基于PCA主成分分析和K-means算法的汽车行驶工况数据量化研究
2020-03-20王沛陈劲杰
王沛 陈劲杰


摘 要:随着我国经济的快速发展,从汽车大国到汽车强国的逐步转变,汽车数量也急剧增加。本文针对轻型汽车实际道路行驶采集的数据(采样频率1Hz),处理为各个运动学片段,采用PCA结合K-means++聚类方法,对处理后数据样本进行降维处理,分析其中主要特征成分,将各运动学片段依据综合特征指标归类,计算主要特征参数,使用相关系数筛选典型特征片段。构建典型汽车行驶工况曲线。使用K-means聚类处理数据段,计算处理结果并分析与总体样本特征偏差范围,判断工况曲线构建的合理性,是否符合世界WLTC工况标准。结合汽车标准行驶工况比较分析综合特征指标差异。
关键词:PCA;K-means++聚类;汽车标准行驶工况
中图分类号:TP18 文献标识码:A
Abstract:With the rapid development of the Chinese economy,the number of cars has also increased dramatically,since the gradual transformation from a large automobile country to the car power.This paper focuses on the data collected from the actual road driving of the light vehicle (sampling frequency 1Hz),then processes the data into each kinematic segment.Using PCA combined with K-means++ clustering method,the processed data samples are subjected to dimensionality reduction processing.Then the main characteristic components are analyzed.Each kinematic segment is classified according to the comprehensive feature index.Then the main feature parameters are calculated.Lastly,the correlation feature is used to filter the typical feature segments.The typical vehicle driving condition curve is constructed.The K-means cluster is used to process the data segments.The processing results are calculated,and the deviation range from the overall sample characteristics is analyzed to determine the rationality of the construction of the working condition curve and whether it meets the world WLTC working condition standard.The characteristics and difference of the comprehensive characteristic indicators are compared and analyzed in combination with the standard driving conditions of the automobile.
Keywords:PCA;K-means++ clustering;automotive standard driving conditions
1 引言(Introduction)
在信息量丢失最小的前提下,主成分分析法可以将多个特征参数变量进行降维找出少数的几个主成分。本文主要将PCA主成分分析和K-means算法结合,对处理后数据样本进行降维处理[1],分析其中主要特征成分,将各运动学片段依据综合特征指标归类,计算主要特征参数,使用相关系数筛选典型特征片段。構建典型汽车行驶工况曲线。对比传统K-means和优化后K-means++聚类处理数据段,计算处理结果并分析与总体样本特征偏差范围,判断工况曲线构建的合理性。结合汽车标准行驶工况比较分析综合特征指标差异。
2 总体设计路线(Overall design route)
所给数据是同一辆汽车在不同时间段的实际行驶数据,数据量大约50万条。根据相关研究文献数据,本文运用数学建模的方法进行筛选,使用插值方法、平滑处理方法(smooth函数)、Excel过滤筛选功能进行数值预处理,由于主要研究的是工况曲线构建的合理性,所以对于以上的方法暂不赘述。之后对处理后的数据划分为多个运动学片段,通过网上查找资料可知,将车辆从一个怠速开始到下一个怠速开始的运动定义为运动学片段,车辆的行程即可视为各种片段的组合。其中某些片段反映的交通状况可能相同,不同的地理位置及时间和公路类型会出现相同的片段,有时高速公路上的片段可能和拥挤的城市中的片段完全一致[2]。将这些片段类型和交通状况联系起来,针对性地分析不同速度的运动形态。通过筛选数据中的怠速区间,对经预处理后的数据进行后划分成多个运动学片段,并结合汽车运动相关知识计算各运动学片段的运动参数指标。
5.2 工况验证
将采集的行驶数据作为总体样本数据,选取平均速度V、加速段的平均加速度A减速段的平均加速度aa、怠速比例P、加速比例P。减速比例P15个特征参数作为判定准则,并基于K-means和融合优化后的K-means++算法计算各特征参数向量[7],与构建的车辆行驶工况与总体样本数据进行对比,各工况下的特征参数值,详见表7。
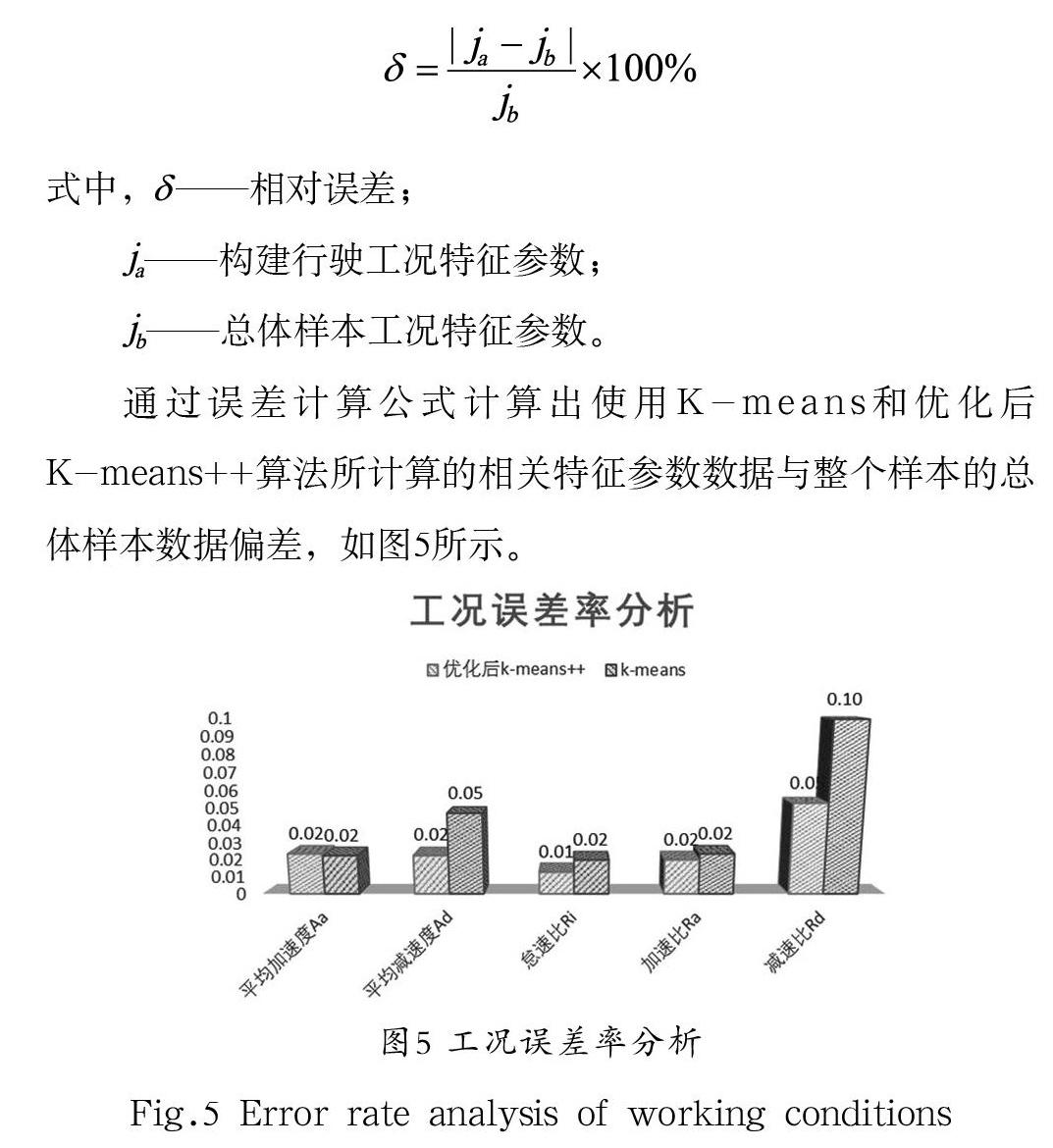
经过K-means和优化后K-means++算法所计算的相关特征参数数据与整个样本的总体样本数据具有一定偏差,因此从中选择一定的特征参数作为分析的指标,分别计算构建的道路行驶工况与道路行驶工况总样本的相对误差,根据所计算的结果来分析构建出的工况是否有效。误差计算公式如下:
式中,——相对误差;
——构建行驶工况特征参数;
——总体样本工况特征参数。
通过误差计算公式计算出使用K-means和优化后K-means++算法所计算的相关特征参数数据与整个样本的总体样本数据偏差,如图5所示。
6 结论(Conclusion)
可见构建的行驶工况特性与总体样本行驶工况特性有一定的偏差,但所取的五个特征参数能够大部分反映行驶工况综合特性,误差率都控制在10%,属于可接受范围。使用K-means算法和优化后K-means++进行比较,优化后的K-means++算法在一定程度上相对于K-means聚类算法减小了与真实样本数据的偏差值,计算结果更接近于总体样本行驶工况。
在国际标准行驶工况中,我国直接采用欧洲的NEDC行驶工况,NEDC工况为基准所优化标定的汽车,实际油耗与法规认证结果偏差越来越大,影响了政府的公信力(譬如对某型号汽车,该车标注的工信部油耗6.5升/100公里,用户体验实际油耗可能是8.5—10升/100公里)。另外,欧洲在多年的实践中也发现NEDC工况的诸多不足,转而采用世界轻型车测试循环,但标准工况往常难以代表实际行驶工况。通过计算构建行驶工况与标准工况的偏差,可以分析了解各标准工况与实际行驶工况之间的差异。选取NEDC行驶工况和WLTC行驶工况进行比较,并选取工况时间、平均加速度、平均减速度、平均速度四个指标作为参考,如图6所示。
由图分析可知,测试工况时间介于两种工况之间,基本符合世界WLTC工况标准,在平均速度特征指标上落后于NEDC和WLTC标准工况[8],在平均加、减速度上均大于两种标准工况值,且特征指标偏差较大。因此,对于实际行驶情况有必要制定对应当地对应的汽车行驶工况。
参考文献(References)
[1] Chen Y,Lin Z,Zhao X,et al.Deep learning-based lassification of hyperspectral data[J].IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing,2014:18-26.
[2] Alisa Arunamata,Jesse Stringer,Sowmya Balasubramanian,et al.Cardiac Segmental Strain Analysis in Pediatric Left Ventricular Noncompaction Cardiomyopathy[J].Journal of the American Society of Echocardiography,2019(6):57-68.
[3] Ho,Sze-Hwee,Wong,Yiik-Diew,et al.DevelopingSingapore Driving Cycle for Passenger cars to estimate fuel consumption and vehicular emissions[J].Atmospheric Environment 2014,97:353-362.
[4] 姜平,石琴,陳无畏,等.基于小波分析的城市道路行驶工况构建的研究[J].汽车工程,2011(1):70-73.
[5] 梁聪,夏书银,陈子忠.基于参考点的改进k近邻分类算法[J].计算机工程,2019(02):167-178.
[6] 吴信东,嵇圣硙.MapReduce与Spark用于大数据分析之比较[J].软件学报,2018(06):1770-1791.
[7] 祁力钧,程一帆,程浈浈,等.基于M-K聚类法的果树上下冠层体积比测算[J].农业机械学报,2018(05):45-49.
[8] 石则强,纪常伟,王伟,等.车辆燃料消耗量计算方法研究[J].车辆与动力技术,2010(04):19-24.
作者简介:
王 沛(1994-),男,硕士生.研究领域:人工智能.
陈劲杰(1969-),男,硕士,副教授.研究领域:智能机器人,机器学习.
