探讨用Hadoop实现物流业务流程中的数据存储
2019-11-11陈玉林王武
陈玉林 王武

摘要:“互联网+”的思维已应用到国内各行各业,web方式的信息系统对物流业务中起到了很大的支撑作用。但由于业务量的快速增长,使得大量的物流数据不能被一般的关系数据库所保存和应用。该文探讨用Hadoop框架来实现物流业务中大数据的存储。
关键词:Hadoop;物流;大数据存储
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2019)27-0223-02
1 Hadoop框架
Hadoop是一个开源的分布式数据存储及分析应用程序。 Hadoop不是物理数据库,而是处理结构化和非结构化数据的软件框架。Hadoop将大量数据分发到不同的处理节点,然后将收集的结果组合在一起。由于系统通常使用较小批量的本地化数据而不是整个库的内容,因此这种方法可以更快地处理数据。Hadoop主要使用Hadoop分布式文件系统(HDFS)和MapReduce来存储和分析数据。HDFS是Hadoop应用程序使用的主要分布式存储。 HDFS会收集数据并将其存储在群集中,直到用户准备好使用它时才会调用数据。Hadoop将非结构化数据分离为节点,这些节点构成更大型数据架构的单个部分。节点链接在一起,能够组合存储在Hadoop的数据,以根据实际应用的需要而设置相应参数,从而生成预想中的结果。
2 物流业中的业务数据
物流的业务数据,包括仓储管理、在途运输、、搬运与装卸、货物包装与流通加工等物流环节中涉及的数据、信息等,而这些数据基于互联网软件系统获取或输入、移动设备、传感器采集数据等。这些数据存储量往很大,没有单纯的存储和组织方式,不会像我们平时自己造的表格那样简单明了,由于业务量很大,所以还会实时产生海量的新数据。
目前的物流领域中,冷链物流、医药物流和电商物流分支在试着运用大数据技术,来进行数据存储和业务决策分析,而从实际应用情况来看,电商物流凭借大量的网民在线购买产品,拥有了一定的先发优势,阿里巴巴旗下的菜鸟网络的建立,更是给电商物流在大数据应用上带来了更好的发展趋势。大数据在物流企业中的主要是应用在物流企业行政管理、物流客户管理、物流决策及物流智能预警等过程中。物流大数据的优势主要体现在三个方面:第一,物流大数据可以根据销售市场进行业务数据分析,提高运营管理效率,对资源合理规划与分配,调整业务结构,确保每个业务均可赢利;第二,物流大数据的预测技术可根据消费者的消费偏好及习惯,预测消费者的高中低需求,把商品物流各环节与客户的需求目标一起同步进行,并规划出运输路线或配送路线,这样,不但可以缓解运输高峰期的物流压力,还可以提高客户的满意度和粘度。
3 大数据的存储的主要方式
物流大数据主要存储技术是采用MPP关系型数据库与Hadoop的非关系型数据库:
方法一:对于结构化数据采用基于列存储+MPP架构的数据库集群,在技术上在面向结构化数据的分析设计和开发时,能有效处理PB级别高质量的结构数据,为应用提供丰富的SQL和事务支持,从而可以解决数据处理性能问题。在用户价值上,新型数据库是运行在x-86 PC服务器之上的,可以大大降低数据处理的成本。
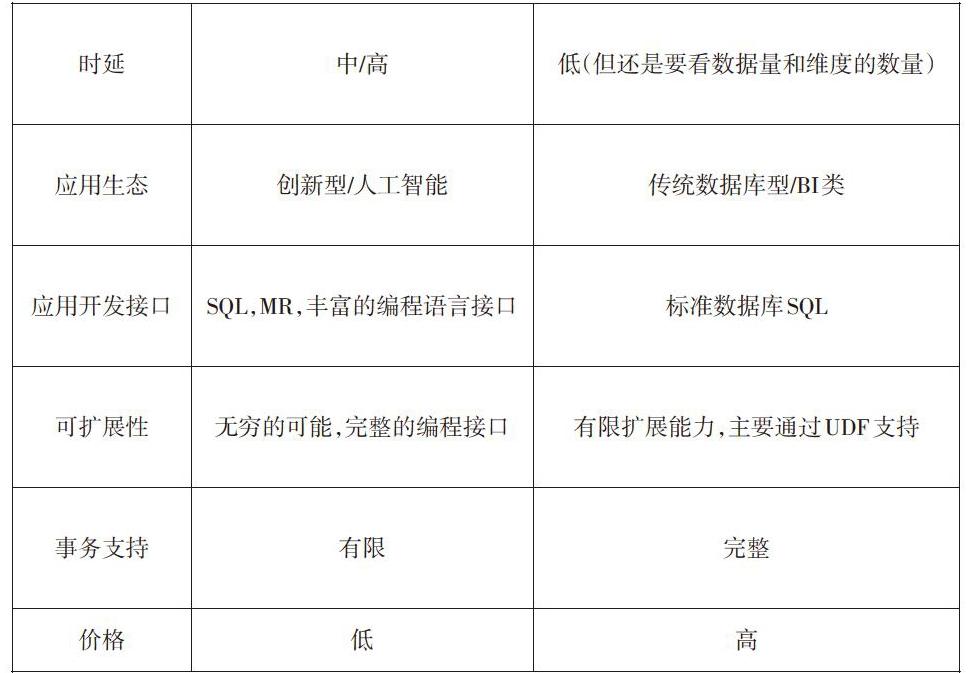
方法二:对于非结构化、半结构化数据存储上采用基于Hadoop的技术的数据库集群。Hadoop平台是开源的技术,主要由HDFS、Hive和HBase构成,具有分布式存储以及并行计算的特性,因此可轻松扩展存储结点和计算结点,解决数据增长带来的性能瓶颈。如下表1对两者的一些特性做了比较。
表1 Hadoop与MPP数据仓库的比较
[特性 Hadoop MPP数据仓库 计算节点数 可到数千个 一般1000个以内 数据量 支持大于10P 一般不大于10P 数据类型 关系型,半关系型,无结构化,语音,图像,视频 关系型 时延 中/高 低(但还是要看数据量和维度的数量) 应用生态 创新型/人工智能 传统数据库型/BI类 应用开发接口 SQL,MR,丰富的编程语言接口 标准数据库SQL 可扩展性 无穷的可能,完整的编程接口 有限扩展能力,主要通过UDF支持 事务支持 有限 完整 价格 低 高 ]
5G和物联网技术的应用,数据的存储越来越多,因此用hadoop进行非结构化数据存储和分析,会有更高的效率和扩展性。
4 对物流海量数据存储所采取的策略
物联网的兴起,各种传感器的应用,持续产生出数量巨大的物流业务数据信息。而这些数据中,文件长度比较短,往往只有几十KB。这种小文件大批量的数据采集与存储,在物流业务中出现的范围很广,也是提高存储性能的一个核心点。
谷歌公司的开源Hadoop框架中,文件系统HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。小文件过多,会过多占用namenode的内存,并浪费block。文件的元数据包括文件被分成了哪些blocks,都是存储在namenode上的。文件长度太小,寻道时间大于数据读写时间,Hdfs的设计原理是接近磁盘读取速度,之所以把block块设置很大,是因为想做到寻道时间远小于文件读取数据块的时间,接近磁盘读取速度。可以采用以下的几种方式来解决HDFS中出现的以上问题:
(1)做出一个小文件存储系统。它是基于HDFS的,采用分布式方式构建,对小文件进行“写缓存”和“写合并”,优化小文件的写吞吐率,通常文件大小不超过1M。
(2)做出一个缓存系统,尽量缩减元数据大小,将元数据全部加载入内存。它是分布式的,可以缓存小文件的大批量写操作。首先把这些小文件缓存在内存,然后根据数据相关性特征,将保存相邻地理位置信息的小文件合并成一个大的逻辑文件,并为这些小文件建立索引以便对小文件进行存取,最后把它写入到底层的HDFS中。同时,在客户端數据采集时,文件名中最好包含一些元数据信息,例如货物的大小、时间、访问频次等等信息,以及该文件所在的逻辑块号。整个系统可以不使用传统的目录树结构,从而可以减少查询的开销。
(3)做出一个聚类算法。在大数据领域聚类算法可以起到十分重要的作用,只有通过有效地聚类才能得到非常直观的结果。根据业务环节或区域地点采集数据,查询订单号关联性,建立评估模型,编写出数据输出点的快速聚类算法。在实践中,聚类中的输入变量不能太多,变量之间的相关性会损害聚类效果,更会使运算耗时。
5 结语
当前,物流业务中产生的数据越来越多,只有使数据能够良好地存储起来,才可以进一步分析和利用。万物相联的时代,数据是物流企业未来运营的最佳资产,而高效存储则是最初的起点。
参考文献:
[1] 任仁.Hadoop在大数据处理中的应用优势分析[J].电子技术与软件工程,2014(15):194.
[2] 管宇旻,汤亚杰,徐剑桥.计量检测数据采集与智能化管理[J].上海计量测试,2017(4).
[3] 董新华,李瑞轩,周湾湾,等.Hadoop系统性能优化与功能增强综述[J].计算机研究与发展,2013(S2) .
【通联编辑:代影】
