术学院,贵州 贵阳 550025;4.北京邮电大学 信息与通信工程学院,北京 100000)
0 引 言
近年,云计算领域蓬勃发展。特别是容器技术的出现颠覆了原有的虚拟化技术,其在自动配置和计划资源调度方面展现了良好性能。而且由于启动和终止开销较低,容器正迅速取代许多云部署中的虚拟机VM[1],带来了技术架构的变革,从SOA到微服务,成为如今国内外大规模云服务产商的关注焦点,如国外Google、AWS、Azure和国内蚂蚁金服、腾讯云等。同时,容器云的出现也带来了新的挑战。基于微服务思想的容器云平台相比传统IaaS云平台,监控指标呈爆炸式增长,比如服务器节点指标、容器指标、应用性能指标、自定义业务指标等等。虽然出现了Prometheus这样一个统一的平台去处理监控问题,但是Prometheus只是一套开源的系统监控报警框架,并没有细粒度对系统健康度进行分析,繁琐复杂的监控指标还需要根据业务进行整合加工才能反映系统健康度。而且,目前对容器云平台的研究多集中于云资源调度和数据分析,对监控指标建模进行健康度分析讨论是比较欠缺的。
针对容器云平台微服务监控指标复杂,配置繁琐的问题,提出了一种基于粗糙集的容器云系统健康度建模方法。通过建立的健康度指标能够更直观地反映系统的健康度,从POD到NODE到整个集群,选取一系列指标从各个粒度和多个维度全面监控和整合数据,方便运维人员快速掌控集群实时情况,定位错误。同时对容器云健康度的建模分析也有助于对集群资源调度的优化。
1 相关工作
近年,学术界对容器云系统健康度建模研究比较欠缺,多集中于对特定应用背景容器平台监控架构设计和平台性能测试。鲜有学者专研系统健康度指标,提出一套通用的健康度评价体系。Seunghyun Seo等人针对异构云平台提出了一套联合监控系统,主要包括四个模块即组件管理器、聚合管理器、注册表管理器和切片管理器[2]。Víctor Medel等人通过Petri网性能模型分析了Kubernetes性能,并设计和规划了基于Kubernetes的弹性应用程序[3];Xie X等人通过实验比较了基于Kubernetes的Docker,Rkt和裸机的性能,得出容器虚拟化技术的资源成本接近于“裸机”资源成本[4];Leila Abdollahi Vayghan等人对Kubernetes的HA架构进行了一系列实验,表明微服务中断远高于预期[5]。
云平台健康度评价问题往往需要做出大量的不确定决策,而粗糙集在对不确定性信息处理方面得到了广泛的应用[6-9],是一种潜在的合适的解决方案。处理不确定性的数据工具除了粗糙集外,还有概率论、模糊集、模糊粗糙集等变种[10-11]。粗糙集在云平台方面应用的研究几乎没有。TeJen Su等人将模糊集理论应用在云环境下的电力监控系统,通过实验证明了其可行性[12]。
在业界,有许多容器云指标监控解决方案,可用于分析Kubernetes性能,无论是开源的还是商业性质的。比如Prometheus,Docker Stats API,cAdvisor,Sysdig,Heaper,Librato等。Docker Stats API直接输出Json很难整合;cAdvisor在每个节点上提供一个运行守护进行,处理和导出每个节点运行容器详细资源使用信息,但是,它没有一个系统的编排,难以转化为更复杂的聚合和测试;Sysdig是一种付费的解决方案;Heapster只能监控主机级别和容器级别的数据,无法监控容器内服务级别数据;Librato更适合结合AWS或Heroku。而Promethues提供多维的数据模型,借助这种多维性所提供的灵活查询语言,理论上服务支持Prometheus端点或是提供http端口的转换器都可以手动拉取数据,既适用于面向服务器等硬件指标的监控,也适用于高动态的面向服务架构的监控[3]。故文中提出的建模方法使用Python借助Promethues中Node exporter API提取各项监控指标数据进行系统健康度建模。
2 资源监控平台架构
2.1 容器云平台架构和监控指标
容器云平台采用Kubernetes和Docker实现,架构为主从架构,监控维度从整个集群到Node再到Pod,一个Node有多个Pod,一个Pod可能有多个容器,如图1所示。Master节点上安装有重要系统组件:API Server、Scheduler、Controller和Etcd,以Pod形式存在。根据业务不同,主要可分为计算密集业务、网络密集业务和IO密集业务。Node监控维度包括Node的CPU、内存、网络和IO利用率等。Pod监控维度包括Pod的CPU、内存、网络和IO相关指标。详细参数参考下面章节内容。
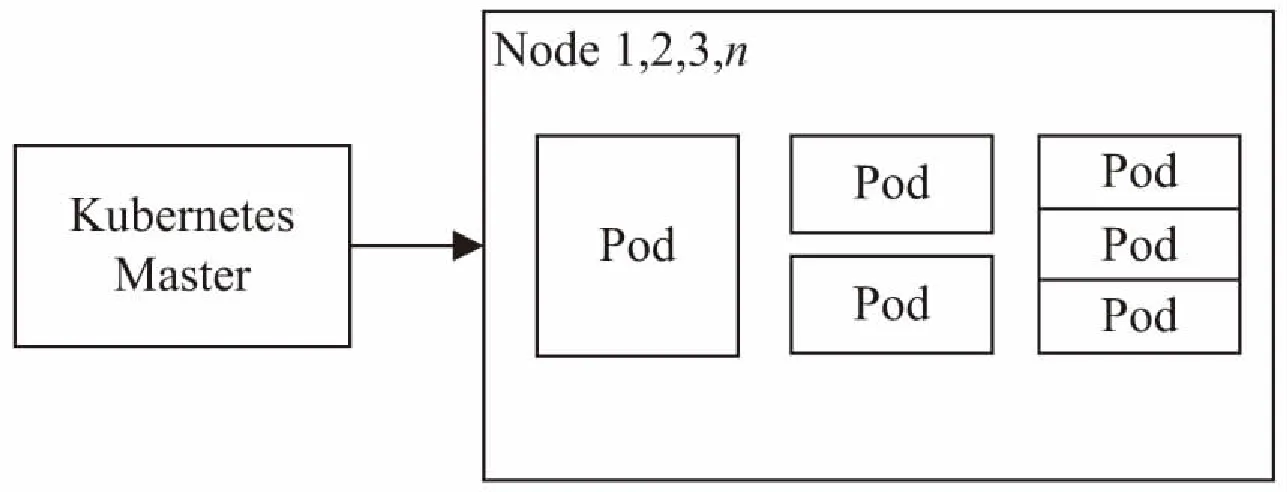
图1 云平台架构
2.2 资源监控数据获取流程
Node-Exporter对Prometheus暴露出系统可以被“抓取”的Metrics信息。Prometheus调用api端口信息完成查询,Grafana调用信息完成数据可视化。文中使用Python抓取从exporter api暴露的Metrics信息,然后进行基于信息熵连续属性离散化处理,最后建立基于粗糙集的决策表,推导出决策规则。
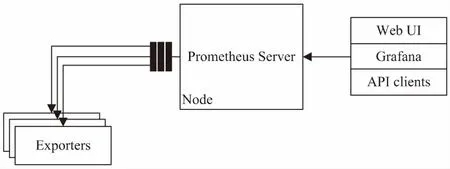
图2 资源监控数据获取流程
3 基于粗糙集的容器云系统健康度建模
3.1 基于系统粗糙集建立决策表
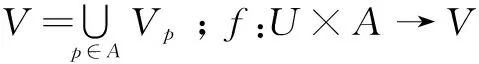
(1)云平台中Node的监控数据(条件属性)NodeC={cpu,memory,network,io…}和PodC={cpu{…},memory{…},network{…},io{…}}均为连续属性,Pod部分经典监控参数见表1。决策属性是系统健康度D={healthy,normal,unhealthy},为离散属性。

表1 Pod监控参数
决策表的一般形式见表2。
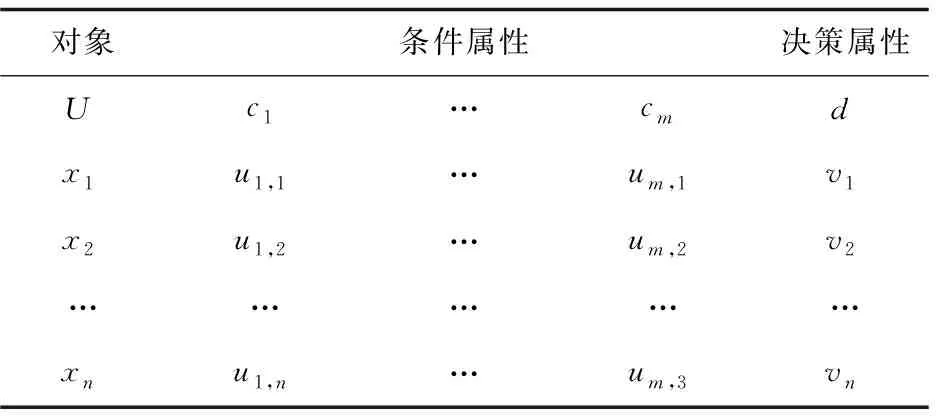
表2 决策表的一般形式
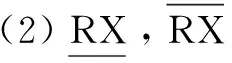
(3)决策表相容度定义为:
其中,|X|表示集合的个数,P(Xk)表示子集Xk在等价关系P下的下近似集。一般有0≤dp(Q)≤1,当dp(Q)=1时,表示所有的实例在相同条件属性下都有相同的决策属性值,此时称决策表是相容的。
(4)属性约简[14]。
定义2:设U为一个论域,P为定义在U上的一个等价关系簇,P中所有绝对必要关系组成的集合称为关系簇P的绝对核,记作CORE(P)。
定义3:设U为一个论域,P和U为定义在U上的两个等价关系簇,若POSP(Q)=POS(P{r})(Q),则称r为P中相对于Q可省略的(不必要的),简称P中Q可省略的;否则称r为P相对于Q不可省略的(必要的)。
属性约简算法:
对于决策表中的每一个条件属性ci,进行如下流程,直至属性集合不再发生变化为止。
{
如果删除该属性ci使POS(P{ci})(Q)=POSP(Q),则说明属性ci是相对于决策属性d不必要的,从决策表中删除属性ci所在列并将重复的行进行合并;
否则,说明属性ci是相对于决策属性d必要的,不能删除
}
对决策表条件属性进行约简,去掉不重要的条件属性,从而提取更准确和最少的判断系统监控度的决策规则。
(5)决策表一致性检查[15]。
定义4:设U为一个论域,P和Q为定义在U上的两个等价关系簇,如果POSp(Q)=U,则称论域U是P上相当于Q一致的。
3.2 基于信息熵离散化连续属性
定义5(信息熵):设离散随机变量X={x1,x2,…,xn},X⊆U,|X|表示实例个数。其中决策属性j(j=1,2,…,r(d))实例个数为Kj,则X的信息熵定义为:
信息熵是信息论中用于度量信息量的一个概念。一个系统越是有序,信息熵就越低;反之,一个系统越是混乱,信息熵就越高。对云平台,如果基于监控指标计算的信息熵增加,表示集群有可能处于异常状态,需要动态弹性调整。因为监控数据是连续数据,建立粗糙集决策表需要将连续数据进行离散化。
具体的离散化算法步骤设计如下:
设决策表S=
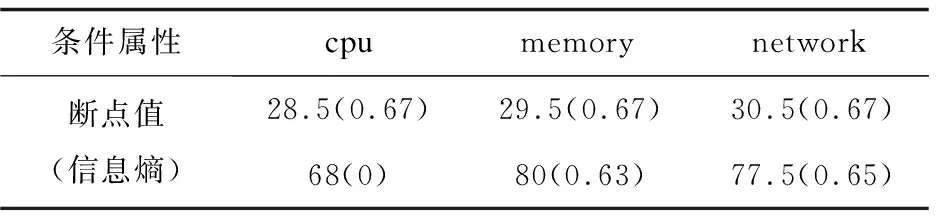
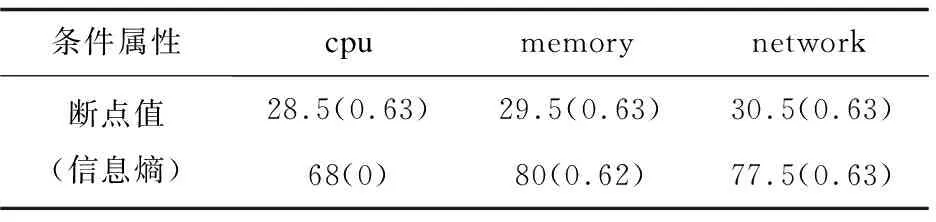
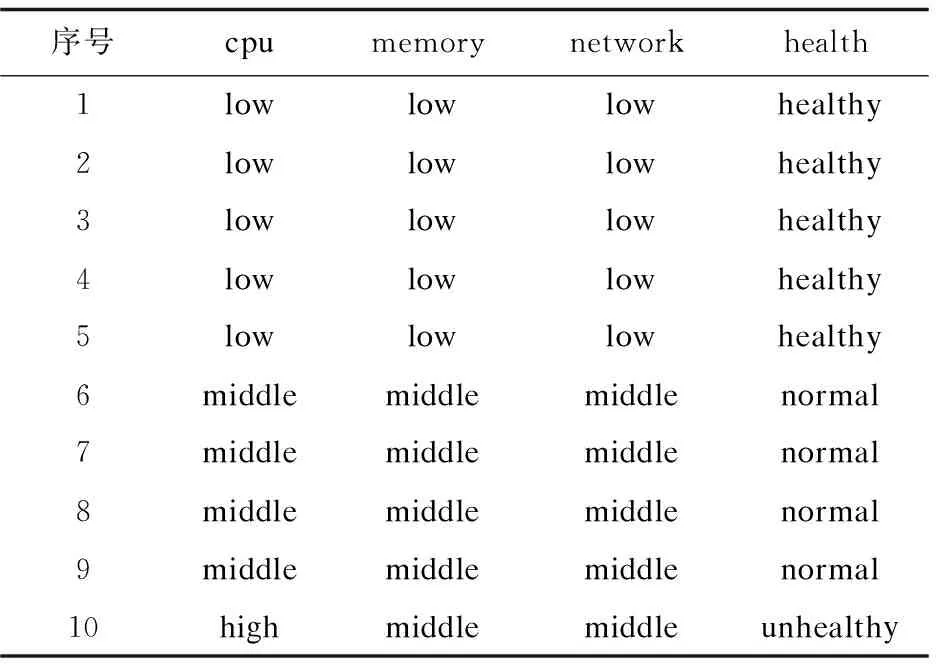
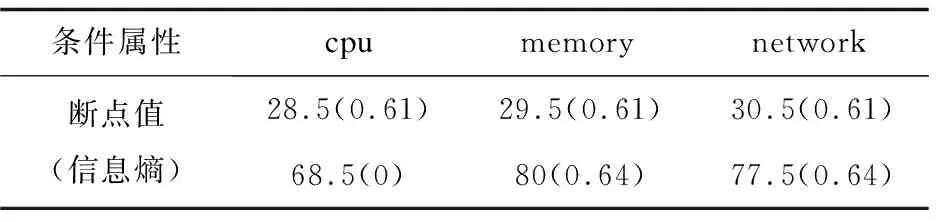
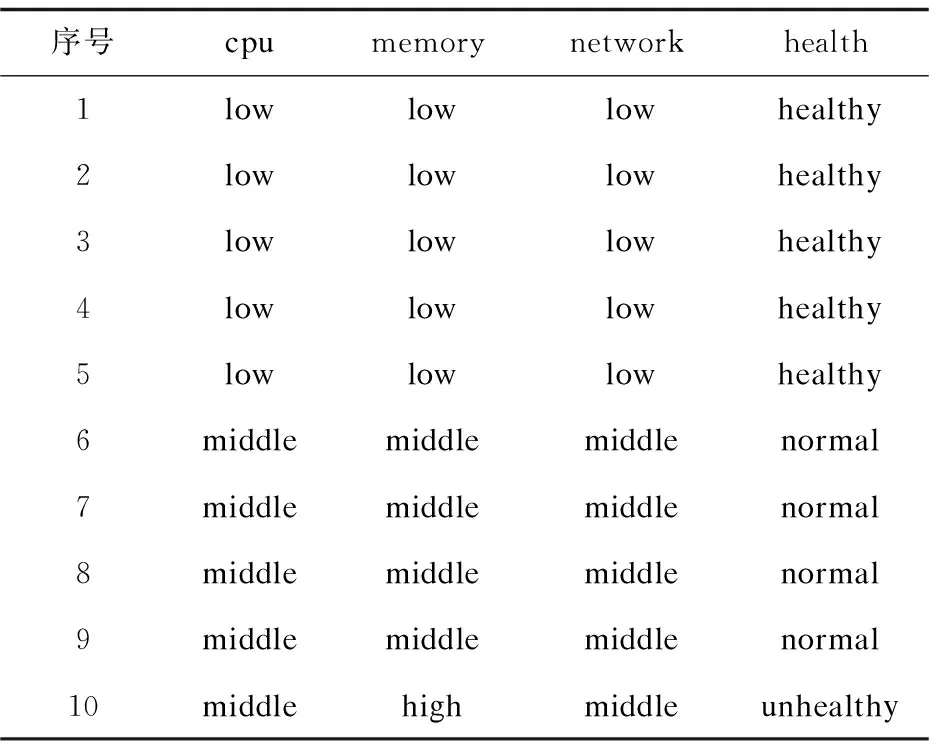
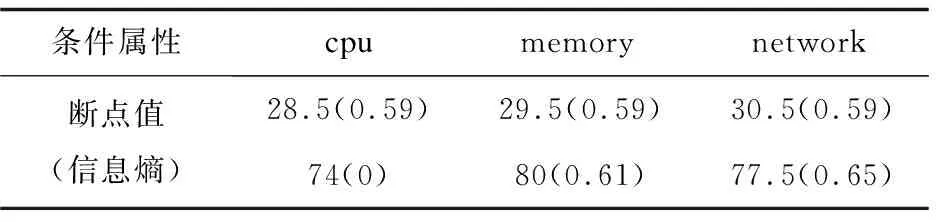
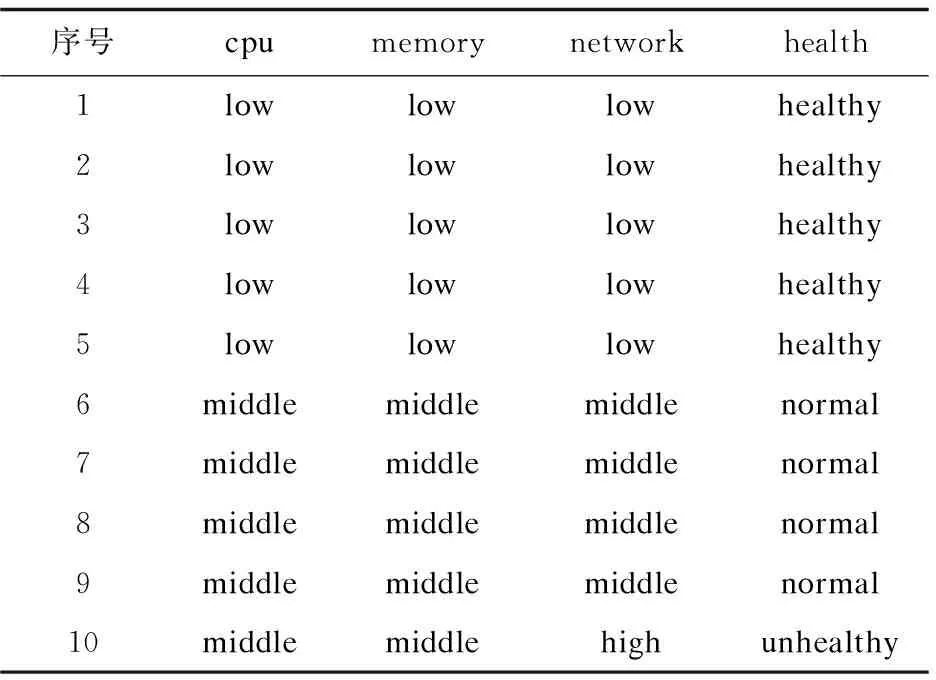
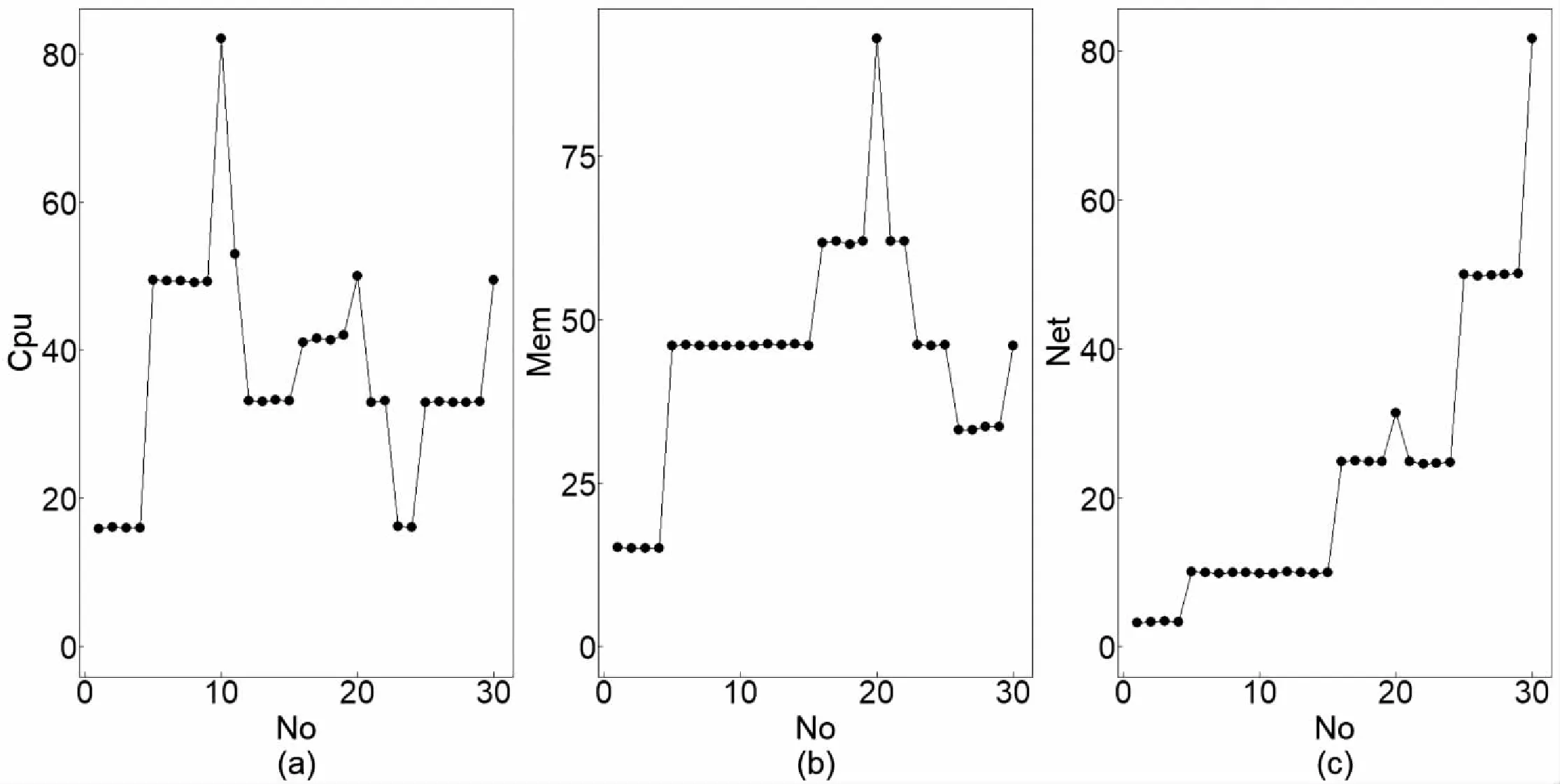
lk=vk0 可选断点: cai=(vai-1+vai)/2(i=1,2,…,n) 对于断点Caj,针对集合U的信息熵计算方法参考文献[15]中方法。 离散化算法如下: 步骤一:P≠Q,Q={U},H=H(U),设置分类断点数i; 步骤二:分别对各条件属性的属性值进行排序,取相邻两个属性均值加入到候选断点集合B中; 步骤三:计算每一个断点信息熵H(c,Q),c∈B,取cmin=min{H(c,Q)}; 步骤四:若cmin是唯一断点,选择使得H(c,Q)最小的断点cmin加入P中,H=H(c,Q);B=B-{c}转步骤六;若cmin不是唯一断点,则转步骤五; 步骤五:计算信息熵相同的断点的条件属性的分类正确率,选择分类正确率大的条件属性的断点作为结果断点; 步骤六:对所有X∈Q,若cmin将等价类X划分成X1和X2,从Q中去掉X,并把等价类X1和X2加入到Q; 步骤七:计算离散后决策表的相容度,如果相容度在可接受范围且选择的cmin的数量等于i则结束,输出断点集合P;若相容度不在接受范围则转步骤三计算下一个断点,若i个点不能计算出相容度接受范围结果,则i=i+1。 根据离散后的决策表和粗糙集算法分别提取出决策规则。 为了验证所建容器云系统健康度模型的有效性,实验选用DELLR710服务器,使用Openstack Q版本开启的3台虚拟机,系统采用Centos7.6,软件版本为Kubernetes 1.13.1,1台Master节点(4G内存4核CPU)2台Slave节点(每台8G内存4核CPU)。实验系统健康度监控粒度为节点级别。文中在Kubernetes平台Slave1采集四组数据,第一组数据为采集筛选后的60个基本训练数据;第二组数据在第一组基础上再采集10次,在第10次插入CPU异常;第三组数据在第二组数据基础上再采集10次,在第10次插入内存异常;第四组数据在第三组数据基础上再采集10次,在第10次插入网络异常。本次实验只选取了三个条件属性代表系统特征,分别为cpu,mem,net,生产环境应当选取更多监控指标和更细粒度的监控级别,可参考3.1。初始决策属性判断依据服务负载占用量给出判断系统健康与否的标准。除此之外,还可以选择新创建服务的响应时间进行判断。 为了模拟云平台负载,在容器中运行Tensorflow卷积神经网络Demo模拟CPU和内存负载,在容器里面使用Tomcat搭建网站,用Apache Bench模拟网站并发访问量。 第一组训练数据的cpu,memory,network选取断点及断点信息熵,如表3所示。 表3 第一组数据基本指标选取断点及断点信息熵 根据选择的信息熵对数据进行离散化,检查离散后的决策表是一致的,属性不可约简,可以导出下列决策规则: 经计算,这些规则的确定性均为1。 (1)cpu异常注入。 第二组数据基本指标选取断点及断点信息熵见表4。 表4 第二组数据基本指标选取断点及断点信息熵 相比第一组基础数据,断点未改变,提取的决策规则不变,能成功判断出cpu异常。 第二组数据离散后判断出的决策表见表5。 表5 第二组数据离散后判断出的决策表 (2)Memory异常注入。 第三组数据基础指标选取断点及断点信息熵如表6所示。 表6 第三组数据基础指标选取断点及断点信息熵 相比第二组数据,断点未改变,提取的决策规则不变,能成功判断出mem异常。 第三组数据离散后判断出的决策表如表7所示。 表7 第三组数据离散后判断出的决策表 (3)Network异常注入。 第四组数据基础指标选取断点及断点信息熵如表8所示。 表8 第四组数据基础指标选取断点及断点信息熵 相比第三组数据,断点未改变,提取的决策规则不变,能成功判断出net异常。 第四组数据离散后的判断出的决策表如表9所示。 表9 第四组数据离散后判断出的决策表 序号cpumemorynetworkhealth1lowlowlowhealthy2lowlowlowhealthy3lowlowlowhealthy4lowlowlowhealthy5lowlowlowhealthy6middlemiddlemiddlenormal7middlemiddlemiddlenormal8middlemiddlemiddlenormal9middlemiddlemiddlenormal10middlemiddlehighunhealthy Slave1实验过程资源负载变化如图3所示。 图3 Slave1实验过程资源负载变化 文中容器云系统健康度模型能够反映集群负载情况并检测异常,从而实时、动态地对整个云平台资源进行直观反映。该容器云系统健康度模型结合了粗糙集和信息熵的理论,基于Kubernetes容器云平台的实验验证了模型的有效性以及分析定位的准确性。对云平台系统健康度的分析建模有助于进一步对系统亚健康状态进行调度优化,从而在提高系统利用率的同时保证服务质量。4 模型验证
5 结束语
