大数据挖掘中的MapReduce并行聚类优化算法研究
2019-06-19吕国肖瑞雪白振荣孟凡兴
吕国 肖瑞雪 白振荣 孟凡兴
摘 要: 针对传统数据挖掘算法只适用于小规模数据挖掘处理,由于数据规模不断增大,其存在计算效率低、内存不足等问题,文中将MapReduce用于数据挖掘领域,对大数据挖掘中的MapReduce进行了并行化改进,并设计相应的并行化实现模型,以期满足大数据分析需求,完成低成本、高性能的数据并行挖掘与处理。
关键词: 大数据; MapReduce; 并行化处理; 聚类算法; 数据挖掘; Map任务
中图分类号: TN911.1?34; TP311.14 文献标识码: A 文章编号: 1004?373X(2019)11?0161?04
Abstract: The traditional data mining algorithm is only suitable for small?scale data mining and processing, and its disadvantages of low computational efficiency and insufficient memory are exposed gradually with the increase of data scale. MapReduce is used in the field of data mining to analyze the MapReduce parallelization improvement of the traditional data mining algorithms; and the corresponding parallelization implementation model is designed to meet the demand of big data analysis, and successfully complete the low?cost and high?performance data parallel mining and processing.
Keywords: big data; MapReduce; parallelization processing; clustering algorithm; data mining; Map task
0 引 言
随着大数据时代的来临,互联网的数据量正呈现出爆炸式的增长,采用传统数据分析法对其进行分析和研究,已经无法满足海量数据处理的需求。基于此,数据挖掘技术随之产生。数据挖掘就是从大量、随机、模糊、有噪声的数据内提取有价值的信息。数据挖掘技术是指从大量数据中利用算法对隐藏信息进行搜索的过程,目前被广泛应用于金融、网络、决策及教育等行业中。数据挖掘技术以统计学作为基础,增设模式识别、机器学习、数理统计、人工智能等多种技术,通过流数据及数据库完成工作[1]。在数据技术不断发展的过程中,还融入了数据安全、数据结构算法、信息检索、信号处理、信息论等多种技术。聚类分析则是一项比较实用的数据挖掘技术,因其能有效分析数据并发现其中的有用信息,被广泛用于文本搜索、人工智能、图像分析等领域[2]。聚类分析把数据对象划分为多个簇,虽然同一个簇内的数据对象相似,但不同簇内的对象存在一定的差异。本文在深入分析大数据挖掘流程的基础上,提出基于MapReduce的并行化模型,以期为类似研究提供一定参考。
1 大数据挖掘实现流程
大数据来源比较广泛,其数据类型有所差异,但最基本的处理流程大致相似,如图1所示。开展数据挖掘的主要目的就是从复杂的数据内提取隐含的、未知的、有价值的信息,并将其用在生产实践中,从而提升生产效率[3?4]。通过数十年的发展,数据挖掘技术慢慢发展成熟,并汇聚数据库、人工智能等领域的关键知识。数据挖掘技术也在聚类、关联分析等领域得到迅速发展,并逐步完成相关的数据挖掘算法,例如,贝叶斯算法等。
图1 数据处理基本流程
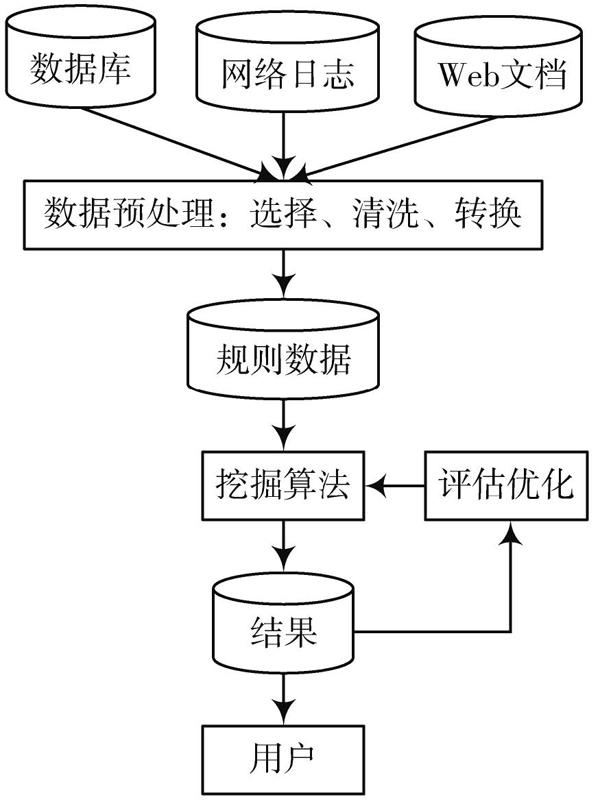
1) 數据预处理。这一阶段的主要作用在于对大量有噪声的原始数据实施去除冗余处理,并提取有效的数据,将其转换为合适的数据格式[5]。数据预处理包含数据选择、清洗、转换等环节。
2) 数据挖掘算法引擎包含算法执行、评估优化、获取结果三个环节。通过对算法执行的输出结果进行分析和评估优化处理,可以为相应的算法提供反馈[6?7]。而用户交互的主要功能在于接收用户发布的指令,负责输出相应的数据挖掘结果。
近些年,由于互联网等行业的发展,数据量明显增加,使得数据规模更庞大,数据类型更多元。与此同时,数据挖掘的具体需求和应用环境也日趋复杂。这些改变给传统数据挖掘算法带来严峻的挑战。基于此,采用分布式并行方法可以解决数据挖掘难题。
2 构建数据挖掘算法并行化模型
2.1 数据挖掘并行化处理思路
数据处理的前提在于做好数据存储,而大数据处理、分析的重点在于具有分布式存储功能及较强的计算能力。在单体计算资源限定的基础上,解决计算问题时使用并行计算技术可以打破内存、CPU等方面的限制,有效提高计算效率。针对数据挖掘计算量大这一难点,一般有以下解决思路:
1) 任务并行化处理:设计一种新的并行算法,把数据挖掘任务拆分为多个子任务,并把子任务提交到各节点展开处理[8]。
2) 数据并行化处理:在并行任务执行结构的基础上,把数据拆分为支持并行处理的子集,并在不同子集处理完成后合并获取最终的结果。
这两种并行挖掘方法各有其优点,能够满足不同应用场景的实际需求。在一般情况下,这两种挖掘方法可以互相补充,协同完成挖掘任务。
2.2 依托MapReduce建立并行化模型
在现实场景下,大部分的大型数据管理系统均以分布式形式出现。在数据挖掘过程中,传统的数据挖掘技术采用集中存储,统一处理的方法。但随着数据量的不断增加,已有硬件的存储空间已经无法满足集中存储的需求。在这种情况下,需要利用分布式数据挖掘策略顺利完成挖掘任务。
分布式并行数据挖掘模型如图2所示。
图2 建立的并行数据挖掘模型
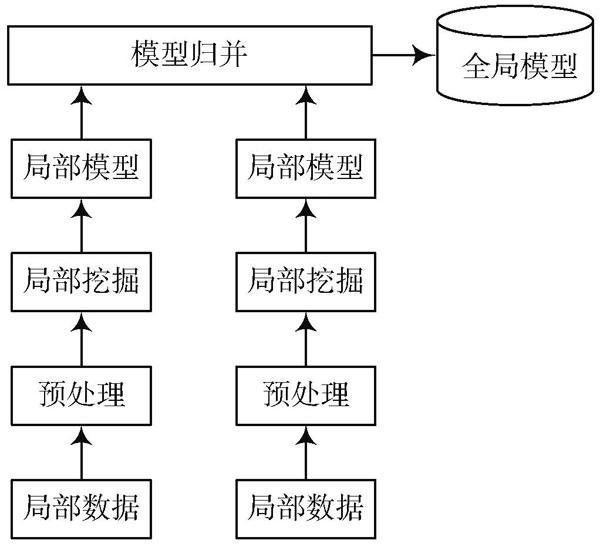
MapReduce作为比较适用于进行大数据量处理、计算环节简单的并行计算框架,把MapReduce应用到数据挖掘方面成为有效解决大数据挖掘难题的一种需求。有学者在NIPS国际会议上提出“求和范式”条件,该条件指出一个数据挖掘算法是否可以通过MapReduce完成并行化处理,其重点在于算法是否可以将数据分解成不同的部分,并将其交给不同的计算节点独立完成计算,最终汇总相应的计算结果。依据数据挖掘算法设定的“求和范式”条件,建立如图3所示数据挖掘算法并行化处理模型。
图3 MapReduce条件下数据挖掘算法并行化模型
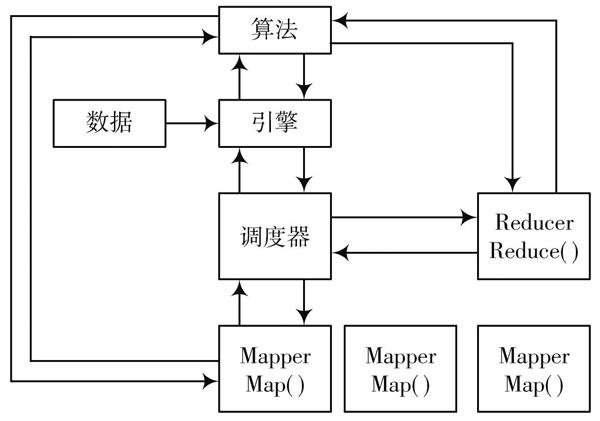
通过分析图3可知,MapReduce并行化执行流程如下:首先启动算法引擎,然后引擎开启相应的调度器,从而合理控制Mapper及其Reducer运行情况。
1) 调度器在Hadoop内属于热插拔组件,其主要作用在于合理分配系统资源。目前,Hadoop包含三个常用的调度器:FIFO Scheduler,Fair Scheduler,CaPacity Scheduler等。其中,FIFO Scheduler作为原理比较简单的调度器,也是Hadoop默认设置的调度机制。FIFO Scheduler实施调度机制在于Hadoop根据队列先后顺序开展作业,即先把作业提交至队列,并执行相应的操作。Fair Scheduler属于一个多用户的调度器,与前者相比较,其主要优势在于支持资源公平共享、支持负载均衡机制等。Capacity Scheduler属于一个多用户调度器,具有复杂的算法机制,支持多个队列,Hadoop在选取队列执行操作时,它用于计算筛选队列。
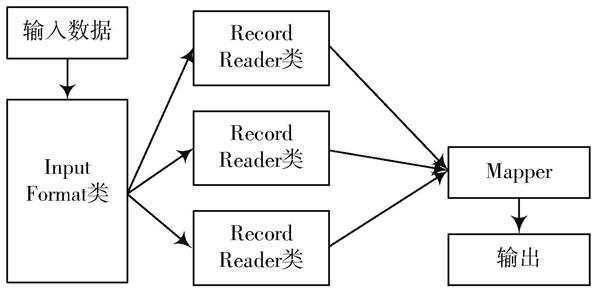
2) 调度器支持把分片数据分配至与之对应的Mapper节点上进行处理。Mapper节点接收相应的Map任务后,会建立TaskInProgress实例,这一实例主要用来完成任务调度和监控工作。为更好地执行该Map任务,需要建立TaskRunner实例,并通过启动JVM确保Map函数处于运行状态。Map任务执行流程如图4所示。分析图4可知,分配而来的数据被解析为图4 Map任务实现流程
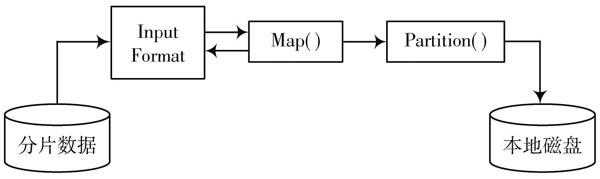
3) Mapper节点经过处理后中间数据交给Reducer 节点进行处理。在某些Map任务顺利完成后,JobTracker会将Reduce任务分配给与之对应的Reducer节点。必须注意,此时,Reduce任务并未开始执行,仅仅是开展一些数据的准备工作,从而有效节省整体时间。在全部的Map任务顺利完成后,Reducer节点才开始执行Reduce任务。
4) 当Reducer完成相应的处理工作后,会把结果汇总并返回。每一个Reducer节点的输出结果保存在临时文件内,当全部的Reduce任务顺利完成后,所有临时文件数据均要实施合并处理,从而组成相应的输出文件。
3 基于MapReduce并行聚类算法实现
在MapReduce基础上的并行遗传算法就是对粗粒度遗传算法进行改进,顺利实现Map与Reduce这两个环节的聚类,系统会把输入的数据集划分为一定大小的文件块(Split),每个文件块又被一个Mapper进行处理,从而完成第一阶段的聚类。在此基础上,把第一阶段聚类产生的数据交由单个的Reducer实施处理,形成第二阶段聚类。如此一来,多个Mapper与单个Reducer即可执行这一算法,其实现模型如图5所示。
圖5 改进后MapReduce并行算法计算框架
其中,在第二个聚类阶段,首先接收源自Mapper染色体并组成一条新的染色体。此外,对那些质心间距比设定阈值小的聚类进行合并,合并后形成新的质心作为原来质心平均值。通过反复实验可知,质心间距离设置为20%,可以确保获得合理结果,阈值求解公式如下:
式中:[T]表示阈值;[Mi,j]表示聚类[i,j]两者间的距离;[Di],[Dj]分别表示[i]类和[j]类各自距离质心最远点的距离。在此基础上,重复以上过程,直至染色体内所有的聚类质心间距存在一个大于指定阈值,迭代结束。最终,染色体获取最佳的聚类中心位置。
4 结 语
由于数据挖掘面临着数据量不断增长的挑战,如何高效率、低成本、可扩展地从海量数据内挖掘有价值的信息成为数据挖掘急需解决的问题。传统并行算法在海量数据挖掘方面有一定的成效,但针对并行任务编程难度大、成本高、网络带宽受限等问题,本文提出的MapReduce编程模型能显著提升数据挖掘效率。本研究在掌握MapReduce并行计算框架的前提下,依托多种数据挖掘算法展开分析,建立MapReduce的数据挖掘算法并行化模型,并提出并行聚类算法。依据这一模型,可以突破海量数据挖掘面临的性能瓶颈,有利于进一步提升数据决策价值的有效性。
参考文献
[1] 封俊红,张捷,朱晓姝,等.基于PAM和均匀设计的并行粒子群优化算法[J].计算机工程与应用,2016,52(12):19?25.
FENG Junhong, ZHANG Jie, ZHU Xiaoshu, et al. Parallel particle swarm optimization algorithm based on PAM and uniform design [J]. Computer engineering and applications, 2016, 52(12): 19?25.
[2] 黄斌,许舒人,蒲卫,等.基于MapReduce的数据挖掘平台设计与实现[J].计算机工程与设计,2013,34(2):495?501.
HUANG Bin, XU Shuren, PU Wei, et al. Design and implementation of data mining platform based on MapReduce [J]. Computer engineering and design, 2013, 34(2): 495?501.
[3] 朱付保,白庆春,汤萌萌,等.基于MapReduce的数据流频繁项集挖掘算法[J].华中师范大学学报(自然科学版),2017,51(4):429?434.
ZHU Fubao, BAI Qingchun, TANG Mengmeng, et al. MapReduce?based frequent itemsets mining algorithm for data streams [J]. Journal of Central China Normal University (Natural Science Edition), 2017, 51(4): 429?434.
[4] 张振友,孙燕,丁铁凡,等.一种新型的基于Hadoop框架的分布式并行FP?Growth算法[J].河北工业科技,2016,33(2):169?177.
ZHANG Zhenyou, SUN Yan, DING Tiefan, et al. A new distributed parallel FP?Growth algorithm based on Hadoop framework [J]. Hebei industrial science and technology, 2016, 33(2): 169?177.
[5] 魏玲,郭新朋.基于并行处理机制的数据复用策略研究[J].计算机应用研究,2017,34(8):2324?2328.
WEI Ling, GUO Xinpeng. Research on data reuse strategy based on parallel processing mechanism [J]. Application research of computers, 2017, 34(8): 2324?2328.
[6] 周浩,刘萍,邱桃荣,等.基于粒计算的决策树并行算法的应用[J].计算机工程与设计,2015(6):1504?1509.
ZHOU Hao, LIU Ping, QIU Taorong, et al. Application of decision tree parallel algorithm based on granular computing [J]. Computer engineering and design, 2015(6): 1504?1509.
[7] 赵艳萍,徐胜超.基于云计算与非负矩阵分解的数据分级聚类[J].现代电子技术,2018,41(5):56?60.
ZHAO Yanping, XU Shengchao. Data hierarchical clustering algorithm based on cloud computing and NMF [J]. Modern electronics technique, 2018, 41(5): 56?60.
[8] 李娜,余省威.云计算环境下多服务器多分区数据的高效挖掘方法设计[J].现代电子技术,2017,40(10):43?45.
LI Na, YU Shengwei. Design of efficient mining method for multi?server and multi?partition data in cloud computing environment [J]. Modern electronics technique, 2017, 40(10): 43?45.
