基于深度学习的无人机土地覆盖图像分割方法
2020-03-09刘文萍宗世祥骆有庆
刘文萍 赵 磊 周 焱 宗世祥 骆有庆
(1.北京林业大学信息学院, 北京 100083; 2.北京林业大学林学院, 北京 100083)
0 引言
土地覆盖动态变化是全球变化过程中的重要因子[1],土地覆盖分类是研究土地覆盖动态变化的基础[2-3],包含准确分类数据的土地覆盖图同时能够为农业监控、城乡规划、生态服务研究以及土地政策制定等工作提供关键信息,具有重大的现实意义[4-9]。
编制土地覆盖图所需数据的传统获取方法以人工实地调查为主,该方式需要耗费大量的人力物力,周期长,且无法获得准确的地理分布情况[2]。随着空间技术和计算机技术的不断发展,利用随机森林[10]、支持向量机[11]、决策树[12]、卷积神经网络[13-16]等算法对卫星遥感影像进行图像分析,在土地覆盖数据获取研究中取得了一定的成果,但是卫星遥感影像成本高、时效性差,且分辨率较低,不足以反映地物细节,严重影响土地覆盖类型的识别精度,得到的数据不能满足编制精细土地覆盖图的要求。
近年来无人机低空遥感技术发展迅速,因其机动灵活、成本低廉、成像分辨率高的优点,已成为获取高分辨率遥感数据的重要手段[17],并在土地资源调查、监测与分类领域得到广泛研究和应用[2,18-23]。然而无人机图像的处理方法大部分沿用了处理卫星遥感图像的思路,其工程量巨大,传统图像分析的方法甚至需要人工选取特征参数。
语义分割方法的出现和发展为高分辨率图像分割与分类提供了新的思路。2014年LONG等[24]提出用于语义分割的全卷积神经网络(Fully convolutional networks, FCN),该方法自动完成特征提取,并对图像中所有像素点逐一进行分类,在Pascal VOC 2012图像分割数据集[25]上平均交并比(Mean intersection-over-union, MIoU)为67.2%,远优于基于滑动窗口的方法。此后基于FCN框架的语义分割技术发展迅速,在Pascal VOC 2012图像分割数据集上各项评价指标均有大幅提升[26-32],其中融合编解码结构的DeepLabV3+模型将MIoU提升至89%,该模型能够准确分割不同区域并分类,得到高质量的分割图。但是与大型通用图像数据集不同,无人机高分辨率复杂土地覆盖图像前景不明确,部分图像类间差异小、类内差异大,直接应用DeepLabV3+模型,得到的结果分割精度较低、分类噪声较大。
本文采用深度学习技术,对语义分割模型DeepLabV3+进行改进,应用在包含多种土地利用类型的无人机高分辨率复杂土地覆盖图像上,以分割不同土地覆盖类型的区域。通过训练得到有效的分割模型,并进行实验,验证其性能。
1 数据集
1.1 数据采集
实验数据采集于山东省临沂市郯城县(118°E,34°N),大疆“御”专业版无人机,搭载3轴云台,可控俯仰转动范围-90°~30°,横滚0°或90°,角度抖动量±0.02°;相机镜头为FOV78.8°(35 mm格式等效),原始图像分辨率为4 000像素×3 000像素。各区域完整航片拼接图像如图1所示。

图1 航片拼接图
1.2 数据集建立
为提升模型的训练速度,降低运算量,将拼接后图像尺寸裁剪为512像素×512像素,裁剪后图像共1 296幅。根据《土地利用现状分类》中12个一级类划分方式,使用labelme开源标注工具,对裁剪后的图像逐像素点标注,并按照2∶1的比例随机划分为训练集和测试集,其中训练集图像864幅,测试集432幅,数据集有效类别数为8。
2 分割方法
本文提出的分割方法基于DeepLabV3+语义分割模型,并进行了4点改进:①采用加入扩张卷积的深度残差网络ResNet[33](以下简称ResNet+)作为主干网络,加速模型收敛,提高实验精度。②在主干网络后增加一个联合上采样模块融合多层特征,增强模型编码器的信息传递能力。③调整ASPP模块,移除全局池化连接并采用较小的扩张率组合,避免精度损失。④解码器融合更多的浅层特征,提高模型对特征图包含的空间位置信息的利用能力。原始模型架构如图2a所示,改进后的模型架构如图2b所示。

图2 模型架构
2.1 ResNet+网络
主干网络作为模型编码器的组成部分,主要功能是对特征自动提取。原始模型对Xception[34-35]进行修改,得到Xception+作为主干网络,主要调整包括:①conv5阶段新增8组共24层卷积网络。②conv5阶段的部分网络层替换为扩张卷积,如表1所示。扩张卷积的作用是增大特征图感受野的同时,保持特征图尺寸,避免空间位置信息的损失。以输入尺寸5像素×5像素为例,标准卷积一步操作如图3a所示,卷积核尺寸为3×3,步长为2像素,填充值为1像素,感受野尺寸为3像素×3像素,扩张卷积一步操作如图3b所示,卷积核尺寸为3×3,扩张率为2像素,步长为1像素,填充值为2,感受野尺寸为5像素×5像素。可以看到,扩张卷积能够在增大感受野的同时保持特征图尺寸,既不影响特征描述效果,还可保留丰富的空间位置信息,对语义分割模型来说非常关键。

表1 Xception网络与Xception+网络的结构对比
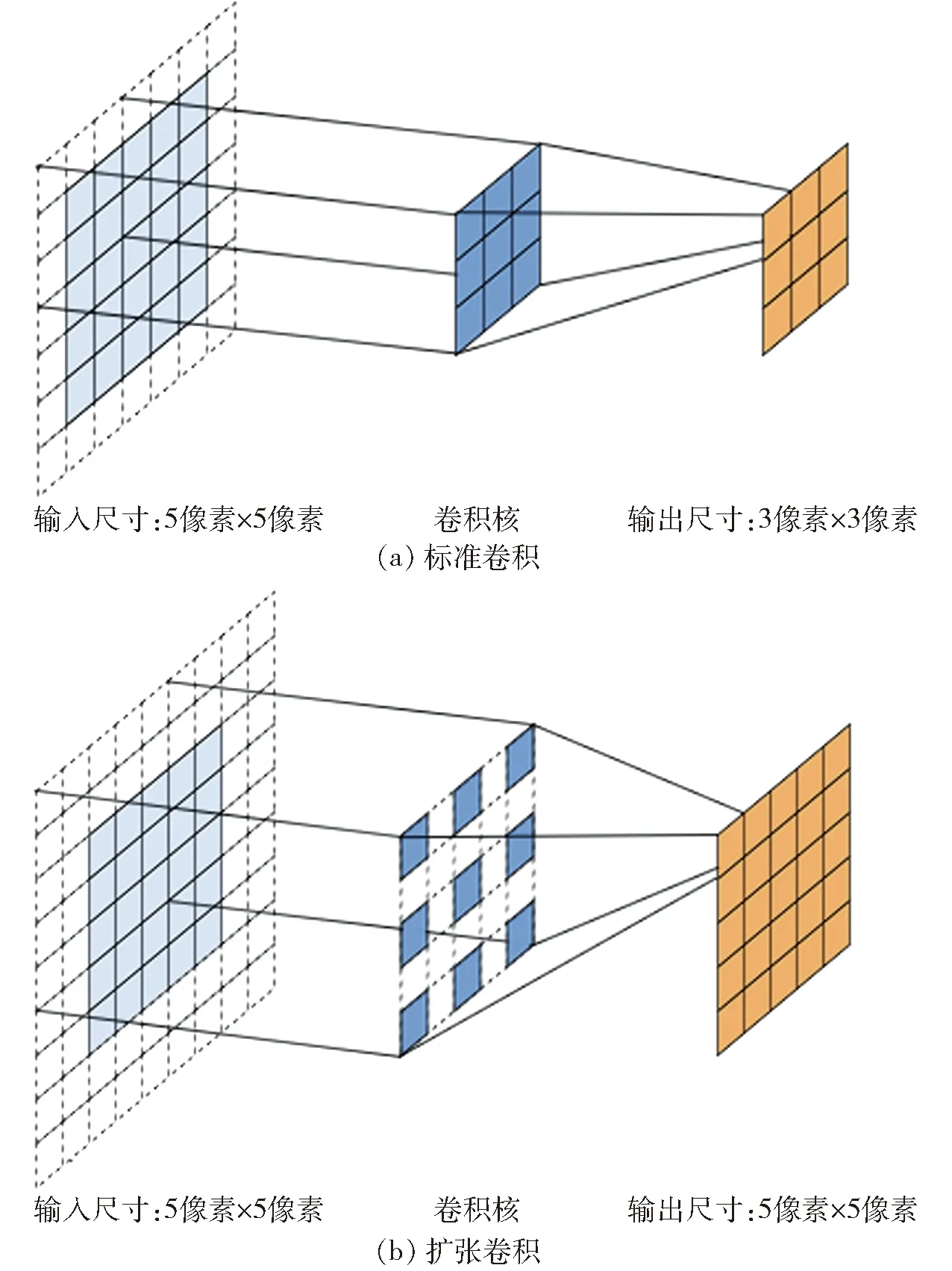
图3 标准卷积和扩张卷积一步操作
但是Xception+作为主干网络,存在以下问题:① Xception+相比原始Xception,网络层数大幅增加,有较高比例的网络层无法加载ImageNet预训练模型的参数,只能进行随机初始化,严重影响模型收敛速度。②Xception+和Xception中均存在大量的可分离卷积,这样的设计能够提升运算效率,但是应用在无人机土地覆盖图像上,对模型精度损害较大。
本文对ResNet网络进行修改,替换conv5阶段的部分标准卷积为扩张卷积,得到ResNet+作为主干网络,如表2所示。ResNet+中不存在可分离卷积,并且扩张卷积层之外的所有网络层,均能加载ImageNet预训练模型参数,进行有效初始化,大幅提升了DeepLabV3+模型的精度和收敛速度。但是主干网络中加入扩张卷积,会增加模型后续阶段的计算成本,因此本文只研究在conv5阶段加入扩张卷积的情况,最终主干网络各个阶段的特征图f1、f2、f3、f4、f5尺寸分别为原始输入图像尺寸的1/2、1/4、1/8、1/16和1/16,如图2b所示。

表2 ResNet网络与ResNet+网络的结构对比
2.2 编码器加入联合上采样模块
在图像分析中,联合上采样旨在利用已有图像作为先验,将其结构化的细节信息传递给目标图像。本文在主干网络之后引入一个联合上采样模块,传递多个不同特征图的信息至主干网络的输出特征图,有效增强了模型编码器信息传递能力,可利用更多结构化信息,提高分类与分割精度;模块还对输入的部分特征图进行采样率为2的上采样,如图2b所示,联合上采样模块接收特征图f3、f4、f5作为输入,分别采用卷积核尺寸为3×3的卷积层进行处理,将f3和f4的通道数降低为512(与f5相等);模块还分别对f4和f5进行一次采样率为2的上采样,然后将3个经过处理的特征图进行逐通道拼接,得到一个新的特征图,用于后续操作。
2.3 调整ASPP模块
原始模型编码器中,ASPP模块结构如图2a所示,该模块由扩张率分别为1、8、12、16的4个扩张卷积和1个全局池化连接组成,用以捕获不同尺寸的目标。但是不同于通用数据集图像,本文数据集中土地覆盖图像经过裁剪后,各土地利用类型区域在图像中所占面积较为接近,尺寸变化幅度小,如图4所示。

图4 通用数据集图像和土地覆盖图像裁剪对比
原始模型中该模块的扩张率组合{1,8,12,16}和全局池化连接降低了分割的精度。本文对原始的ASPP模块进行调整,如图2b所示,采用较小的扩张率组合{1,2,4,8},并移除全局池化连接,以改善模型在本文土地覆盖图像上的分割效果。
2.4 解码器的改进
解码器主要功能是对特征图进行上采样,扩大特征图尺寸以得到最终的图像分割结果。如图2a所示,解码器将主干网络中含有丰富空间位置信息的浅层特征图f2和ASPP的输出特征图f6进行融合,输出一个与原始图像输入尺寸相同的分割图。原始解码器结构较为简单,没有充分利用编码器各个阶段输出的特征图信息。
为此本文对原始解码器进行改进,改进后的解码器如图2b所示,输入为浅层特征图f1、f2、f3以及ASPP的输出特征图f6。首先分别对这4个特征图进行一个卷积核尺寸为3×3的卷积操作,将4个特征图的通道数分别降为48、48、64和256;然后将处理后的特征图f2、f3和f6进行上采样,使其尺寸与f1一致;四者进行逐通道拼接,再经过一次采样率为2的上采样,输出一个与原始输入图像尺寸相同的分割掩码图。
3 实验与结果分析
3.1 实验环境与模型训练
实验在Ubuntu18.04LTS 64位系统下进行,基于Pytorch开源深度学习框架并使用NVIDIA GEFORCE GTX 1080ti显卡加速。模型训练阶段采用动量为0.9的随机梯度下降算法进行优化,初始学习率为0.001,以4幅图像为一个批次进行120次完整迭代,学习率从第100次迭代开始减小为0.000 1,使用交叉熵损失函数,训练过程中进行了简单的数据增广:首先以50%的概率对单幅图像及其标注图像同时进行水平翻转;再以同样的概率,对单幅图像进行随机高斯滤波处理。
3.2 评价指标
为了客观合理地评价模型在无人机土地覆盖图像上的分类与分割精度,本文使用像素准确率(Pixel accuracy, PA)和平均交并比作为评价指标,指标的数值越大,模型的效果越好。
3.2.1像素准确率
像素准确率能够表示像素点分类的精度,用图像中分类正确的像素点数量与像素点总数的百分比来表示,计算式为
(1)
式中pii——像素点i被预测为i的数量
pij——像素点i被预测为j的数量
C——数据集中不同土地利用类型的数量,本文为8
3.2.2平均交并比
平均交并比是语义分割模型的标准度量指标,定义为
(2)
通过计算每一类真实值像素集合和预测值像素集合的交集和并集的比值,得到每一类别的交并比后,计算所有类的平均值即为平均交并比,该指标在实验中能够较好地反映模型在不同利用类型的土地区域上分割的准确性和完整性。
3.3 实验结果分析
不同组成的模型在无人机土地覆盖图像测试数据集上的实验结果如表3所示。模型1为原始DeepLabV3+模型,主干网络为Xception+,在测试集上PA为80.51%,MIoU为55.73%;模型2在模型1的基础上替换主干网络为ResNet+,PA和MIoU分别提升了11.46个百分点和12.50个百分点;模型3在模型2的基础上加入联合上采样模块,PA和MIoU分别比模型2提升了1.55个百分点和10.25个百分点;在模型3的基础上调整ASPP模块后得到模型4,PA和MIoU有小幅提升,分别为93.60%和79.50%;最终应用改进后的解码器得到模型5,PA和MIoU分别提升至95.06%和81.22%,相比原始DeepLabV3+模型即模型1,两个指标分别提升了14.55个百分点和25.49个百分点。
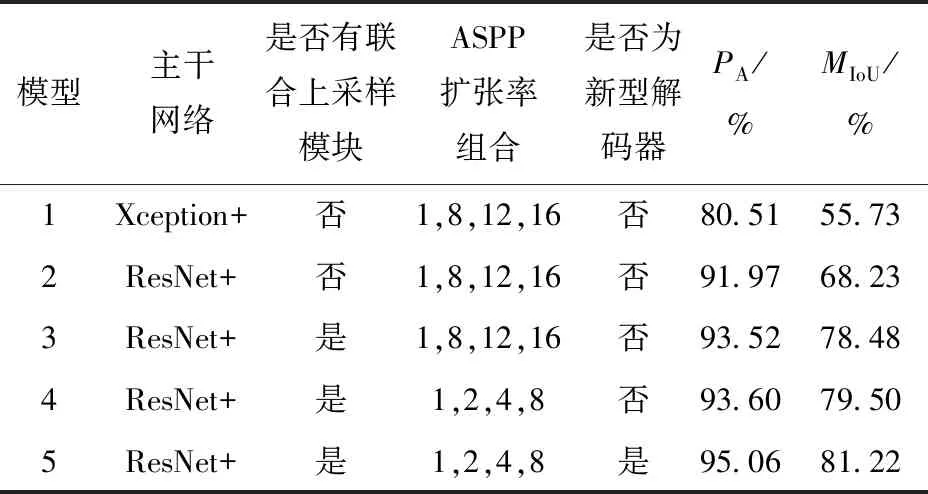
表3 不同模型在测试集上的实验结果
另外,采用相同的数据集和参数分别训练了FCN-8S模型和PSPNet模型,与本文提出的方法进行对比,结果如图5所示。可以看到,常用的FCN-8S模型收敛速度较慢,相同迭代次数的情况下效果最差;原始DeepLabV3+由于使用Xception+作为主干网络,两个指标波动较大,但与PSPNet接近;本文模型的两个指标均为最高,且收敛速度快,对无人机土地覆盖图像数据集的分割与分类效果最好。
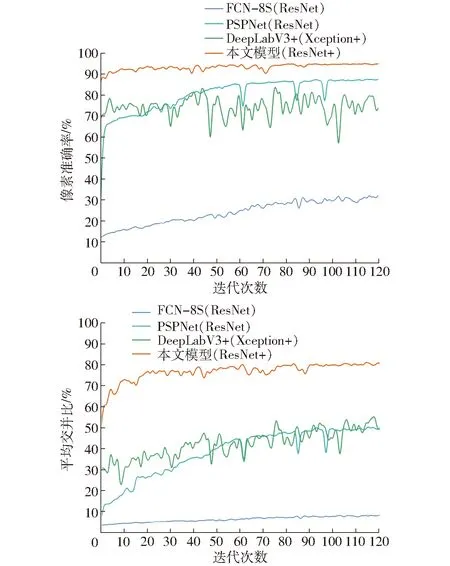
图5 测试集上像素准确率和平均交并比随迭代次数的变化
3.4 分割结果与分析
本文利用多个模型在包含432幅图像的测试数据集上进行实验,部分分割结果如图6所示。可以看到,本文方法在复杂的土地覆盖图像上分割和分类精度都较高,而且对无人机图像拼接过程造成的小幅图像变形具有较高的鲁棒性。
尽管模型取得了较好的效果,但是实验中也出现了一些低质量的分割结果,如图7所示。由图7a可知,当原始图像发生大范围的变形时,模型分割结果会受到严重干扰。图7b中的白框区域中树木遮挡了部分道路,造成分类错误。图7c的白框区域中,耕地的农作物行间种植了较多树木,导致模型的低质量分割结果。

图6 PSPNet、DeepLabV3+和本文模型的分割效果对比

图7 低质量的模型分割结果
4 结论
(1)针对现有土地覆盖数据获取方法成本高、精度低、工程量大等问题,应用深度学习技术,提出一种面向无人机高分辨率复杂土地覆盖图像的语义分割方法。该方法能够对不同土地利用类型的区域进行分割并分类,得到质量较高的土地覆盖数据,用于编制精细土地覆盖图。
(2)该方法基于DeepLabV3+语义分割模型并进行改进,编码器中将主干网络替换为ResNet+,增加联合上采样模块,调整ASPP模块,解码器中融合更多浅层特征。结果表明,本文提出的方法像素准确率为95.06%,平均交并比为81.22%,相比原始DeepLabV3+模型像素准确率提高了14.55个百分点,平均交并比提高了25.49个百分点,能够得到效果更好的分类与分割结果。
