一种基于有限自动机的程序分析技术研究
2019-12-23王超
王超

摘 要: 程序分析在软件测试和软件维护方面均有着重要作用。为实现软件程序的自动分析,基于有限自动机理论,提出一种实现软件静态信息识别的程序分析技术,根据程序设计语言的语法规则對程序语句进行了分类,针对每类语句设计了对应的识别自动机,在此基础上设计并实现了一个程序分析原型系统。系统应用结果表明,利用这一技术可以有效的提取出程序的控制流和数据流信息,能够为软件质量的定量分析和软件维护工作奠定良好基础。
关键词: 有限自动机; 程序分析; 信息识别; 软件维护
中图分类号:TP39 文献标志码:A 文章编号:1006-8228(2019)12-12-03
A technique of program analyzing based on the theory of finite automata
Wang Chao
(Dalian Naval Academy, Dalian, Liaoning 116018, China)
Abstract: Program analysis plays an important role in software testing and software maintenance. To realize the automatic analysis of the program, this paper presents a technique of information identification based on theory of finite automata. The program code is classified according to the grammar rules of the programming language, the finite automata is designed in allusion to the each kind of code, and then an archetypal of the program analysis is designed and realized. The application of the system indicates that the information of control-flow and data-flow can be analyzed effectively with this method, which will establish a favorable foundation for software quality analyzing and software maintenance.
Key words: finite automata; program analyzing; information identification; software maintenance
0 引言
软件的静态分析是软件测试和软件维护活动中一个必不可少的环节[1-2]。通过对软件实施静态分析,软件研发人员可以了解它的整个结构及各部分之间的相互关系,了解其中所采用的数据结构及变量的使用情况,有助于对软件的缺陷跟踪和软件可维护性预测等工作的开展[3]。随着软件规模的不断增长,采用人工方式实现软件理解工作已经越来越困难。
有限自动机作为一种自动识别装置,能够按照程序语言的语法规则识别出各种程序单元和实体[4],因此可以用作开发程序分析器的自动构造工具。本文在有限自动机的理论基础之上,提出一种实现软件静态信息识别的程序分析技术。
1 基本定义
构造有限自动机之前,首先需要对程序语言的词法规则和语法规则进行形式化描述,文法作为形式化语言理论的基本概念之一[5],是阐明程序语言语法的一个重要工具。
定义1 描述语言语法结构的形式规则称为文法。
文法[G]表示为一个四元组:[G=VT,VN,S,P],其中[VN]是一个非空有限集,每个元素称为非终结符;[VT]是一个非空有限集,每个元素称为终结符。[VT?VN=?],即[VT]与[VN]不含公共元素。用[V]表示[VT?VN], [V]称为文法[G]的字母表。[P]是一个有限的具有如下形式的规则的集合:[α→β]。其中,[α∈V+]称为规则的左部,[β∈V*]称为规则的右部(此处[?]表示作闭包运算);[S]是一个非终结符,称为开始符号,它至少要在一条规则中作为左部出现。
Chomsky在1956年创立形式语言谱系的时候,把文法分为四种类型即0型、1型、2型和3型。其中,2型文法又称为上下文无关文法,3型文法又称为正规文法。上下文无关文法和正规文法解决了程序语言的形式化描述问题,在此理论分析基础之上,可以预先定义好程序语言所有的词法语法规则,建立一个用于程序分析的规则库。
有限自动机作为一种识别装置,能够自动识别包含一系列规则的文法所定义的语言。有限自动机分为两类:确定的有限自动机(Deterministic Finite Automata,以下简称DFA)和不确定的有限自动机(Nondeterministic Finite Automata,以下简称NFA)。
定义2 一个确定的有限自动机([DFA])[M]是一个五元组:[M=K,Σ,f,S,Z],其中, [K]是一个有限集,它的每个元素称为一个状态;[Σ]是一个有限字母表,它的每个元素称为一个输入字符,所以也称[Σ]为输入符号字母表;[f]是转换函数,是在[K×Σ→K]上的映像,如[fki,a=kj][ki∈K,kj∈K]就意味着,当前状态为[ki],输入字符为[a]时,将转换到下一状态[kj],我们把[kj]称作[ki]的一个后继状态;[S∈K],是唯一的一个初态;[Z?K],是一个终态集,终态也称可接受状态或结束状态。
[NFA]和[DFA]的区别在于转换函数[f]的不同,[DFA]的[f]是在[K×Σ→K]上的单值映射,某种状态下给入一个输入字符将会确定的转到后继状态,而[NFA]的[f]则是多值映射,每种状态的后继状态数量不是唯一的。
2 基于DFA的程序分析
2.1 有限自动机的表示
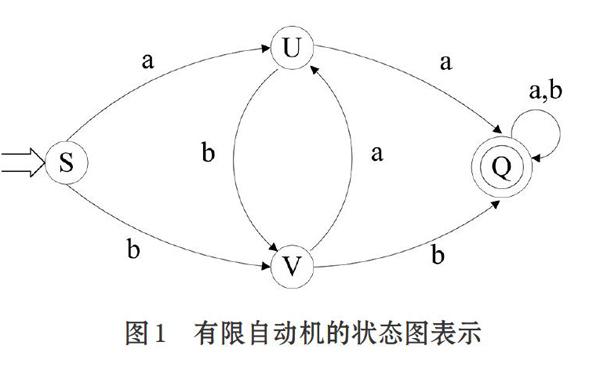
有限自动机通常采用状态图表示,以[DFA]为例,假定[DFA] M有m个状态,n个输入字符,那么这个状态图含有m个结点,每个结点最多有n条弧射出,整个图含有唯一一个初态结点和若干个终态结点,初态结点冠以“[?]”,终态结点用双圈表示,若[fki,a=kj],则从状态结点[ki]到状态结点[kj],画标记为a的弧。例如,对于这样一个[DFA]:
其中[f]定义为:
用状态图表示为:
对于[Σ*]中的任何字符串t,若存在一条从初态结到某一终态结的道路,且这条路上所有弧的标记符连接成的字符串等于t,则称t是可以为该有限自动机识别的,换一种方式描述,若[t∈Σ*],[fS,t=P],其中[S]为[DFA]的开始状态,[P∈Z],[Z]为终态集,则称[t]可为[DFA][M]所识别。
2.2 程序识别分类
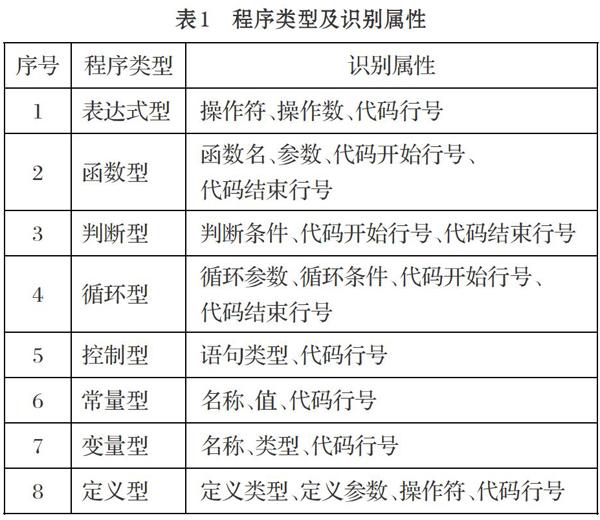
根据程序设计语言的语法规则,软件程序由定义、判断、函数、循环等多种类型的代码组成,为实现程序信息的识别,首先需要根据语法规则对程序进行分类,然后分别设计相应的有限自动机进行识别。以C语言为例,可以将程序类型分为表达式型、函数型、判断型、循环型、控制型、常量型、变量型和定义型等八大类,每种类型程序需要重点识别的属性如表1所示。
2.3 程序分析流程
在程序分类的基础上,设计基于DFA的程序分析流程如下。
Step1:根据每种类型语句的语法规则分别构造一个DFA;
Step2:扫描源程序并经过匹配分析,识别出程序中的关键字;
Step3:根据关键字来确定待识别的语句类型,并将该关键字有效作用范围内的代码提取出来,构造一个待识别的标识符集合;
Step4:将该类型语句的DFA与扫描得出的标识符集合进行匹配,匹配的同时,根据该句型的特点对程序的结构信息等属性进行提取和存储。
重复Step1~ Step4,最终可以达到理解整个源程序的目的。
例如,对于函数型程序,可以这样构造如下DFA:
其状态图表示如图2所示。
在使用DFA对源程序进行匹配、分析的同时,需要不断的将识别出的标识符进行分类记录,分类的依据是状态的变迁。DFA的每个状态都代表着一定的含义,因此每次发生状态改变时,字符扫描库里所记录的字符串都是具有特殊含义的。
例如,对于函数型语句的DFA,状态0处记录的是函数名,状态1处记录的是参数名,这样,我们在设计DFA时,就应该在状态0处将记录的字符串作为函数名保存,在状态1处将记录的字符串作为参数名保存,对于这样一条函数执行语句:function(kind, num, color);在采用DFA对其识别后,就可以记录下列信息:函数名为“function”,参数包括“kind”、“num”、“color”,这样即实现了对这条函数执行语句的理解。
2.4 程序分析技术的实现
基于以上理论研究成果,构建了一个基于DFA的程序分析原型系统,体系结构如图3所示。
基于该原型系统可以实施程序分析工作,通过对源程序的扫描、识别,提取出程序的静态信息,将程序的内部耦合关系、函数调用关系等数据流和控制流等信息以图形化的方式进行直观的显示,可以用于进一步的软件质量度量、软件缺陷追踪,以及软件维护活动[6],为项目的软件质量保证工作提供有益且实用的支持环境。
3 結束语
对于软件维护人员来说,程序分析是一项困难且费时的任务,本文提出的基于有限自动机的程序分析技术,根据程序设计语言的语法规则设置相关有限自动机后,能够对软件的多项静态参数进行识别,显著降低了用户理解软件的难度,对提高软件维护人员工作效率、减少软件维护成本能够发挥积极作用。本文提出的方法目前主要适用于C语言开发的软件,进一步的工作需要将该方法扩展到C++、Java等多种语言环境,增加适用的领域和范围。
参考文献(References):
[1] 丁剑洁,鱼滨,候红.软件维护中程序理解的应用与研究[J].计算机技术与发展,2007.17(4):218-221
[2] Liang Jia-biao,Li Zhao-peng,Zhu Ling.Symbolic execution engine with shape analysis[J].Computer Science, 2016.43(3):193-198
[3] 刘磊.程序分析方法[M].北京:机械工业出版社,2013
[4] 蒋宗礼,姜守旭.编译原理[M].北京:机械工业出版社,2017
[5] 殷人昆,郑人杰,马素霞,白晓颖.实用软件工程[M].北京:清华大学出版社,2012
[6] Swarup Kumar Sahoo, John Criswell, Chase Geigle. Using likely invariants for automated software fault localization[J].ACM SIGARCH Computer Architecture News,2013.41(1):139-152
