基于改进ACF算法的道路行人检测算法研究
2020-03-05王衍陈镜任冯宇庆
王衍,陈镜任,冯宇庆
(1.重庆珞璜港务有限公司,重庆402260;2.武汉理工大学计算机科学与技术学院,武汉430063;3.武汉民政职业学院,武汉430070)
0 引言
港口行人、车辆众多,对港口行人的运动轨迹进行跟踪对于港口作业安全具有很大意义。
行人检测是行人运动轨迹预测的基础,要想对行人运动进行分析,并预测其接下来的运动趋势,首先就必须要检测出初始帧中行人存在的具体位置。行人检测技术发展至今已经取得了一定的效果,但依然存在误检漏检的情况,给行人检测带来不小挑战[1-2]。
行人检测的目的是判断图像中是否存在行人,并找到其具体位置。行人检测算法主要有基于背景建模、基于深度学习、基于机器学习这三类。
基于背景建模的方法要求摄像头须是固定不动的,同时,算法只能将运动的目标与背景进行分离,而不能判断出运动中的前景目标的类别,其适用的场景受到限制。基于深度学习的方法运算复杂度较大,对硬件要求较高,应用落地性有待提升。基于机器学习的方法可以应对静态和运动的摄像头所拍摄到的视频图像,且对硬件要求不高,因此本文选用基于机器学习的行人检测方法进行研究。该方法的基本框架如图1所示。
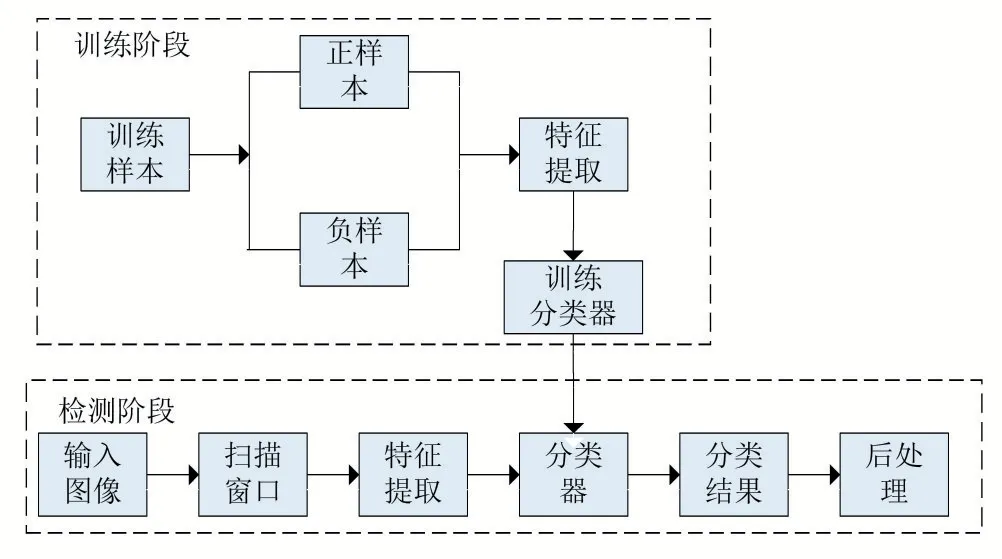
图1行人检测算法框架
1 基于改进ACF的行人检测算法
ACF[1]是一种基于机器学习的、性能较为不错的行人检测算法。ACF采用聚合通道特征作为行人特征,采用AdaBoost算法作为分类器,经过训练得到了检测性能较好的行人检测器。图2为ACF行人检测算法流程。
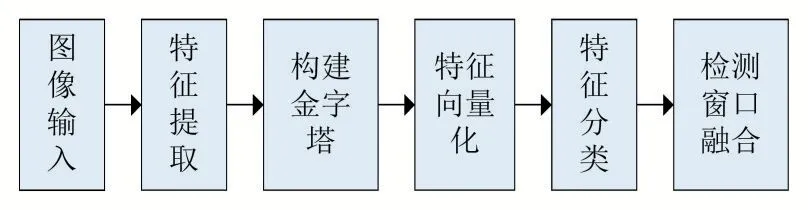
图2 ACF行人检测算法流程
1.1 聚合通道特征
聚合通道特征中包含了三种特征通道,其中,颜色通道有三个,梯度幅值通道有一个,梯度方向通道有六个[3-4]。
(1)颜色特征:行人的颜色特征主要表现在行人的衣着上,根据颜色特征可以将穿不同颜色衣服的行人检测出来。用于行人检测的主要颜色特征有:LUV、RGB、HSV。
(2)HOG特征:HOG特征能够描述图像的局部梯度方向和梯度强度分布,能够在边缘位置未知时,利用边缘方向的分布来表示目标的外形轮廓。
1.2 构造特征金字塔
传统的构建特征金字塔的方法较为繁琐,它将待检测的图像进行多尺度缩放,之后在所有的尺度上都要 提 取 特 征,按 照Cs=Ω( R( I,s) )计 算,而 忽 略 掉C=Ω(I)中包含的信息。
本文构建特征金字塔的方法是:将待检测的图像缩小为原来的1倍、2倍、4倍,然后计算这三个尺度上的特征,用已经计算出的三个尺度上的特征去估计其他尺度上的特征。具体思路为:令Is表示在尺度s上捕捉到的图像I,R( )I,s表示用s重采样得到的图像I。在已经计算出C=Ω()I的情况下,用C在新尺度s上预测通道图像Cs=Ω(Is)。采用如(1)式所示的特征近似的思路,这种近似处理简便、相对准确,提升了构建金字塔的速度:

图3为传统特征金字塔与快速特征金字塔比较图。
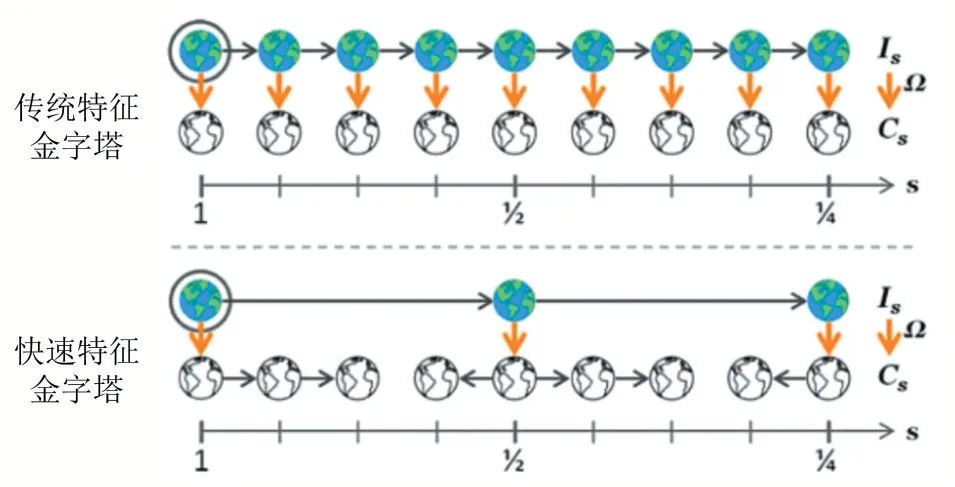
图3传统特征金字塔与快速特征金字塔比较
1.3 改进的AdaBoost
Kearns等人[5]于1988年在研究可能近似正确学习(Probably Approximately Correct Learning,PAC Learn⁃ing)时提出了Boosting问题,对于“能否将弱可学习视为强可学习”提出了疑问,而Schapire则在随后对该问题作出了肯定的回答,并设计出了第一个Boosting算法。但Boosting算法的前提是要能够预知弱分类器的错误率上限,这就使得其难以应用于实际问题中。后来,Freund等人发现在线分配问题与Boosting问题非常相似,于是他们在Boosting算法中引入了在线分配思想。即,将加权投票与在线分配问题相结合,得到了著名的AdaBoost算法。AdaBoost算法无需提前知道弱分类器的先验知识,这一点促使其成为主流的分类算法,并在解决实际问题中取得了极大成功[6]。
(1)原始的AdaBoost及分析
原始的AdaBoost算法给定训练样本及其分类( x1,y1),…,( xn,yn),其中xi∈X,yi∈Y={- 1,+1}。初始化样本的权重D1(i)=1 n,即初始时,各个样本权重相等。
分析经典的AdaBoost算法可知,对难度较大的样本进行分类时,会使困难样本的权重以非常快的速度增长,这样就产生了“退化问题”。此外,AdaBoost易受噪声干扰,执行效果依赖于弱分类器的选择,且弱分类器训练时间偏长。
(2)改进的AdaBoost
为了克服经典AdaBoost的上述缺点,可以修改弱分类器权重值αt的计算方法。新的计算方法为:
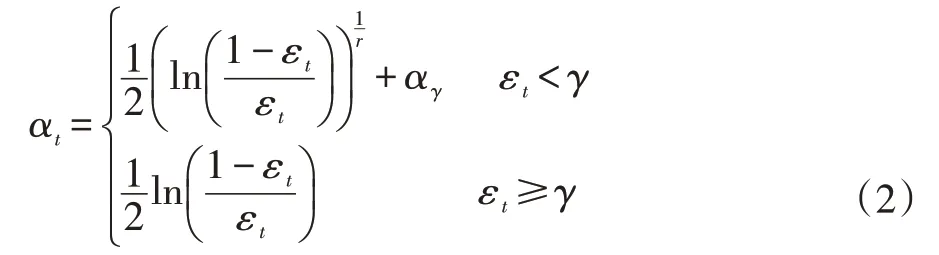
利用上式计算弱分类器权重值αt,防止任一样本的经验分布在某一阶段中显著增长。然而,在每一步更新经验分布,经过几次迭代之后,与其他样本相比,那些被重复错误分类的样本的概率权重的值会大大增加。因此,为每个样本i=1,2,...n引入反向变量β()i和年龄变量life(i)。反变量β(i)的初始值为1,此时算法就按照经典AdaBoost算法处理样本,即,当样本被错误分类时,就增加其经验分布,否则减小其经验分布。如果的值是-1,则算法就按照逆AdaBoost处理样本,即,当样本被错误分类时,减小其经验分布,否则增加其经验分布。变量life(i)计算样本i被按顺序错误分类的次数,如果该数量超过阈值τ,则将β(i)的值反转为-1。也就是说,被错误分类的样本的权重会持续增长,直到迭代次数达到极限τ,然后开始减小。如果β(i)在被反转为-1后,样本在接下来的步骤中被正确分类,那么就将β(i)的值又反转回1。
改进后的算法在经典AdaBoost和逆AdaBoost之间交替。通过将异常值的影响限制在经验分布中,检测并减少困难样本的经验概率,并在污染数据下执行更准确的分类,使得其性能更加稳定。
在第一阶段采用上述权值更新方法,经过多轮训练,获得一个较为可靠的样本分布wi(s)。接下来,在第二阶段采用并行方法,提高训练效率,在训练中不再对样本权值进行更新,而统一采用wi(s)。改进的Ada⁃Boost如下程序所示:
输入:给定训练集Z={( x1,y1),...,( xn,yn)},其中xi∈X,yi∈Y={- 1,1};
输出:强分类器HT(x)
1参数初始化:设置年龄变量的阈值τ,界限阈值λ,鲁棒参数r,令T=0;
2为每个样本( x1,y1),i=1..n.初始化经验分布D1(i)=1 n,反向变量β(i)=1,年龄变量life(i)=0;
3 repeat
4将T增加1;
5从训练集Z中获取带有分布DT的自举样本ZT;
6使用自举样本ZT作为训练集,训练弱分类器hT:X→{- 1,1};
7 按式(7)计算弱假设hT的加权错误率εt;
8按式(11)计算αT;
9按式(10)计算经验分布;
10按式(11)计算阶段T的强假设HT(x)
11 使用强假设HT(x)对训练数据集Z={( x1,y1),...,( xn,yn)}进行分类;
12 if HT(x)将样本( x1,y1)正确分类,即HT(xi) yi>0 then
13 令life(i)=0且β(i)=1;
14 else
15 使life(i)增加1;
16 if life(i)>τthen令β(i)=-1且life(i)=0;
17 end if;
18 until达到标准
1.4 改进的ACF算法框架
综上所述,得到改进的ACF算法框架如图4所示。
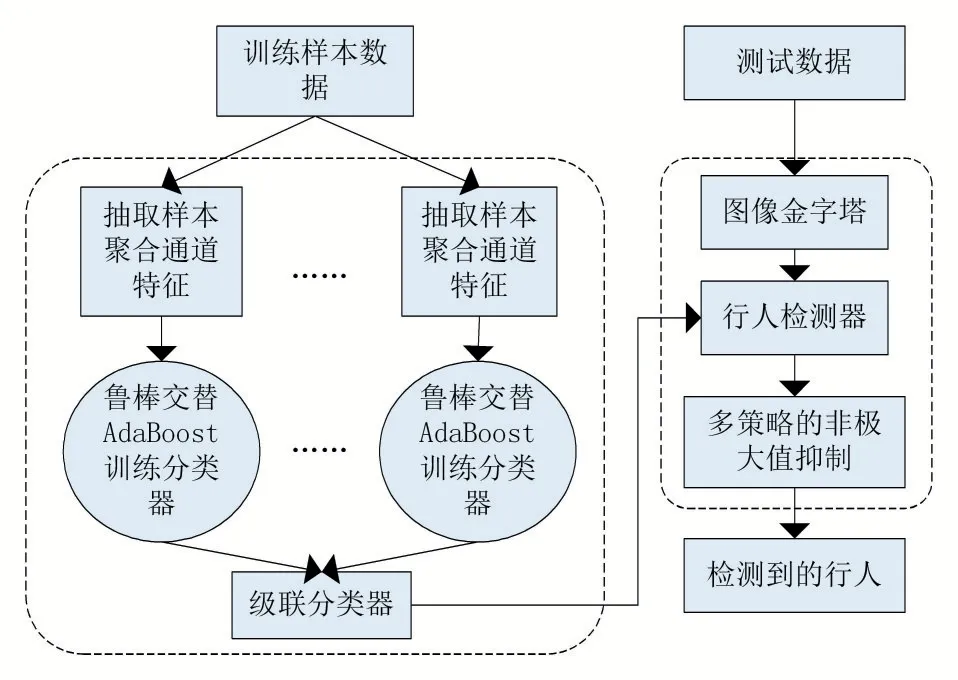
图4改进的ACF行人检测框架
2 实验设计及分析
2.1 数据集
本文的训练使用的数据来自INRIA数据集,训练集里原本有614张行人图片,一共1239个正样本,样本数偏少,只用这些数据进行训练难以得到分辨能力更强的分类器,因此将原本的1239个正样本经过镜像翻转,得到2478个正样本,负样本选自INRIA和Caltech。测试集选自INRIA测试集中的图像和在校园内自采集的行人图像,一共包含750张图像,共673个正样本,429个负样本。
2.2 评价指标
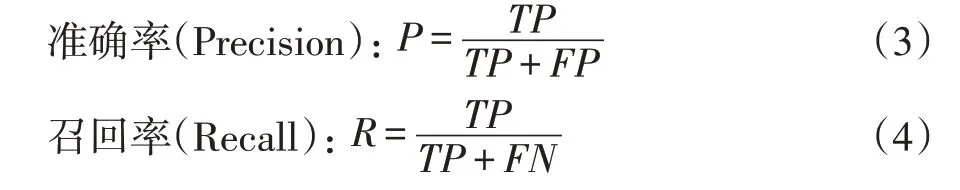
其中,真正例(True Positive,TP):实际上是行人,被检测成行人的图像数。假正例(False Positive,FP):实际上不是行人,被检测成行人的图像数。真反例(True Negative,TN):实际上不是行人,被检测成非行人的图像数。假反例(False Negative,FN):实际上是行人,被检测成非行人的图像数。
2.3 定量分析
通过在INRIA测试集中抽取的正样本行人图像和自采集的行人图像组合而成的测试集上进行实验,与同是基于机器学习的HOG+SVM算法、DPM算法、ACF算法进行比较,结果如表1所示。
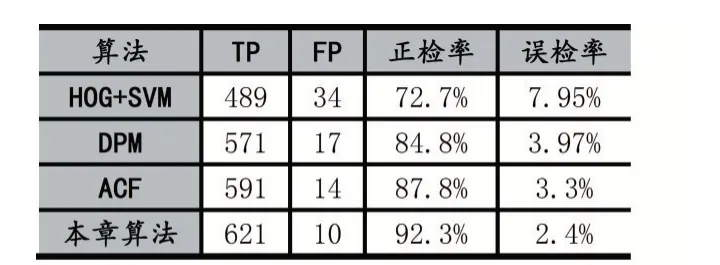
表2不同算法行人检测结果比较
如表2所示,本文提出算法的正确检出率为92.3%,相比于HOG+SVM、DPM、ACF有一定的升。
同时考虑准确率和召回率,以召回率(Recall)为横坐标,以准确率(Precision)为纵坐标,得到P-R图,P-R曲线围成的面积就是检测精度,即,P-R曲线围成的面积越大,检测的平均精度越高。如图5所示,HOG+SVM检测算法的P-R曲线在最下面,围成的面积最小;DPM的P-R曲线比HOG+SVM围成的面积要大;再上面是ACF;再上面是本文算法。本文算法的P-R曲线围成的面积最大,说明其检测的平均精度是最高的。
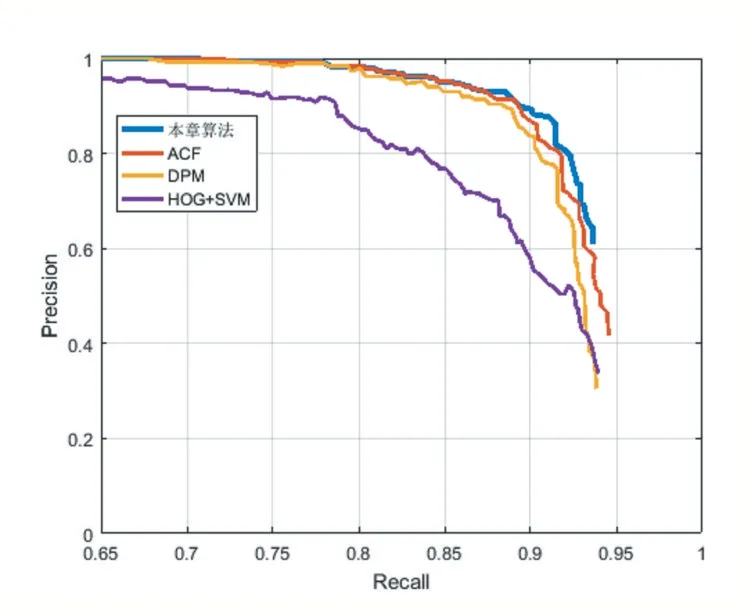
图5各算法的P-R图
3 结语
本文对ACF算法进行了改进。实验表明,算法降低了误检率和漏检率,检测效果有一定提升。在未来的研究中,将研究提升算法对大幅形变的行人的检测效果。
