基于多目标最优化的最小代价决策树构建与实现∗
2019-12-27曹礼园李深洛
曹礼园 李深洛
(1.广东科技学院 东莞 523083)(2.广西师范大学计算机科学与信息工程学院 桂林 541004)
1 引言
确定挖掘方法、选择挖掘对象及合理定义挖掘约束是数据挖掘要面对三大难题,其中,挖掘方法的确定至关重要,而事选将问题进行分类无疑大大简化确定挖掘方法程序。分类器的构建是分类的主要程序,分类器,通常是一个分类函数或分类模型,分类器能把数据库中的数据项映射到大数据库里给定类别中的某个最佳类别。
决策树(Decision Tree)应用非常广泛。本研究在构建决策树的过程中把误分类代价、测试代价、等待时间代价和信息增益率构建最优化问题,作为属性选择的准则,从而构建最小代价决策树。然后,对于有缺失值的数据,提出了具体的构树策略和测试策略。
2 构建决策树
相对传统决策树通常构准确率最高的决策树,代价敏感决策树构造代价最小的决策树。假设训练数据和测试数据都含有缺失值,我们的构建决策树包括以下三个步骤:1)选择分列属性;2)建立代价敏感决策树;3)测试决策树。
2.1 代价的定义
文献[1]总结出9种主要的代价,它们是Cost of Misclassification Errors、Cost of Tests、Cost of Teacher、Cost of Intervention、Cost of Unwanted Achievements、Cost of Computation、Cost of Cases、Human-Computer Interaction Cost和 Cost of Instabili⁃ty。本文主要考虑测试代价、等待时间代价及误分类代价这三种代价。
1)误分类代价(MC)
误分类代价:由错误的分类而引发的惩罚代价。对于类别标签为i的某一类,其预测类别为j,则误分类代价为 MCi,j,其中 MCi,j∈[0 ,+∞ ) 。在构树过程中,选择属性A作为分裂属性,则其所引起的误分类代价为MC(A ),其中MC∈[0 ,+∞ )。
2)测试代价(TC)
测试代价:是获取属性值测试所需要的花费,由所处理数据的领域提供。实际应用中,测试代价要复杂得多,获取属性A的值,其测试代价为TC(A),实际的值由领域专家给出。
3)等待时间代价(WC)
等待时间代价:获取属性值等待测试结果所引发的代价。如果某属性A的测试一定要等待另一个属性B的结果出来才可以进行,则属性A等待时间代价与属性B的等待时间代价相关,我们称属性B为属性A的先验属性。
等待代价并非一成不变,不同情境,不同的人群,即使是同一个测试,等待代价也可能是不一样的。
因此,对于测试属性A,其等待时间代价可以定义为WC(A)=WCT(A)⊕WCT(B)⊕WCS(A),其中,WCT(A)表示测试属性 A的实际的等待时间,WCT(B)表示属性A的先验属性B的实际等待时间,WCS(A)表示由于测试对象、资源等因素差异而引起的等待时间代价,WCS(A)由领域专家确定。因为WCT(A)、WCT(B)和WCS(A)的度量标准不一样,所以不能简单地相加,必须统一度量标准。在我们的定义中,用⊕连接WCT(A)、WCT(B)和WCS(A),表示WC(A)是由这三者决定的。
2.2 分裂属性的选择
给定一个训练集 S={xn,yn},n=1,…,N ;其中 N为样本数,输入向量 xn属于某一值域X⊆ℝD,yn属于分类标签集Υ={1,2,…,K};每一实例{xn,yn}都是在某一未知分布分布D:Χ×Υ上相互独立的[11]。相应地,给定属性测试代价集TC={TC(A)|A∈T},属性的等待时间代价集WC={WC(A)|A∈T},T为所有属性的集合。
代价敏感决策树分裂属性选择的任务是利用训练集、测试代价集和等待时间代价集找出一个分裂属性A,使得对于任意的A*∈T′,T′为所有待分裂属性的集合,有

其中,GainRatio(A,S)表示属性A的信息增益率。
如此,代价敏感决策树分裂属性的选择就构成了一个多目标最优化问题。标准化各种代价和信息增益率后,用线性加权和法把多目标最优化问题转化为单目标最优化问题,得

2.3 建立代价敏感决策树
我们的算法根据式(2)选择使得F最小的属性作为当前分裂属性,生成一个节点。类似C4.5,我们的算法是根据局部最优选择的属性,且是不能回溯的,所以最后有可能得不到全局最优的决策树。但是,采取局部最优法能大大提高算法建树的效率。
特别地,建树的过程中要注意到以下三点。
第一,根据式(2),我们选择使得F取到最小的属性作为当前节点,如果存在两个或两个以上的属性同时使得F取到最小,那么我们再进一步根据以下的策略选择属性:
1)没有标准化前具有更小误分率代价MC的那个属性;
2)没有标准化前具有更小测试代价TC的那个属性;
3)没有标准化前具有更小等待时间代价WC的那个属性。
根据实际应用需求,优先级策略2)和3)可以调换。因为代价敏感决策树最终的目标最主要是为了减小误分类代价(特别是在医疗诊断领域),所以把具有更小误分类代价的那个属性优先考虑。
第二,当训练数据有缺失值时。文献[14]实验验证了多种处理缺失值的方法来构造代价敏感决策树,得到结论:最好的方法是文献[5]提出的内部节点策略,即缺失的值不作为普通的输入,而是根据误分类代价由内部节点处理。因此,在训练数据时,我们将采用内部节点的方法来处理缺失值来构造我们的代价敏感决策树。
第三,在怎样的条件下停止建树。类似于C4.5,我们当满足以下两个条件中的一个时,我们停止建树。
1)在某一个节点处的所有的实例的类标签是一样的;
2)待分裂属性的集合T′为空集。
当没有待分裂属性,而节点中包含的实例的类标签有多个时,此时,我们不能确定这个节点将作为标注哪一个类标签的叶子节点。在通常的决策树中,那个类标签包含的实例最多,则这个节点就被标记为这个类标签的叶子节点。在我们的算法中,代价敏感决策树最终的目标最主要是为了减小误分类代价。所以,对于每一个叶子节点,算法标注其为某一个类标签,最主要的是为了减小误分类代价。假设,某训练数据的类标签Υ={1,2,…,K}有K个类标号,即训练数据中的实例可分成K类。在某一节点,T′为空,这一节点中有 pi个实例的类标签号是“i”,i=1,2,…,K。我们按照以下的标准来标记这个节点。

即当这个节点被标记为“i”的叶子节点时,其引起的误分类代价最小。
2.4 测试决策树
当决策树构造完成后,我们就要用测试数据测试决策树,验证决策树是否满足要求,即误分类代价、测试代价和等待时间代价是否满足一定的标准,以达到实际的应用需求。对于有缺失值的测试数据,文献[3]提出了四种测试策略,并总结了这四种测试策略。文献[3]总结出当前的代价敏感决策树测试策略主要有顺序测试和批量测试这两大类测试策略,提出了一个把这两种测试策略结合起来的混合策略。本文采取这种混合测试策略。具体如下:
首先,根据以下的公式计算每个属性的效度(Utility)。
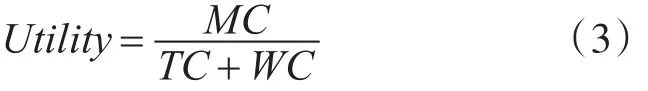
效度(Utility)是一个自然数,表示单位有形代价(TC+WC)的时间内能使无形代价(MC)降低的能力。效度与分类效果成比,效度越大,分类效果越好。
其次,用式(4)计算批量属性的效度。其中批量属性应满足一下两点:
1)这些属性作为批量属性是由领域专家标定的,且这些属性之间有公共的一部分测试代价,这里命名为CC(Commom Cost);
2)所有这些批量属性的花费的有型代价T_C(Tangible Cost)不能超过这次测试实例的总的资源。
批量属性的效度计算公式如下:

最后,由以上两步所计算的到效度最大的属性首先进行测试。当效度最大的是单个属性,则我们的测试策略可看作是顺利测试策略;另一方面,当效度最大的是批量属性,则看作是批量测试策略。
当所有的测试都完成或者测试实例的资源消耗完,则测试结束。
3 实验结果及分析
为了验证所提算法的有效性,我们从UCI机器学习仓库[15]选择了两个应用非常广泛且属性值为离散的数据集,数据集的基本信息如表1所示。每个数据集我们把它分成两份:训练集(60%)和测试集(40%)。由于数据集Car没有缺失值,Mushroom有2480个缺失值(只占1.39%),我们人工利用完全随机缺失(MCAR)机制分别把这两个数据集的属性缺失值比例占10%、20%、30%、40%、50%和60%。对于每个属性的测试代价在[1,100]之间随机分配,等待时间代价在[0,50]之间随机分配。而误分类代价如表2和表3所示。特别地,误分类代价是一个相对值,它与测试代价和等待时间代价的衡量标准是不一样。

表1 实验数据集

表2 Mushroom数据集误分类代价
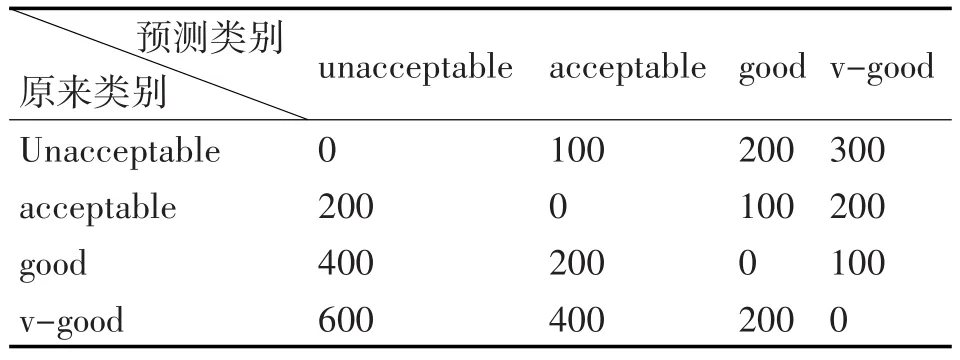
表3 Car数据集误分类代价
我们用三种不同的分裂属性准则来构建不同缺失率下的代价敏感决策树,分别是基于信息增益率的准则(M1),基于最小总代价的准则(M2),和我们的基于多目标最优化的准则(M3)。其中,在我们的方法中,各种代价所取的权重一样,即都是0.25。然后利用有缺失值得训练数据测试决策树,M1用的是C4.5的方法处理缺失值,M2用的是文献[4]的第1中方法处理缺失值,M3用的是本文提到的混合测试方法。实验结果如图1、2所示。

图1 Car数据集三种算法在不同缺失率下表现

图2 Mushroom数据集三种算法在不同缺失率下表现
其中,平均总代价就是所有训练数据所引起的误分类代价、测试代价和等待时间代价三种代价和的平均。由图1和图2可以看出,随着缺失率的增高,三种算法下的平均总代价(Average total cost)也随着增大。这是由于随着缺失率的增高,所构建的决策树性能随着降低,且训练数据时测试代价和等待时间代价都要曾高。但是,相对于另外两种算法,我们的算法表现得更好,效率更高。
4 结语
本文中我们把误分类代价、测试代价、等待时间代价和信息增益率构造多目标最优化问题模型,然后用线性加权和法把这个多目标最优化问题转化成单目标最优化问题模型进行求解,作为属性选择的准则,而后构建决策树,应用的一种混合的测试决策树方法。实验结果表明,我们所提的算法效率高,应用性强。但是,我们注意到,代价敏感决策树最主要的是降低误分类代价,所以在后续的工作中,我们可以把各种代价有差别的对待构造分层多目标最优化问题的数学模型,在求解最优值时把误分类代价首先考虑。
与此同时,过分地追求低误分类代价,有可能是以高误分率为代价的[11],误分率过高这势必会影响决策树的实际应用。所以在后续工作中,在构建决策树时有必要把误分率也考虑进去。
