基于迁移学习的FDR土壤水分传感器自动标定模型研究
2020-03-09李鸿儒于唯楚王振营
李鸿儒 于唯楚 王振营
(1.东北大学信息科学与工程学院, 沈阳 110819; 2.沈阳巍图农业科技有限公司, 沈阳 110021)
0 引言
土壤含水率是土壤的重要参数,也是农业灌溉决策、管理中的基础数据[1-2],准确获得可靠的土壤含水率在农业生产中极为重要。近年来,随着传感器技术的发展,利用频域反射技术(FDR)对土壤含水率进行测量,获得了业内的普遍认可,得到了广泛应用[3-5]。
土壤物理性质多种多样,不同地区以及同一地区的不同时间土壤性质也会存在差异,使得FDR传感器在不同土壤中的测量结果不同,因此FDR传感器在某区域首次使用以及使用一段时间后均需重新标定。对于传感器的标定方法已有许多学者进行了研究。文献[6]提出了土壤水分传感器的三级标定方法,即对土壤水分传感器的安装标定、田间标定以及测量数据标定,提高了测量数据的准确性,但标定过程较为繁琐。文献[7]证明了FDR系统适用于检测湿地土壤中的土壤含水率,但校准程序受到土壤性质的限制。文献[8]分析得出,土壤水分站点数据可用性低,是因为田间标定法在自然条件下几乎无法得到覆盖土壤各个湿度区间的均匀样本数据,导致二次标定参数不合理。综合以上研究可发现,FDR传感器标定存在数据采集耗时、费力,可用于标定的有效数据较少,人工操作与参数拟合存在一定误差等问题。
随着科技的发展,机器学习技术在土壤含水率建模方面得到了广泛应用。文献[9]在室内利用ASD FieldSpec 3型高光谱仪获取土壤的原始光谱,在进行数据预处理和不同数学变换后,通过最小二乘回归法、逐步回归法、岭回归法建立了土壤含水率高光谱模型;文献[10]通过对数据进行归一化处理和数据融合,能够根据不同区域进行划分和在不同作物灌水下限进行相应的运算,从而得到估计精度较高、区域大小可调的多尺度精准灌溉决策信息;文献[11]提出电容式土壤湿度传感器大规模校准的半自动化框架,但是不能完全消除数据不确定性带来的影响。如果将不同地区数据进行统计,使用机器学习方法进行标定,则可解决标定的有效数据较少的问题,但不同地区数据特征存在差异。相关学者使用了迁移学习的解决方法,如文献[12-13]采用迁移学习方法解决了小样本下图像识别准确率低的问题;文献[14]采用深度迁移学习对柑橘叶片钾含量进行了精准预测。
针对当前FDR传感器标定问题,本文以沈阳地区采集到的壤土为研究对象,考虑土壤性质、温度等因素对FDR传感器测量结果的影响,利用其他地区已获取的数据,采用机器学习方法训练模型,实现不同目标域之间的样本迁移和融合,建立基于迁移学习的FDR传感器自动标定模型。
1 数据来源
1.1 研究区概况
研究区位于辽宁省沈阳市(123.4°E,41.78°N,海拔5~441 m),该地区为温带半湿润大陆性气候,年平均气温6.2~9.7℃。
沈阳巍图农业科技有限公司对FDR传感器有长期的研究基础,在全国范围建有测试站点。为本文的研究提供了沈阳地区6个测试站点的数据,分别为站点11~16,其他地区10个站点数据分别为站点1~10(分别为北京、天津、西安、武汉、广州、重庆、大连、哈尔滨、银川、长春)。
本文将沈阳地区各站点作为FDR传感器目标使用地点,其他地区数据作为参考。沈阳地区供试土壤类型为壤土,土粒密度为2.70 g/cm3,容重为1.2 g/cm3,孔隙度55%,颗粒组成见表1。

表1 实验土壤颗粒组成
1.2 干燥法土壤水分测量原理
干燥法也叫称量法。利用恒温箱,在温度为105℃的条件下将土壤干燥至恒定质量,干燥前后土壤质量做差,再与干燥达恒定质量时的干土质量做比值,结果与土壤容重相乘即得到土壤体积含水率θ,采用百分数的形式表示。
1.3 FDR土壤水分测量原理

图1 传感器等效电路图
FDR型土壤水分测定传感器是一种利用LC电路的电磁振荡,根据电磁波在不同介质中振荡频率的变化来测定介质的介电常数ε,通过一定的对应关系反演出真实土壤体积含水率θv的仪器。传感器采用串联LC谐振电路,其等效电路如图1所示[7]。
根据电路原理,当谐振发生的条件成立时,谐振频率
(1)
式中L——电感,HC——电容,F
采用新型水盐一体传感器,传感器标定过程中,首先在室内通过专用设备测试各层传感器在空气和纯水中的频率,以确定传感器的基点和极大值,用于对传感器测试结果归一化,归一化频率定义为[8]
(2)
式中Fn——归一化频率
Fa——空气中传感器输出频率,Hz
Fw——纯水中传感器输出频率,Hz
Fs——土壤中传感器输出频率,Hz
研究发现,土壤介电常数与温度有关,使得FDR测得频率存在误差。针对该问题,文献[15-18]建立了温度对土壤体积含水率的补偿模型,减小了温度对传感器测量精度的影响;文献[19]通过实验的方式选择了75 MHz为最佳频率,消除温度对频率的影响。本文考虑在传感器设计时已加入了温度补偿模型,对此不做深入探究。
传统人工标定方法的FDR传感器标定经验公式为
(3)
式中a、b——标定参数
使用多组真实体积含水率θv与归一化频率Fn即可拟合曲线得到参数a、b,从而得到FDR测量的频率与土壤体积含水率的函数关系式。
1.4 数据采集
采用沈阳巍图农业科技有限公司研制的新型水盐一体传感器对全国16个站点进行长时间数据采集,涵盖了土壤水分稳定期、缓慢消耗期、大量损耗期及恢复期的不同含水率的土样。在每个站点分多个土层(土层深度为测试点距地表距离分别为10、20、40、60、80、100 cm)进行测试,测试记录数据包括站点、土层深度、传感器输出频率(包括Fa、Fw、Fs)以及与输出频率对应的真实体积含水率(干燥法测得),测试土壤体积含水率为5%~50%,其中站点1数据如表2所示。
2 研究方法
新型FDR土壤水盐一体传感器输出的原始信号是频率,传感器的标定即是在频率信号、土层深度和土壤含水率之间建立函数联系。同时考虑到各个测量值与土壤体积含水率之间的相关性,计算其相关性矩阵如表3所示,矩阵中数据表示两参数间相关性,相关系数取值范围为[0,1],0表示无相关,1表示强相关。

表2 站点1不同土层数据
由表3可知,体积含水率与其他参数均存在一定相关性,因此在建立模型时采用Fa、Fs、Fw、FDR归一化频率Fn、土层深度作为输入,土壤体积含水率θv作为输出。
FDR土壤水分传感器标定时需使用干燥法测体积含水率,代价很高,所以可用于传感器标定的有效数据较少。因此,本文考虑结合其他地区测量的大量相关数据,使用机器学习方法建模分析。传统的机器学习方法训练和测试数据同分布,通过数据分析知,不同地区的数据分布不完全相同,故不能直接使用其他地区数据用于当前地区的传感器标定模型训练。为此,本文引入迁移学习的方法,采用TrAdaBoost算法在当前地区少量有效标定数据的情况下结合其他地区数据作为辅助进行模型建立。

表3 输入输出之间的相关系数
2.1 数据预处理与分析
2.1.1数据预处理
在数据建模前首先需进行数据清洗,去除异常数据。箱型图不受异常值的影响,能够准确稳定地描绘出数据的离散分布情况,利于数据的清洗。本文采用箱型图的方法,处理结果如图2、表4所示。针对异常值识别结果,剔除不符合框图要求的数据,剔除输入数据Fa在85.07~88.64 Hz外、Fw在58.55~64.85 Hz外、Fs在63.73~76.58 Hz外的数据。

图2 输入输出数据的箱形图

表4 输入输出数据排序
2.1.2数据分布分析
为验证训练数据和测试数据是否满足同分布,以站点1~10数据为训练数据,站点11~16数据作为测试数据进行分析,结果如图3、4所示。由图3、4可知,训练数据和测试数据不满足数据同分布,不能使用传统机器学习方法直接训练,故采用迁移学习方法。

图3 站点1~10训练数据概率密度分布
2.2 基于迁移学习的自动标定模型

图4 沈阳地区站点11~16源域概率密度分布
采用集成学习算法——基于实例的TrAdaBoost迁移学习算法。TrAdaBoost[20-21]是戴文渊提出的一种基于实例的迁移学习算法,是一种从历史数据中提取实例的方法,即将一部分能用的带标签历史数据,结合带标签新数据(可能是少量),构建出比单独使用带标签新数据训练更精确的模型,适用于分类领域。本文模型的输出为体积含水率,是连续型变量,应采用回归模型,为此对TrAdaBoost算法进行改进,将该算法原为面向分类问题的基学习器AdaBoost,改为面向回归问题的XGBoost。该算法所涉及的数据集包括辅助训练数据、源域数据、目标域数据,其中辅助训练数据是指大量相关数据;源域数据是指少量与测试数据同分布的数据;目标域数据是指测试数据,即实际应用时的无标签数据。
基于其他地区10个站点数据(站点1~10),沈阳地区6个站点数据(站点11~16)为依据进行数据分析,将站点1~10的数据作为辅助训练数据(Xb,共589条数据,其中站点1为棕壤土、站点2为潮土、站点3为红粘土、站点4为黄棕壤土、站点5为红壤土、站点6为黄壤土、站点7为潮土、站点8为黑土、站点9为灰钙土、站点10为黑钙土),站点11~16分别作为FDR传感器目标使用地点,取其80%数据为源域数据(Xa)进行迁移学习训练得到标定模型,剩余20%数据作为目标域数据验证集测试模型误差。在实际应用时,源域数据的采集要求在不破坏土质的情况下涉及10、20、40、60、80、100 cm土层,体积含水率在0%~20%、20%~30%、30%~50%均有数据,样本量最多为辅助训练数据样本的10%,样本量最少为20个,否则迁移学习算法将退化为基学习器效果。
2.2.1基学习器算法——XGBoost模型
将辅助训练数据进行数据处理后,以Fn、土层深度作为输入,体积含水率作为输出,利用XGBoost作为基学习器对其进行训练。
XGBoost[22]是一种基于集成学习的用于处理稀疏数据的树学习算法。它的优点在于使用最少的集群资源扩展到更大的数据的端到端系统。
该算法的伪代码为:

Fork=1 tom:
GL← 0,HL← 0
Forjin sort (I, byxjk) do
GL←GL+gj,HL←HL+hj
GR←G-Gj,HR←H-HL
end
end
输出:分裂后的得分score
2.2.2目标域——面向回归的TrAdaBoost算法
TrAdaBoost算法是采用AdaBoost作为基学习器的分类算法,为适应本文的回归模型,将基学习器改为XGBoost。在TrAdaBoost算法中对权重进行迭代更新时采用误分类样本误差率
(4)

对于回归模型,修改误差率计算式为
(5)
式中ht(xi)——回归器的预测值
c(xi)——真实值
max|ht(xi)-c(xi)|——训练集上样本的最大误差
改进后的TrAdaBoost算法既保留了XGBoost可降低过拟合、自动学习缺失样本的分裂方向等优点,又弥补了XGBoost不能进行知识迁移的缺陷。改进后的算法伪代码如下:
输入:源域数据Xa,辅助训练数据Xb,合并的训练数据集T={Xa∪Xb},基学习器(Learner)XGBoost,迭代次数N。
(1)初始化
①初始化权重向量
其中

(2)权重迭代更新
对于t=1,2,…,N:
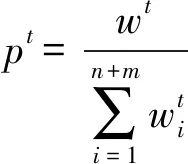
②调用Learner,根据合并后的训练数据T以及T上的权重分布pt,得到一个回归器ht
③根据式(5)计算ht在Xb上的误差率

⑤重新调整权重
⑥得到最终的回归器
(3)输出最终的回归器
对于辅助训练样本来讲,预测值和标签越接近,权重越大;而对于源域数据则相反,预测值和标签差异越大,权重越大。需要找到辅助样本中和源域数据分布最接近的样本,同时放大源域样本loss影响(增加源训练数据中错误率大的样本的权重,同时减小辅助训练数据中错误的权重),那么源域样本预测值与标签尽量匹配,辅助样本在前面处理的基础上筛选出最匹配(权重大的)的部分。
3 实验结果与分析
将站点1~10数据作为辅助训练数据,站点11~16分别作为源域数据,进行传感器标定模型训练与测试。对每个站点进行标定时,取该站点80%数据作为源域数据,共60条数据;剩余20%数据作为测试集,共15条数据。
根据传感器标定结果,由传感器输出频率计算得土壤体积含水率为测试值,认为干燥法得到的土壤体积含水率为真实值,使用平均百分比误差(MAPE)评估模型输出结果的准确率。
为防止过拟合,在计算测试值时,在源域数据和测试集上采用k折交叉验证。不重复地随机将源域数据划分为k个部分,k-1个部分用于训练,剩余部分用于测试,重复该过程k次,得到k个模型对模型性能的评价,基于评价结果可以计算平均性能,此方法对数据划分方法敏感度相对较低,每次迭代过程中每个样本点只有一次被划入训练集或测试集的机会。本文使用k=5,即每个部分为站点数据的20%。
为验证使用迁移学习进行初步模型校准的必要性,在站点11~16分别使用基学习器训练得到初步标定模型,并用迁移学习得到最终的标定模型,对比初步标定模型与最终的标定测试准确率,结果如表5所示,基学习器模型列为初步标定模型的准确率,自动标定模型列为使用迁移学习对初步标定模型校准后的准确率。表5结果显示,仅使用基学习器模型,准确率仅为65%左右,不能满足传感器标定要求;而使用迁移学习算法对模型进行校准后的准确率提升到了99%左右,已可满足传感器标定要求。故使用迁移学习的自动标定模型是有效且必要的。

表5 标定测试准确率
针对每个站点每个土层80%数据使用人工标定方法计算FDR传感器标定参数,使用剩余20%数据计算人工标定传感器测量准确率,每个站点准确率为该站点测试准确率平均值,结果如表5所示。与本文方法进行对比发现人工标定方法准确率为90%左右,而本文方法平均准确率达到99.1%,充分说明本文算法的有效性。
4 结论
(1)针对FDR传感器有效标定数据量少的问题,提出了基于迁移学习的FDR土壤水分传感器自动标定模型,仅需少量数据对模型进行校准即可使得模型输出结果满足要求。该算法克服了传统人工标定数据采集费时、费力的问题,减少了对标定数据的需求。
(2)改进了TrAdaBoost算法,更新了训练模型回归误差率的计算方式,并采用k折交叉验证有效防止了过拟合问题。
(3)将本文方法与基学习器方法的实验效果进行对比,结果显示,在使用迁移学习进行模型校准后,大大提高了模型测试准确率,说明了基于迁移学习的自动标定模型的有效性。
(4)使用本文方法,传感器在土壤体积含水率测试时,得到平均绝对误差均小于2%,符合农业测量土壤含水率小于±5%的规范要求。
