基于SNP系统的改进粒子群聚类算法
2019-08-27李立
李 立
(安庆广播电视大学, 安徽 安庆 246003)
0 引 言
在众多的聚类分析算法中,K-means是基于划分的经典聚类算法,具有局部寻优能力强、聚类速度快和易于实现的优点,但该算法也存在聚类结果过于依赖初始聚类中心点、波动性大且易于陷入局部极值的缺点.对此,有学者提出了基于多种粒子群优化(Particle swarm optimization,PSO)的聚类算法[1-2],即将PSO算法的全局寻优能力和K-means算法的局部寻优能力相结合来改善聚类算法的性能,并取得了一定的效果.但是,PSO算法在实现优化时会出现早熟收敛现象,且具有较强的随机性,在实际应用中具有一定的局限性.针对该问题,有学者提出一种以生物细胞为原型的膜计算算法模型[3],其可将细胞区域划分成各自独立的计算单元,具有强大的计算能力.目前,脉冲神经膜(Spiking neural P,SNP)系统是基于神经型的膜计算模型,也是膜计算领域的研究热点之一[4-7].本研究在粒子群聚类算法中引入SNP系统,构建了一种基于SNP系统的改进PSO-KM模型,即SNPS-PK算法,其原理是将初始聚类中心的各种组合作为粒子,将其分配到若干个神经元,并在神经元中进行粒子群的迭代与进化,利用SNP系统的高并行性和PSO算法的全局寻优能力在更短的时间内得到更优化的初始聚类中心,为下一步K-means算法的局部寻优提供更好的聚类初值,以进一步提升聚类结果的稳定性和准确率.
1 概念及定义
1.1 PSO算法
PSO算法是一种仿生方法,粒子之间通过相互协作并不断迭代来生成最优解,其实现步骤如下:
假设含M个粒子的群体在一个N维空间进行搜索,粒子i(1≤i≤M)的位置、速度和历史最优位置分别用3个维向量来表示,Xi=(xi1,xi2,…,xiN),Vi=(vi1,vi2,…,viN)和Pbesti=(Pbesti1,Pbesti2,…,PbestiN).整个粒子群的全局最优位置可表示为,Gbest=(Gbesti1,Gbesti2,…,GbestiN).在迭代过程中,粒子更新速度和位置如式(1)与式(2)所示.
Vi(t+1)=ωVi(t)+c1r1(Pbesti-Xi)+
c2r2(Gbest-Xi)
(1)
Xi(t+1)=Xi(t)+Vi(t+1)
(2)
其中,ω为惯性权重,c1和c2为学习因子,r1和r2为随机权重.
1.2 K-means算法
K-means算法是一种基于质心的启发式聚类算法,其实现步骤如下:
1)在n个数据样本中随机选择k个Ci(i=1,2,…,k)作为初始聚类中心;
2)计算其他数据样本与初始聚类中心的距离,若数据样本Xj属于第i聚类,则其权重值wji=1,否则为0,如式(3)所示:
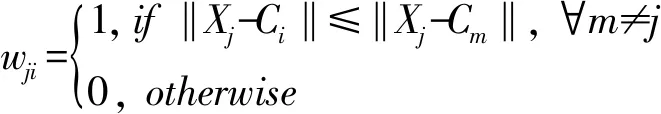
(3)
3)由式(4)计算目标函数J,若J值不变,则停止迭代,算法结束.否则,进入步骤4),
(4)
4)由式(5)更新聚类的中心点,回到步骤2).
(5)
1.3 SNP系统的定义
一个标准SNP系统的定义为,
Π=(O,σ1,σ2,…,σm,syn,in,out)
(6)
其中:
1)O={a}是脉冲a的集合.
2)σ1,σ2,…,σm是系统Π中所含的m(m≥1)个神经元,σi=(ni,Ri)(1≤i≤m),其中,ni表示σi中脉冲的初始值,而Ri表示两类规则的集合:
(1)激发规则.E/ac→a;d(c≥1,d≥0),E为a的正则表达式,d为时延.若神经元σi在某时刻有k个脉冲,且ak∈L(E)(k≥c),则利用规则E/ac→a激发,消耗c个脉冲,并在d步之后向相关神经元分别发送1个脉冲.
(2)遗忘规则.as→λ(s≥1),对Ri中的任意规则E/ac→a;d,都满足as∉L(E).若神经元σi在某时刻有且仅有s个脉冲,则利用规则as→λ,消耗掉所有的脉冲,且不会产生新的脉冲.
3)syn⊆{1,2,…,m}×{1,2,…,m}表示神经元之间的突触.其中,(i,j)∈syn,(1≤i,j≤m,i≠j).
4)σin和σout分别表示输入和输出神经元,其中,in,out∈[1,2,…,m].
2 基于SNP系统的改进粒子群聚类算法
本研究将SNP系统与PSO算法、K-means算法相结合,构建了一种基于SNP系统的改进PSO-KM模型的SNPS-PK算法,以进一步提升聚类结果的稳定性和准确率.
2.1 粒子群的适应度函数和编码方案
聚类分析时,PSO算法的适应度函数用来评价k个聚类中心的性能,其定义为,
(7)
其中,f(x)是粒子在位置x处的适应度值Zj(1≤j≤k),是类Cj的聚类中心,Xi是集群中的数据样本.粒子的f(x)可以衡量数据对象的结合程度,f(x)越小表示结合越紧密,聚类效果越好.
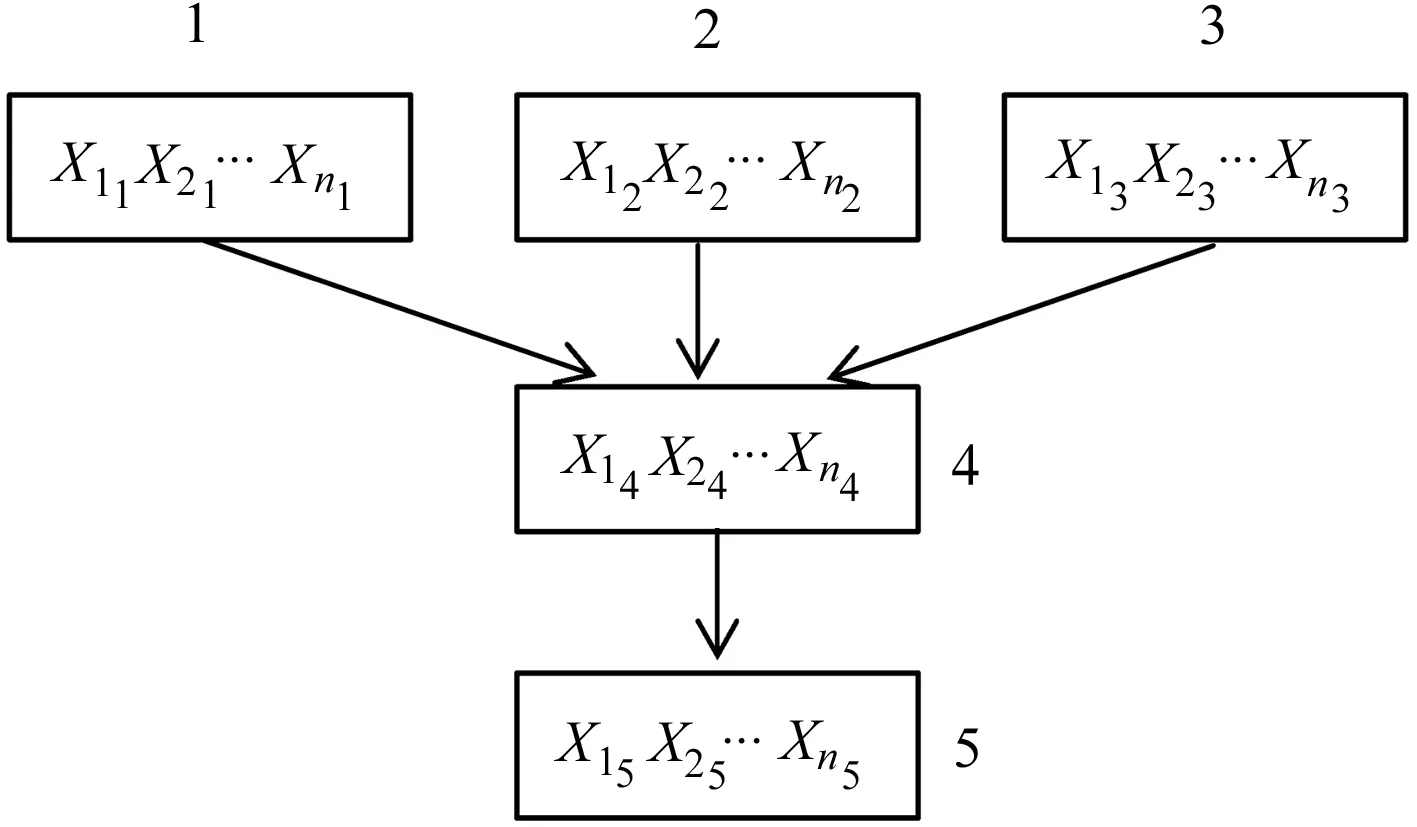
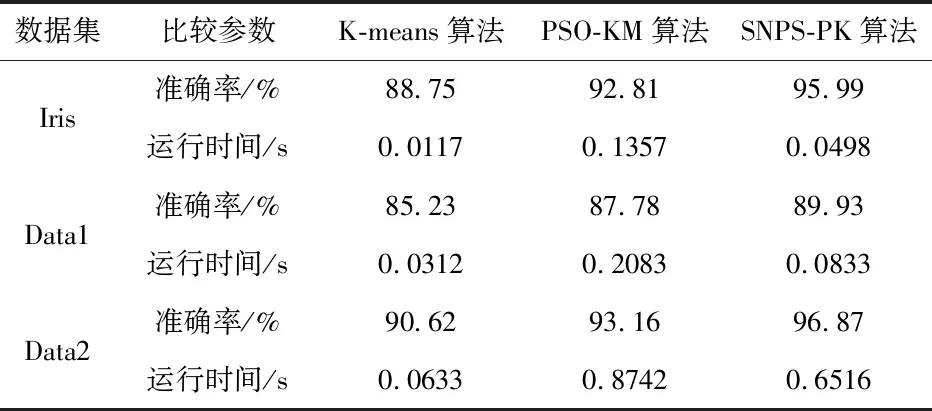
PSO算法的优化目标就是搜索到f(x)值最小的粒子位置,其对应的就是优化后的初始聚类中心.粒子i在第(t+1)次迭代时,如果f(xi(t+1)) 采用PSO算法对K-means算法的初始聚类中心优化前,k个聚类中心Zj(1≤j≤k)映射成集群中的粒子,其坐标向量组成了粒子在优化过程中的位置,而粒子i的适应度值为f(xi)(1≤i≤k).每个粒子代表某种可行解,粒子的编码由k个d维聚类中心中粒子的位置、速度和适应度值组成,其编码方案为, Z11…Z1dZ21…Z2dZk1…Zkd‖V11…V1dV21…V2dVk1…Vkd‖f(xi) 为了达到全局搜索和局部搜索之间的平衡,文献[1]给出了一种惯性权重ω随迭代次数的增加而线性下降的方法,其惯性权重ω的计算式为, ω(t)=ωmax-(ωmax-ωmin)t/ωmax (8) 其中,ωmax和ωmin分别是最大和最小惯性权重,t和tmax分别是当前迭代次数和最大迭代次数.ω的理想取值范围为0.4~0.9. 在实际计算中,为了避免“振荡”并让粒子加快收敛到最优解,可在式(2)中增加飞行时间因子,则式(2)变为, Xi(t+1)=Xi(t)+H0(1-t/tmax)Vi(t+1) (9) 其中,t和tmax分别是当前迭代次数和最大迭代次数.H0为1.5. 式(1)中,学习因子c1和c2分别调节向Pbest和Gbest方向飞行的最大步长,c1是粒子自身学习的权重系数,c2是粒子群体学习的权重系数.为了平衡随机因素的作用,一般情况下,c1=c2.而r1和r2被设置成介于[0,1]之间的随机数,目的在于增加粒子飞行的随机性. SNPS-PK算法的膜结构如图1所示.神经元内的对象不是脉冲,而是粒子对应的位置,即不断迭代的聚类中心. 图1中的神经元1、2和3为辅助神经元,神经元4为主神经元,神经元5为输出神经元.系统Π中辅助神经元粒子的主要功能是搜索可能存在最优解的领域并及时将搜索信息传回主神经元.辅助神经元1和3中的粒子按照式(1)和式(2)更新速度和位置,按照式(8)进行惯性权重ω的调整.神经元内部每次迭代后,都根据适应度值对粒子进行优劣排序,将其中最优的s个粒子送入主神经元4. 图1 SNPS-PK算法对应的膜结构 神经元1和3中的规则如下: 辅助神经元2中的规则如下: 主神经元4对从辅助神经元1、2和3接收到的3s个粒子进行重新迭代和排序,搜索到最优解. 主神经元4中的规则如下: SNPS-PK算法包括2个阶段:在前阶段,利用SNP系统的并行性和PSO算法的全局寻优能力进行全局搜索,在可行解空间内找到k个优化的初始聚类中心;在后阶段,执行K-means算法,进行局部优化,并输出最终的聚类结果. 其中,SNPS-PK算法前后两个阶段的转换时机是根据适应度方差σ2来判定粒子群的收敛程度.适应度方差σ2定义如下, (10) 其中,m是粒子群的规模,favg是粒子适应度的平均值.当σ2很小时,粒子群的状态已趋于收敛,此时即为SNPS-PK算法的转换时机. 为了验证SNPS-PK算法的有效性,本研究对其进行了仿真实验测试. 实验环境为:操作系统Windows 10,CPU 2.7 GHz InterCore(TM),内存4 GiB,编译软件为Edit with IDLE,用Python语言编程实现.本研究在3个数据集上测试SNPS-PK算法,其中包含1个真实数据集Iris及2个人工数据集Data1和Data2.在实验中,分别在此3个数据集上运行SNPS-PK算法,得到的聚类结果如图2~图4所示. 图2在数据集Iris上执行SNPS-PK算法 图3在数据集Data1上执行SNPS-PK算法 图4在数据集Data2上执行SNPS-PK算法 同时,实验中还将SNPS-PK算法与标准K-means算法、PSO-KM算法进行了比较.三种算法的聚类准确率及运行时间的比较结果如表1所示. 由表1可知,三种算法中,K-means算法的准确率最低,SNPS-PK算法的准确率最高,PSO-KM算法介于两者之间.PSO-KM算法利用PSO的全局搜索能力,此在一定程度上提升了聚类准确率.而SNPS-PK算法在PSO-KM算法的基础上引入SNP系统,利用SNP系统的并行性进一步优化了聚类中心,并对惯性权重w和飞行时间因子H0进行动态调整,使SNPS-PK算法能够更好地接近最优解,聚类准确率得以进一步提升. 表1 3种算法的聚类准确率及运行时间比较 本研究在粒子群聚类算法中引入SNP系统,将SNP系统的并行性和PSO的全局寻优能力相结合,使得初始聚类中心得以进一步优化,为下一步K-means算法的局部寻优提供了更好的聚类初值,提升了聚类结果的准确率.由于聚类算法与SNP系统的结合是一种新的研究思路,目前对其的研究仍主要集中在理论的探讨上[8-9].因此,如何利用基于SNP系统的聚类算法解决实际问题是下一步的主要研究方向.2.2 SNPS-PK算法中的参数设置
2.3 SNPS-PK算法的膜结构
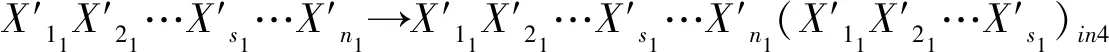
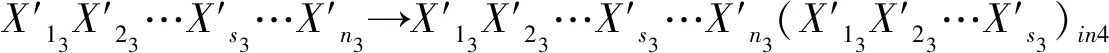
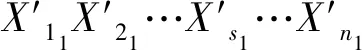

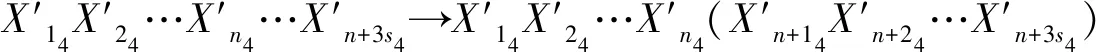
2.4 SNPS-PK算法的转换时机
3 实验与分析
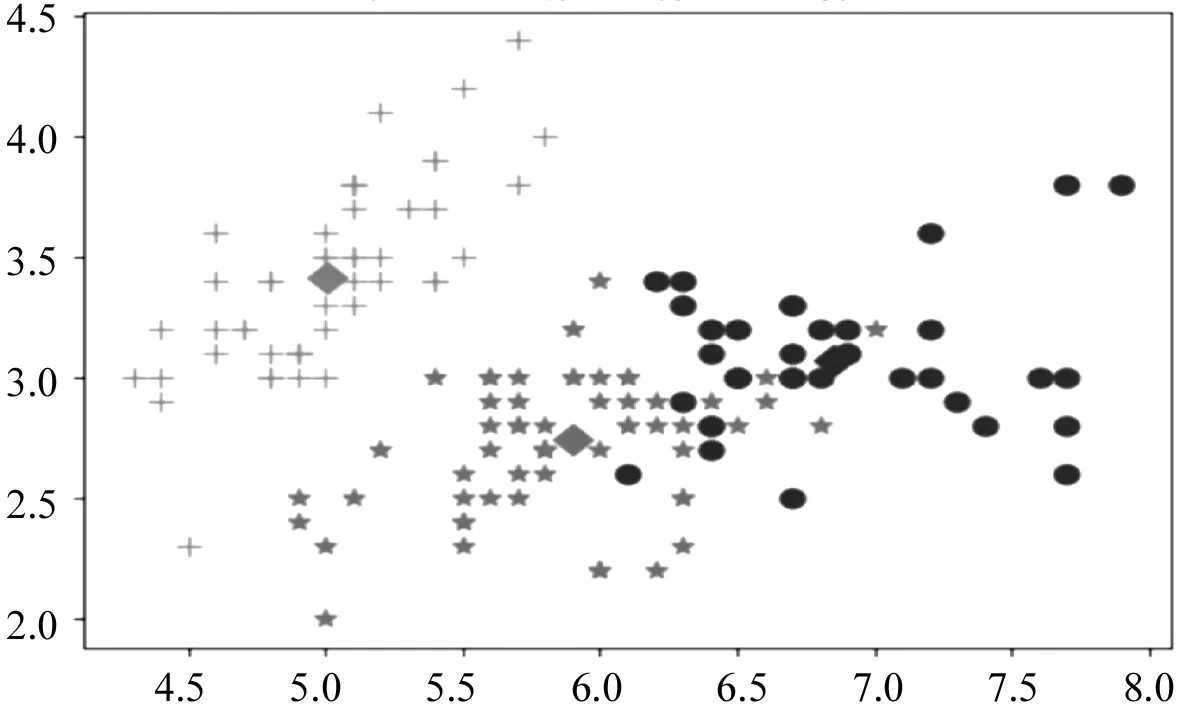
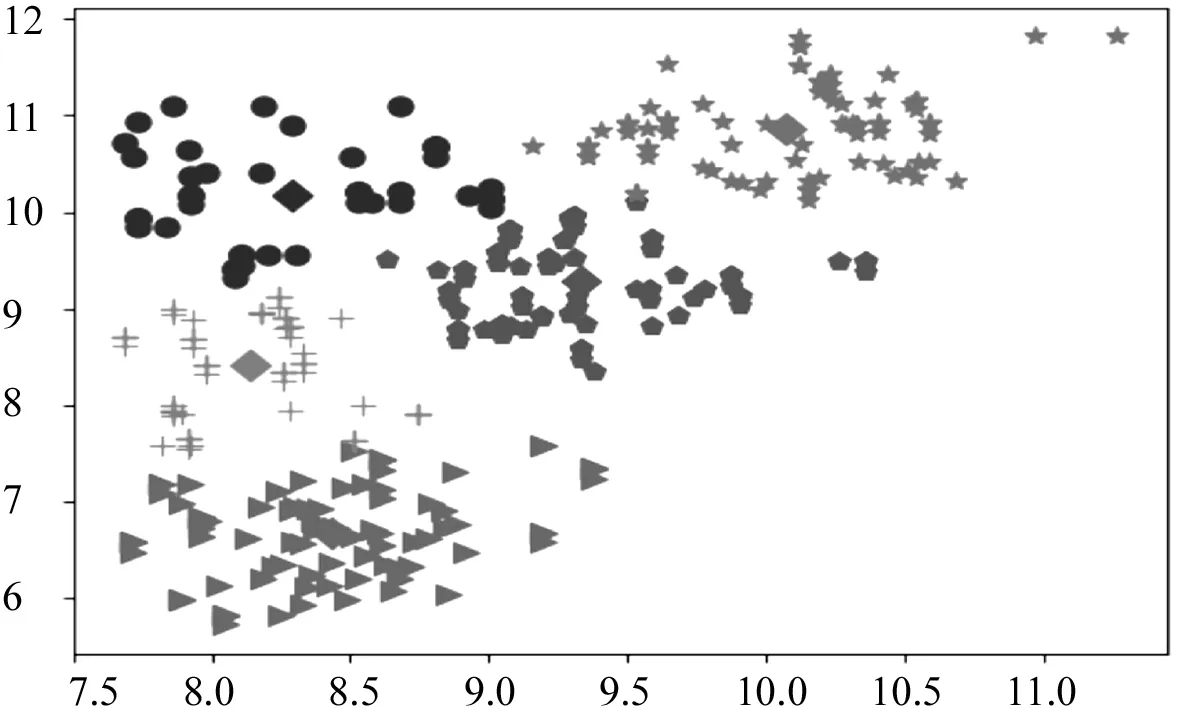

4 结 语
