基于机器学习的柴油机纳米级微粒预测模型
2020-04-08李加强王艳艳谭建伟
邹 浪, 何 超*, 李加强, 王艳艳, 谭建伟
(1.西南林业大学机械与交通学院,昆明 650224; 2.西南林业大学云南省高校高原山区机动车环保与安全重点实验室,昆明 650224; 3.北京理工大学机械与车辆学院,北京 100081)
近年来,机动车尾气排放已成为大气污染主要来源,尤其是大气颗粒物的增加对人体健康影响显著。研究表明,颗粒物粒径与呼吸道和心血管疾病的增加以及死亡率之间存在关联[1-2]。据报道,柴油车尾气已成为碳质气溶胶来源之一[3-5]。因此,减少大气颗粒物的排放成为当前研究的热点。
随着柴油机排放法规发展到欧VI阶段,在原来颗粒物质量排放测试的基础上增加了颗粒物数量的测量[6]。然而,纳米技术的进步使得试验仪器能够精确测量1~1 000 nm颗粒物粒径及数量,从而降低偶然误差和系统误差带来的影响。研究发现,机动车辆燃烧产生的颗粒对人体的危害主要来自细颗粒物和超细颗粒物[7-10],尤其是直径小于100 nm的超细颗粒物对人和动物的危害比细颗粒物更加突出[11]。相比汽油车,柴油车具有使用寿命长久、燃油经济性好、压缩比高、低污染等优点,被作为动力装置安装在许多欧美轿车及重型车辆上。由此可见,改善柴油车的污染物排放对控制大气污染起着重要的作用。
针对发动机转速、空燃比、气缸压力、废弃再循环(exhaust gas re-circulation,EGR)率等燃烧特性与纳米级PM的研究已有大量报道[12-16]。因此,利用发动机燃烧产生的缸压循环及空燃比等物理参数预测污染物的排放必不可少。Henningsson等[17]利用柴油机在不同速度、喷油定时及EGR率等条件下气缸压力对NOx和尾气中的氧气浓度λ进行了有效预测;Pu等[14]利用气缸压力作为神经网络的输入,预测了粒径为15~1 000 nm的颗粒物分布;Weymann等[18]建立燃烧压力轨迹的神经网络模型,结果表明该模型的预测值与实际值的相关系数为0.992;余林啸[19]研究不同海拔高度对柴油机的燃烧特性和排放特性的影响,结果表明随着海拔的升高,柴油机缸内最高燃烧压力逐渐减小,核模态和积聚模态颗粒物数量增加。
然而,在不同海拔、转速及转距情况下,利用柴油机燃烧产生的气缸压力预测纳米级颗粒物(particulate matter,PM)在相关领域的文献非常有限。由于实验条件非常复杂,需要测试大量原始数据,导致模型的构建十分困难。基于此,运用机器学习领域的方法,采用主成分分析(principal component analysis, PCA)研究不同海拔下气缸压力的相关特征。随后训练神经网络,以主成分训练数据作为输入,颗粒物排放的粒径数量浓度作为输出,从而比较不同主成分对于颗粒物浓度预测情况,选择合适的主成分建立模型是研究的重点。
1 试验设备
试验用柴油机为锡柴CA6DF3,试验发动机规格如表1所示, 燃料为0号柴油。

表1 试验发动机参数
采用CW440D型电涡流测功机实时测量发动机的输出转矩和转速。为了得到精确的燃烧特性参数,使用DEWETRON 5000型燃烧分析仪对角标仪与缸压传感器所测试的数据进行实时现场测量,按每0.2曲柄角间隔采集1个气缸压力数据。同时,使用低压静电冲击式采样器ELPI对不同粒径的颗粒物数量浓度进行测量,第一级冲击器中加入滤纸,使测量范围扩展到7 nm粒径,粒径分布如表2所示。
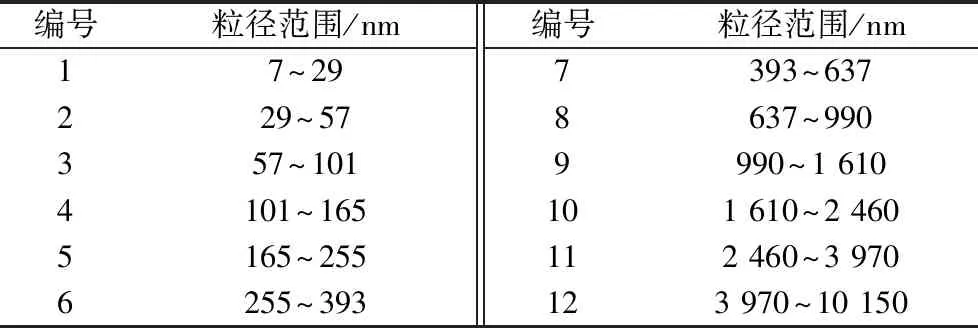
表2 ELPI粒径分级
2 试验方法
2.1 试验设计
试验对280种工况进行测试,其中包括4种海拔(0、1 608、2 408、3 300 m),每种海拔下8种转速(1 030、1 200、1 400、1 600、1 800、2 100、2 300 r/min及怠速700 r/min),以及每种转速下10个不同的转矩(怠速除外),相同海拔下转速与转矩的关系如图1所示,其中转矩为47~790 nm。每个工况点的转矩和转速保持一致,待发动机工作稳定后,再进行数据采集。经过多次测试,对每个工况随机选取50个周期取平均值,收集大量气缸压力及不同粒径的颗粒物浓度数据。
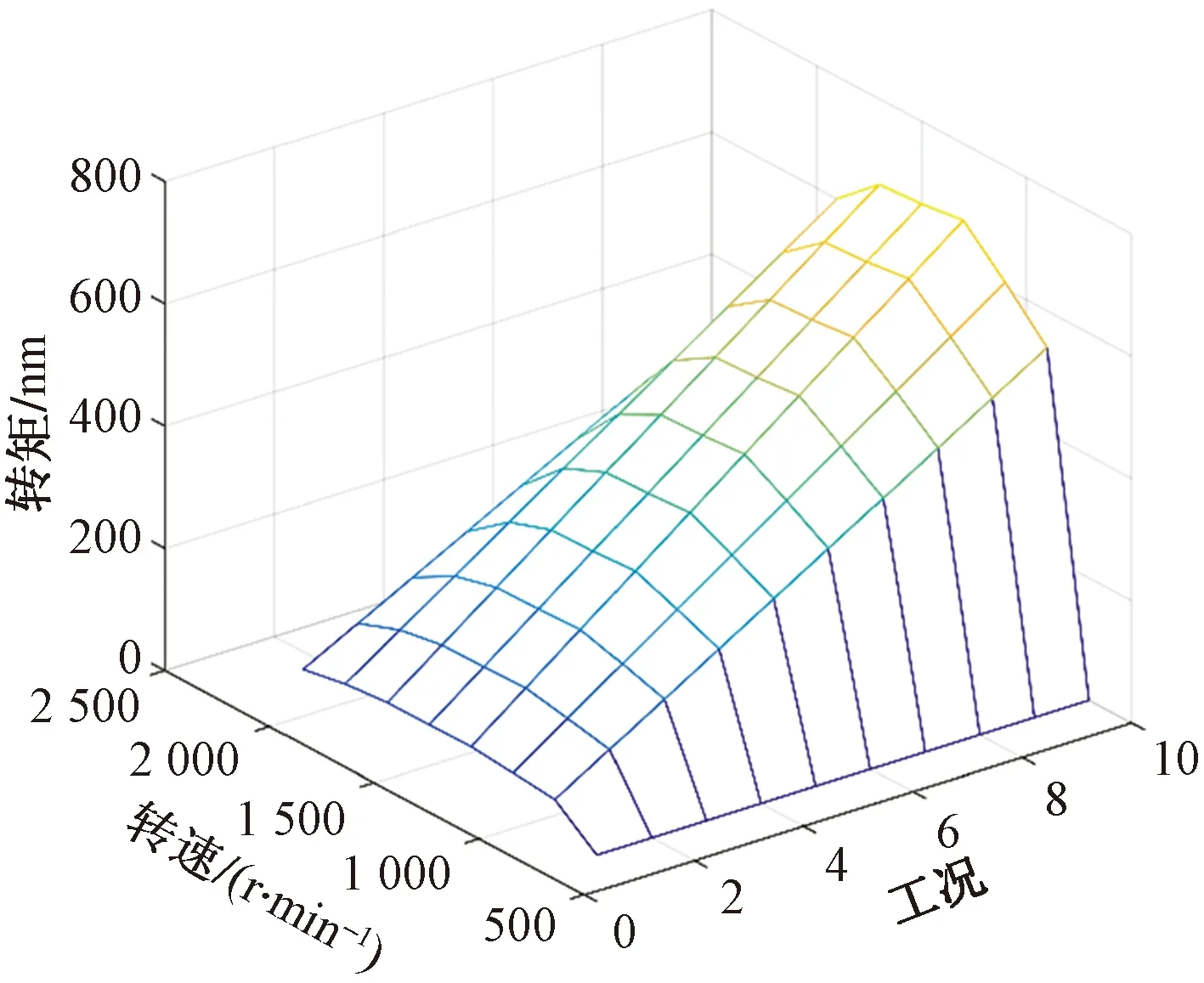
图1 相同海拔下转速与转矩关系
2.2 主成分分析原理
主成分分析是一种大数据降维的方法[20],通过查找变量之间的联系,使原始变量重新线性组合得到一组不相关的综合指标,这为降低数据的维数提供了方法。因此,主城分分析在图像识别、模型预测及计算机等领域运用广泛。主成分分析原理公式如式(1)所示:
(1)
式(1)中:A∈RN是原始数据集,N为原始变量的维数,即不同海拔、转速和转矩条件下,N变量的气缸压力数据组合成原始数据集;X=[x1,x2,…,xL]为主成分组成的基向量矩阵;C=[c1,c2,…,cL]为是由L个系数组成的向量矩阵;e为误差。
当L≪N,使误差e最小化时,可由式得到式(2),其中T为转置。这表明C的每个分量即主成分系数能表示相对应原始数据的特征。
C=AXT或X=CTA
(2)
由于奇异值分解不仅是谱分析的推广运用,还能消除干扰信号带来的影响。因此,原始数据使用MATLAB svd函数进行奇异值分解,其原理如式(3)所示:
A=USVT
(3)
式(3)中:A为任意实维矩阵;U和V为正交矩阵;S为奇异值矩阵,奇异值按列从左到右逐渐减小;U和V的列向量分别是左奇异向量和右奇异向量,其中U的列向量是奇异值从大到小依次对应的特征向量。若奇异值矩阵的某部分对角线元素远远大于其他奇异值之和,则这部分元素对应的特征向量代表原始数据的大部分信息。
2.3 神经网络结构
对影响指标A=[a1,a2,…,an]进行主成分分析,其结果X=[X1,X2,…,Xn]作为神经网络的输入向量,得到对应的输出结果y,如图2所示。wij和wih分别为输入层与隐含层、隐含层与输出层的连接权值。通过设定期望误差来评估实模型的精确程度,如果实际输出与预测输出之间的误差大于期望误差,则进行多次逆向传播修正,直至小于期望误差终止,最终建立神经网络模型。
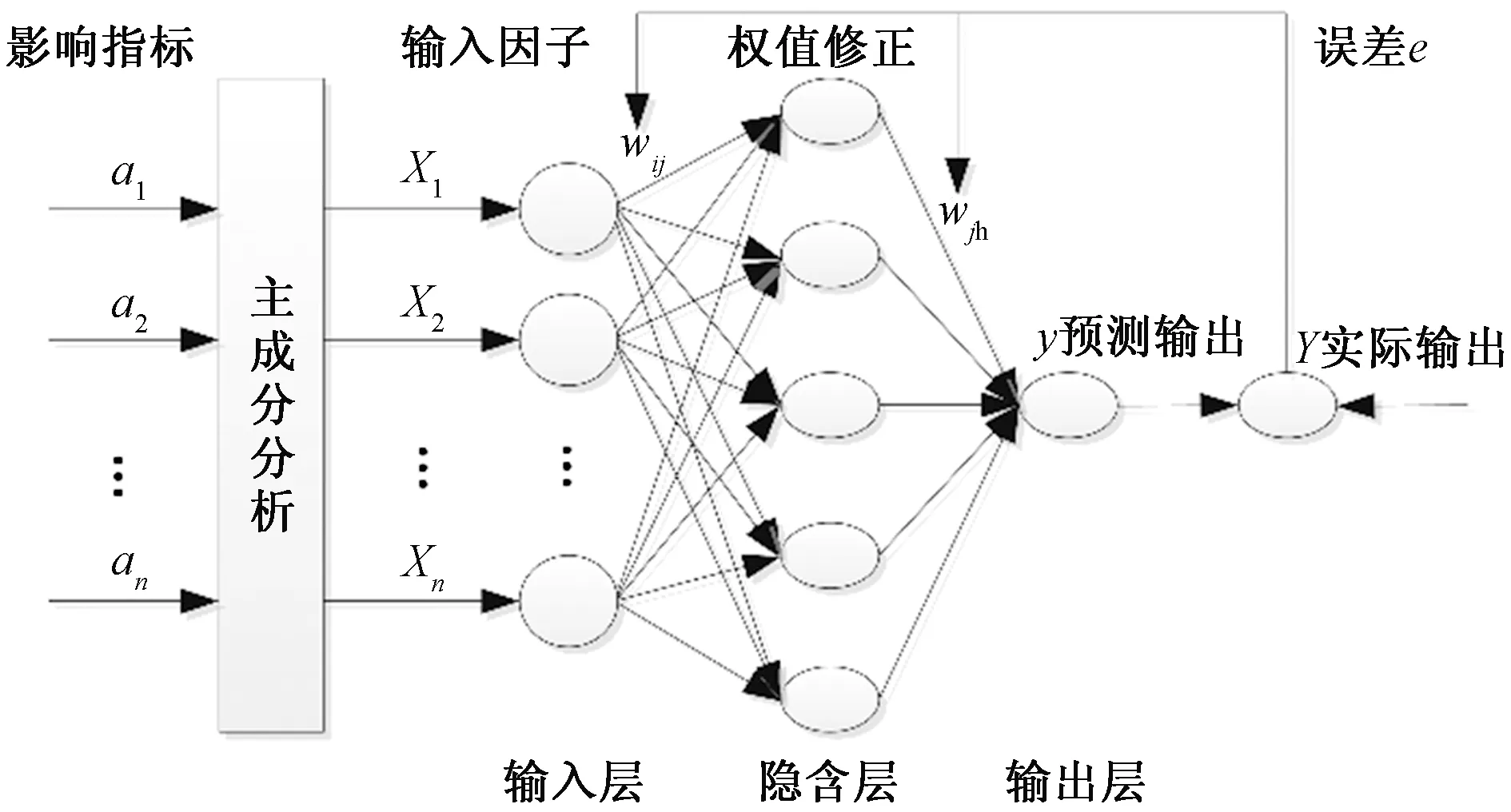
图2 神经网络结构原理
3 试验结果与分析
3.1 主成分分析气缸压力
发动机燃烧过程集中在活塞上止点附近,这时气缸压力变化趋势最能代表整个周期的燃烧特性。由此可见,选择上止点-30~45 ℃曲柄角进行数据研究是降低实验难度的可行方案[14]。每循环采样1次,采样间隔为0.2曲柄角,可获得375个样本点,最终对10 500个数据进行分析。
通过MATLAB奇异值分解并计算气缸压力的前10个主成分贡献率如表3所示。图3所示为X1、X4、X7、X10主成分的气缸压力变化曲线,其中横坐标表示曲柄角,纵坐标表示数据预处理后的缸压。由表3、图3可知,第1主成分提取原始数据62.02%的特征信息,而主成分10主要捕捉活塞上止点附近压力变化的频率。图4所示为不同海拔下X1、X4、X7、X10主成分的重构数据与原始数据的分布,表明主成分维数越高,奇异值分解重构数据与原始数据信息重合度越好,说明奇异值分解降低了原始数据特征信息的损失。这是由于PCA的本质是空间坐标的变换且数据结构保持不变,获得的主成分集是原始变量的线性组合造成的结果。

表3 主成分贡献率
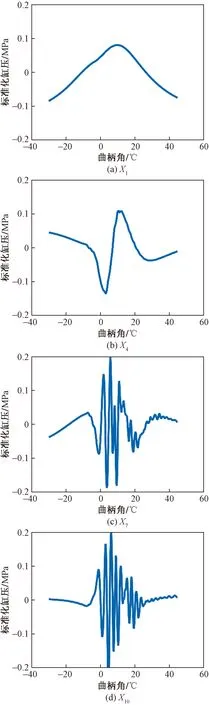
图3 部分主成分的缸压变化曲线
对280组原始数据和重构数据进行均方根误差(RMSE)检验,结果如图5所示。在图5中,第1主成分因贡献率小于80%造成均方根误差过大,导致信息提取过少,因此不能用于分析模型的训练数据。图3~图5表明,前4个主成分代表缸内压力总体变化趋势,且随着主成分贡献率的增大,均方根误差急剧减小,当达到一定程度后误差缓慢降低。当达到10个主成分时,均方根误差为0.014~0.082 MPa,信息提取效果较好。综上所述,不同工况下气缸压力变化趋势能由主成分系数表示。
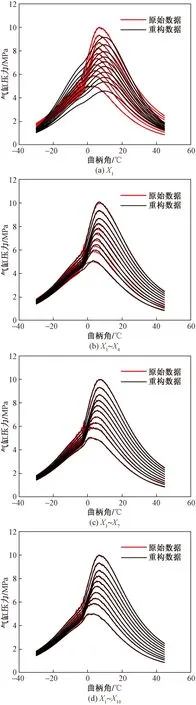
图4 主成分重构数据与原始数据的缸压分布
3.2 神经网络预测模型分析
3.2.1 神经网络模型的设计
由于柴油机的颗粒物排放受负荷、温度、转速、喷油时间、火花正时、燃料及EGR率等物理参数的影响。因此建立气缸压力与颗粒物的排放模型属于非线性映射。显然,一个多层反向传播的前馈神经网络是非线性映射模型仿真的最佳选择之一。鉴于原始数据涉及不同的量纲,为保证预测模型精确度,必须对数据进行标准化处理。
选择单隐含层的神经网络模型,输入是经过前4、7、10个主成分分析的280组标准化数据,输出为具有6个神经元的粒径为7~990 nm颗粒物浓度(即第一组粒径为7~29 nm;第二组粒径为29~57 nm;第三组粒径为57~101 nm;第四组粒径为101~255 nm;第五组粒径为255~990 nm,第六组粒径为7~990 nm)。其中随机产生238组数据用于神经网络训练,剩余42组数据用于神经网络测试。主成分分析与神经网络模型流程如图6所示。

图5 气缸压力均方根误差曲线
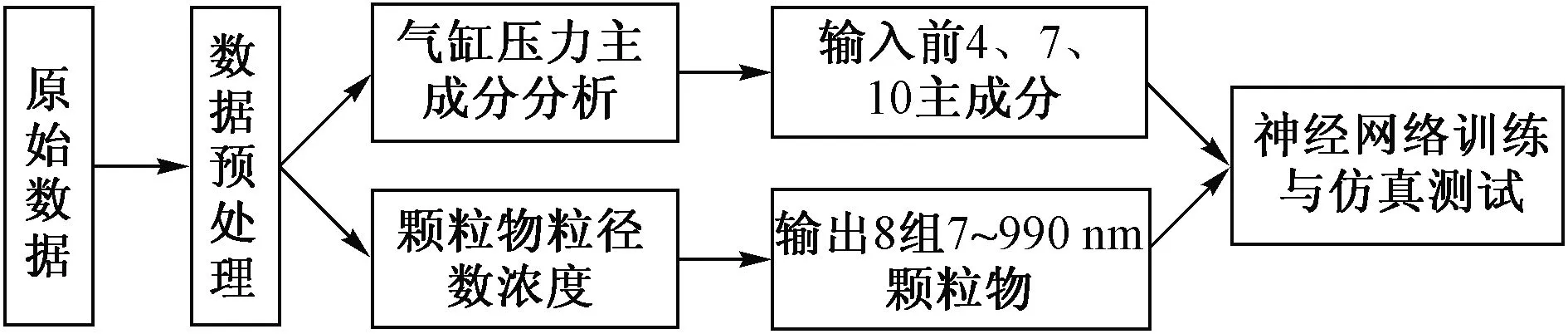
图6 主成分分析与神经网络模型流程
由于神经网络极易陷入局部最优化,而贝叶斯正则化反向传播算法能使神经网络模型具有最佳整体性能。因此,选择MATLAB定义的贝叶斯函数(trainbr)对该模型进行训练优化。最大训练次数为1 000次,训练目标为0.001,学习率设置为0.01。
3.2.2 模型预测结果分析
为研究不同工况下不同主成分的气缸压力与PM粒径浓度模型的最佳结合点,需要对神经网络模型进行反复测试和训练。其中平均绝对误差(MAE)和均方根误差(RSME)越小,回归系数R2越接近1,则表明该模型预测效果越好。
经过多次训练后,X1~X4主成分预测PM粒径数量浓度的神经网络采取4个输入层神经元,隐含层节点为5时,该模型能准确预测7~990 nm的颗粒物粒径浓度,测试的R2达到0.85,整体性能R2达到0.81,如图7所示,其中横坐标从左到右依次表示为训练目标、测试目标和全局输出数据,纵坐标表示神经网络对应的预测输出。此外,X1~X7主成分选用7个输入神经元,8个隐含层节点时模型预测稳定高效,测试的R2达到0.86,整体性能R2达到0.91,如图8所示;X1~X10主成分采用10个输入变量,9个隐含层神经元,测试的R2达到0.92,整体性能R2达到0.95,如图9所示。

图7 X1~X4回归分析
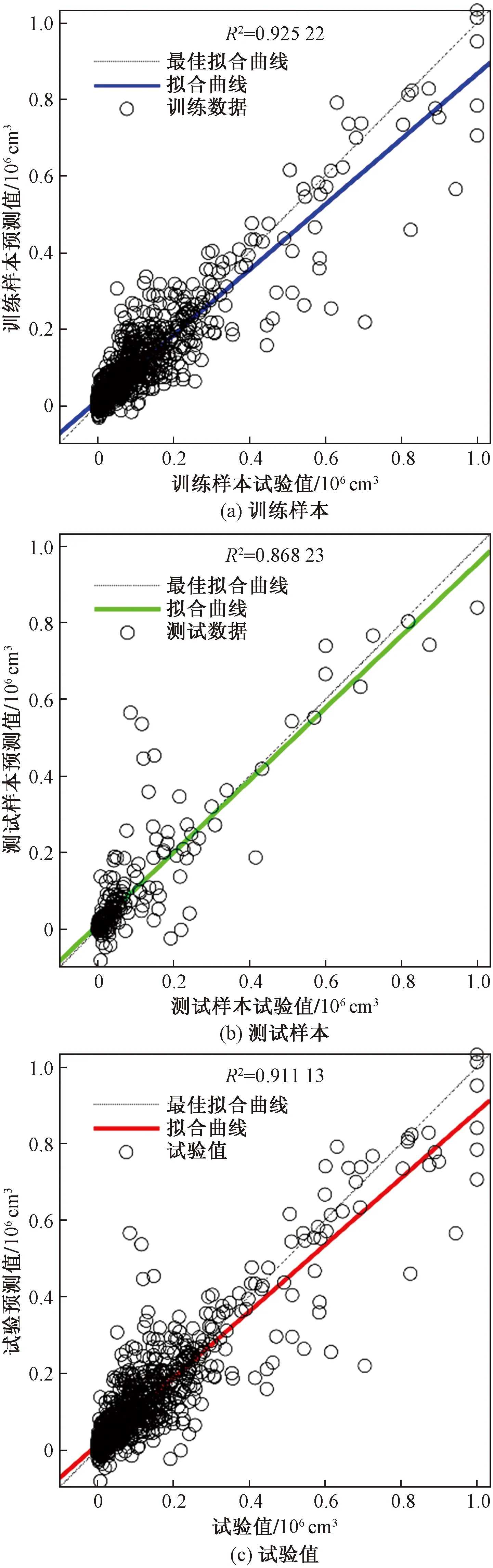
图8 X1~X7回归分析
对X1~X4、X1~X7和X1~X10三个模型进行仿真测试,引入平均绝对误差(MAE)和均方根误差(RSME)对样本预测值与实测值进行检验,得到结果如表4所示。由表4可知,模型的平均绝对误差为90.74~2.284 29×103cm3,均方根误差为1.612×104~9.769×104cm3,这表明柴油机燃烧产生的气缸压力能准确预测7~990 nm每组颗粒物的数量浓度分布。由表4可知,平均绝对误差和均方根误差随着主成分贡献率的增大而逐渐降低,表明主成分占比与模型的预测精度成正相关,这是由于新加入的主成分相比旧主成分对于原始数据的特征提取更全面,引起主成分与不同粒径的颗粒物浓度的相关性增加的结果。其中7~990 nm PM数浓度在X1~X10模型的样本预测值与试验值如图10所示。
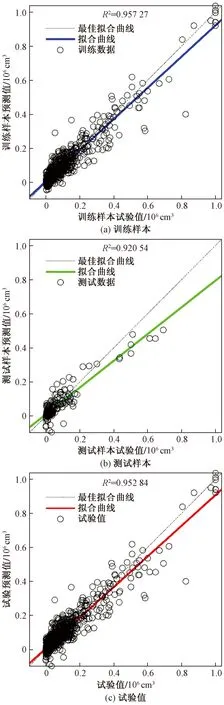
图9 X1~X10回归分析图
研究表明在不同行驶工况下,当主成分达到一定比例时,利用柴油机燃烧产生的气缸压力提取主成分来预测PM的排放是一种有效方法。此外,前10主成分的缸压预测7~990 nm颗粒物的平均绝对误差为90.74 cm3,均方根误差为1.612×104cm3,回归系数R2为0.95,表明在某些复杂实验条件下测量颗粒物的粒径浓度排放时,可以独立测量气缸压力进行预测。
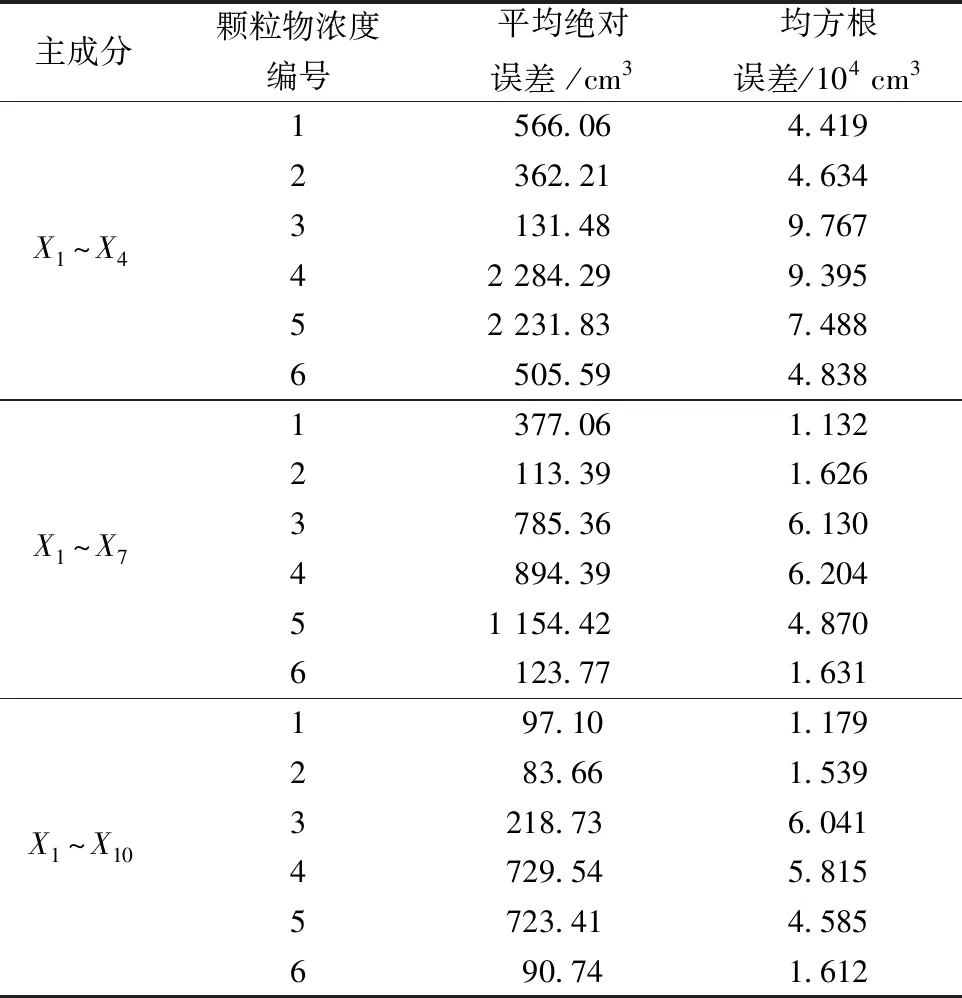
表4 每组粒径浓度的试验值和预测值的误差
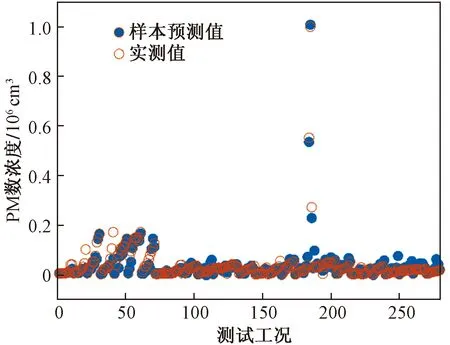
图10 PM数浓度在X1~X10模型的试验值与样本预测值
4 结论
通过主成分分析与神经网络组合模型,得到以下结论。
(1)奇异值分解能有效减少原始数据信息的损失。
(2)在运用主成分方法分析气缸压力时,不同工况下的气缸压力变化能够由主成分系数表示。
(3)利用主成分分析和神经网络建模,当主成分达到一定比例时,实测数据与模型的预测值具有良好的一致性,其回归系数R2达到0.95。证明主成分分析与神经网络结合是一种降低数据维度和模型构造难度的可行方法之一。
(4)柴油机气缸压力与在7~990 nm颗粒物的数量浓度预测分布拟合效果较好,表明发动机燃烧产生缸压力可以用来标定不同工况下车辆颗粒物的排放。
