伪标签置信选择的半监督集成学习视频语义检测
2019-10-23尹玉詹永照姜震
尹玉 詹永照 姜震


摘 要:在視频语义检测中,有标记样本不足会严重影响检测的性能,而且伪标签样本中的噪声也会导致集成学习基分类器性能提升不足。为此,提出一种伪标签置信选择的半监督集成学习算法。首先,在三个不同的特征空间上训练出三个基分类器,得到基分类器的标签矢量;然后,引入加权融合样本所属某个类别的最大概率与次大概率的误差和样本所属某个类别的最大概率与样本所属其他各类别的平均概率的误差,作为基分类器的标签置信度,并融合标签矢量和标签置信度得到样本的伪标签和集成置信度;接着,选择集成置信度高的样本加入到有标签的样本集,迭代训练基分类器;最后,采用训练好的基分类器集成协作检测视频语义概念。该算法在实验数据集UCF11上的平均准确率到达了83.48%,与Co-KNN-SVM算法相比,平均准确率提高了3.48个百分点。该算法选择的伪标签能体现样本所属类别与其他类别的总体差异性,又能体现所属类别的唯一性,可减少利用伪标签样本的风险,有效提高视频语义概念检测的准确率。
关键词:视频语义概念检测;半监督;集成学习;伪标签;置信度
中图分类号: TP391.41
文献标志码:A
Semi-supervised ensemble learning for video semantic detection based on pseudo-label confidence selection
YIN Yu, ZHAN Yongzhao*, JIANG Zhen
School of Computer Science and Telecommunication Engineering, Jiangsu University, Zhenjiang Jiangsu 212013, China
Abstract:
Focusing on the problems in video semantic detection that the insufficience of labeled samples would seriously affect the performance of the detection and the performances of the base classifiers in ensemble learning would be improved deficiently due to noise in the pseudo-label samples, a semi-supervised ensemble learning algorithm based on pseudo-label confidence selection was proposed. Firstly, three base classifiers were trained in three different feature spaces to get the label vectors of the base classifiers. Secondly, the error between the maximum and submaximal probability of a certain class of weighted fusion samples and the error between the maximum probability of a certain class of samples and the average probability of the other classes of samples were introduced as the label confidences of the base classifiers, and the pseudo-label and integrated confidence of samples were obtained through fusing label vectors and label confidences. Thirdly, samples with high degree of integrated confidence were added to the labeled sample set, and base classifiers were trained iteratively. Finally, the trained base classifiers were integrated to detect the video semantic concept collaboratively. The average accuracy of the algorithm on the experimental data set UCF11 reaches 83.48%. Compared with Co-KNN-SVM algorithm, the average accuracy is increased by 3.48 percentage points. The selected pseudo-label by the algorithm can reflect the overall variation among the class of samples and other classes, as well as the uniqueness of the class of samples, which can reduce the risk of using pseudo-label samples, and effectively improve the accuracy of video semantic concept detection.
Key words:
video semantic concept detection; semi-supervised; ensemble learning; pseudo-label; confidence
0 引言
在多媒体技术和互联网技术大发展的环境下,视频资源得到了人们的广泛关注。近些年来,智能携带设备所代表的移动互联网的兴起,视频特别是短视频依然是人们最感兴趣的内容之一。在这种情况下,如何快速又准确地帮助用户获取其关注的语义概念[1],更有效地检测出视频事件,已经成为当前迫切需要解决的问题[2-4]。
网络视频检索早先是采用人工标注视频语义概念,由已标注的视频语义概念实现检索;但是手工标注十分耗时,同时由于每个人对视频理解的差异性,手动标注还具有主观性,无法应对大量而丰富多彩的视频内容检索任务。为了克服手工标注的缺点,研究者们提出了基于内容的视频检索检测方法,但是这种方法采用的是视频的低层视觉特征进行相似性检索检测,不能体现视频的高层语义信息。为了跨越低层特征到高层语义概念之间的语义鸿沟,基于语义的视频检测技术应运而生。基于语义的视频检测技术利用人们所理解的视频内容的高层语义概念建立了低层特征与高层语义概念之间的映射关系,并使用这种映射关系实现视频内容的检测,使计算机对视频的理解更贴近人的思维,所表达出的语义概念更加准确,因此基于语义的视频检测技术已成为了当今研究视频检索检测的热门和热点。
基于语义的视频检测最关键的技术之一是语义模型的建立。充分的视频语义模型的描述和其泛化能力是提高视频语义概念检测准确性的关键所在,但是在现实应用中,由于训练模型的有标记样本严重不足,而未标记样本往往很容易收集,因此如何利用这些大量的未标记样本来更合理地建立视频语义概念模型并使其具有良好的泛化性能,就成为了研究重点。半监督学习[5]恰恰提供了一条利用“廉价”的未标记样本的途径,它能自动地利用未标记样本来提升语义概念分类器模型的性能;但是预测效果不好的分类器会造成误差传播,导致最终学习得到的分类器的性能提升不足。而集成学习[6]则是通过构建并结合多个有差异的分类器来协同完成学习任务,可以有效地抑制误差传播,从而可以获得比单一分类器更显著的性能提升和泛化效果。
目前利用对无标记样本进行半监督集成学习获得的伪标签样本来增强分类器训练还存在着伪标签样本引入的噪声问题[7-9],如何更置信地选择伪标签样本促进分类器的协同学习、提升视频语义概念检测性能仍需进一步研究。
为了保证集成学习的基分类器的差异性,解决半监督学习的分类器效果不理想导致的伪标签误差传播问题,本文提出一种伪标签置信选择的半监督集成学习的视频语义检测方法。该方法利用不同特征所训练出的基分类器进行伪标签预测,引入加权融合样本所属某个类别的最大概率与次大概率的误差和样本所属某个类别的最大概率与样本所属其他各类别的平均概率误差,来确定样本作为伪标签的置信度,融合选择伪标签置信度高的样本加入到有标签的样本集,迭代训练基分类器,最后采用训练好的基分类器集成融合检测视频语义概念,以期有效减小利用未标记样本的风险,提高视频语义概念检测的准确性。
1 相关研究
1.1 基于多特征的视频语义检测方法
基于多特征的视频语义检测就是利用不同的特征提取算法,采用不同的结合策略对视频中的对象进行检测的方法。它主要分两类,第一类是只利用视频中视觉图像特征进行语义检测。此类方法分别使用基于视觉图像的特征提取算法对视频进行特征提取,然后将得到的特征向量采用某种方法结合,形成统一的特征向量。文献[10]利用多特征加权融合方法提取行人特征,与前一帧中的行人特征信息进行匹配;文献[11]分别提取颜色、区域和纹理特征向量,然后结合这些特征向量和主成分分析(Principal Component Analysis, PCA)得到用于分类的低维特征向量;
这里的两幅彩色RGB特征图是根据不同的特征公式得到的两个不同的特征。
文献[12]把根据不同的特征公式得到的两幅彩色RGB(Red Green Blue)特征图、纹理特征图和运动特征图这四个特征映射通过四元数离散余弦变换,组合生成四元数特征。第二类则是利用视觉图像特征以外的特征和视觉图像特征相结合的方法来表达视频的特征。在文献[13]中提取人物衣服的颜色以及人物声音作为视频特征,而文献[14]则结合颜色和纹理的图像特征和相应的文本特征作为视频的特征。这类特征组合方法虽然有较好的效果,但并不是所有的视频都会具有音频或文本等特征,所以该类特征组合方法有较大的局限性。而在视频语义检测中所采用的特征提取方法,既要表达人们观看视频时所关注的人或物体的颜色、轮廓和纹理等信息,又要适应环境和人或物体的运动而导致的变化。HSV(Hue Saturation Value)颜色模型恰恰符合人眼的視觉特征,直接用色调(Hue, H)、饱和度(Saturation, S)和亮度(Value, V)这三要素来表达颜色空间。而局部二值模式(Local Binary Pattern, LBP)是一种描述图像局部纹理的特征提取方法,主要反映像素与周围像素之间的关系,它具有灰度不变性和旋转不变性。方向梯度直方图(Histogram of Oriented Gradients, HOG)是一种进行物体检测的特征描述方法,通过计算局部区域的每个像素的梯度,并且统计直方图来构成特征,具有几何和光学的形变不变性。根据以上三种特征提取方法的特点,本文通过使用这三种特征提取方法所训练出的代表不同特征视角的分类器来保证集成学习基分类器的差异性。
1.2 半监督与集成学习视频语义检测方法
有不少研究者研究了基于半监督学习的视频语义检测方法。Martin等[15]提出了一个完整的、一般的和模块化的半监督系统,它能够检测和跟踪多摄像机运动视频中的每个运动员,而且为了匹配跨摄像机的轨迹,重点研究了所检测出的斑点的不同轨迹的融合。
Zhan等[16]提出了一种基于视频语义检测的自适应概率超图的半监督增量学习方法。在概率超图模型中,可以自适应地决定顶点是否属于超集。该模型可以克服传统概率超图模型中属于同一超集的固定数顶点的缺陷,具有很强的鲁棒性。
Misra等[17]提出了一种半监督的方法,该方法在长视频中定位多个未知对象实例,从少量有标签框开始,学习和标注数十万个对象实例;同时还提出了用于约束半监督学习过程的准则。实验通过评估各种度量上的自动标记数据验证了该方法的有效性。但这些方法在不同程度上存在着伪标签样本引入的噪声问题,限制了语义概念分类模型性能的提升。
在基于集成学习的视频语义概念检测方面,Yang等[18]提出了一种积极的增强型集成学习框架,包含了新的采样技术和基于基本学习算法的集成学习机制,在探索性实验中证明了该框架的有效性。
Mitrea等[19]主要研究视频监控多实例人物检索问题,使用增强、打包和混合(堆叠)这三种基于集成学习的技术训练多个学习器,并且组合其输出。该方案在评估系统中也得到了较好的结果。
文献[9]提出了一种协同训练半监督学习方法——Co-KNN-SVM,该方法利用K近邻(K-Nearest Neighbors, KNN)和支持向量机(Support Vector Machine, SVM)作为基分类器,分别用这两个基分类器对无标签样本进行预测,形成伪标签样本集,然后利用伪标签选择策略,选择出具有较高置信度的样本加入到对方训练集中迭代训练,利用这两个性能较好的基分类器进行视频语义概念检测分类。但这些方法还未更合理考虑利用各分类器检测的置信度来融合检测语义概念,影响了语义概念检测分类性能的进一步提升。
2 伪标签置信选择的半监督集成分类器训练
2.1 算法的基本思想
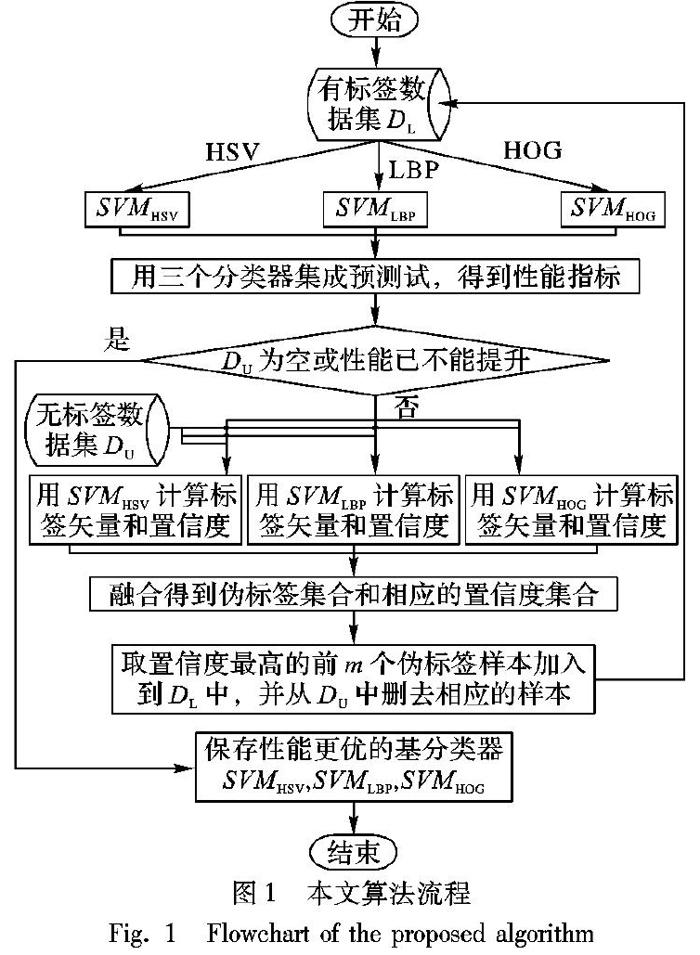
现有研究已表明集成特征不同的基分类器进行任务的分类可提高分类的性能[20-22],然而在有标签训练样本有限的情形下,各基分类器训练不足会影响分类性能,从而影响集成分类的最终分类性能与泛化能力。伪标签置信选择的半监督集成分类器训练的基本思想是:采用半监督集成学习在无标签的样本中更置信地判断出其标签,即伪标签,并将置信度高的伪标签样本选择出来,加入到有标签的训练样本集中重新训练各基分类器,以便提升各基分类器的分类性能,从而提升集成分类最终的分类性能与泛化能力。本文算法将样本集分为:有标签样本集DL、无标签样本集DU和预测试样本集DT,分别采用HSV、LBP和HOG方法对视频关键帧进特征提取,使用这些有差异性的特征作为各自的支持向量机基分类器SVMHSV、SVMLBP和SVMHOG训练和预测试的特征向量。
首先,在有标签样本集DL上训练三个基分类器;然后,使用这三个分类器对无标签样本集DU进行预测,得到相应的样本伪标签和置信度,
并根据伪标签融合选择策略选择置信度最高的前m个伪标签样本,将这些样本从DU中删去并加入到DL中,从而形成新的DL和DU,
再进一步迭代训练基分类器,并用预测试样本集DT进行集成分类测试,从而获得集成分类性能更高的基分类器,直到无标签样本集DU为空或集成分类性能已无法再提升为止。本文算法的处理流程如图1所示。
2.2 伪标签选择策略
在半监督学习伪标签样本重新注入过程中,需要根据置信度选择伪标签样本。传统的方法是选择基分类器的最大类预测概率作为选择伪标签样本为该类的置信度,文献[9]提出了对基分类器采用样本所属某个类别的最大概率与次大概率的误差作为该基分类器的置信度。但是这些置信度并没有充分表达样本的随机分布特性,因此这些置信度无法合理地权衡样本所属类别与其他类别的总体差异性和所属类别的唯一性。所以本文考虑加权融合样本所属某个类别的最大概率与次大概率的误差和样本所属某个类别的最大概率与样本所属其他各类别的平均概率误差,以确定样本作为基分类器对伪标签选择的置信度,该置信度既可考虑样本所属类别与其他类别的总体差异性,又可考虑所属类别的唯一性。该置信度算式如下:
Cg( x )= (1-λ)(Pmaxg( x )-Psubmaxg( x ))+
λ Pmaxg( x )- 1 n-1
∑ n-1 i=1, pg,i( x )≠Pmaxg( x )
pg,i(x)
(1)
其中:Cg( x )表示基分类器g判别样本 x 所属某个类别的标签置信度,g∈{SVMHSV,SVMLBP,SVMHOG};Pmaxg( x )表示基分类器g判别样本 x 所属某个类别的最大概率;Psubmaxg( x )表示基分类器g判别样本 x 所属某个类别的次大概率; 1 n-1
∑ n-1 i=1, pg,i( x )≠Pmaxg( x )
pg,i( x )表示基分類器g判别样本 x 所属某个类别的除了最大概率之外的概率平均值;pg,i( x )表示基分类器g判别样本 x 所属类别i的概率;λ为置信度参数,0<λ<1;n为数据样本集的类别总数。
本置信度算式有效性和可行性分析:
式(1)等号右边的第一项(+号前的项)是测量样本所属某个类别的最大概率与所属另一类别且是所有类别中的次大概率的误差,该误差越大,表明分类器将样本鉴别为最大概率的类别越确定、越唯一。这与文献[9]的思想是一致的,文献[9]的置信度是本置信度的特例。式(1)等号右边的第二项(+号后的项)是测量样本所属某个类别的最大概率与样本所属其他各类别的平均概率误差,该误差越大,相对其他类别来看,分类器将样本鉴别为最大概率的类别越值得肯定。因此本置信度算式综合考虑了以上2项的误差,既可衡量分类器判别类别的唯一性程度,又可衡量分类器判别类别值得认可的程度,故本置信度算式是有效和可行的。
3 多分类器集成的视频语义概念检测
对一个待检测视频样本 x k,本文的多分类器集成的视频语义检测是基于待测样本在每个基分类器检测的语义概念类别的置信度的,集成融合各基分类器的检测类别矢量和置信度,将集成检测置信度最高的类别作为最终的视频语义概念类别。该算法有以下四个步骤:
首先,对待检测视频样本 x k
取k个关键帧,选用HSV、LBP和HOG这三种特征提取方法分别对这些关键帧进行特征提取并形成特征向量;
其次,分别利用迭代训练得到的更优基分类器SVMHSV、SVMLBP和SVMHOG对待检测样本 x k进行预测,得到预测标签矢量 y HSV( x k)、 y LBP( x k)和 y HOG( x k);
再次,使用式(1)得到各分类器的标签置信度CHSV( x k)、CLBP( x k)和CHOG( x k),再利用式(2)集成融合各基分类器的检测类别标签矢量和标签置信度;
最后,利用式(3)和(4)将集成检测置信度最高的类别作为最终的视频语义概念类别。
多分类器集成的视频语义概念检测具体算法如算法2所示。
算法2
多分类器集成的视频语义概念检测算法。
输入
已经训练好的具有更优性能的三个基分类器SVMHSV,SVMLBP,SVMHOG,待检测视频样本 x k。
输出
视频样本 x k的视频语义概念类别l x k。
步骤1 对待检测视频样本 x k取k个关键帧,选用HSV、LBP和HOG这三种特征提取方法分别对这些关键帧进行特征提取并形成特征向量。
步骤2 x k SVMHSV y HSV x k, x k SVMLBP y LBP x k, x k SVMHOG y HOG x k。
步骤3 x k 式(1) CHSV x k, x k 式(1) CLBP x k, x k 式(1) CHOG x k,L( x ) 式(2) a1,a2,…,an。
步骤4 利用式(3)和(4)将集成检测置信度最高的类别作为最终的视频语义概念类别l x k。
返回:视频样本 x k的视频语义概念类别l x k。
4 实验结果与分析
4.1 实验数据集
实验采用的数据集是UCF YouTube Action数据集(UCF11)。在UCF11中,所有的视频都转换为29.97帧/s(frames per second, fps),并且完成了所有视频的注释。该数据集包含11个动作类别:投篮球(basketball shooting)、
骑自行车(biking/cycling)、
跳水(diving)、打高尔夫(golf swinging)、骑马(horse back riding)、颠球(soccer juggling)、荡秋千(swinging)、打网球(tennis swinging)、蹦麻(trampoline jumping)、打排球(volleyball spiking)和溜狗(walking with a dog),如图2所示。每个类别有25个组,每组有4个以上的视频片段,同一组中的视频具有相同的目标、类似的背景和类似的视角等特点。在以上数据集上,利用基于视频片段边界的方法来进行对视频进行关键帧提取,选取视频片段的第一帧、中间帧和最后一帧这三帧作為关键帧,然后在这些关键帧的基础上,利用本文提出的算法进行视频语义检测。
4.2 置信度参数的实验分析
在半监督学习伪标签样本重新注入过程中,需要根据置信度选择伪标签样本。本文的置信度选择方法如式(1)所示。该置信度是两种误差的加权融合,其中λ是置信度参数。在预测试集上,让λ在[0.1, 0.9]区间变化,得到了不同的置信度参数下的视频语义概念预测准确率的变化情况,如图3所示。从图3可以看出,在随着λ增大,视频语义概念预测准确率逐步提高,这说明代表类别概率波动的误差在分类器分类的置信度确定中有重要的贡献。当λ=0.7时,预测准确率达到最佳状态,所以本文将选用λ=0.7作为分类器分类的置信度参数。
4.3 实验对比分析
为了验证本文算法的有效性,本文选择在HSV、LBP、HOG和HSV+LBP+HOG这四种特征空间下训练的SVM分类器和Co-KNN-SVM算法[9]与本文的算法进行对比实验,并采用十折交叉验证来计算各算法的检测分类准确率。
表1给出了分别在220、440、660个有标记样本下不同方法的平均检测准确率。由表1可知,由于本文的方法和Co-KNN-SVM采用了半监督集成学习,可以利用伪标签样本来提升分类器性能,所以它们都比单独使用SVM分类器进行视频语义检测具有更高的准确性。但是Co-KNN-SVM算法是基分类器KNN和SVM分别把置信度较高的伪标签样本加入到对方的有标签训练集中,这样会很容易引入噪声,而本文算法是集成三个分类器,采用了更加合理的置信度选择标准,选取置信度较高的伪标签样本加入到有标签训练集中进行迭代训练,该置信度选择策略既体现了样本所属类别与其他类别的总体差异性,又能体现所属类别的唯一性,可有效降低伪标签样本引入的噪声,从而提升分类器的泛化能力,所以分类准确率高于Co-KNN-SVM方法,在有标记样本数为220、440和660时,本文方法比Co-KNN-SVM方法分别高出255个百分点、1.40个百分点和3.48个百分点。
表2給出了本文方法分别在220、440、660个有标记样本下11个类别的初始检测准确率和最终检测准确率。从表2可以看出,本文方法在三种有标记样本数下,经过迭代集成训练,每个类别的检测准确率都有了较大的提升。在有标记样本数为220时,diving、tennis swinging和volleyball spiking三类的检测准确率达到了90%以上,平均检测准确率提高了2220个百分点。在有标记样本数为440时,平均检测准确率提高了13.36个百分点。在有标记样本数为660时,basketball shooting类的最终检测准确率也提升到了90%以上,平均检测准确率提高了8.99个百分点。这说明采用伪标签置信选择的半监督集成分类器迭代训练方法能有效提高视频语义概念检测准确率。
同时,又对目前优秀的视频语义概念检测分类方法在UCF11数据集上的实验结果进行比较。文献[23]采用多特征的早期和晚期融合,并且结合场景上下文去处理视频样本,检测分类准确率达到了73.20%;文献[24]采用将光流场和哈里斯三维角探测器相结合的方法来获得一种新的视频序列的时空估计,然后从估计动作区域中提取局部特征,最后利用SVM进行检测,检测分类准确率达到了76.06%;文献[25]研究了基于多通道的时空兴趣点的视频语义概念问题,检测分类准确率达到了78.6%;本文方法检测的准确率分别比文献[23] 、文献[24] 和文献[25]方法提高了10.28个百分点、7.42个百分点和4.88个百分点。这说明采用伪标签置信选择的半监督集成分类器迭代训练的多分类器集成的检测分类方法能更合理融合多分类器协同检测分类,有效提高视频语义概念检测准确率。
5 结语
本文针对有标记样本不足会严重影响视频语义概念分类器的检测性能,以及由于在半监督集成学习中伪标签样本选择置信不足而影响集成分类器性能提升有限的问题,提出了一种伪标签置信选择的半监督集成学习的视频语义概念检测方法。该方法引入加权融合样本所属某个类别的最大概率与次大概率的误差和样本所属某个类别的最大概率与样本所属其他各类别的平均概率误差,来确定基分类器将样本作为伪标签的置信度,融合选择伪标签置信度高的样本加入到有标签的样本集,迭代训练基分类器,这种伪标签的选择可有效减少利用伪标签样本的风险;再利用这种方法训练好的基分类器集成检测视频语义概念。实验结果表明,本文提出的方法与其他方法相比,能有效减少伪标签样本引入的噪声,同时更合理融合多分类器协同检测分类,提升了视频语义检测的准确性。在未来的工作中,可考虑引入基于深度学习的视频特征与半监督分类器集成学习相结合的方法,实现更有效的视频语义概念检测。
参考文献
[1] UEKI K, KOBAYASHI T. Object detection oriented feature pooling for video semantic indexing [C]// Proceedings of the 12th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications. Setúbal: SciTePress, 2017, 5: 44-51.
[2] KIKUCHI K, UEKI K, OGAWA T, et al. Video semantic indexing using object detection-derived features [C]// Proceedings of the 24th European Signal Processing Conference. Piscataway, NJ: IEEE, 2016: 1288-1292.
[3] QUEMY A, JAMROG K, JANISZEWSKI M. Unsupervised video semantic partitioning using IBM Watson and topic modelling [C]// Proceedings of the Workshops of the EDBT/ICDT 2018 Joint Conference. Piscataway, NJ: IEEE, 2018: 44-49. Proceedings of the 2018 Workshops of the International Conference on Extending Database Technology and the International Conference on Database Theory. Vienna: CEUR-WS, 2018, 2083: 44-49.
[4] SHELHAMER E, RAKELLY K, HOFFMAN J, et al. Clockwork convnets for video semantic segmentation [C]// Proceedings of the 14th European Conference on Computer Vision, LNCS 9915. Berlin: Springer, 2016: 852-868.
[5] BULL L, WORDEN K, MANSON G, et al. Active learning for semi-supervised structural health monitoring [J]. Journal of Sound and Vibration, 2018, 437: 373-388.
[6] ZHOU Z-H. Ensemble Methods: Foundations and Algorithms [M]. 1st ed. Boca Raton, FL: Chapman & Hall, 2012: 47-66.
[7] JANG W D, KIM C-S. Semi-supervised video object segmentation using multiple random walkers [C]// Proceedings of the 27th British Machine Vision Conference. Guildford, UK: BMVA Press, 2016: 57.1-57.13. http://www.bmva.org/bmvc/2016/papers/paper057/index.html
[8] KUMAR V, NAMBOODIRI A, JAWAHAR C V. Semi-supervised annotation of faces in image collection [J]. Signal, Image and Video Processing, 2018, 12(1): 141-149.
[9] 景陳勇,詹永照,姜震.基于混合式协同训练的人体动作识别算法研究[J].计算机科学,2017,44(7):275-278. (JING C Y, ZHAN Y Z, JIANG Z. Research on action recognition algorithm based on hybrid cooperative training [J]. Computer Science, 2017, 44(7): 275-278.)
[10] WANG X, SONG H, CUI H. Pedestrian abnormal event detection based on multi-feature fusion in traffic video [J]. Optik, 2018, 154: 22-32.
[11] LI P, WANG H. Video semantic classification based on ELM and multi-features fusion [C]// Proceedings of the 2014 International Conference on Network Security and Communication Engineering. Leiden: CRC Press, 2015: 305-308. NSCE 2014
[12] 严云洋, 杜静, 高尚兵, 等. 融合多特征的视频火焰检测[J]. 计算机辅助设计与图形学学报, 2015, 27(3): 433-440. (YAN Y Y, DU J, GAO S B, et al. Video flame detection based on fusion of multi-feature [J]. Journal of Computer-Aded Design & Computer Graphics, 2015, 27(3): 433-440.)
[13] 蒋鹏, 秦小麟. 一种基于多特征的视频人物聚类方法[J].计算机科学,2008,35(5):240-242,245. (JIANG P, QIN X L. Automated person indexing in video [J]. Computer Science, 2008, 35(5): 240-242, 245.)
[14] 陈芬,赖茂生.多特征视频分类挖掘实验研究[J].现代图书情报技术,2012,28(5):76-80. (CHEN F, LAI M S. Video classification using multiple features [J]. New Technology of Library and Information Service, 2012, 28 (5): 76-80.)
[15] MARTN R, MARTNEZ J M. A semi-supervised system for players detection and tracking in multi-camera soccer videos [J]. Multimedia Tools & Applications, 2014, 73(3): 1617-1642.
[16] ZHAN Y, SUN J, NIU D, et al. A semi-supervised incremental learning method based on adaptive probabilistic hypergraph for video semantic detection [J]. Multimedia Tools & Applications, 2015, 74(15): 5513-5531.
[17] MISRA I, SHRIVASTAVA A, HEBERT M. Watch and learn: semi-supervised learning of object detectors from videos [C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2015: 3593-3602.
[18] YANG Y, CHEN S. Ensemble learning from imbalanced data set for video event detection [C]// Proceedings of the 16th IEEE International Conference on Information Reuse and Integration. Piscataway, NJ: IEEE, 2015: 82-89.
[19] MITREA C A, CARATA S, IONESCU B, et al. Ensemble-based learning using few training samples for video surveillance scenarios [C]// Proceedings of the 5th International Conference on Image Processing, Theory, Tools and Applications. Piscataway, NJ: IEEE, 2015: 93-98.
[20] SHI W, JIANG M. Face recognition based on multi-view: ensemble learning [C]// Proceedings of the 1st Chinese Conference on Pattern Recognition and Computer Vision, LNCS 11258. Cham: Springer, 2018: 127-136.
[21] ZHANG Y, HUANG Q, MA X, et al. Using multi-features and ensemble learning method for imbalanced malware classification [C]// Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA. Piscataway, NJ: IEEE, 2016: 965-973. 15th IEEE International Conference on Trust, Security and Privacy in Computing and Communications
[22] ALBUKHANAJER W A, JIN Y, BRIFFA J A. Classifier ensembles for image identification using multi-objective Pareto features [J]. Neurocomputing, 2017, 238: 316-327.
[23] REDDY K K, SHAH M. Recognizing 50 human action categories of web videos [J]. Machine Vision and Applications, 2013, 24(5): 971-981.
[24] LIU D, SHYU M, ZHAO G. Spatial-temporal motion information integration for action detection and recognition in non-static background [C]// Proceedings of the 14th International Conference on Information Reuse and Integration. Washington, DC: IEEE Computer Society, 2013: 626-633.
[25] EVERTS I, GEMERT J C van, GEVERS T. Evaluation of color STIPs for human action recognition [C]// Proceedings of the 26th IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 2850-2857.
