基于sigmoid函数的题目难度值动态调整算法的设计
2020-03-23莫怀训刘晓瑞
莫怀训 刘晓瑞

摘 要:本文主要针对各级各类信息化教学或考试系统中的题库题目难度值进行讨论,分析如何进行分布计算并动态调整。本文将难度值定义为错误率,即错误次数/调用总次数,再进一步分析发现根据本定义直接进行计算的方法需要进行改进,可用sigmoid函数进行拟合,并在此基础上设计出分布计算算法和线性叠加算法。通过本方法,各终端无须额外存储其他数据,仅根据当前题目回答错误情况即可更新难度值;同时也无须连线中心服务器,可独立分布计算,然后线性叠加即可获得最终难度值。因此可在一定程度上降低整个题库系统设计的难度,同时也可以看出本方法对存储敏感型和去中心的任务具有一定参考价值。
关键词:题目难度值;sigmoid函数;分布计算;线性叠加
中图分类号:TP301 文献标识码:A
1 引言(Introduction)
在信息化教学系统及目前各级各类等级考试系统中,题库是其中的重要内容,它承担着对学员训练、考核以及选拔等重要功能。题库中基本元素就是题目,而题目的形式、内容、难度等特征就是题库根据考核目标抽取题目组成测试卷需要考量的基础数据。其中试卷整体难度值和试题难度分布情况是组卷系统考虑的非常重要的两个指标,而试卷整体难度值、难度分布很明显是基于试卷各题目难度值来计算的[1]。
从实际情况来看,我们一般根据经验或过往的大量统计数据来确定一道题目的难度值,很明显这样效率低下而且往往并不一定符合实际情况。特别是一道题目面对不同学员群体时,难度值实际上是不同的,例如某一道电工计算题对于职业学校普通学生可能难度值较高,但对于经过培训的考证学员可能难度值中等。因此我们需要针对难度值设计一种计算方法,使得题目难度值在使用中动态调整,并逐渐符合实际情况[2]。
2 题目难度值的定义(Definition of difficulty value)
对于一道题目,其难度值可以从得分率、平均完成时长、错误率等维度去考虑。目前各级各类理论考试题库中,最常见的题型是选择题,实际上填空题、计算题、判断题等都可以变形为选择题而不减弱其测试效果,所以很多理论题库甚至只有选择题[3]。而对于选择题,一般不存在部分得分,因此使用错误率去代表难度值就比得分率合理。另外在一般考试过程中,试题作答没有顺序要求,考生可以根据实际情况灵活选择试卷前后的题目来作答,因此准确统计一道题目的平均完成时长较为困难。所以在本文中,题目难度值主要根据本题在实际使用中的错误率来代表[4],公式如下:
其中,总次数=错误次数+正确次数。错误率越高代表难度越高,调用的次数越多该值会越趋近于实际难度。从公式可以总结出难度值分布应该具备的基本规律如下:
難度值在0—1。
当错误次数趋近于总次数时,难度值趋高,为1时表示难度最高。
当正确次数趋近于总次数时,难度值趋低,为0时表示难度最低。
当正确次数=错误次数时,难度值=0.5,与总次数无关。
3 难度值计算方法的初步分析(A preliminary analysis of the calculation method of difficulty value)
对于一道未知难度的题目,最开始很自然可以假设学员做错的概率与正确的概率一样。即假设如已经调用次数为10000,则错误次数为5000,那么难度值初始值为0.5。
难度值随着错误次数增加的表达式y=(5000+x)/(10000+x),如图1所示。难度值随着正确次数增加的表达式y=5000/(10000+x),如图2所示。根据表达式易看出,调整次数初始假设值,对曲线的基本形态没有影响,但对难度值随着错误次数变化快慢有较大影响。
首先我们需要针对每道题单独存储错误次数及调用次数,随着系统规模的扩大和用户使用人次的增加,最终可能会导致存储需求超出预算;其次错误次数增加及正确次数增加,实际表达式不一样,不利于将来对系统进一步的分析;最重要的是如果起始假设总调用次数太小,则难度值对错误次数太敏感,波动大,起始假设总调用次数过大,则难度值又变化不明显,两者都会导致动态调整时间过长,对系统使用造成不便,而应该假设为多少则难以进行合理分析。
4 难度值计算方法的优化(Optimization of calculation method)
4.1 基于sigmoid函数的拟合
仔细考察上面图1和图2。如果我们把错误次数定义为正值,正确次数定义为负值,即图2以y轴对称翻转,然后把它们连接在一起。我们可以很容易发现连接图形与sigmoid函数图像非常相似,如图3所示[5]。
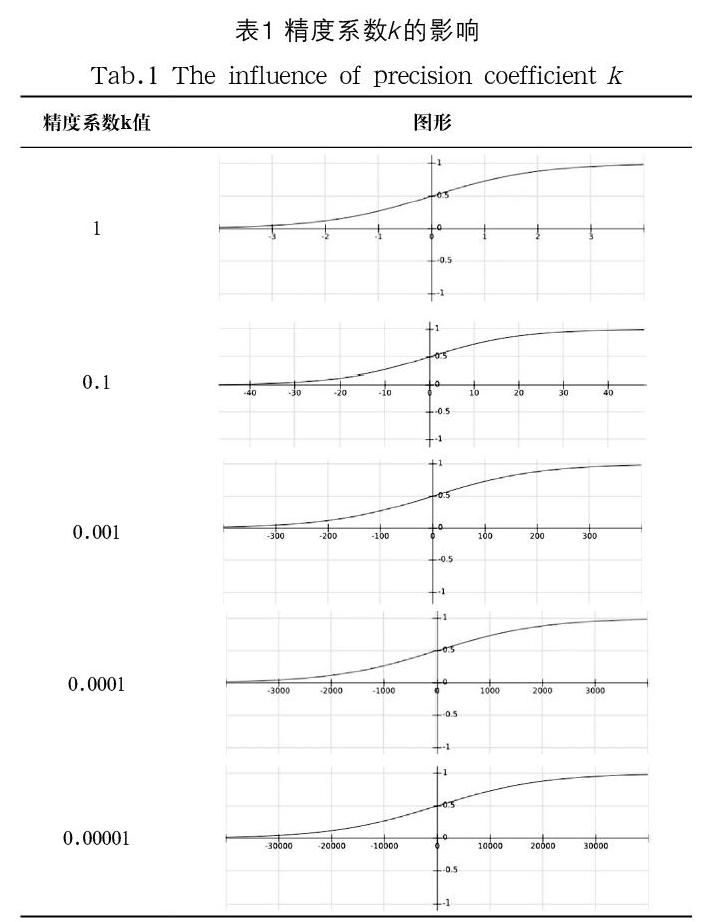
4.2 精度系数k的估算
精度系数主要根据题库面向对象的范围来确定。
例如本项目题库主要面对本校中职生源,而我校一届机电类中职生约300人,本题库题目生命周期暂定为10年,则对应人数约3000人,每人每学期针对某一道题可能会作答四次,即学习时一次,复习时一次,期中测试一次,期末考试一次。也就是每道题可能会被作答12000人次。假设对于某道题,有95%的同学人次错误,即大约有11000次错误,则错误净值x=11000-(12000-11000)=10000,难度值y应约等于1;同理如有95%的同学正确,则x=-10000,y约等于0。
查阅表1可知k取值范围在(0.00001—0.0001)。经过实验,k取0.0004,如图4所示。从图中可以看出,此时当x≥10000时,难度值y≈1;当x≤-10000时,难度值y≈0;当x=0,即一半人错误一半人正确时,难度值y=0.5。曲线对难度值变化拟合度非常高,完全符合本文第2点对难度值总结的四条基本规律。
4.3 分布计算的合并处理
我们题目难度值可以在后台根据数据统一计算,这种方法比较简单,但需设置一个中心服务器来处理。
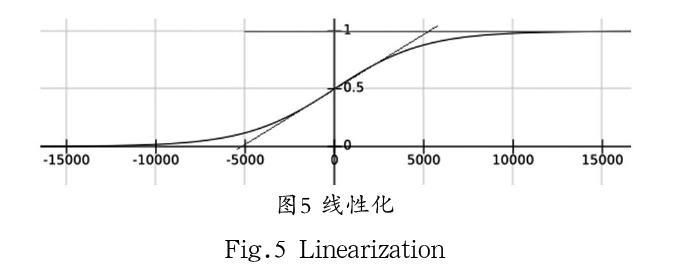
如果难度值与错误净值在一定的范围内呈线性关系,那么难度值可分布在各终端独立计算,需要合并时线性叠加即可。观察图5可发现难度值变化曲线是分3段近似线性的。因此我们可以将其线性化,得到叠加计算方法。
对于点(0,0.5)两侧邻域的曲线,其一阶导数,二阶导数,也就是说对于该点两侧邻域的曲线等价于直线,将该点代入后可得,所以我们采用直线来拟合点(0,0.5)两侧的曲线。
随着邻域的不断扩大,拟合误差也不断增大。当拟合直线与y=1、y=0分别相交后,拟合直线分别转变为y=1、y=0。交点分别为、,因为,所以,故此时误差达到最大。如果我们对误差要求较高,则应适当调整拟合直线的斜率,使得最大误差符合我们的要求。
因此如果误差?y≈0.12合适的话,我们可以将难度值曲线简化为三段折线:以点(0,0.5)为中心,在的范围内,近似为直线;在的范围内近似为直线y=1;在的范围内近似为直线y=0。
(2)叠加算法
假设目前对于某道题,我们从两个终端分别获得难度值、,那么叠加方法如下:
对于区间,其中n为可能的总人次数,而难度值函数自变量x是错误净值,也就是x=错误人次数-正确人次数,所以一般来说本区间应该覆盖了x的很大部分取值范围。因此我们首先考虑以直线来进行叠加。对于,有,对于,有,所以,从本式可以看出,拟合直线斜率的调整完全不影响叠加算法的结果。
如果,则表明难度值进入到拟合直线y=1的区域,故此时y=1;
如果,则表明难度值进入到拟合直线y=0的区域,故此时y=0。
5 算法设计(Design of algorithm)
5.1 递推计算方法的推导
如果考虑到存储优化及计算过程优化,我们往往希望不需存储所有次数的情况,只要存储最新的操作情况即可更新难度值,那么我们必须设计出递推算法。其推导过程如下:
容易导得难度值函数的微分。
而,在本问题中自变量x每一次最小的变化为1,即。
所以,因此可得难度值递推公式如下:
6 结论(Conclusion)
本算法的优点在于动态调整算法简单可行,对于题目只需要存储当前难度值,然后根据当前作答的正确或错误情况动态调整即可;同时本算法可以使得难度值计算分布在各终端进行,当进行合并时只需线性叠加即可,特别的是,我们发现拟合直线根据精度要求调整斜率完全不影响叠加算法。另外给出了拟合实际数据的精度系数k的预估方法,并有较合理可信的解释。因此本算法的优化方法对一些存储敏感型或去中心化的任务具有一定的参考价值。
本算法的缺点在于主要只考虑了错误率对于题目难度值的影响。对于某些可能采用单题应答时间限制或者可以部分得分的考试形式,题目难度值还应考虑平均完成时间或者得分率。因此本算法还需进一步完善,以期适应更多不同的题库系统。
参考文献(References)
[1] 李俊杰,张建飞,胡杰,等.基于自适应题库的智能个性化语言学习平台的设计与应用[J].现代教育技术,2018,28(10):5-11.
[2] 王玥.自适应测验中题库的构建及其有效性检验[D].山东师范大学,2019.
[3] 刘宪爽,吴华明,肖文波,等.改进的双Sigmoid函數变步长自适应算法及在OCT中的应用[J].电子学报,2019,47(01):234-240.
[4] 张春霞.基于Matlab的自动组卷系统的设计与实现[D].内蒙古大学,2018.
[5] 叶勇,刘秀华,叶琰,等.基于LaTeX的题库管理与组卷系统设计[J].西南师范大学学报(自然科学版),2018,43(03):181-186.
作者简介:
莫怀训(1978-),男,硕士,高级讲师.研究领域:电气自动化,计算机控制,智能教育技术.
刘晓瑞(1980-),女,硕士,讲师.研究领域:前端设计技术,数据库,青少年计算机社区教育.
