城市轨道交通线路的CPU/GPU协同快速建模方法
2019-09-09魏庆朝吕希奎
李 鸣,魏庆朝,吕希奎
城市轨道交通线路的CPU/GPU协同快速建模方法
李 鸣1,魏庆朝1,吕希奎2
(1. 北京交通大学土木建筑工程学院,北京 100044;2. 石家庄铁道大学交通运输学院,河北 石家庄 050043)
城市轨道交通线路三维可视化设计能有效地改进设计质量。针对传统基于CPU的线路三维建模方法存在着建模速度慢、等待设计成果时间长、渲染效率低、场景优化困难等问题,提出一种基于CPU离散-GPU建模的城市轨道交通线路三维模型快速建模方法。首先,将线路分为线状模型和点状模型,然后根据线形设计成果利用CPU分解线状模型得到离散化的边界条件,解析点状模型得到空间信息参数,分别形成独立的、数据量极小的离散数据包;然后利用GPU的并行计算能力通过离散数据包实现线路三维模型的快速建立;联合CPU的场景拣选能力和GPU的顶点扩展能力,建立了一种用于长线状模型显示的场景优化方法。研究结果显示:①该方法建模耗时仅为传统方法的0.55%~1.30%;②浏览体验相比基于传统CPU建模和场景管理的方法显著提升,最小帧数在70帧以上;③可有效降低内存及CPU占用率等性能指标,释放设计平台计算压力;④为线路三维可视化设计实用化提供了一种可借鉴的方法和思路。
城市轨道交通;线路设计;三维线路建模;快速建模
三维可视化设计在减少设计冲突、提高设计质量和效率方面具有显著的作用,目前已成为城市轨道交通线路信息化设计的主要发展趋势。很多学者进行了有益的探索,如王明生[1]采用面向对象的图形仿真建模技术,实现线路路基、隧道和桥梁各部分的三维建模;吕永来和李晓莉[2]完成了单线和双线的线路建模;文献[3-5]研究了用于线路设计的三维城市景观的建模方法。上述研究均利用CPU实现线路三维及景观的建模,但城市轨道交通线路海量的数据和CPU串行计算的特点,使得单纯利用CPU进行建模存在以下问题:
(1) 建模速度较慢,特别是较长线路建模时更为明显[6],无法达到二维设计平台中所绘即所得的高效率。特别是线路设计变更频繁时,每次变更均需要长时间的等待,效率过于低下。
(2) 渲染效率低,场景优化困难,传统的CPU动态调度算法难以满足线状模型的渲染优化要求。
(3) 计算资源消耗多[7],内存占用大。海量的三维模型数据占用了大量的CPU、内存和硬盘资源,使得设计平台的计算资源余量较少,难以付出更多的资源参与到与设计相关的逻辑计算中去,造成平台的设计效率低下。
上述问题是制约目前轨道交通线路三维设计实用化的主要瓶颈。而随着现代硬件GPU技术的飞速发展,其几何扩展能力、并行计算能力愈发强大。针对线路模型的标准化、结构化的特征,本文结合CPU与GPU运算的特点,将传统的基于CPU的线路三维建模过程合理分配至CPU及GPU中。通过以下几个方面解决传统CPU在线路三维设计中存在的关键问题:
(1) CPU-GPU协同的线路三维建模。根据轨道线路模型特点及GPU并行计算机制,设计出一种“CPU离散-GPU建模”的线路模型绘制的算法:CPU进行线路中线的离散化操作,计算离散中线的边界条件、部件空间位置姿态等数据,且向GPU传送极为简单的离散化属性数据包。GPU利用离散化数据与各个核心同步、并行地创建离散模型并组合,从而实现模型的快速实时绘制。
(2) 基于GPU的线状模型渲染优化。利用GPU的顶点扩充、裁剪能力,根据视点与模型的空间关系,实现同一绘制批次下模型的非一致性LOD模型表达,在保证模型显示精度的情况下,提高渲染效率。
(3) 大规模数据的管理能力。生成模型的过程中,CPU及内存只需管理及保存极少的线路属性数据,所以有着充足的数据管理余量及计算资源余量参与至设计平台的其他过程中去,对提高设计平台的效率有着重要意义。对设计成果也只需保存原始的设计数据即可,有效地节约了存储资源,并且有极快的重载速度。
1 CPU-GPU三维模型建模流程对比与分析
传统线路模型CPU建模方法的流程如图1(a)所示。大量的建模工作均由不擅长并行计算的CPU进行,且CPU需要向GPU传递全部可视的模型数据,造成CPU建模速度慢、占用率高,形成前文所述的问题,制约着轨道交通线路三维设计的实用化。
考虑到线路模型具有高度参数化的特征,线路的组成结构层次分明,组件间的约束关系清晰,易于使用函数语言表达。基于线路模型特征及几何构成特点,本文将整个建模过程分为:CPU离散和GPU建模2个部分。如图1(b)所示,CPU承担逻辑串行计算:包括计算线路中线的空间曲线参数、对线路中线进行离散化操作、离散中线的边界条件计算等工作;利用GPU的并行计算能力,将原本通过CPU完成的高强度建模计算全部移交至GPU完成:包括由顶点着色器进行场景管理、由几何着色器进行线路模型的顶点计算、三角网化,CPU与GPU间只需传递少量的离散曲线数据。该建模方法,充分利用了CPU、GPU各自的优势,有效地提高了建模效率。
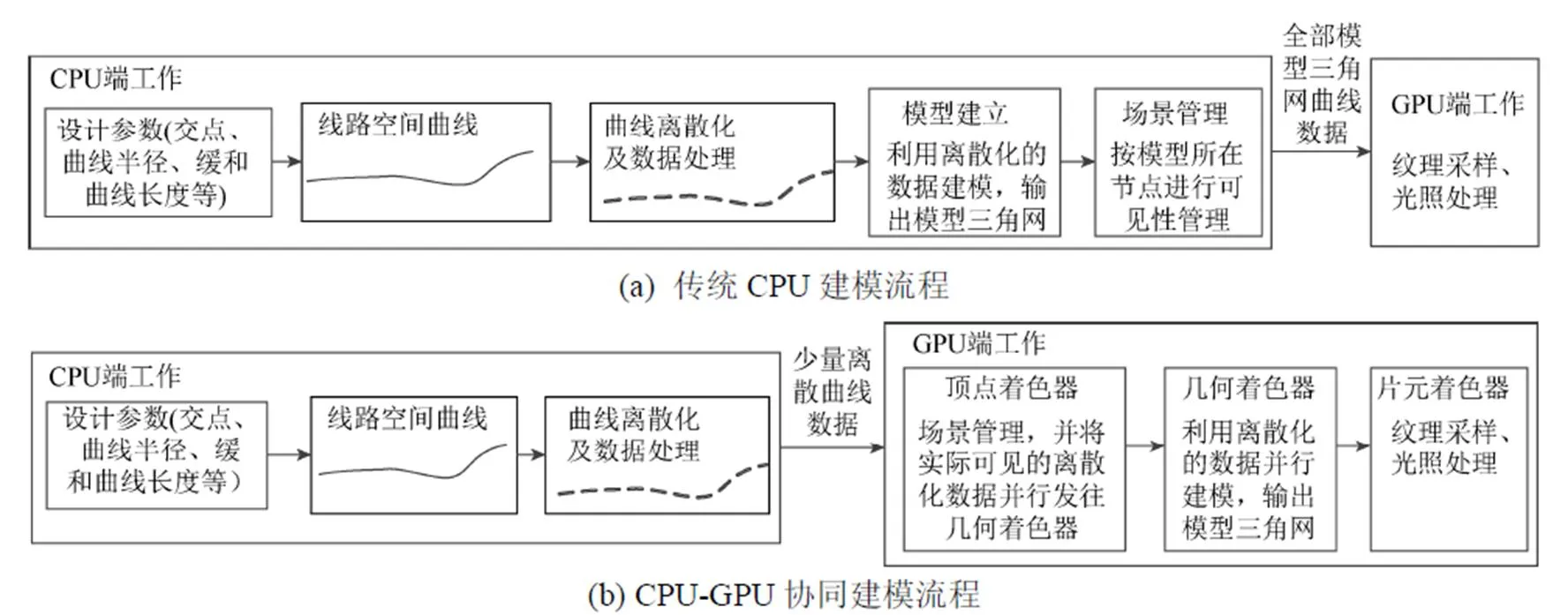
图1 协同建模流程及对比
2 CPU线路模型数据处理
利用CPU的串行数据处理能力,完成线路模型原始数据处理,为GPU提供建模数据,包括2部分内容:
(1) 合理分解线状模型,用一定长度的直线拟合原线路中线,形成离散中线集合,然后通过离散中线的前后几何关系,得到每一条离散中线的边界约束条件及里程信息。通过CPU的计算处理后,将离散化中线的端点坐标、边界约束条件、里程等信息顺序传递至GPU各个核心,为GPU提供并行计算的数据集合。流程如图2所示。
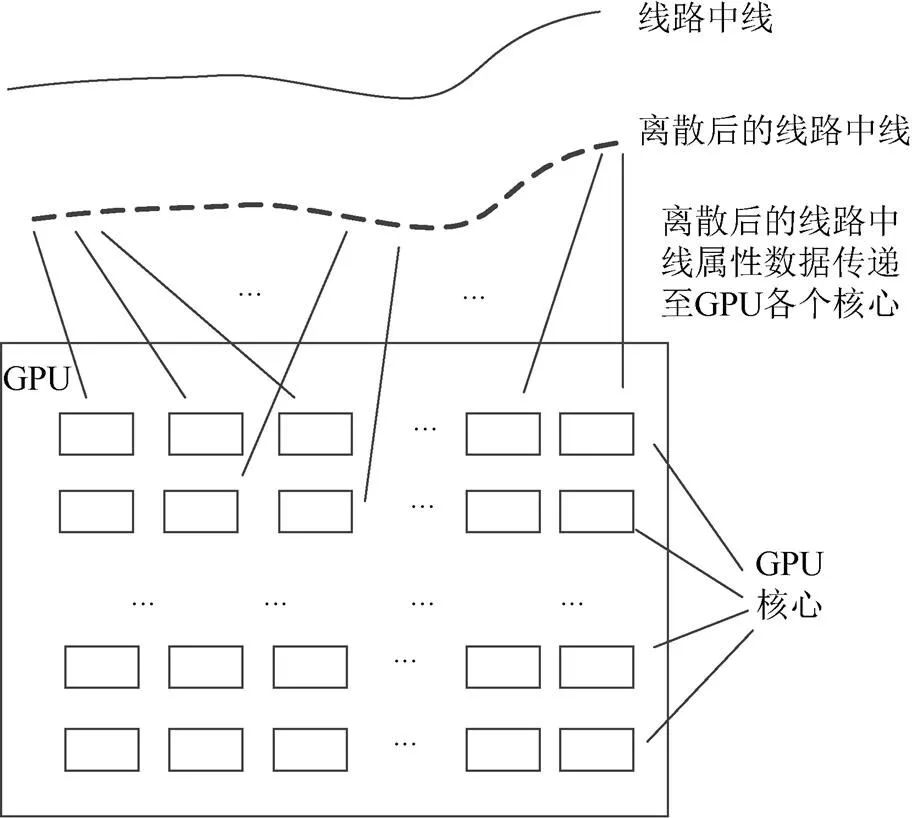
图2 CPU的独立性计算流程示意图
(2) 解析点状实体模型的三维数据,发送至GPU缓存中,同时计算插入点及空间角度参数,确保GPU能正确绘制模型。
2.1 基于特征点识别的线路中线离散化

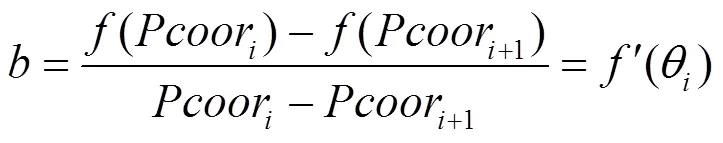
离散结果如图3所示,直线部分由于没有局部特征点,保持原样,而曲线部分被离散为若干个小段。
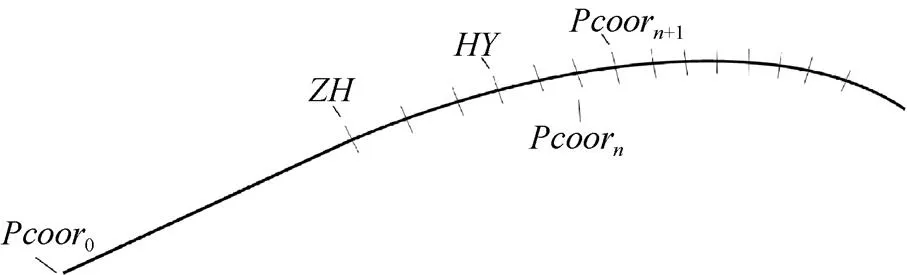
图3 线路中线的离散化
2.2 边界条件的确定
线状模型在曲率变化处存在模型失真的问题,按2.1节计算结果及横截面数据直接创建分段模型,在模型拼接处曲线的内侧会出现模型重叠、外侧出现模型空隙,如图4所示。由于建模工作均提交至GPU,考虑到各个核心并行计算时的独立性,因此,需设置一个边界条件,确保GPU各核心在创建模型时,满足模型拼接处0阶参数的连续性0[10](拼接面处坐标点相同),以及拼接面上各点至离散中线的距离恒定的条件(模型几何外观不变),如图5所示。

图4 线路模型拼接图
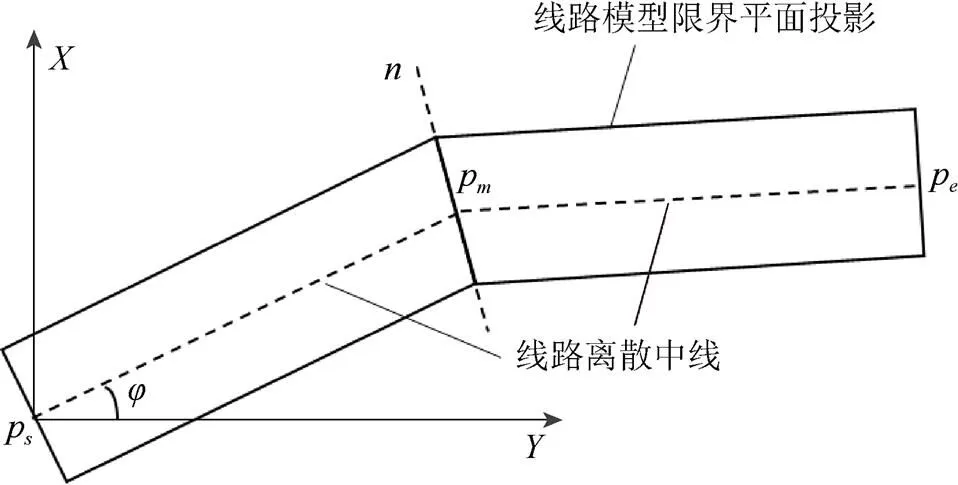
图5 边界条件图
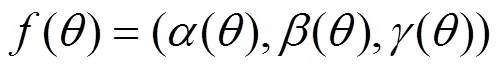
3 GPU三维建模的实现
接受离散化数据后,由GPU中的顶点着色器将每一对(p,p)坐标,以及p和p处的拼接面法向量通过数组VS_OUT传递至几何着色器:
几何着色器及片元着色器共同完成建模:利用几何着色器的几何扩展及裁剪能力,根据(p,p)处的坐标与法向量完成线路模型的顶点网格数据计算及场景管理;利用片元着色器对模型的纹理、光照进行渲染模型并在屏幕上显示。
3.1 几何着色器建模
本文主要利用了几何着色器的2个功能,一是几何顶点计算输出能力,几何着色器可根据输入参数扩展生成出更丰富的图形细节,如输入一条线路的中线,可根据预定义的钢轨、排水沟及隧道面等构件与中线的相对坐标关系扩展出上述模型的三角网,并用于扫掠体模型的建模;也可读取GPU缓存中的顶点数据,实现对实体模型顶点的空间变换计算及顶点输出。二是几何顶点的裁剪能力,依据一定的规则计算,采用不同等级的顶点输出策略,减少顶点的计算及输出,实现GPU的场景管理,进一步提高运行效率。
3.1.1 模型的创建
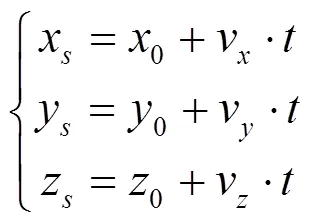
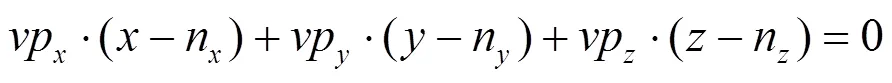
联立式(1)和式(2),有

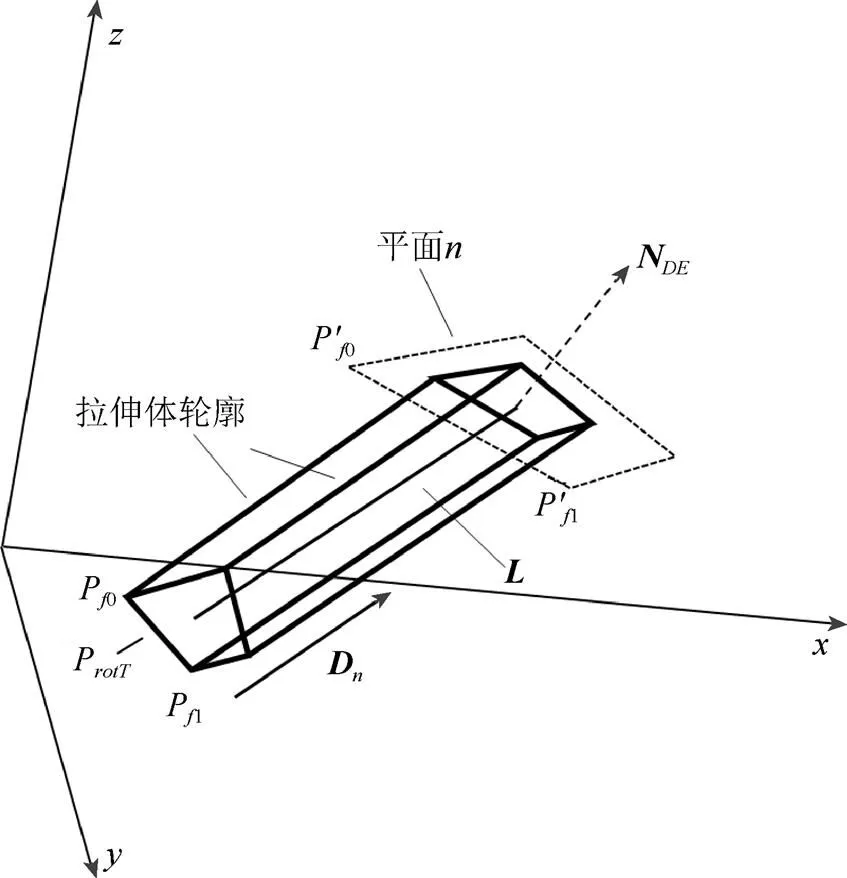
图6 轮廓扫掠及裁剪图
//设置接受的数据为离散的线段
layout (lines) in;
//设置输出的数据为三角网带
layout (triangle_strip, max_vertices = 500) out;
void creatModel(vec4 insertPt)//传递模型的插入点

gl_Position=StretchTemplate(pfi[],0)// StretchTemplate为空间转换矩阵,0表示计算起点处的轮廓点。
gl_Position=StretchTemplate(pfi[],1)// StretchTemplate为空间转换矩阵,1表示计算终点处的轮廓点。
}
EndPrimitive();//完成该模型的建模
}
3.1.2 CPU-GPU联合场景渲染优化
在传统CPU建模方式中,往往使用层次空间包围盒及可见性剔除算法,如八叉树或KD-tree进行场景管理,以优化显示效率。这些算法根据场景节点的可见性、距视点的距离控制模型的显示精度,但该场景管理方式在优化线状模型的管理上存在弊端:线状的轨道交通线路模型往往只有少量的路段出现在视锥体内,而CPU建模的方式难以分段控制同一绘制批次内线路模型的绘制等级,在同一个场景节点中,模型的绘制精度是相同的。如图7所示,当线路模型走向与视线几乎相同时,采用CPU建模方法时,同一绘制批次内远离及贴近视点的模型均只能采用同一精度的模型,造成远离视点处的模型仍采用高精度绘制,无法有效降低绘制量及系统负担。
考虑到线路模型的线状特征与GPU建模的单体控制能力,本文的建模方法在场景管理上设计了2个场景的优化策略。由CPU进行模型整体的可见性剔除,通过其将剔除后的数据提交至GPU,并利用高效的并行计算能力进行个体模型的绘制精度控制。与传统的CPU对整个节点的渲染优化过程相比,本文方法在保证模型细节效果的前提下,有效降低了模型绘制量,提高了系统的渲染效率,优化过程如下:
(1) 由CPU对线路模型进行可见性剔除。首先,在每条线路CPU解析的过程中,根据设计资料JD (交点)的数据,为模型创建OBB包围盒。当视锥体包含该OBB包围盒时,保留该模型并传递至GPU顶点着色器,否则剔除该模型。
(2) 由GPU顶点着色器对视锥体内模型的各个组成构件进行独立的可见性判断,依据视距距离评定构件的绘制精度,向几何着色器输出相应的绘制等级数据。几何着色器根据该数据选择绘制模型的精度,或者不绘制,以达到优化的目的。优化方法按模型的绘制方式分2种:
方法1,扫掠体的优化。以视点到扫掠线的最短距离作为判断距离。采用隔点法或分裂法(道格拉斯·皮尤克算法[12])对扫掠体的轮廓面进行简化、甚至取消,达到减少绘制量的目的。
方法2,点状实体的简化。以视点至插入点的距离作为判断距离。采用顶点聚类算法[13]对点状实体进行简化,由于该简化算法较为复杂,不适合在几何着色器内使用。本文在建模之前使用一个计算着色器完成点状实体的分级简化工作,分级的简化结果保存至着色器顶点缓存数组中。由几何着色器根据判断距离读取顶点并输出。
本优化方法应用在线状模型上取得了良好的渲染优化效果,如图7所示。同一绘制批次的轨枕(扫掠体)及扣件(点状实体),根据与视点距离的关系,模型精度由近及远逐步降低,直至取消不再显示,既保证了视觉体验,也提高了运行效率。
图7 轨枕、扣件的分等级绘制
3.2 基于GPU视点光线的真实感渲染
片元着色器负责渲染模型并向屏幕输出。几何着色器向片元着色器输出构成模型的三角网数据,包括三角网的顶点坐标、各顶点的法向量及三角形的纹理坐标。在该阶段,片元着色器为组成模型的各个三角形贴上适当的纹理,完善模型渲染细节,如图8所示。

图8 纹理效果图
光照能提高模型的立体感及视觉效果。线路设计往往处于大场景的条件下,单一光源无法有效覆盖、凸显模型的局部细节。本文采用视点光源的方式,由CPU传递视点坐标的uniform (统一值)至片元着色器,始终绑定光源及视点位置,使得观察者能有良好的视觉效果。图9为定点光源与视点光源作用在扣件及轨枕的对比图。

图9 光照效果对比图
4 实验对比分析
在Windows 10平台下,利用OSG 3.4.5平台和GSLS 4.3着色器版本编制了算法的验证程序,测试计算机的CPU为i7-4800HQ,显卡为GTX 960m。验证程序创建了隧道和桥梁线路模型,运行效果如图10所示。整个运行过程流畅,画面精细度高,模型的各个部件可根据视点距离灵活地切换显示精度。

图10 建模效果图
与CPU建模的测试对比数据见表1。

表1 本文方法与CPU建模测试对比
由表1可知,本文GPU建模方法在建模速度上相比传统的CPU建模有着较大的优势,且随着绘制长度的增加,GPU绘制增加的时间很少,而CPU绘制的时间与里程有着相对应的比例关系,增加幅度很大。如三角形从3 200万增加至10 000万时,GPU用时只增加了1.1 s,而CPU则增加了623 s。在绘制相同的三角形个数时,GPU用时约为CPU的0.55%~1.30%,显示出本文算法的极大优势和绘制效率。究其上述差距原因在于,本文方法在CPU端并不实际创建三角形,只进行线路模型的离散化计算,并将离散数据包直接传递至GPU,一旦传递结束,GPU即实时创建与画面相关的三角形。离散化计算的耗时很小,其中大部分的时间是在进行数据变量的初始化工作,随着长度的增加,GPU建模绘制增加的时间很少。而传统的CPU建模方式,需要由CPU进行所有的三角形创建,并存入内存,时间及内存消耗均很大,CPU负担很重。
在CPU占用率方面,由于本文方法只需管理少量的离散化数据,其占用率仅为15%;而传统的CPU建模方式占用率最高可达73%。由此可知,本文方法极大地解放了CPU及内存的资源。
最小帧数决定着使用者的最终体验,随着线路的增长,数据量的增多,CPU建模方式下降幅度达到了34%,且12帧的帧数已无法提供流畅的体验;而本文方法仅下降了3%,且帧数一直维持在流畅的程度,显示了本文方法中场景管理的有效性。
在设计成果的存储方面,本文方法只需要保存原始的如JD,曲线半径等线路参数数据,大小仅为几百kB,而CPU建模方法则需要保存各级别LOD模型,大小可达3 G。
5 结束语
本文针对传统的CPU线路三维建模方法存在的数据占用空间大、建模速度慢、场景渲染效率低等不足,利用GPU高效并行的运行机制,研究了CPU-GPU协同的城市轨道交通线路三维快速建模方法。实现了线路数据在CPU端的离散化处理,在GPU端的线路三维模型快速建立、渲染优化和场景管理。经过实例验证,较传统CPU的建模方法,本文方法在建模速度、运行效率、渲染优化、节约存储空间等方面都具有极大的优势,也为城市轨道交通线路三维可视化设计实用化提供了一种可借鉴的方法和思路。
[1] 王明生. 城轨线路三维可视化设计基础理论和方法[D].北京: 北京交通大学, 2013.
[2] 吕永来, 李晓莉. 基于CityEngine平台的高速铁路建模方法的研究与实现[J]. 测绘, 2013, 36(1): 19-22.
[3] 吕希奎, 王明生, 李鸣, 等. 城市轨道交通三维城市景观快速建模方法研究[J]. 城市轨道交通研究, 2013, 16(9): 43-46.
[4] 何彬. 基于GIS的城市轨道交通三维空间选线系统研究[D]. 石家庄: 石家庄铁道大学, 2015.
[5] 李鸣. 城市轨道交通线路设计三维地理环境建模方法与应用研究[D]. 石家庄: 石家庄铁道大学, 2013.
[6] 朱颖, 闵世平, 代强玲. 面向铁路行业三维场景快速构建一体化技术研究[J]. 铁道工程学报, 2011, 28(12): 4-10.
[7] WOLFF D. OpenGL 4 shading language cookbook [M]. 2nd ed. Birmingham: Packt Publishing, 2013: 215-219.
[8] 刘丹丹, 张树有, 刘元开, 等. 一种基于特征点识别的曲线离散化方法[J]. 中国图象图形学报, 2004, 9(6): 755-759.
[9] 魏庆朝. 铁路线路设计[M]. 2版. 北京: 中国铁道出版社, 2016: 198-200.
[10] 施法中. 计算机辅助几何设计与非均匀有理B样条[M]. 北京: 高等教育出版社, 2001: 75-76.
[11] 陈维桓. 微分几何初步[M]. 北京: 北京大学出版社, 1990: 18-30.
[12] 于靖, 陈刚, 张笑, 等. 面向自然岸线抽稀的改进道格拉斯—普克算法[J]. 测绘科学, 2015, 40(4): 23-27, 33.
[13] 魏子衿, 肖丽. 改进顶点聚类方法的并行核外模型简化算法[J]. 计算机工程与应用, 2018, 54(13): 181-190, 215.
A Fast CPU/GPU Cooperative Modeling Method of Urban Rail Transport Lines
LI Ming1, WEI Qing-chao1, LV Xi-kui2
(1. School of Civil Engineering, Beijing Jiaotong University, Beijing 100044, China; 2. School of Traffic and Transportation Engineering, Shijiazhuang Tiedao University, Shijiazhuang Hebei 050043, China)
Three-dimensional (3D) visualization can greatly improve the quality and efficiency of urban rail lines design. However, the traditional CPU-based method of 3D modeling have some problems in modeling speed, render efficiency, optimization scene, which require to be improved urgently. A fast 3D modeling method of urban rail transport lines based on CPU discrete-GPU modeling is proposed. Firstly, the line is divided into linear models and point models, and then, according to the results of line design, CPU is used to decompose linear models to obtain dataset of discrete boundary conditions. Subsequently, the point models are analysed to obtain dataset of spatial information parameters which can form, independent discrete data packets with a small amount of data respectively. Finally, with these discrete data packets, the fast modeling of 3D line model is achieved owing to the parallel computing ability of GPU. Combining the scene picking ability of CPU with the vertex expansion ability of GPU, a kind of scene optimization method that applies to long linear model display is established. The results show that ① The time-consumed by this method is only 0.55%–1.30% of the time using traditional CPU-based method. ②The proposed method is better than traditional CPU modeling method and scene management in browsing experience, minimum frames per second is higher than 70. ③The performance indicators such as occupancy of memory and CPU are greatly improved, which help to lessen the pressure of design platform.④It provides significant implications for the 3D design of practical urban rail transport lines.
urban rail transport; line design; 3D transport line modeling; fast modeling
U 212
10.11996/JG.j.2095-302X.2019040644
A
2095-302X(2019)04-0644-07
2019-01-02;
定稿日期:2019-04-29
国家自然科学基金项目(51278316),北京市自然科学基金项目(8172040)
李 鸣(1984-),男,广西柳州人,博士研究生。主要研究方向为铁路线路BIM设计。E-mail:81792534@qq.com
