基于模式匹配的企业关系图谱构建
2019-09-12岳浩然胡成凤袁君伟
岳浩然 胡成凤 袁君伟
摘 要:本文研究的企业关系图谱是图谱技术在商业领域的应用,通过从互联网获取企业相关信息,构建企业法人实体,匹配出实体关系,再通过关系图谱在系统中查询展示,探讨关系抽取方法。
关键词:关系图谱;实体关系;模式匹配
中图分类号:TP391.1文献标识码:A文章编号:1008-4428(2019)07-0033-02
一、 引言
在当今“互联网+”大数据时代,经营决策一方面靠经营者的经验与直觉,另一方面日益取决于数据分析。随着信贷领域“用户画像”的成功应用,互联网前沿技术的运用加强了金融风险的严密把控,推动了资本市场进行颠覆性的创新。
近年来各地工商、市场监管部门利用互联网构建了各自的业务系统,企业基本信息可以在互联网上直接查询,但是这些由不同软件厂商开发的业务系统相互独立,存储方式没有统一的标准,处于“数据散、查询统计难、数据展现不直观、利用率不高”的困难局面。在考查企业之间关联信息、关联关系时,难以便捷地查询到企业的组成结构和资产状况。这需要归集处理分散、异构、多源的数据,有效地整合、集成各省市工商行政管理部门不同数据库平台之间的企业信息。结合企业信息检索领域业务需求,在信息抽取、数据融合、信息加工等方面开展面向查询业务的企业关系图谱研究,利用计算机软件技术让用户方便、透明地使用工商部门提供的企业基础数据,实现多源数据的互联互通,对基础数据的融合和应用具有实用价值。
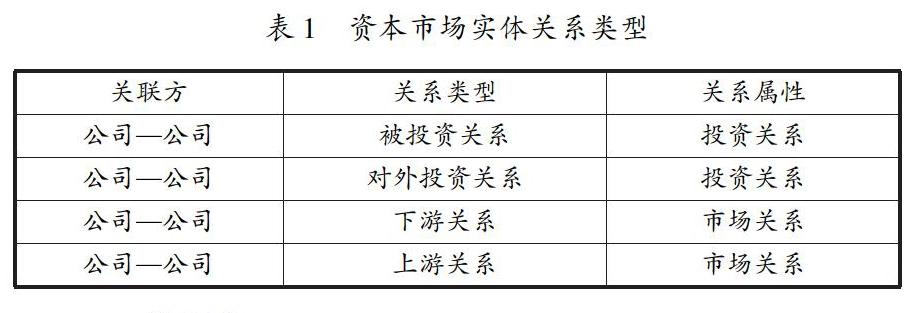
二、 实体关系类型
为了对资本市场之间建立关系图谱模型需要获取实体间的关系。在资本市场的实体关系可分为投资关系和业务关系,投资关系又可分为对外投资关系与被投资关系,业务关系可分为上游关系和下游关系。
根据资本市场领域特点,定义实体关系类型如表1所示。其中关系属性表示该种关系类型的效用范围。本文主要研究的是投资关系和市场关系,在资本市场里,企业不是单独存在的个体,必然存在着接受投资或者对外投资,这种投资有直接的也有间接的。市场关系是指供应商与客户作为买卖双方的关系,企业在持续经营过程中同时扮演着供应商与客户的角色。通过投资关系和市场关系可以对企业作出详细的刻画,从而了解该企业在资本市场中的现状。
三、 数据集
(一)基础数据的抽取
本文构建了一套爬虫系统,通过编写正则表达式来获取网页中我们需要的数据。以政府提供的企业法人数据集为基础,构建爬虫系统融合百度百科数据集,完成企业法人本体的构建,为企业法人关系图谱提供统一的模式层。
(二)数据集的分析
对已有的政府结构化数据集、百科数据集进行整体分析,结合知识图谱面向的特定人群以及需要解决的相关问题。对本文要研究的领域概念或属性进行抽取,将抽取到的概念或属性之间的语义关联表示为三元组的结构,例如(公司A,持有股票,公司B),此三元组通过持有股票这一语义关联将公司A和公司B的关系描述出来。
四、 实体关系获取方案
(一)关系提取方案
如何从大量的结构化数据和非结构化数据中抽取出我们所需要的关系,是本文研究的一个重点。对于结构化数据,由于本身就是规范的结构,所以抽取方法较为简单,此处不再赘述。对于非结构化数据,我们采用半监督学习的方法。半监督学习已经成为实体关系抽取中应用最广泛的方法,其标志为自训练。从一个较小的数据集开始,标注出其中的关系实例,这些关系实例被称为种子。如:2015年4月19日,北京京东投资北京高梓行远科技有限公司620万人民币。可标注为“北京京东 投资 北京高梓行远科技有限公司”,以此为种子。再从“种子”提取模版。通过模版在非“种子”语料中提取新的实体关系实例,并将这实例作为新的种子。不断循环,直到循环终止条件达成,抽取出大量的实例关系。
(二)企业名称识别
“北京京东”“北京高梓行远科技有限公司”这种名字的识别国内外都已经有了大量的研究工作,尤其在地名和人名的识别方面,而在机构名的识别方面相对较少,涉及中文机构名识别的更少。机构名是命名实体(Named Entities)七种类型之一,一般采用模式匹配进行识别。“北京京东”的模式为“地名+企业名”相对较短较易识别,我们准备了大约五十万个“地名+企業名关键字+公司”模式的企业名,经过分词后取2gram存储记录下来。在实际识别时也先分词,遇到“公司”后向左逐个查询存储的2gram记录,直到向左遇到地名为止,这时推断从地名到“公司”这一串文字为企业名,中途如果没查到2gram记录也立即停止。
上述识别策略模拟了图灵机“走纸带”的过程,也是图灵完备的。该识别策略综合考虑了企业名的结构特征和文本上下文信息,识别结果达到了令人满意的86%的正确率。
(三)实体关系的模式匹配
识别出企业名后,将企业名在抓取到的文本里搜索,检索获取“A投资B”模式的信息。搜索引擎我们采用布隆过滤器的算法构建,布隆过滤器是一个m位的数组,初始化时全部设置为0。构建索引时定义使用k个不同的哈希函数,每个哈希函数将某个集合元素映射或哈希到数组m的一个位置,形成一个统一的随机分布。其中k是一个比m小得多的常数,与要添加的元素数成正比;k的精确选择和m的比例常数由过滤器的既定错误率决定。构建索引的步骤包括:
1. 当添加元素时,计算该元素哈希值,获取在数组中的位置,并将所有这些位都设置为1。
2. 当查询一个元素(测试它是否在集合中)时,计算该元素哈希值,获取在数组中的位置。如果这些位置的任一位为0,则该元素肯定不在集合中;如果是,则插入时所有位都将设置为1。如果所有元素都是1,要么元素在集合中,要么在插入其他元素的过程中位偶然被设置为1,这容易导致误报。简单的Bloom过滤器无法区分这两种情况,使用较新的技术可以解决这个问题。
检索模式文本采用BM25算法。BM25是一种用来评价搜索词和文档之间相关性的算法,它是一种基于概率检索模型提出的算法:一个query和一批文档Ds,现在要计算query和每篇文档D之间的相关性分数,先对query进行切分,得到单词q(i),单词的分数由3部分组成:单词q(i)和D之间的相关性、单词q(j)和query之间的相关性;每个单词的权重。最后对每个单词的分数求和,得到query和文档之间的相关分数。
五、 结论
企业关系图谱面向资本市场的参与实体即企业与人物,设计构建了关系图谱模型,从分散、冗余、低价值密度的多源异构数据提取出结构化的实体及关系信息,并且设计实现了包括关系图谱在内的信息系统,为证券交易所等机构对资本市场投资、监管、调查等业务提供了支持。
参考文献:
[1]金贵阳,吕福在,项占琴.基于知识图谱和语义网技术的企业信息集成方法[J].东南大学学报(自然科学版),2014,44(2):250-255.
[2]李涛,王次臣,李华康.知识图谱的发展与构建[J].南京理工大学学报,2017,41(1):22-34.
[3]王宁,葛瑞芳,苑春法,等.中文金融新闻中公司名的识别[J].中文信息学报,2002(2):1-6.
作者简介:
岳浩然,男,安徽马鞍山人,宿州学院商学院学生,研究方向:会计学;
胡成凤,女,安徽六安人,宿州学院商学院学生,研究方向:财务管理;
袁君伟,男,安徽合肥人,宿州学院商学院学生,研究方向:会计学。
