基于E-LSTM循环神经网络的制冷设备状态预测
2020-01-08徐晨蕊贾克斌刘鹏宇
徐晨蕊,贾克斌,刘鹏宇
(1.北京工业大学 信息学部,北京 100124; 2.先进信息网络北京实验室,北京 100124;3.计算智能与智能系统北京市重点实验室,北京 100124)
数据中心[1]主要由IT设备、制冷设备系统和供配电系统三部分构成,随着数据中心的规模不断扩大,数据中心机房的安全作为网络正常运行的前提,已成为人们生活的一部分。随着智能楼宇[2]的发展,制冷设备的安装量和使用量不断增加,但是运维人员的数目有限,由于故障造成的能耗损失占总能耗损失相当大的一部分,据统计由于制冷设备故障导致的能耗损失占制冷设备总能耗的10%~40%,所以一旦发生故障,会造成不同程度的经济损失和严重后果。因此对制冷系统里的重要特征值进行预测,可以提高风险分析能力,防范于未然,加强制冷设备的稳定性。
随着计算机技术的进步和数据分析方法的发展,预测研究不断深入,相应的预测方法也是层出不穷。文明[3]等人提出用非线性自回归时间序列预测模型对隧道施工过程中的围岩水平收敛和地表变形进行预测,仅对趋势性较平稳的数据具有良好的预测效果,而对具有趋势性、季节周期性和随机性的非平稳序列,难以得到较高的预测精度;张洁[4]用回归预测模型对实际的电力预测问题进行深入研究与分析,但用的是人工提取的方法,其泛化性较差;为此,李彬楠[5]等人采用灰色-BP神经网络的组合预测模型对土壤的水分特征进行预测分析,通过关联度的计算,量化各影响因子对因变量的影响程度,进而合理确定BP神经网络的输入因子,最终达到优化模型微观结构。虽然该方法相比人工提取特征的方法有更好的性能,但是没考虑到数据间的时序性;钟楠祎[6]提出基于深度学习的数据特征的提取与预测,用RNN-RBM神经网络模型对医院的门诊量数据进行预测,虽然RNN能从时间序列中提取时间特征,但是很容易遗忘历史信息,从而降低了预测精度。
针对数据中心中的制冷设备采集的数据为时序序列的特点,应用一种深度学习的方法——LSTM神经网络去预测制冷设备的状态。研究发现制冷设备普遍存在工作原理复杂、数据类型繁多的问题,LSTM较难对制冷设备里的特征进行有效提取。鉴于此类问题,本文提出了一种E-LSTM循环神经网络的制冷设备状态预测方法。基于有限长度的时序数据,提出一种在原有的LSTM模型前加一层全连接神经网络,对制冷设备的特征进行预提取。旨在提高数据预测的正确率和加强预测模型的鲁棒性。
1 相关理论
本章简要介绍制冷系统工作原理、数据预处理、相关性分析的相关方法,以及LSTM神经网络的细胞结构。
1.1 制冷系统工作原理
机房里的制冷系统主要由冷却水循环系统、冷水机组和冷冻水循环系统组成,其工作原理极其复杂。制冷系统的工作原理图如图1所示。
冷水机组[7]是由压缩机、冷凝器、膨胀阀(又称节流阀)和蒸发器四大件组成。冷水机组通过压缩机将低温低压制冷剂气体压缩成高温高压气体,冷凝器通过将高温高压气体转化为低温低压液体与冷却水进行
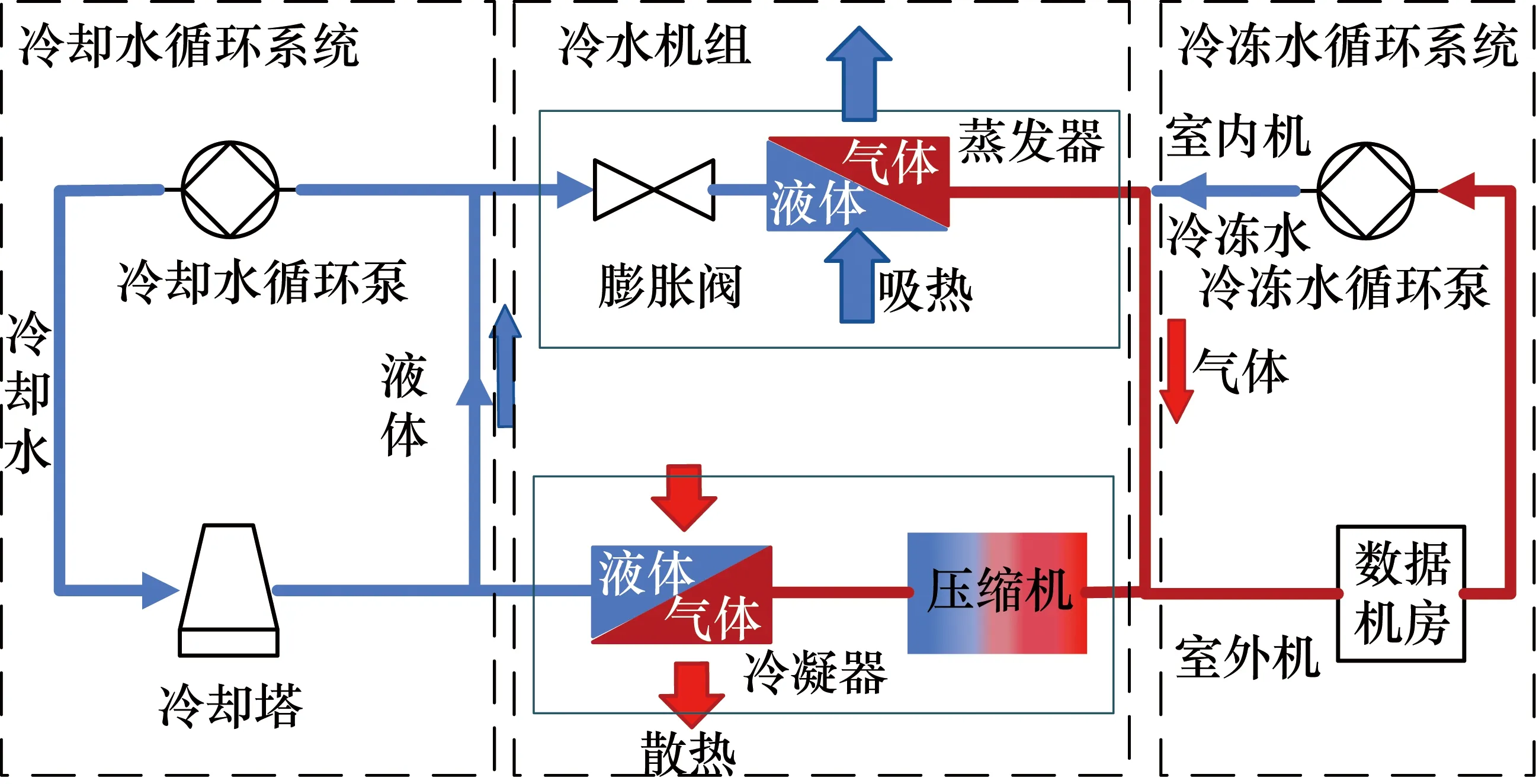
图1 制冷系统工作原理图
热交换,使冷却水温度升高,由冷却泵将升了温的冷却水压入冷却塔,使之在冷却塔中与大气进行热交换,然后再将降温了的冷却水,送回到冷水机组进行热交换;低温低压冷凝剂液体经过节流装置膨胀阀,蒸发器通过将低温低压液体变成气体与冷冻水进行交换,使冷冻水温度降低,冷冻水泵将冷冻水送到各数据机房的空调末端,由风机吹送冷风达到机房内降温的目的。
1.2 数据预处理
分析的数据来源于某个数据中心实际采集得到的制冷设备的数据,选取2018年7月1日0时0分至2018年9月28日23时19分范围内平均每35 s采集一次的数据,输入的特征值有:室外温度、湿球温度、室外焓值、回路压差、数据中心总功率、IT负载;输出特征有:冷源功率、PUE和冷冻二次泵,其中,输出特征里的过去信息同样也作为输入。一共有36080条数据。先对数据进行初步分析,其中PUE的曲线图的波动较大,如图2所示。
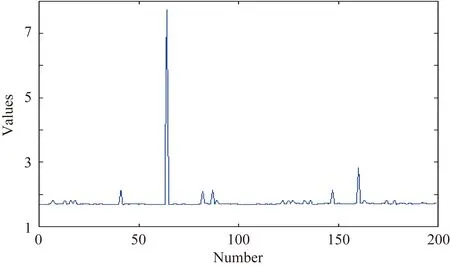
图2 PUE数据分布图
PUE值越接近于1,表示一个数据中心的绿色化程度越高。我国的大多数数据中心的PUE值在2~3之间。对于图中PUE出现的异常值,通过调研发现,是因为机房有的时候,会出现大批裁撤和下架,所以值会有所波动,出现异常。
那么对于原始数据中包含有异常值或空值的情况,无法直接进行数据分析预测,或者预测结果差强人意。为了提高数据分析预测的质量,需要用到数据预处理技术。在本文中,采用的是均值滤波[8]的方法对PUE等特征值里的异常数据进行删除和填补,具体是利用python中的pandas库对数据进行清洗,删掉空行,过滤异常值,填补空缺值。使用scikit-Learn[9]中的MinMaxScaler中的预处理类对数据进行归一化处理,将数据缩放到0~1,这样做的目的是提高预测精度。均值滤波流程图如图3所示。
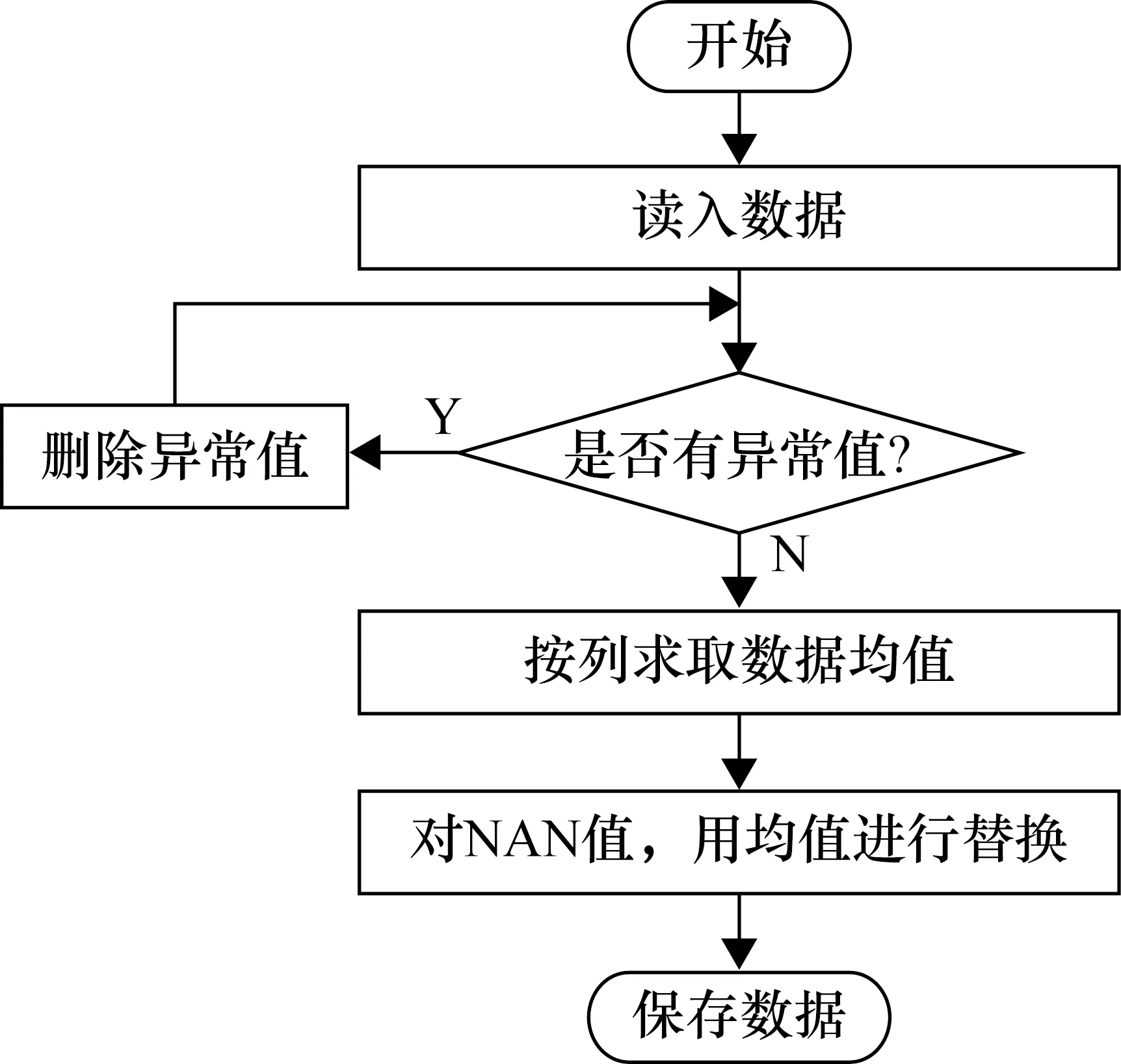
图3 均值滤波流程图
1.3 相关性分析
相关分析是研究两个或两个以上处于同等地位的随机变量间的相关关系的统计分析方法。对制冷设备的特征值进行相关性的分析,可以得到特征值之间的相关性系数,对后续选取相关性大的特征值具有重要意义。相关性可以通过热力图[10]展示出来,这样可以对数据间线性关系有更直观的了解。用R语言内置函数 cor()计算特征值之间的相关系数,使用Python的pandas库中corrmat函数和sns.heatmap函数画热力图,使之前的相关性系数矩阵直观展现出来,便于后续进行数据分析。热力图如图4所示。
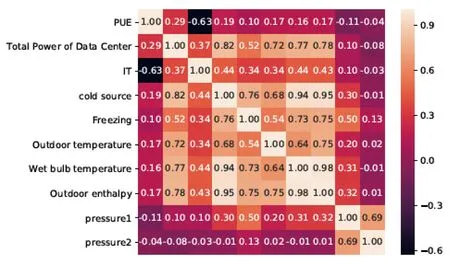
图4 特征之间关联性分析热力图
由图4可以得出各个特征之间的相关性系数。图4中,颜色越浅,代表相关性越大,颜色越深,代表相关性越小。由热力图,可以发现冷源功率和数据中心总功率(0.82)、湿球温度(0.94)、室外焓值(0.95)的相关性较大; PUE 和 IT 负载(-0.63)成负相关,负相关一般看绝对值,绝对值越大,相关性越高。由此能发现制冷设备中各个特征之间都有关联性。
1.4 LSTM关键技术介绍
LSTM神经网络[11]是一种改进的时间序列循环神经网络(Recurrent Neural Network,RNN),缓解了传统RNN在训练过程中容易出现的梯度消失、爆炸等现象。LSTM通过在RNN的重复模块中加入输入门、遗忘门和输出门来解决普通循环神经网络具有的长期依赖问题,通过其独特的记忆模式和遗忘模式,使网络充分挖掘数据的时序特征,学习信号中的时间依赖关系,对长期信息的记忆使得长短期记忆神经网络具有更好的预测准确率,标准LSTM 框架图如图5所示。
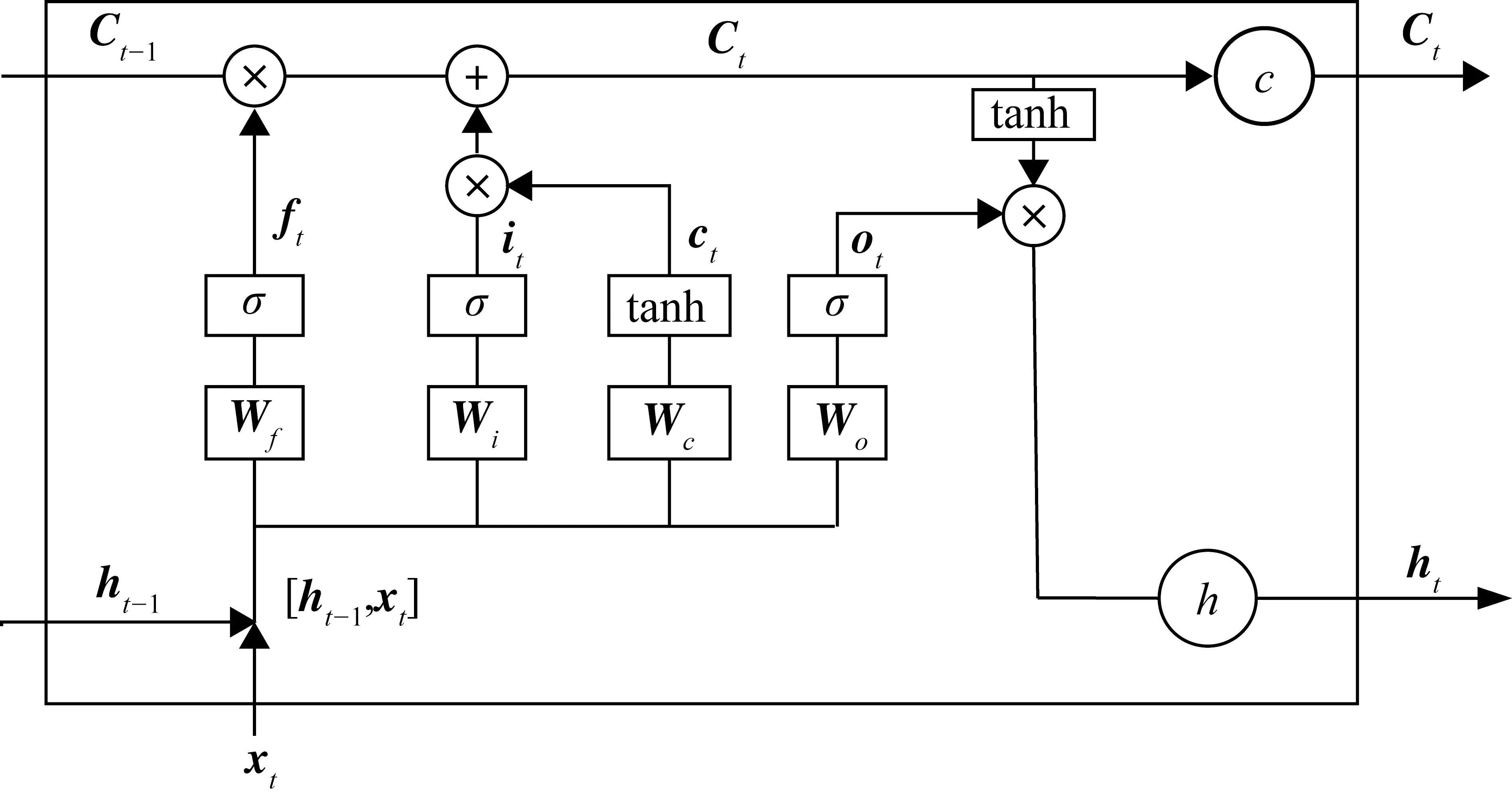
图5 标准LSTM 框架图
在每个时间步t中,xt为输入向量,ct为细胞状态向量,ht是根据ct输出的隐藏状态向量,公式如下:
it=sigmoid(Wixt+Uiht-1+bi)
(1)
ft=sigmoid(Wfxt+Ufht-1+bf)
(2)
ot=sigmoid(Woxt+Uoht-1+bo)
(3)
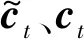
(4)
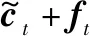
(5)
ht=ot○ tanh(ct)
(6)
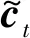
2 LSTM模型的改进
2.1 E-LSTM模型的介绍
为解决LSTM记忆模块的选择有限、输入的序列长度不宜过大的问题,本文提出一种改进型LSTM网络(Enhanced-LSTM)模型去提高预测制冷设备的精度。具体结构如图6所示。
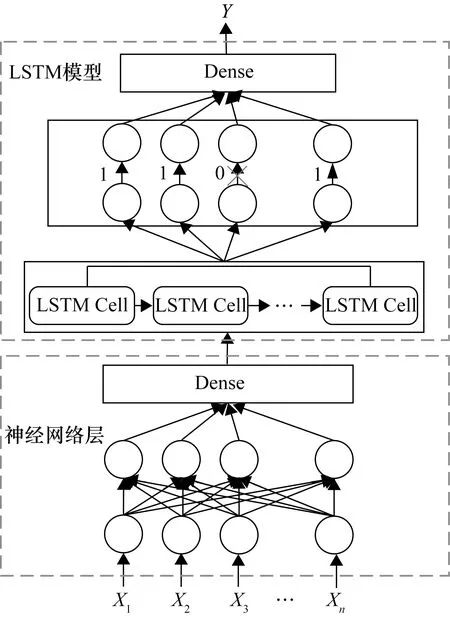
图6 E-LSTM模型架构
在原始的LSTM模型前加入了全连接网络Dense层,相当于利用神经网络进行特征的预提取和降维。将预提取后的特征输入到LSTM网络,为了防止网络层数过深或数据维度太少导致的过拟合问题,在LSTM网络层嵌入了一层Dropout层,随机抽取模型中一定概率的神经元权重不参与训练,最后整个改进模型的输出层也选用Dense层。
改进的E-LSTM模型有效解决了制冷设备中数据复杂度高的问题,不仅能够对输入的长序列信息进行特征预提取,还增加了整个模型的深度,有效防止了由于网络层数的过深导致的过拟合问题,提高了整个网络模型的预测精度。
2.2 E-LSTM模型的训练和预测
E-LSTM的网络训练主要是在Tensorflow[12]平台实现的。训练过程主要分为7个步骤:
① 在输入数据到E-LSTM模型之前,设定每个时间步长输入8个变量,序列长度设置为5(在3.1.2节会具体阐述设置为5的原因),以2:1的比例划分数据集(即前2500个数据为训练集,其余为测试集)。
② 训练集数据归一化。用sklearn.preprocessing模块对数据进行归一化处理,使得数据范围在[0,1]之间。把归一化后的数据放到神经网络里,可以使得模型的收敛速度加快。
③ 将归一化后的输入序列在LSTM网络的前置神经网络中处理后由全连接层输出,将一个5×8(40)维的输入序列经过全连接层输出后降维到5维。
④ 设定LSTM网络的隐藏层有128个神经元,epoch为100,每个batch的大小为200。由式(1)~式(6)计算LSTM细胞的输出值。
⑤ 计算每个细胞的误差。本文用均方误差(MSE)来计算误差,误差函数计算公式如下:
(7)
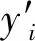
⑥ 根据误差计算每个权重的梯度。
⑦ 应用基于梯度的优化算法更新权重。本文采用Adadelta[13]梯度下降算法来最小化地降低误差。损失函数选用mean_squared_error。
应用训练好的E-LSTM模型进行预测,将测试集test_x输入到模型,利用test_y作为理论输出和模型的实际输出来计算模型的预测精度。本文选用MAE和RMSE作为模型预测精度的评估标准,公式如下:
(8)
(9)
式中,T为整个时间步长的个数;yt、ft分别为模型输出的实际值和预测值。MAE、RMSE的数值越小,说明模型的预测精度越高。
3 实验验证
本章使用某数据中心的制冷设备中的数据作为实验数据集,应用第2章的相关理论和第3章的模型构建方法展开实验验证,具体包括实验结果、案列分析两部分。
3.1 实验结果
3.1.1 对比实验
为了验证E-LSTM模型性能的优越性,本文选用6种机器学习的方法与之做对比。实验选用相同的超参数去训练所有的循环神经网络。PUE、冷源功率和冷冻二次泵的对比实验如表1所示。
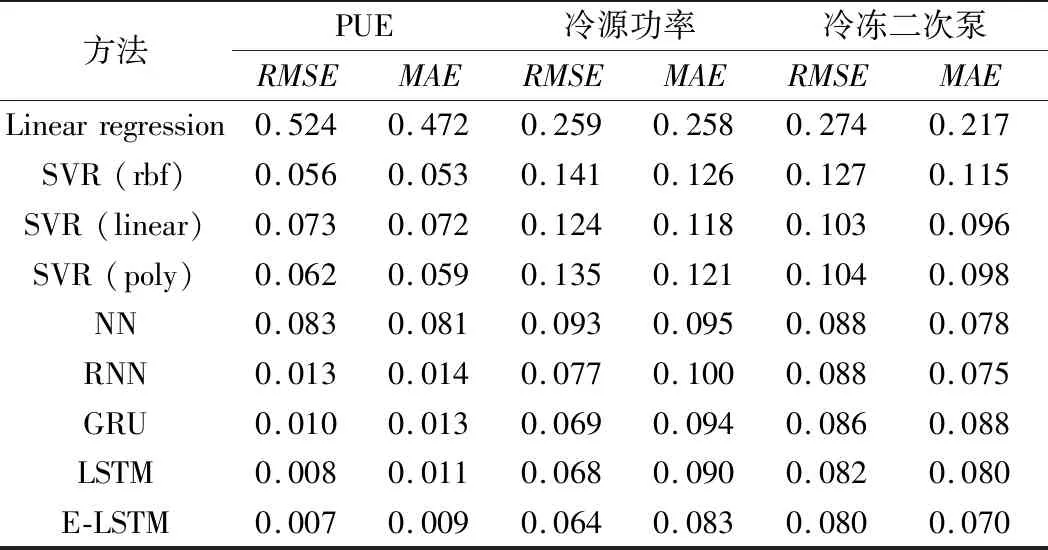
表1 三种预测的对比结果
从表中可以看出,E-LSTM模型的RMSE和MAE均低于原始的LSTM模型、RNN模型和GRU模型。与其他机器学习的算法相比,改进的模型的RMSE和MAE明显低于NN、支持向量机和线性回归3种方法,证明了该方法在制冷设备状态预测任务中的有效性。
3.1.2 获取精度较高的模型参数
为了进一步评估模型的性能,本文对不同的序列长度的PUE、冷源功率、冷冻二次泵做实验。分别选取序列长度为1、3、5、10、30、50、100和150作为时间步长,训练E-LSTM模型。PUE、冷源功率和冷冻二次泵的预测结果如图7所示。
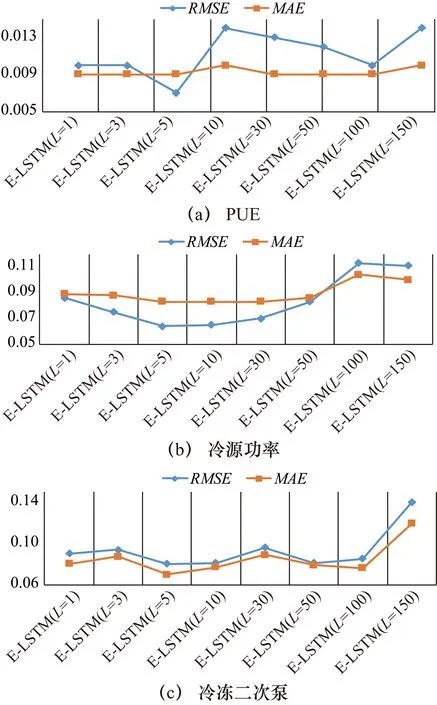
图7 不同序列长度下3种E-LSTM模型的RMSE和MAE变化
从图7可以看出,E-LSTM模型的RMSE和MAE在不同的PUE、冷源功率和冷冻二次泵序列下呈波浪式上升。RMSE和MAE的值都是在PUE、冷源功率、冷冻二次泵时间序列长度为5时最小。从而得出结论:本文选用时间序列长度为5,去预测未来3 h的制冷设备状态下的数值,预测效果最好。
3.2 案列分析
为了证明对制冷设备状态进行多变量输入预测的必要性,本部分将多输入制冷设备状态预测与单输入制冷设备状态预测的效果进行了比较。保持其他参数设置不变,只更改输入。图8展示了多输入预测和单输入预测之间的PUE、冷源功率和冷冻二次泵的性能。其中蓝线代表实际曲线,红线代表预测趋势。
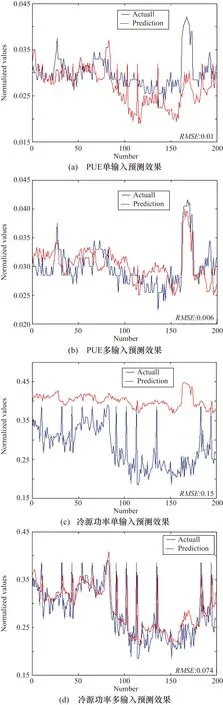

图8 单输入和多输入预测的对比实验
从图8可以看出,单输入预测的性能比多输入预测差得多。在RMSE方面,单输入预测的误差明显大于多输入预测的误差。该对比实验证明了E-LSTM模型能够较好地预测多输入制冷设备的状态。
4 结束语
本文基于机房的制冷设备中的数据,选取PUE、冷源功率、冷冻二次泵、室外温度、湿球温度、室外焓值、回路压差、数据中心总功率、IT负载这10个特征为主要研究对象,应用改进型LSTM(E-LSTM)对PUE、冷源功率、冷冻二次泵做预测,得出以下几点结论:
① 改进的LSTM(E-LSTM)神经网络有效地改善了LSTM 在有限长度的数据预测中存在的问题,比LSTM更高效地提取时序数据之间特征,使得改进的LSTM 预测能力更强。
② E-LSTM循环神经网络模型的RMSE和MAE都远远低于RNN、GRU、NN、SVR、Linear regression这5种模型,说明E-LSTM模型更适用于制冷设备的状态的预测。
③ E-LSTM神经网络适用于多输入单输出预测。进行单输入单输出和多输入单输出预测对比实验发现,在针对制冷设备中各个特征之间有相关性这个特点,对改进型神经网络进行多输入单输出预测,预测精度会更高。
