藏文分词的前向匹配算法研究
2019-11-11王福钊周雁
王福钊 周雁

摘要:藏文分词是进行藏文文本信息化处理的基础,是一切工作的核心步骤。文中对最大前向匹配算法的藏文分词进行了研究,并对该算法进行了改进。文中详细叙述了改进的前向最大匹配算法思想,同时以同一藏文文本语料使用改进前后的前向最大匹配方法进行分词实验,并比较了两者的分词效率,最后结合实验结果探讨了该方法的优点以及存在的问题。
关键词:藏文;分词;前向最大匹配;算法改进
中图分类号:TP391.1 文献标识码:A
文章编号:1009-3044(2019)27-0195-03
Abstract: Tibetan participles are the basis for the informatization of Tibetan texts and are the core steps of all work. In this paper, the Tibetan word segmentation of the maximum forward matching algorithm is studied and the algorithm is improved. In this paper, the improved forward maximum matching algorithm is described in detail. At the same time, the forward-maximum matching method before and after the improvement of the same Tibetan text corpus is used to carry out the word segmentation experiment, and the word segmentation efficiency of the two is compared. Finally, the method is discussed with the experimental results. The advantages and problems.。
Key words: Tibetan; participle; forward maximum matching; algorithm improvement
1 引言
藏文是古老而历史悠久的中华民族语言文字之一,是藏族文化传播和弘扬的重要载体。在藏文信息化处理中,藏文分词是最基础且最重要的关键步骤。藏文分词是进行藏文句子的生成、词频统计、句法分析、自動文摘、自动分类、电子词典的建设、机器自动翻译系统的开发和搜索引擎的设计与实现等研究的坚实基础。从藏文的句子组成上看,藏文属于藏汉语系,同汉文一样与英文不同,英文句子由空格明显隔开的词与词连接构成,而藏文句子和汉文句子一样由没有明显的分割标记隔开的词与词连接构成[1]。在藏文中词通过音节(也称为字)组成,音节之间有明显的分割标记隔音符“?”。虽然藏文分词的研究已经取得了一定的成果,但还存在分词效果不理想以及受特定文本语料的限制问题,至今许多的研究者还在对分词方法进行不断的优化和改进。在藏文信息处理中实现高效率、高准确率的自动分词仍然是亟待解决的重要问题。
2 研究基础
2.1 藏文结构
正藏文起源于吐蕃松赞干布时期,由吐蕃大臣吐弥桑布扎结合梵文创造而成。藏文属于藏汉语系,同汉文一样属于拼音型文字,但与汉文不同的是藏文属于拼写一体,其书写和拼读皆通过30个辅音字母和5个元音字母(其中?a为省略不写)构成[1]。藏文的辅音和元音字母如下表1,2所示。
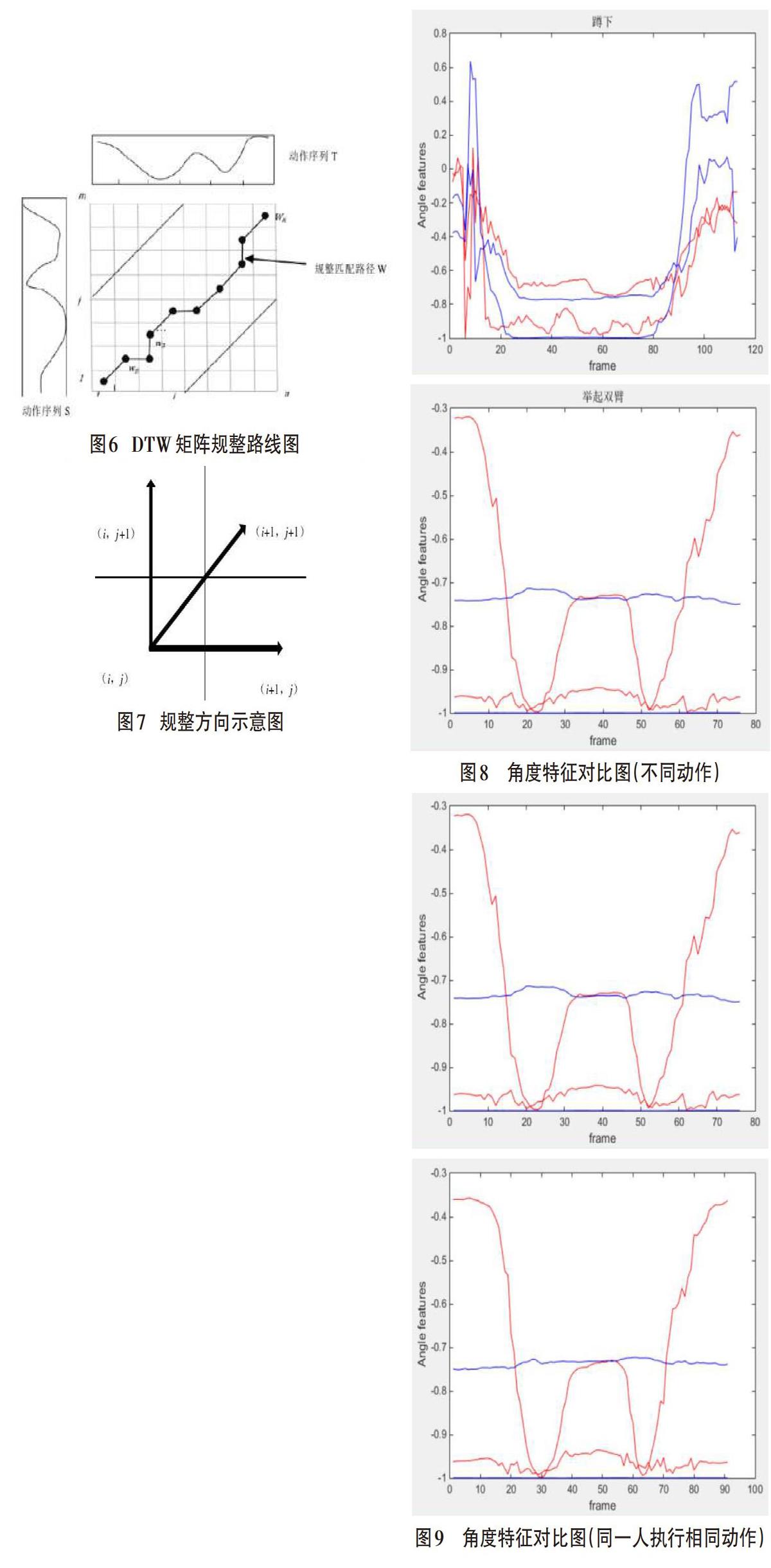
藏文字形结构属于纵向-横向共同构成的平面结构,以基字(一个辅音字母)为核心。现代藏字有一般结构和特殊结构。在一般结构中,藏字至少由一个辅音字母组成,最多可由七个字母组成,如藏字?和???????,其中元音不能单独出现,只能加在字丁(纵向叠加部分,如???)部分的上下位置[1]。现在藏字的一般结构如下图1所示。
在特殊结构中,有以下如包含再下加字???,???等、合并的藏字????,????等情况的出现,这些特殊结构虽存在但使用较少。现代藏文文本通过由多个藏字以及藏字间的隔音符构成句子,句子与句子之间由单垂符或双垂符分割构成段落[1]。
2.2 预处理
藏文文本的组成结构较为复杂,在文本中存在藏文符号以外的其他符号以及藏文词语在词法、语法上的一些变形。所谓预处理就是要将文本进行理论标准化,将句子常规表述转换为理论程序能够处理的一般形式。(1)在文本中会出现如逗号、引号、冒号等非藏文符号,在处理过程中首先需要进行符号归一化;(2)在藏文文本中存在大量的缩略词和虚词使用,需要对缩略词进行缩略还原处理,对虚词进行消除歧义处理。藏文自动分词需要特殊考虑藏文虚词“??,??,??,??,?,?”前是否添加后加字?等紧缩词的还原问题。如:对????????????? 这个句子进行自动分词时,不能将句子中的???????分为一个词,因为???????这词最后两个字符“??”属于藏文格文法中的属格助词。也不能将???????直接分成?????/??,因为,??没有后加字,违反了藏文传统文法“字性组织法”的规则。正确的自动分词结果为??????/?? ,在分词过程中首先要将后加字?还原,再进行分词[3-4]。
2.3 分词原理
藏文自动分词是将一个完整的藏文句子通过计算机程序自动切分为有具体意义的独立的词。在藏文分词的方法上大致分为基于词典匹配的分词方法和基于机器学习的分词方法两种[3]。在本次研究中将对词典匹配方法中的前向最大匹配方法进行改进,并对改进前后的前向最大匹配方法进行分词效率比较。
