基于改进ML-KNN算法的文本分类研究
2020-03-24邢娟韬白金牛
邢娟韬 白金牛


摘 要:由于传统ML-KNN算法数据集中每个特征具有相同权重,与事实上的不同特征具有不同权重相违背,故提出对ML-KNN算法的改进,用ML-KNN来构建分类模型进行分类。为验证该算法的分类效果,选取算法常用的衡量标准与其他两种算法比较,结果表明由改进ML-KNN算法构造的模型要优于其他两种算法,能有效表达多领域数据集分类问题,算法效果更好。
关键词:多标记学习;ML-KNN;最近邻;聚类;距离权重
中图分类号:TP311 文献标志码:A 文章编号:2095-2945(2020)09-0025-03
Abstract: Because each feature in the data set of the traditional ML-KNN algorithm has the same weight, which is contrary to the fact that different features have different weights, an improvement to the ML-KNN algorithm is proposed, which uses ML-KNN to build a classification model for classification. In order to verify the classification effect of the algorithm, the commonly used criteria of the algorithm are compared with the other two algorithms. The results show that the model constructed by the improved ML-KNN algorithm is better than the other two algorithms, and can effectively express the classification problem of multi-domain data sets, and the effect of the algorithm is better.
Keywords: multi-marker learning; ML-KNN; nearest neighbor; clustering; distance weight
1 概述
传统的单标记分类任务是将一个样本映射到单个类别标签L(L=1)中;当L=2,该分类问题就是“二类分类”;当L>2,该分类就是“多类分类”,也称为多标记分类问题[1-2]。该方法已应用到很多新的领域,如音乐分类[3]、蛋白质功能分类[4]、Web挖掘[5]以及图像和视频的语义分类[6-9]。ML-KNN(Multi-Label K-Nearest Neighbor)就是典型的多标签分类算法。在ML-KNN算法中的数据集,每个特征具有相同的特征权重。事实上,对于数据集中的每一个样本,它的k个近邻的标签集合理论上应该跟它自身的标签集合有一定程度上的相似,这种相似度会随着近邻到样本距离的改变而改变,而且距离大,相似度越小。故不同特征所承担不同权重,ML-KNN算法并没有讲这一问题,故提出对ML-KNN算法的改进。
2 方法描述
2.1 ML-KNN算法
ML-KNN算法思想:给定一个分类预测点x,计算预测点到训练数据集中所有点的距离。采用交叉验证方法得到最优K值,结合贝叶斯方法并运用最大化后验概率,由式(1)得到预测点x的预测结果Y。
2.2 改进ML-KNN算法
基于上文提出的ML-KNN算法弊端,利用权重来解决这一问题。提出新的分类函数:
其中:w表示由x的最近邻到x的距离所转换而来的权重,也是x的最近邻在本文改进算法中的权重;1-w则表示x的k个近邻的权重;NNx(li)表示x的最近邻样本是否含有li标签,可能为0可能为1。w取最合适的高斯函数:w=a?鄢e■,a和c是常数;d表示欧式距离。算法具体步骤如下:
输入:训练数据集、测试数据集。
输出:分类结果。
(1)利用k-means聚类算法将训练数据和测试数据分别分为r(R1,R2,...Rr)个聚类中心,t(T1,T2,...,Tr)个聚类中心;
(2)计算Ti到Rj的欧式距离D(Ti,Rj),其中i=1,2,...,t,j=1,2,...,r;
(3)取2步骤中最短的欧式距离记为Rj,其中j=1,2,...,r;
(4)将Ti对应的簇作为新的测试集,记为NewY;
(5)將3步得到的Rj对应的簇作为新的训练数据,记为NewX;
(6)对于每一个xu∈NewX,计算每一个li∈L的先验概率:
(7)采用交叉验证法得到xu的K个近邻,获取最近邻距离d,并运用上文提及的高斯函数转化为w;
(8)计算li∈L的后验概率:
(9)利用新的分类函数2式计算每一个zv∈NewY拥有li的后验概率,得到终极结果。
3 实验结果与分析
3.1 数据集和文本预处理
本文实验数据来自新浪微博平台,通过爬虫获得,共计4000多条,其中训练样本3000条,测试样本1000条,训练样本集包含时尚、娱乐、体育、新闻、影视、科技、美食、人文、医药、护肤、情感、历史、经济、健康、游戏15个标签类别。具体如下:
本文使用jieba中文分詞模块对样本博文进行分词,可以有效处理未登录词语的识别问题,能够适应市场需求,使用TP-IDF方法实现文本的特征提取。
3.2 评价指标
本文选取5个常用的多标签评价指标:汉明损失、1-错误率、覆盖率、排序损失、平均精度。其中,汉明损失、1-错误率、覆盖率、排序损失的值越小表示分类性能越好,平均精度的值越大表示分类性能越好。
3.3 实验结果分析
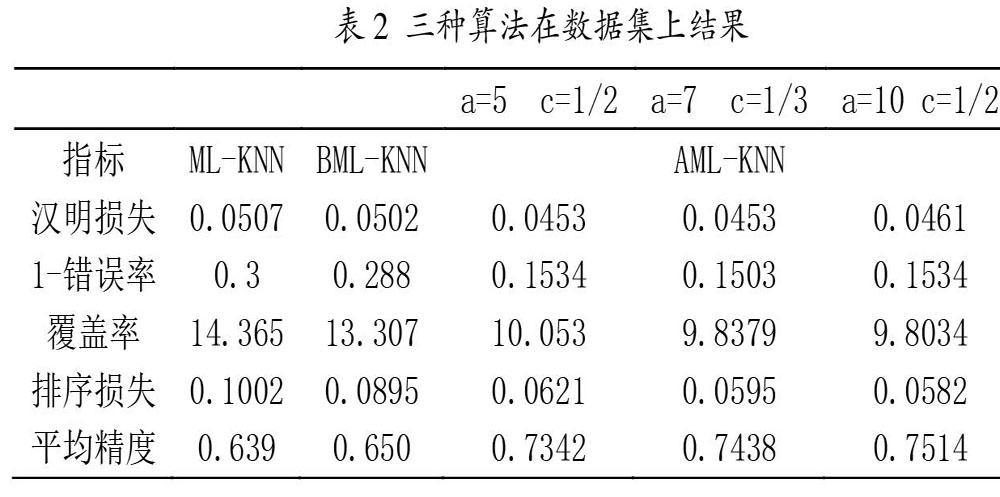
由上述算法的描述可知,有最近邻K 值、高斯函数a、c两个参数、训练数据r个聚类簇数、测试样本t个聚类簇数。其中K值由交叉验证法取15,a、c取值如表2,为了验证改进ML-KNN算法的性质,将改进ML-KNN算法记为:AML-KNN,文献[10]中提出的改进算法称为BML-KNN,在MATLAB上实现。
由表2可知:当a=10、c=1/2时,算法效果最好。同时由上述算法易知:不同聚类簇数对本文算法也有至关重要的影响,如表3所示,当a、c确定时,聚类簇数不同对算法性能的影响。
表3 数据集上不同聚类簇数的影响
由表3可知,本文所选数据集在r=2,t=2效果最好。
4 结束语
针对ML-KNN算法中的数据集,每个特征具有相同的特征权重这一问题,对ML-KNN算法优化,结合聚类和最近邻距离权重,本文提出的改进ML-KNN算法在实验结果上,取得了很好的分类效果,并且在多标签评价指标上也优于其他两种算法。
参考文献:
[1]Gao Sheng,Wu Wen,Lee C H,et al.A MFoM learning approach to robust multiclass multi-label text categorization[C]//Proc of the 21st International Conference on Machine Learning.San Francisco:Morgan Kaufmann Publisher,2004:329-336.
[2]Zhang Minling, Zhang Kun. Multi-label learning by exploiting label dependency[C]//Proc of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York: ACM Press, 2010:999-1007.
[3]Li Tao,Ogihara M.Toward intelligent music information retrieval[J].IEEE Trans on Multimedia,2006,8(3):564-574.
[4]Zhang Minling,Zhou Zhihua.Multi-label neural networks with applications to functional genomics and text categorization[J].IEEE Trans on Knowledge and Data Engineering,2006,18(10):1338-1351.
[5]Tang Lei,Rajan S, Narayanan V K. Large scale multi-label classification via metalabeler[C]//Proc of the 19th International
