基于多核集成学习的跨项目软件缺陷预测
2019-06-14荆晓远董西伟
黄 琳,荆晓远,董西伟
(南京邮电大学 自动化学院,江苏 南京 210003)
0 引 言
软件缺陷的产生往往是由于开发人员需求理解不正确或是经验不足。而含有缺陷的软件在运行时可能会产生意料之外的结果,严重的时候会给企业造成巨大的经济损失,甚至会威胁到人们的生命安全。软件缺陷预测(software defect prediction,SDP)是软件工程中最重要的研究课题之一[1],吸引了学术界和工业界的广泛关注。基于度量的静态软件缺陷预测技术借助于从已有的软件模块中获得历史数据,对新的软件模块进行缺陷预测,来判断它们是否存在缺陷,从而为软件项目提供决策支持[2-4]。近年来,支持向量机(support vector machine,SVM)[5]、决策树[6]、朴素贝叶斯[7-8]、代价敏感学习[9]和集成学习[10-11]这些机器学习技术已经被广泛地用于软件缺陷预测领域。最近,字典学习[12]、稀疏表示[13]等方法也被引入了软件缺陷预测中。软件缺陷预测的历史数据具有样本不足、结构复杂和类别分布不平衡的特点。为了解决这些问题,文中提出一种基于多核集成学习的跨项目软件缺陷预测算法(cross-project software defect prediction based on multiple kernel ensemble learning,CMKEL)。
1 相关工作
1.1 跨项目缺陷预测
软件缺陷预测是当前大数据技术在软件工程领域的重点研究方向之一[14]。在早期大多数的研究都是使用项目内已经标记的程序模块,一部分样本来构建预测模型,另一部分样本作为预测。然而在实际应用中项目内的历史数据是有限的。由于历史数据的缺少,研究者们开始关注跨项目软件缺陷预测的问题,跨项目就是使用其他项目的训练数据来构建预测模型,并对一个全新项目进行缺陷预测。
1.2 多核学习技术
多核学习就是将不同特性的核函数进行组合,获得多类核函数的优点,来达到更优的映射性能。和传统的单核方法相比,多核学习不仅能够组合利用各基本的单核函数的特征映射的能力,而且还能将不同特性的核函数进行组合,来获得多类单核数的优点,从而得到更优的映射能力,提高预测的精度。
1.3 集成学习技术
集成学习就是用多个弱分类器结合为一个强分类器,从而提升分类方法的效果。集成学习能够得到比基分类器更好的分类效果和泛化能力,不容易出现过拟合情况,因此适用于跨项目缺陷预测问题。
2 基于多核集成学习的跨项目软件缺陷预测
对于静态软件缺陷模块存在的结构复杂、类别不平衡、历史数据缺少的问题,文中提出一种基于多核集成学习的跨项目软件缺陷预测方法。
假设训练的软件模块D={(xi,yi),i=1,2,…,N},其中xi是模块属性的向量,yi∈{0,1}是模块的标签,N是项目数。K={kj:X×X→R,j=1,2,…,M}是M个核函数的集合,其中X是输入空间。CMKEL主要是学习基于多核的一个分类器f(x),这个分类器是通过有标记的历史数据进行多核训练得到的,通过基于多核的分类器f(x)来预测新的软件模块,基于多核分类器表示为:
(1)
其中,T为整个boosting过程的次数;ft(x)为第t次(1≤t≤T)boosting过程得到的弱分类器;αt为相应的权重值。
该算法的关键点是每次在M个基于核函数的分类器中进行boosting过程后,学习得到一个错误分类误差最小的ft(x)分类器及其组合权重αt。经过T次boosting过程之后,将这些分类器按照权重值集成,得到最终的分类器。
2.1 多核学习分类器
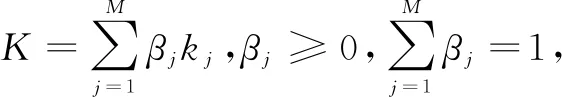
(2)
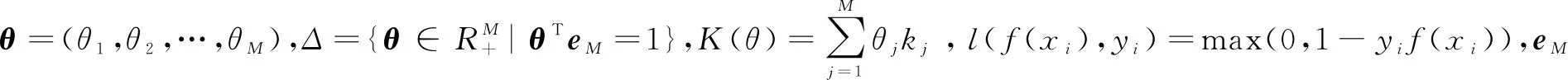
多核学习的目标是通过最优化方法来求取合成核的参数,将上式转化为如下的最优化形式:
(3)
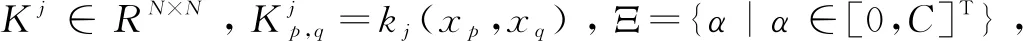
2.2 多核集成学习分类器
为了学习一个多核集成的分类器,文中采用一个典型且有效的boosting算法。具体而言,在初始化训练集之后通过一系列boosting过程,重复学习一些基于核的分类器,然后根据它们的组合权重进行集合,从而得到最终的CMKEL分类器。在boosting过程之前,需要先对训练集进行初始化。文中在整个训练集上直接执行随机抽样策略,然后将这些选择的样本作为CMKEL初始训练集。
在训练集初始化完成之后,需要有对应的Dt向量,Dt表示每个样本在整个boosting过程的不同权重。最初,这些权重都是相同的。为了更加关注那些错误分类的样本,在每一次boosting过程增加错误分类的权重或是减少正确分类的权重,来调整权重向量Dt。一旦得到训练集和权重向量Dt,就可以进行boosting过程。每次boosting过程的关键是要从M个基于核函数的分类器中学习得到一个基于核假设的分类器ft(x)。
样本中无缺陷模块的标签为0,有缺陷模块的标签为1。软件缺陷预测模型对有缺陷的模块被预测为无缺陷时称为Ⅰ类错误,代价表示为cost(1,0);反之Ⅱ类错误表示无缺陷模块被预测为有缺陷的,代价表示为cost(0,1),显然Ⅰ类错误的代价敏感要远大于Ⅱ错误代价敏感。文中定义的代价矩阵如表1所示。

表1 代价矩阵
在表1中,μ表示I类错误的代价敏感系数。
考虑到代价矩阵后的每个基于核分类器的错误分类误差的计算为:
(4)
其中,cost(l,g)为代价矩阵,cost(l,g)表示l类被错分成g类的代价。
最好的分类器是得到最小的错误分类误差,在第t次boosting过程之后得到的弱分类器为:
(5)
在第t次的boosting过程中,ft(x)分类器的权重αt和错误分类误差的关系表达式为:
(6)
在得到权重αt之后,第t次的boosting过程完成。在下一次boosting开始前,要根据第t次boosting过程的结果更新下一次boosting过程中的权重向量Dt+1。权重向量的更新原则是根据分类结果进行更新,通过提高错分样本的权重,降低正确分类样本的权重。目的是在下一次boosting过程中将重点放在错误分类的样本上,训练样本集的权重向量更新表达式为:
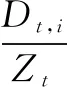
(7)
其中,Zt是规范化因子。
根据分类的结果,权重向量的更新策略详细表示为:
(8)
其中,ft(xi)=yi表示被正确分类;ft(xi)≠yi表示被错误分类。
经过T次boosting过程后,最终的分类器为:
(9)
综上所述,CMKEL算法的描述如下:
输入:训练集、核函数kj、初始权重分布D1=1/N。
(1)开始第t=1~T次的boosting过程,权重向量表示每个训练样本Dt的权重分布。
(2)对于j=1~M来训练对应kj核函数的弱分类器,根据式4计算在Dt下的错误分类误差。
(3)训练完所有的基于核的分类器之后,选择最小错误分类的分类器,由式5得到ft(x)。
(4)由式6计算αt。
(5)根据式8权重更新的策略,更新下一次boosting过程的权重向量分布。
(6)T次boosting过程之后,得到T组分类器和与之对应的权重。
输出:最终分类器G(x)。
3 实 验
为验证CMKEL算法的预测效果,将该算法与加权朴素贝叶斯(weighted Naïve Bayes,NB)算法[7]、压缩的C4.5决策树(compressed C4.5 decision tree,CC4.5)算法[15]和代价敏感的Boosting神经网络(cost-sensitive boosting neural network,CBNN)算法[16]在NASA、AEEEM数据库中进行对比验证。
3.1 实验数据库
NASA、AEEEM数据库的工程数都是五个,它们各个工程的静态代码度量和缺陷占比如表2所示。
3.2 实验指标
预测模型的评估指标有召回率(pd)、误报率(pf)、查准率(precision)和精确度(acc)。
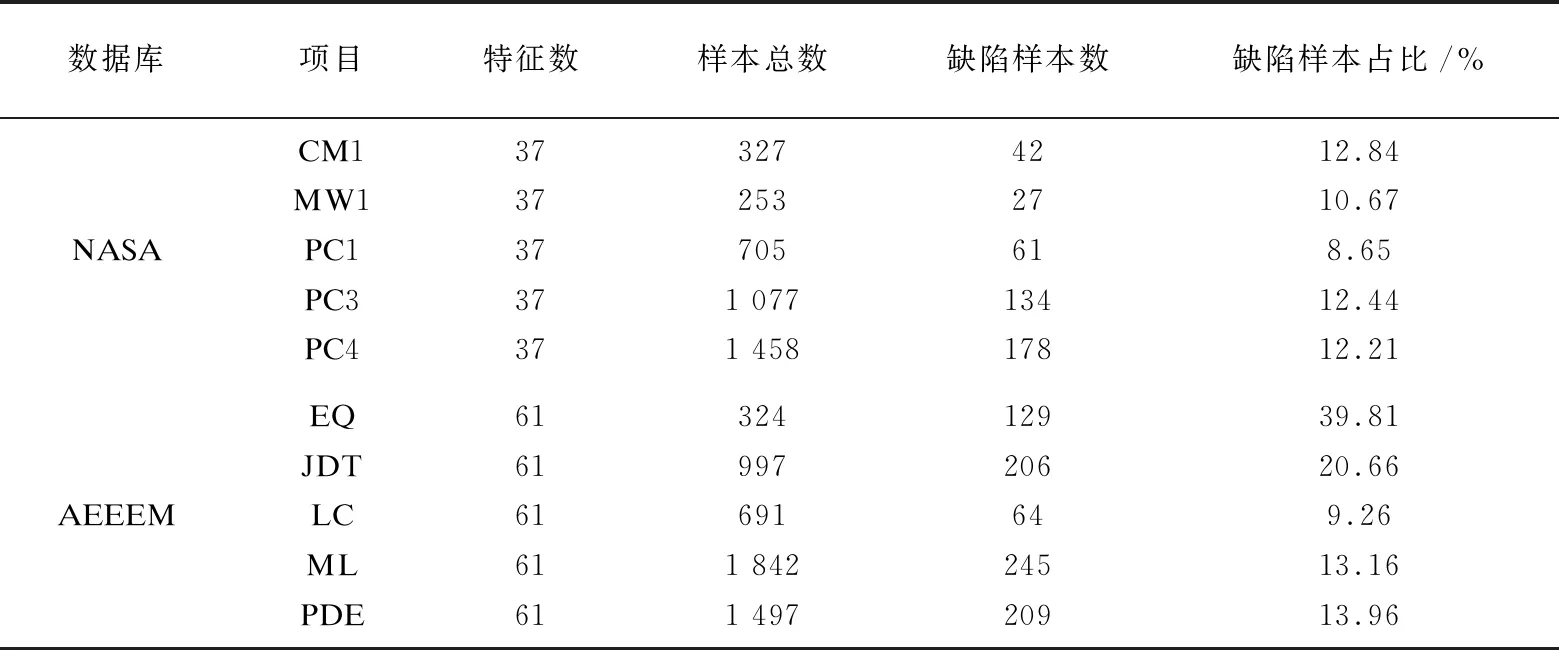
表2 数据集的详细信息
文中主要采用两个综合性能指标:F-measure,就是将pd与precision结合起来评价;AUC值(area under curve)被定义为ROC曲线下的面积,使用AUC值可以评估二分类问题分类效果的优劣。F-measure和AUC的数值越大,表示软件缺陷预测模型的预测性能越好。
3.3 实验设置
在多核学习的训练中,选择具有20个不同宽度(2-10,2-9,…,29)的高斯核函数,然后使用这20个基核分别将NASA和AEEEM里面的每一个工程映射到一个新的特征空间。对于弱分类器SVM,结合每个核函数训练得到一个基于核的分类器,整个过程采用流行的LISVM工具箱作为SVM求解器。为了验证代价敏感系数对模型是否有影响,设置μ=1,5,10,15,20,观察代价敏感系数不同时对实验的影响。Boosting过程的初始设计如下:在同一个数据库下,随机选择一个工程作为训练样本,另一个工程作为测试样本,每组算法迭代20次,最后将20次跑出来的数据取平均。Boosting的过程和文献[17]中一致,训练次数T为100。
3.4 实验结果及分析
为了验证在CMKEL算法中代价敏感系数的大小对实验结果的影响,设置了不同的μ值,在AEEEM数据库上的实验结果如表3所示。其中μ=1表示没有引入代价敏感系数。
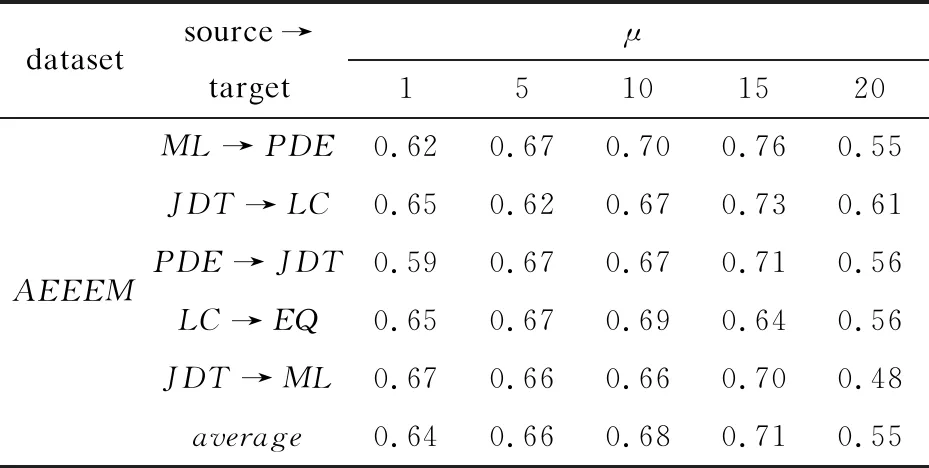
表3 不同代价敏感系数下的AUC值
从表3中的实验结果可以看出:当μ>1时,AUC值要比μ=1高,说明引入代价敏感系数提高了预测的效果;随着μ值的增大,AUC的值也在增长,但是当μ>15时,AUC值开始下降,说明代价敏感系数并不是越大越好,当μ=15时,CMKEL算法能达到最好的效果。
为了验证文中算法是否有更好的性能,分别在NASA和AEEEM两个数据库与其他算法进行对比,结果如表4所示。(实验结果中将F-measure值表示成F值)
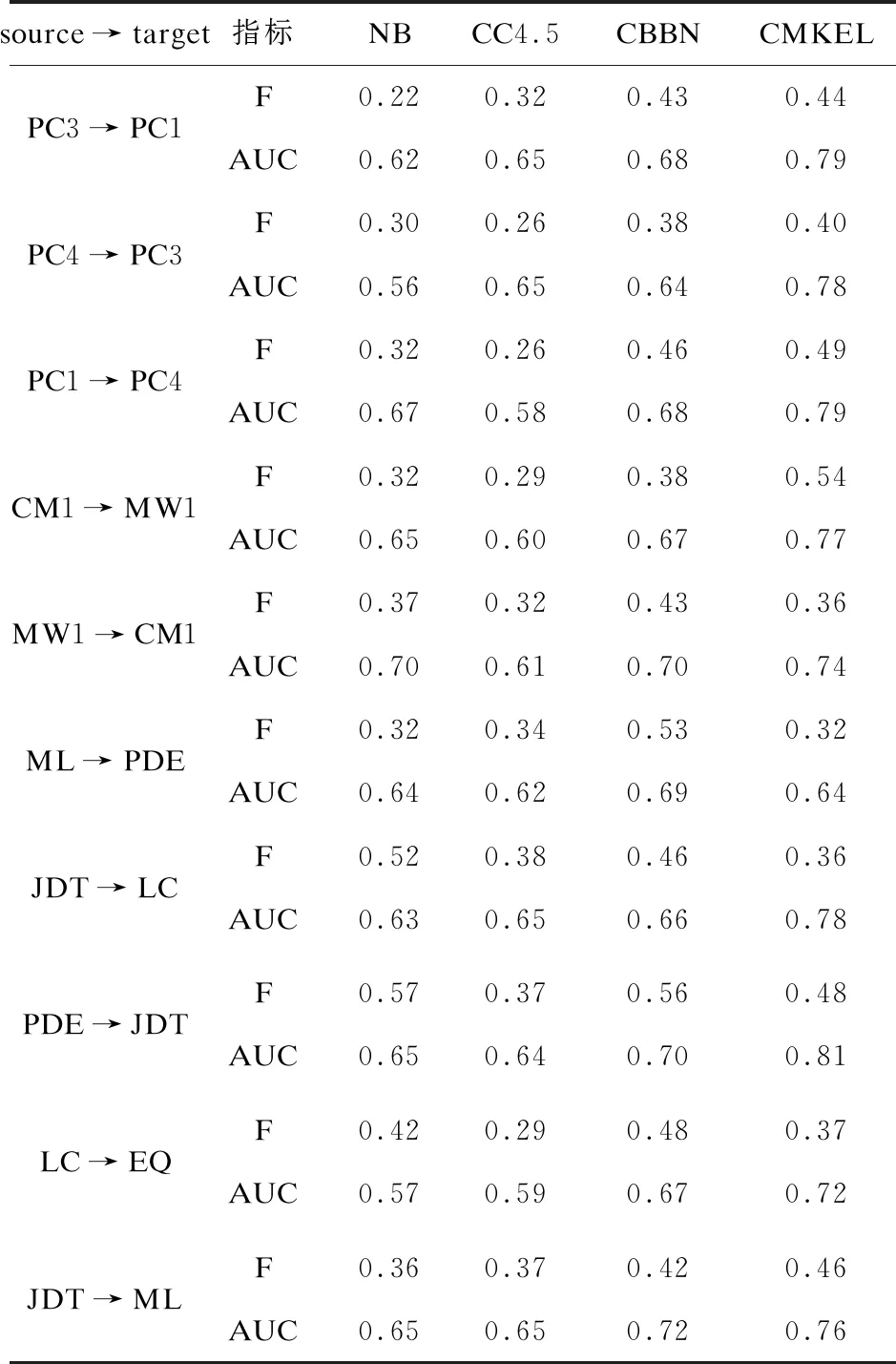
表4 算法对比结果
通过以上实验可以看出:NB,CC4.5,CBBN算法在某些项目上面能够有比较好的F-measure值,但是CMKEL在大部分项目上都同时有很好的F-measure值、AUC值,效果要比前三种算法好,表明了CMKEL算法的优越性。
4 结束语
为了解决软件缺陷预测中样本数据结构复杂与类别分布不平衡的问题,提出一种基于多核集成学习的跨项目软件缺陷预测算法。利用多核学习将数据映射到新的特征空间,更好地表示数据,提高预测的精确度。集成学习能够解决类别分布不平衡的问题。在NASA和AEEEM这两个数据库上的实验结果证明了该算法的有效性。
