笔迹书写形成方式判别的系统开发研究
2020-03-17张兴鹏任宇波
张兴鹏 任宇波
(1.天水市公安局麦积分局,甘肃天水 741020;2.北京市公安局大兴分局,北京 100076)
前言
随着网络科技的日益发展,良莠不齐的信息时刻充盈在人们的生活中,为此,互联网科技通过运用贝叶斯的先验概率,建立判别分类模型,对垃圾进行识别拦截,有效地抑制了垃圾短信、邮件信息的泛滥。这也充分的说明贝叶斯先验概率算法在分类模型中的优异属性。
对于非正常笔迹的识别,传统方式主要是通过办案人员对笔迹检材的介绍或者借助司法鉴定人员的经验以及知识理论体系,依据司法鉴定员知识理论体系中非正常笔迹特征的差异性,与样本笔迹表现出的笔迹特征进行比较、分析,最终确定其书写形成方式。虽然传统方式亦能够较为成熟的对笔迹的形成方式进行有效判别,但传统的判别方式依据鉴定人员知识理论体系的完备和准确具有较大的主观性。分类模型是依据大量实验样本数据的采集数据,对不同笔迹的形成方式进行科学的概率判断,max求得为最优分类,其他概率较小的即为疑似笔迹形成方式,具有较强的科学性和系统性。
1 先验概率与后验概率的比较
传统的后验概率统计理论是把常识用数学公式表达了出来(拉普拉斯语),即认为某件事的发生概率是介于0到100%之间的某个具体数值,例如传统概率理论认为硬币某一面朝上的概率为P=50%,抛硬币游戏中,其某一面朝上的次数约等于总抛币次数的一半。即样本可变而概率固定。而贝叶斯学派的观点截然相反,贝叶斯先验概率理论认为参数是随机变量,而样本却是固定的,因而主要研究参数的分布,贝叶斯概率模型是将人脑在已知条件下做出直觉判断的一种数学表示。通过对大量样本的分析,最终得到该种条件下发生的具体概率大小,例如在抛硬币实验中,传统后验概率的成立前提是硬币材料加工等诸多条件完美的呈现理想对称状态,显然绝对临界状态是极难达到的,贝叶斯理论的先验则可以通过多次抛币,得到该硬币在该条件下的某面朝上的概率,与该硬币的本身是否临界对称没有必然联系。
2 模型样本数据的采集
贝叶斯分类模型是否能够准确的实现分类的决策,关键依据数据库的建立,在数据采集过程中,对类型的选择主要选择了醉酒笔迹,强行加速书写笔迹,左手伪装笔迹,老年人书写笔迹以及摩仿笔迹等五种类型的非正常笔迹。在理论上而言,随着变量之间独立性的增强,朴素贝叶斯概率的概率计算准确率随之增高,因此尽量选择相对独立的变量,以期减少贝叶斯模型的误差率,使之达到最大准确率。综合各个醉酒笔迹样本特征出现的概率,选取相对独立且发生改变的变量作为本模型的变量,字间的大小、书写速度、是否出现反复的缠绕现象、收笔长度、过度线条痕迹、笔画是否弯曲抖动、笔画是否缺失、是否存在多余笔画(虫形线条)、修饰重描、文字形状是否异常等笔迹异常的特征属性。
3 离散型朴素贝叶斯的算法研究
离散型朴素贝叶斯在分类实践中在金融行业,垃圾信息筛选,医疗,市场营销等诸多领域都有重要的应用。其先验概率中,条件概率的计算公式为:

式中:A——类别属性;
B——特征属性。
该公式表示,在B 条件下,发生A 类别特征的概率。
当多个特征时,B 特征为特征集合Bj,贝叶斯定理公式表示为:

朴素贝叶斯分类器模型广泛应用于分类模型,假设各个变量相互独立,假设有变量集A={A1,A2,A3……An}包含满足要求的n 个条件属性,C={C1,C2,C3……Cn},则在朴素贝叶斯模型中条件属性集合Aj有均为类型Ci的子节点,建立分类模型。将预测待分类样本依条件提取W={w1,w2,w3……wn},并依次代入类型Ci(1≤i≤n),依次求解出现满足该条件相应的P(Ci|W)(1≤i≤n),依据概率的大小进行最优化分类。其中假设各变量间绝对独立则:

在分类模型中的分母不影响大小的比较,因此有:
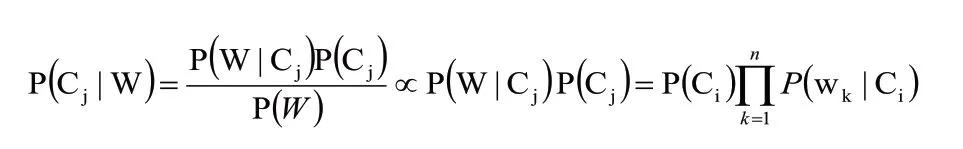
即该模型选出的最优解则为:

4 离散型朴素贝叶斯算法的编程实现
显然,用excel的函数可以完成对离散型朴素贝叶斯分类的计算,但是在该过程中,需要反复的进行函数使用,较为复杂,且容易出现差错,数据的更改也会对函数公式区域产生影响,因而笔者采用编程完成对该算法的实现,可以采用诸多编程语言较多,如MATLAB、C语言、C++,以及Jave 等,但这些语言都较为繁琐,其书写较为繁复且落后,再者matlab 被MathWorks 公司对华限制,因此经过反复比较,由于python 的简洁性、易读性以及可扩展性,再者python 简洁美观、易于学习掌握,因此近些年在国内外呈线性增长,基于此,本实验采用“python 3.8.2 for Windows”语言,在Pycharm编辑器上完成程序编写和运行。
4.1 评估模型的估算器准确性
为了避免过拟合(Overfitting)情况,在进行机器学习实验时,通常取出部分可利用数据作为测试数据集(test set)进行交叉验证。醉酒笔迹、强行加速书写笔迹、左手伪装笔迹、老年人书写笔迹以及摩仿笔迹的数据分别采集70份后,依次对上文提及的特征进行判断,存在即赋值为1,否则为0,即得到350 份笔迹样本数据,在该程序中,选择了rate=25%进行准确率测试得知在该数据库下,该模型的准确率达到80%,并且该准确率会随着数据库的数据加大,准确率逐步提升。测试准确率的主要程序如下所示:


4.2 离散型朴素贝叶斯模型的实现
朴素贝叶斯分类是经典的智能分类模型,可以通过笔迹特征的识别,依据其特征属性,判断该未知笔迹类型的书写形成方式,并初步对可疑样本进行智能自动分类。通过python 编程过程中,利用python 具有强大的开源模块这个特点,引入时下机器学习领域中常用的sklearn模块,从sklearn中调用MultinomialNB和classification_report 等关于贝叶斯与数据处理的函数模块,实现朴素贝叶斯的自动运算。
如图1 所示,当测试特征属性的数列test=[1,1,1,1,1,1,1,1,1,1,0]时,其预测结果为醉酒书写笔迹,且有概率可以看出,虽然为MAX类型概率高达63.9%,但其老年人书写笔迹的概率也高达35.9%,即最佳预测可能为醉酒笔迹,但需要注意其是否为老年人书写形成笔迹,亦或是老年人书写的醉酒笔迹。本实验中运用的样本为64周岁的老人在醉酒状态下所书写该预测结果与实际相符。

图1 预测样本(左)与预测结果以及概率
5 总结
离散型贝叶斯模型在决策树分类中具有重要的作用,在上文中均已进行阐述,此处不再详述。在笔迹形成方式的判别领域一直未对其进行有效运用,本文通过实验表明,该模型在笔迹司法鉴定的实际运用中具有重大的作用,可据此对笔迹的形成方式进行有效判别,为司法鉴定工作提供理论依据和实践指导。该模型是在pycharm软件上完成python代码的编撰,该软件的运用对于未进行训练的鉴定人尚有难度,因此若能编写前端输入口,使得该数据库以及代码成为后端,将会使其更为方便。
