基于声学音素向量和孪生网络的二语者发音偏误确认
2019-05-24王振宇解焱陆张劲松
王振宇,解焱陆,张劲松
(北京语言大学 语言资源高精尖创新中心,北京 100083)
0 引言
汉语二语学习者难以习得标准发音,即使有很多对话经验的高级汉语学习者也难以掌握正确的汉语发音和声调。计算机辅助发音教学作为有限传统教育资源的有力补充,能给予二语学习者及时有效的帮助和反馈。计算机辅助发音训练作为计算机辅助发音教学系统的重要组成部分,在系统构建过程则发挥着重要作用。
在以往研究中,自动语音识别系统被应用于在音段层级的发音偏误检测任务中来评估学习者发音的正确与否,以音素为单位计算对数后验概率分数来检测发音偏误[1]。Witt和Young[2]引入基于概率的发音良好度方法,此方法给出的是一个归一化的对数似然比分数并在文献[3-5]中用于句子确认。后来出现了一些发音良好度的变体[6-8],也都是基于每一个音素相对于母语者置信分数均值来设置阈值从而判断偏误。以上系统提供的音段层级的反馈是比较有指导性和直观的评价结果。
由于基于发音良好度方法的一个重要组成部分是依赖于大量人工标注的自动语音识别系统。因此,我们想探究使用弱监督的方法去获得一个有区分性的特征表示,此方法也较适合于一些资源稀缺的情况[9-10]。之前的部分研究使用了一种叫孪生网络[11]的结构。此网络将一对标明相同与否的词对输入到两个权值共享的深度神经网络,从而得到话者和音段信息[12]。Synnaeve 等根据所给数据标签类型改进了损失函数,在音素错误率上得到了和全监督方法近乎相等的结果[13]。使用声学词向量的词区分任务也已经在几个其他的研究中得以应用[14-16],通过比较词向量的距离计算平均错误率,来衡量系统准确性。Herman等比较了几种用于词区分任务的方法,使用卷积孪生网络使系统得到了进一步的提升[17]。
我们的方法引入声学音素向量来确认二语学习者的发音偏误,并给出了有指导性且具体的反馈。基于前人的声学词向量想法,我们使用带有配对信息的音素,基于弱监督的方法来做音素区分任务。以定长的语音特征向量作为孪生网络的输入,判断生成的音素向量是否来源于同一音素并依此修正生成向量间的距离。结果显示,使用余弦最大间隔距离损失函数的卷积孪生网络得到了最好的音素确认结果。基于此结论,我们使用实验得到的最好模型进行二语者的发音质量评价,在不添加标注的二语发音偏误数据作为训练数据的情况下,得到了优于基于发音良好度的方法的结果,并且模型的鲁棒性也更好。
本文中,第一部分概要描述了经典的发音良好度、DNN-HMM方法,以及基于声学音素向量和孪生网络的音素确认的方法;第二部分对实验配置和实验过程进行具体说明,第三部分根据实验结果进行分析讨论,第四部分为总括性的结论。
1 音素确认方法概要
本节介绍了传统的发音评价方法—发音良好度,和经典的基于DNN-HMM语音识别框架的发音偏误检测的基本原理。基于对传统方法原理的思考,我们提出了用基于音素结合孪生网络的方法进行发音偏误确认。
1.1 发音良好度打分
在发音评分中,发音良好度GOP(Goodness of Pronunciation)是最广泛使用的方法之一。此方法为句子中的每个音素都给出一个置信分数。音素p的发音良好度分数,如式(1)所示。
(1)
给定声学模型和正则文本,p是标准单元,q是对比单元,Op是NF(number of frames)帧音素p的输入特征。边界信息来源于强制对其结果,Q是可能音素的集合。设置一个阈值以确认当前单元是否是一个正确发音,高于此阈值即为正确反之错误,此阈值根据任务和训练数据不同可做相应调整。可以利用式(1)计算任何给定的音素的对数后验概率,并称之为亚音段分数。我们在音素发音错误确认任务中,使用的基线系统是发音良好度评价系统,该系统由在大规模母语者语料库[18]训练得到的神经网络三因子声学模型构成。
1.2 DNN-HMM框架
深度神经网络结合隐马尔科夫模型的声学模型建模框架式是现今在自动语音识别领域比较通用和流行的框架,其在大规模的连续语音识别任务中的性能也远超传统混合高斯模型GMM-HMM混合模型。因此,本文将DNN-HMM模型引入发音偏误检测的声学模型建模阶段,以期获得更好地系统检测性能。高迎明等在文献[19]中将使用DNN-HMM混合模型训练得到的声学模型应用到发音偏误检测任务中,并得到88.6%的诊断正确率。DNN深度神经网络是前馈人工神经网络,在它的输入和输出之间有多个隐藏层。每一层由多个用来保存参数的节点构成,用输入数据对一个多层的生成性模型—深层置信网络(deep belief network, DBN)进行拟合得到参数初值[20]。DNN的输出层一般为softmax输出,从该层得到每一帧音频数据所对应的三音子音素的绑定状态的后验概率。已知从训练集估计得到的各绑定状态的先验概率,利用贝叶斯公式将先验概率转化为各状态的后验概率并输出,某状态s的输出概率,如式(2)所示。
(2)
其中,o指每一帧的声学特征,P(s)就是绑定状态的先验概率,P(s|o)是经过DNN得到的状态s的后验概率,const(s)是与绑定状态s无关的常量。得到各绑定状态的输出概率后,经过HMM[21]算法得到相应的识别结果。整体框架如图1所示。

图1 DNN-HMM框架
1.3 带调音素向量
由于传统发音良好度的方法的检测效果有限,而基于DNN-HMM语音识别框架的发音偏误检测系统需要大量标注了二语者发音偏误的数据,本文提出了音素向量的方法,期望通过得到音段层级声学特征的高层表示来区分各音素种类,从而区分二语者偏误发音和母语者标准发音。
音素区分任务将变长的语音段特征输入神经网络,神经网络最后一层的输出向量作为输入特征的高维表示,在这个向量空间中相同语音段的映射距离近,不同的类别互相远离。关键词搜索[23]和无监督条目搜索[24]已经使用过了类似的表示向量。在汉语中共有60个音素类型,21个声母39个韵母,每个汉字带一个声调(包括轻声共五类),并且声调由韵母,也就是元音来区分。在训练集中理论上,应有216类音素类型(21+39*5)。由于在汉语中部分元音不对应某些声调,其中204类在汉语中较为常见。所以,训练集中共包括204类音素类型。这个分类方法期望在一个音素区分任务中同时解决确认声调和发音偏误确认两个问题。最终,不同的音素特征向量应该被映射为能有效区分音素类型的高维表示向量。
1.4 音素相似性孪生网络
这种基于配对信息的监督学习已经在一些领域中得到应用,包括语义词向量[25-27]和图像方面的应用[28]。这些研究同样引入了孪生网络,该网络结构于19世纪90年代被首次提出[11]。我们的发音偏误确认任务通过判定标准发音人和二语者的发音相似性来达到评价二语者发音良好度的目的,这和孪生网络用来区分语义或者图像的方式有相似之处。孪生网络由两个权值共享的神经网络构成,先输入两段语音特征矩阵,再将其映射到由最后一层全连接层产生的高维向量的空间。在训练过程中,依据高维特征表示空间中的因素向量是否来自于同一类音素来调整优化他们之间的距离。在训练集中的数据标签只是配对信息而不是具体的音素标注,即每对输入特征都带有一个标签来说明他们是不是一类数据。这种辅助信息在缺乏资源或者数据稀疏的场合更容易获得,之前有研究使用无监督的条目发现系统来找未定义的匹配词对[29-30]。
在我们的实验中,语料依据强监督的音素识别系统给出强制对齐结果切分成音素段,且音素边界准确率在96.26%误差在50毫秒。因所有语音数据都是文本已知的朗读语料,故依据强制对齐结果得到每个音素的边界。然后,再结合文本中音素序列给每一个音段打上对应的标签。最后,根据音素类别标签生成配对信息。由于训练语料[18]中均为发音状况良好的母语者,我们默认将母语者发音作为标准音来训练模型。所以在数据标签获取过程中无需人工标注数据。图2描述了我们的网络结构。

图2 孪生网络结构(双生/三生)
图2是以两个输入和以三个输入开始的孪生网络结构,两种输入模式对应不同的损失函数。基于欧式距离[28](式(3))的损失函数更易于理解也符合网络的设计初衷,它更倾向于解决区分不同配对的问题,对于相同的配对效果不佳。然而,余弦距离相似性[13](式(4))的损失函数可以计算向量间的夹角而不再是空间距离。余弦距离相似性损失函数的最好情况是相同的向量夹角趋近于0,不同的向量夹角趋近于正交,如式(3)、式(4)所示。
我们希望将训练集中每一类和其他类区分开,且对多个不同类的相似程度也不同,相对距离更适合作为损失函数中的距离衡量,并假设没有在训练集中出现的配对为不同的对。由此我们引入了余弦最大间隔距离损失[26](式(5))这个损失函数。
Losscoshinge=max{0,m+dcos(x1,x2)-d(x1,x3)}
(5)

2 实验
本节介绍了所有实验用到的实验数据,给出了基于计算音素后验概率的发音良好度方法的实验配置和部分实现细节,以及基于音素向量的孪生网络的网络配置和实验过程。
2.1 语料
863语音识别语音语料库[18]用作训练数据,其中10%的数据用作开发集数据。测试数据分两部分,不同实验目的下使用不同测试语料。用母语者数据测试模型的性能,用二语者数据来做发音偏误确认实验。所有测试语料来自北京语言大学中介语语音语料库[31]。数据描述如表1、表2所示。

表1 测试集数据

表2 训练集数据
2.2 发音良好度评价系统
我们使用kaldi语音识别工具箱[32]实现发音良好度评价系统,训练出一个上下文相关的HMM-DNN声学模型,基于声学模型输出的后验概率为每个音素给定一个音段层级的发音分数。使用48维声学特征,包括13维MFCC和3维音高还有各自的一阶和二阶差分系数。深度神经网络包括六个全连接层,每一层有1 024个单元。输出层使用softmax函数产生2 943个帧级别音素概率状态类型。输入为11帧向量,由当前帧和前后五帧拼接而成。给定强制对齐结果,使用发音良好度评价系统得到的帧级别的对数后验概率分数,通过式(1)计算发音良好度分数,设置阈值为0.5来给出一个这个音是否发对的二择一判断。结果表明,发音良好度系统在母语者数据上的测试结果能达到86.32%准确率。
2.3 基于音素向量的评价系统
提取特征阶段以10ms为帧移20ms为窗长提取MFCC特征和音高以及各自的一阶和二阶差分系数,共48维声学特征。声学音素向量的方法要求将定长的语音特征向量映射到定长的特征表示空间中。由此我们将帧数较长的音素段利用动态时间规整[33]方法,将帧数较短的音素段使用补零的方法,统一归整18帧,即0.018秒。动态时间规整的方法的缺点之一就是需要计算大量的对齐距离,且不管是动态时间规整还是补零对原始信息都有一定程度的损失和扭曲,结合两个方法的目的也是为了最大程度上缓解原始信息的扭曲。同时,对每句话做全局均值方差归一化[34]以尽量消除话者或者其他方面信息的干扰。
本文使用了大约100小时的母语者数据来做音素对,整个训练数据包括开发集产生235万个音素段,这些数据被分批加入到孪生网络中训练。每批数据有512个条目,可产生6万个音素对,我们随机挑选其中3万对,并且相同对和不相同对各半,以保证训练数据平衡。测试分两步,先用母语者数据测试以检测模型的性能,然后使用二语者数据在性能最好的模型上做音素区分实验,并与发音良好度评价系统结果进行比较,所有测试数据文本来源一致。
2.4 孪生网络配置
本文使用利用tensorflow作为后台的keras工具包实现孪生网络。使用ADADELTA[35]作为随机优化方法,ADADELTA的优点是依照过去梯度的积累来调整学习率。网络结构描述如下:
DNN SIA: 2 048个节点的全连接层,激活函数RELU;1 024个节点的全连接层,激活函数RELU;256个节点的全连接层,激活函数为线性激活函数。
CNN SIA: 96个过滤器的一维卷积层对每9帧进行过滤,激活函数RELU最大池化层,步长为3;96个过滤器的一维卷积层对每8帧进行过滤,激活函数RELU最大池化层,步长为3;1 024个节点的全连接层,激活函数为RELU;256节点的全连接层,线性激活函数,损失函数是基于欧氏距离的损失函数或者是基于余弦相似性的损失函数。
CNN TRI: 和CNN SIA的结构相同,只是网络被复制成了三份,接受三个输入,损失函数余弦最大间隔损失函数。
我们比较了不同类型的损失函数和网络结构,最后使用余弦最大间隔距离损失函数的三输入孪生网络达到了最好的效果,边界参数m为0.15。
2.5 评价指标
对于母语者数据我们以预测结果是否和根据标注文本得到的配对信息相对应来衡量模型的精度。对于二语者数据,基于实验中的四种情况: 接受率,拒绝率,错误接受率,错误拒绝率。最后该实验包括三个指标来评价偏误确认系统的性能,分别是:
False Rejection Rate(FRR): 正确的发音被诊断为错误发音的数量占全部正确发音的比例。
False Acceptance Rate(FAR): 错误的发音被诊断为正确的数量占全部错误发音的数量占全部的比例。
Diagnostic Accuracy: 预测结果和标签一致的比例,即正确的被诊断为正确的,偏误发音被预测为偏误的比例。
3 结果
表3描述了在母语测试数据上的模型准确率结果。每个模型的阈值都是0.5,设置成0.5的原因是,针对根据声韵母标注而来的配对标签,每次预测的过程其实都是二分类问题,因为随机的概率是0.5,所以每个模型给出的预测概率必须大于0.5才算预测正确。
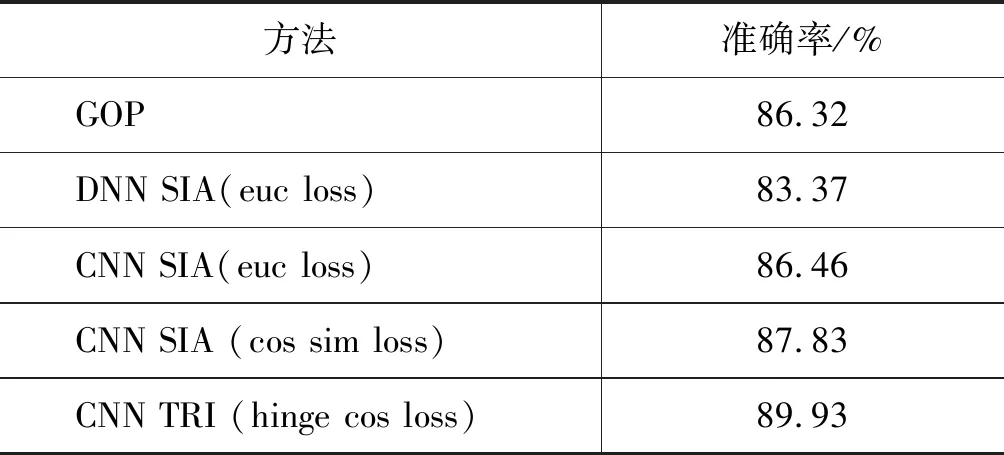
表3 在母语者数据集上的测试结果
分析以上结果我们发现,使用余弦最大间隔损失的三输入的孪生网络达到最好的效果。高迎明等结合了一些词典扩展和特征融合的技巧[19]使用二语者数据训练基于DNN-HMM框架的语音识别系统,来进行发音偏误监测任务。本文在相同的测试数据集上,用表3中所有的方法训练得到的模型来进行音素发音偏误确认的实验,并与发音良好度模型和文献[19]中的DNN-HMM模型进行对比,DNN-HMM的结果来自于高迎明的实验结果[19]。结果如表4所示。

表4 在二语者数据集上的测试结果
从结果中我们发现,发音良好度方法的效果下降非常明显。原因是训练数据和测试数据的不匹配造成的。训练数据为母语者,而测试数据为二语者,则二语者产生的非标准音素发音被当作未知音素,其识别结果无法估计,由此造成了较大损失。而DNN-HMM模型效果较好的原因是训练数据和测试数据匹配程度较高, 且基于强监督学习方法依赖音段层级的人工标注。相比之下,孪生网络的方法就有较好的鲁棒性和可实践性,原因是结合孪生网络的区分原则。如果是在训练过程中没有出现的配对就视为是不同的。那么,恰好二语者发音的非标准音素发音就被视为了和标准音不同的类型。我们知道相比母语者数据,二语者数据更难以收集,所以孪生网络训练音素向量的方法也有更好地可行性。这里我们还尝试了调整孪生网络最后一层生成的向量的维度,结果表明最后一层维度是128维的情况下,音素区分正确率最高(图3)。
图4展示了我们的方法应用在音素发音偏误确认任务的一个例子,发音偏误确认系统给出了该句中每个音素与标准音的相似度分数,该条数据来自于二语者数据。该句是一个日本女性发音人的音频数据,内容为“很忙,你呢”。通过人工听辨发现,其中“很”和“呢”的发音有较明显的声调错误。

图3 调参结果

图4 确认样例
4 结论
发音评估是二语教学中比较重要的环节。传统教学方法难以及时和有针对性的给出二语学习者有效的帮助和反馈,故我们希望用计算机辅助发音教学来弥补传统教学方法的不足。其中计算机辅助发音训练是影响计算机辅助发音教学系统性能的重要部分。二语者的数据和母语标准模板数据在听觉感知上有较明显差异,结合音素向量可以作为输入特征的高层特征表示和孪生网络能够区分输入特征向量的相似性的特点。本文提出了一种基于声学音素向量和孪生网络的方法来训练音素区分模型,之后依据系统给出的二语者和母语者的发音相似程度来给二语者的发音提供一个音素层级的评估打分。二语者可以根据该有指导性意义的打分来提高自己的发音水平。对比发音良好度基线系统和基于DNN-HMM框架的偏误检测系统,本文方法训练得到的模型的鲁棒性更优,而且训练数据及相应标签也更易获得,并在音素诊断诊断正确率上达到89.19%的效果。
