应用于UWB系统的低硬件开销128点FFT处理器设计
2019-04-25赵炅柱
于 建 赵炅柱
(1.河北民族师范学院物理与电子工程系,承德,067000;2.韩国圆光大学,益山,54538)
引 言
超宽带技术广泛应用于短距离高速的数据传输。本文介绍了一种低硬件开销的128点FFT处理器方案用于超宽带系统。FFT处理器作为超宽带系统中关键单元模块,消耗着相当大的硬件资源。因此,如何降低FFT单元模块所占用的硬件资源成为近年来的研究热点。
基-2算法作为最著名的FFT算法,由于其简单的蝶形架构应用于FFT模块的硬件实现,可以降低硬件资源的开销,但是随着FFT点数的增加,它所需要的复杂乘法运算量会变得相当巨大[1]。随后,基-22,基-23,和基-24相继被提出,以上这些算法被统称为基-2k算法[2-4]。基-2k算法具有与基-2算法一样简单的蝶形架构,同时又能够大大降低旋转因子(Twiddle factor,TF)的计算量,因此,非常适合FFT的硬件实现。不过,随着k值的增加基-2k算法的优势变得越来越小,这是由于所能利用的对称子项变得越来越少[5]。而且,高k值的基-2k算法可以用低k值的混合基-2k算法替代,表1为512点混合基-24-23算法和改良基-25算法[6]的详细旋转因子分布。仔细观察表1的旋转因子序列,容易发现如果以W512为轴,将两边的旋转因子互换位置,就会得到同样旋转因子序列的分布。因此,本文的设计方案只考虑当k≤ 4时的基-2k算法。
在以往的研究过程中,不同的FFT架构被提出。在这些架构中,流水线架构由于其较高的吞吐量以及适中的硬件成本得到了广泛的应用。流水线FFT处理器架构一般分为两类:多路径延迟转换(Multi-path delay commutator,MDC)和单路径延迟反馈(Single-path delay feedback,SDF)[7]。MDC架构同时支持M路并行输入数据,数据吞吐量是SDF架构的M倍,但是其对数据路径、FFT点数以及基-2k算法都有限制。另外,MDC架构中所需的存储器和复杂乘法器都比SDF架构多。所以,MDC架构能完成较高数据吞吐率,而SDF架构需要较少的存储器和硬件成本。为了获取更低的硬件开销,本文的设计方案使用SDF架构。
一般来说,对于N点FFT(N>64)都会采用布斯乘法器来处理序列与旋转因子WiN的复数乘法运算。本文提出了一种新型串接CSD常数乘法器来实现序列与Wi128的运算,一方面能够进一步降低硬件资源的开销,另一方面无需任何只读存储器(Read only memory,ROM)对旋转因子常数值进行存储。
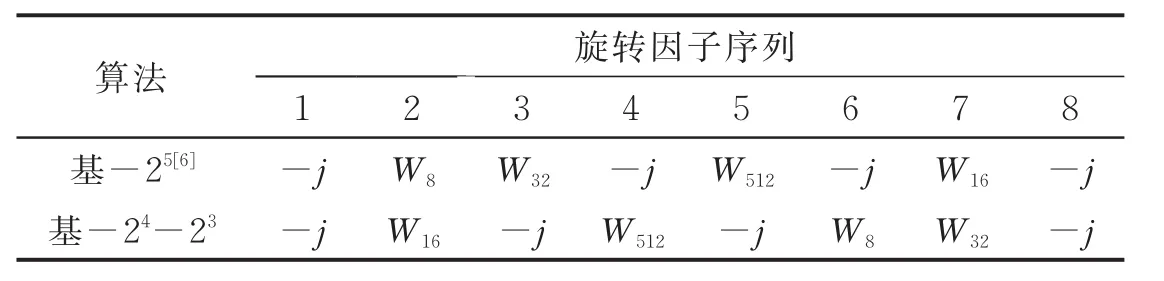
表1 512点混合基-24-23算法和改良基-25算法旋转因子序列分布Tab.1 Sequence distribution of 512-point FFT twiddle factor for mixed radix-24-23and modified radix-25
1 算法选择
利用基-2k算法实现128点FFT包括6个旋转因子序列,表2给出了针对基-2k算法的详细旋转因子序列分布以及复数乘法的运算量。其中-j的运算为普通运算,只需对输入序列实部和虚部的位置进行交换,再对虚部求反即可。
复数乘法运算量可由下列公式进行计算
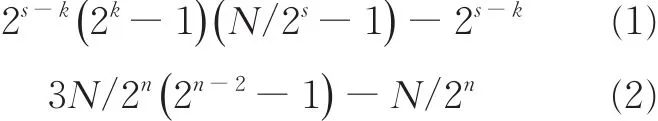
式中:N代表FFT点数;s代表旋转因子所在的阶段;k代表基2k算法的指数;n代表基2k算法所合并出来常数旋转因子Wconstant的指数,例如,基23算法合并出来的W8,其n值为3(2n=8 → n=3)。

表2 128点基-2k算法旋转因子序列分布Tab.2 Sequence distribution of 128-point FFT twiddle factor for radix-2k
以计算基23算法128点FFT为例,其中W8为算法合并出来的Wconstant,需要利用式(2)计算它的复数乘法运算量,而W128和W16为普通旋转因子,其复数乘法运算量用式(1)来计算。因此W8的复数乘法运算量为32,W128的复数乘法运算量为104,W16的复数乘法运算量48。从表2可以看出,混合基-24-23算法拥有最简单的旋转因子序列,同时复数乘法的运算量也是最少的。因此,本文的设计方案采用混合基-24-23算法。
2 设计方案
图1所示为混合基-24-23算法的128点SDF流水线结构图。图中⊗代表复数乘法运算;BFI和BFII代表两种类型的蝶形运算单元;CLK是整个架构的控制时钟,它由7位计数器产生。在整个设计过程中,复数乘法运算都采用CSD常数乘法器来实现。
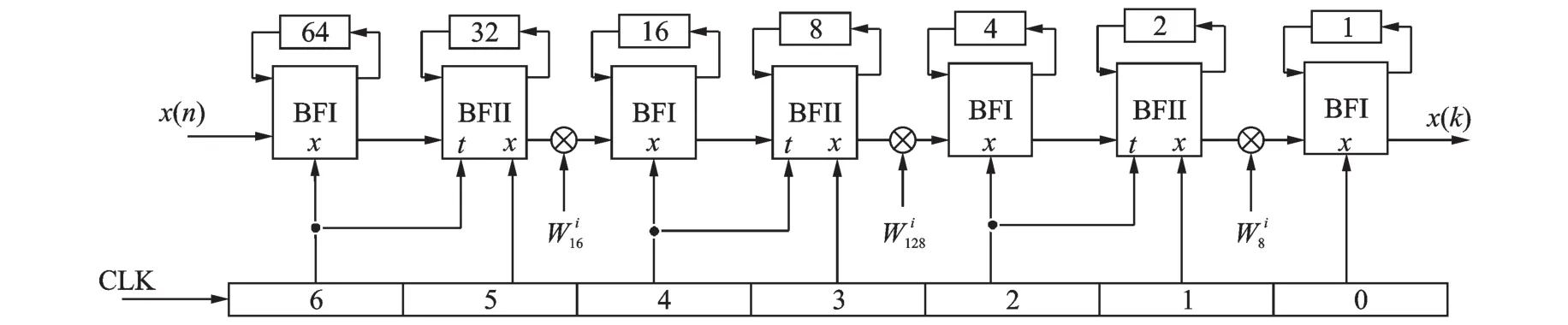
图1 混合基-24-23算法128点SDF结构图Fig.1 Block diagram of 128-point FFT with mixedradix-24-23algorithm
2.1 蝶形单元
图2 所示为两种类型的蝶形单元详细架构,作为FFT处理器中必不可少的部分,主要用来执行复杂的加法和减法操作,图2中的xr(n)和xr(n+N/2)对应与输入复数序列实部,而xi(n)和xi(n+N/2)则对应输入复数序列的虚部。Zr(n),Zr(n+N/2),Zi(n)和Zi(n+N/2)对应于输出复数序列的实部和虚部。值得注意的是,I型蝶形单元对输入序列只进行简单的复数加减法运算,而II型蝶形单元除了需要进行必要的复数加减法运算以外,还需要额外的“-j”运算。因此,在硬件实现上比I型蝶形单元多出了选择单元与相应的控制逻辑电路。
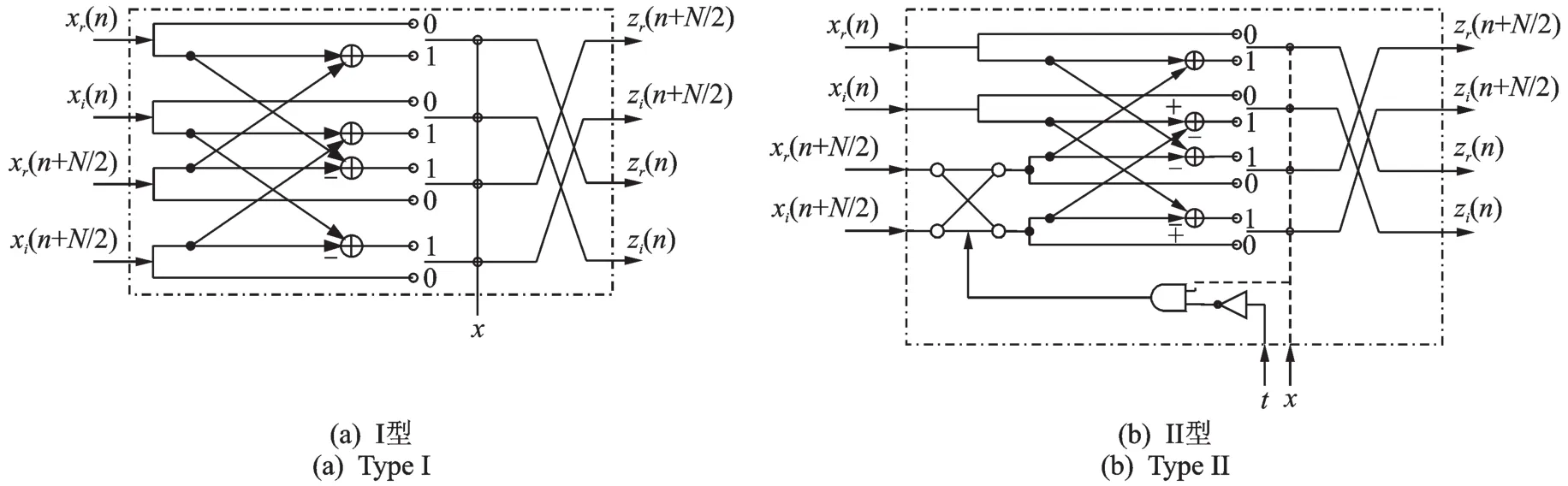
图2 蝶形单元架构Fig.2 Block diagram of butterfly structure

图3 12位字长的CSD表示Fig.3 CSD representation forwith 12-bit word-length

图4 CSD常数乘法器架构Fig.4 Structure of-CSD constant multiplier
表3 旋转因子的7组常数值Tab.3 Sven constant values of twiddle factor
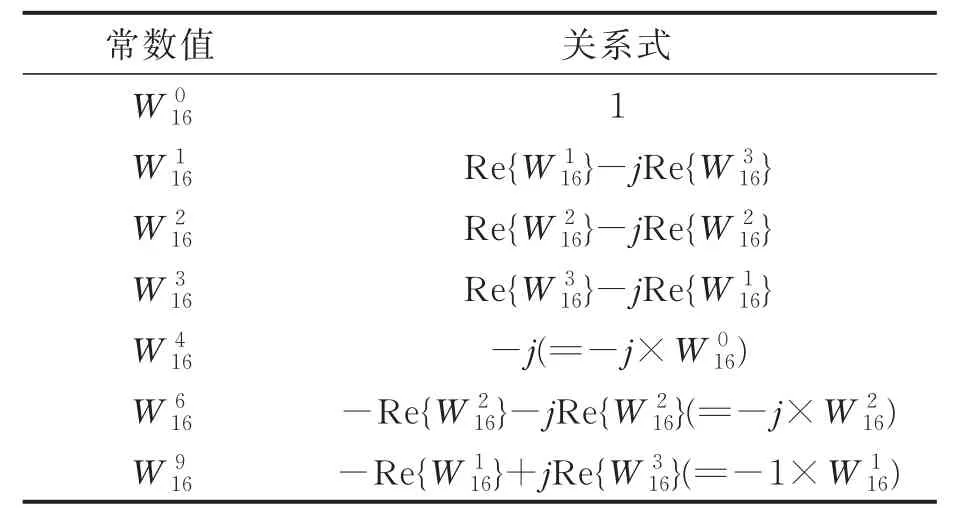
表3 旋转因子的7组常数值Tab.3 Sven constant values of twiddle factor
常数值 关系式W0 16 W1 16 W2 16 W3 16 W4 16 W6 16 W9 16 1 Re{W1 16}-jRe{W3 16}Re{W2 16}-jRe{W2 16}Re{W3 16}-jRe{W1 16}-j(=-j×W0 16)-Re{W2 16}-jRe{W2 16}(=-j×W2 16)-Re{W1 16}+jRe{W3 16}(=-1×W1 16)
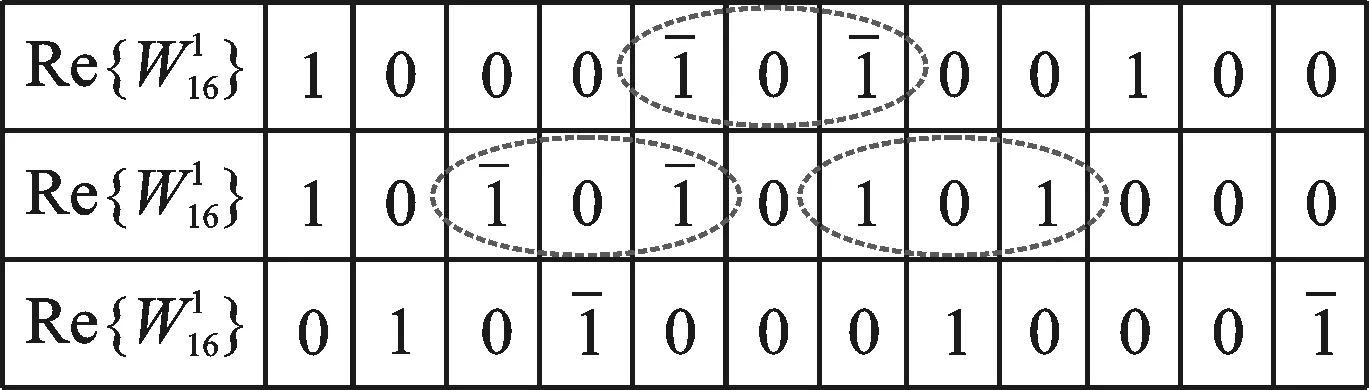
图5 12位字长的CSD表示Fig.5 CSD representation forwith 12-bit word-length
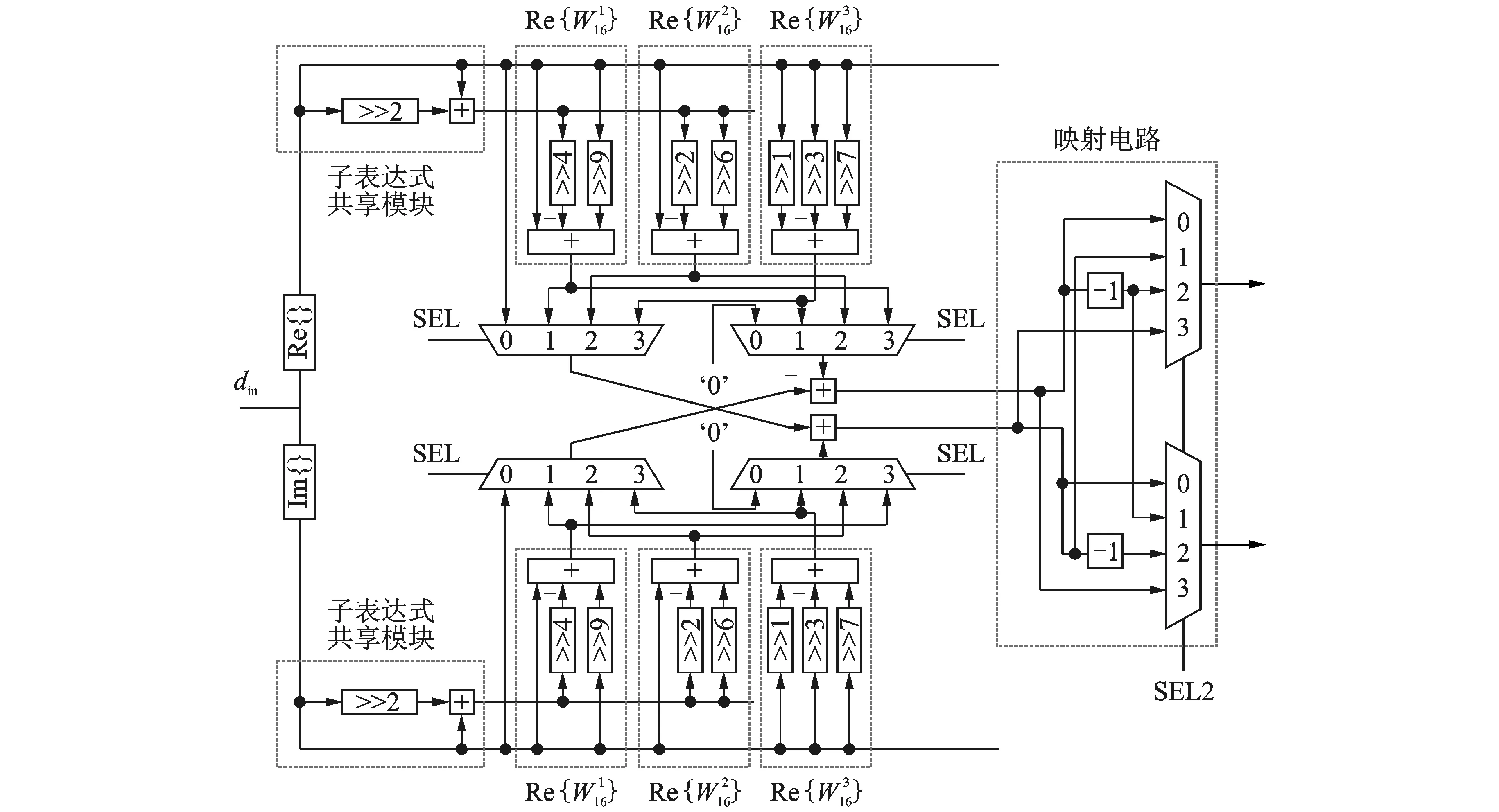
图6 -CSD常数乘法器架构Fig.6 Structure of-CSD constant multiplier
2.4 新型串接CSD常数乘法器单元
图7 所示为旋转因子的1/8特性,根据此特性可将旋转因子的常数值的个数降低为原来的1/8。对于来说,利用此特性,所需旋转因子常数值的个数仅仅为N/8。
一般来说,当旋转因子常数值的个数过多,直接利用CSD常数乘法器处理输入序列与旋转因子的复数乘法运算往往比普通布斯乘法器在硬件资源消耗上更高。因此,为了减少旋转因子常数值个数,提出了新型串接CSD常数乘法器的方案。串接CSD常数乘法器将复数乘法运算拆解成两阶段复数乘法运算,以达到降低旋转因子常数值个数的目的,从而降低乘法器的资源消耗。虽然串接CSD常数乘法器能够减少旋转因子常数值的个数,但是仅仅局限于完成输入序列、旋转因子与,和的复数乘法运算。
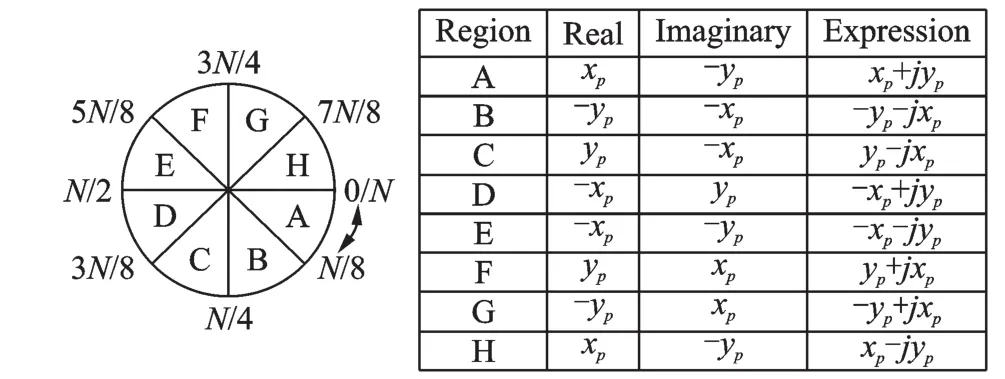
图7 旋转因子对称性映射图Fig.7 Symmetric region mapping of twiddle factor
以本文设计对象128点串接CSD乘法器为例,首先,利用1/8对称特性,将旋转因子常数值的个数降低到16个。然后,对旋转因子的指数i进行分解,分解方案为i=4i1+i2,i1=1~4,i2=0~3,旋转因子常数值的个数由16个减少为8个。如果要实现输入序列与进行复数乘法运算,令i1=3,i2=1(=),输入序列先与进行复数乘法运算,再与进行复数乘法运算,得到最终的输出结果。图8所示为计算旋转因子12位字长的CSD表示,其中椭圆圈起的部分是3组子表达式共享模块:椭圆圈起的“101”,椭圆圈起的“10”和椭圆圈起的“1000”。
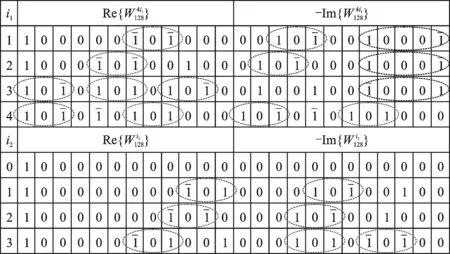
图8 12位字长的CSD表示Fig.8 CSD representation forwith 12-bit word-length
3 结果与比较
本文方案基于QUARTUS PRIME工具软件进行开发,使用Verilog语言进行设计。表4所示为不同方案128点FFT计算量的比较,包括了布斯乘法器使用量,CSD常数乘法器使用量,复数加法器使用量,计算时间以及延迟的比较。本文的设计方案计算时间为6TA+3TMUX+2TN,表4中TA代表加法单元运算所需时间,TMUX代表选择器单元运算所需要时间,TN代表取补码运算所需时间,TM代表乘法单元运算所需时间。由于本文的设计方案只利用CSD常数乘法器来完成复数乘法运算,因此只需考虑加法单元,取补码单元以及选择单元的计算时间。由于乘法单元计算所需时间要高于加法单元计算所需时间。因此,本文方案的计算时间同其他方案一样能够满足128点FFT处理器实时处理的需求。表5所示为不同设计方案逻辑单元使用量,寄存器使用量,记忆体单元使用量和动态功耗的比较。设计的输入字长设置为12位,输出字长设置为22位,器件家族选择的是Cyclone 10 LP,功率评估等级(Power estimation confidence,PEC)为高。编译报告显示,对比于其他方案[8-11],本文的设计方案至少可节省逻辑单元使用量40%,寄存器使用量3%,记忆体单元的使用量14%。同时,基于本文设计方案的128点FFT处理器的动态功耗仅仅为5.59 mW。图10所示为基于MODELSIM RTL级仿真结果(输入序列的实部和虚部设定为1~128),与MATLAB计算的结果一致,证实了本设计方案的有效性。
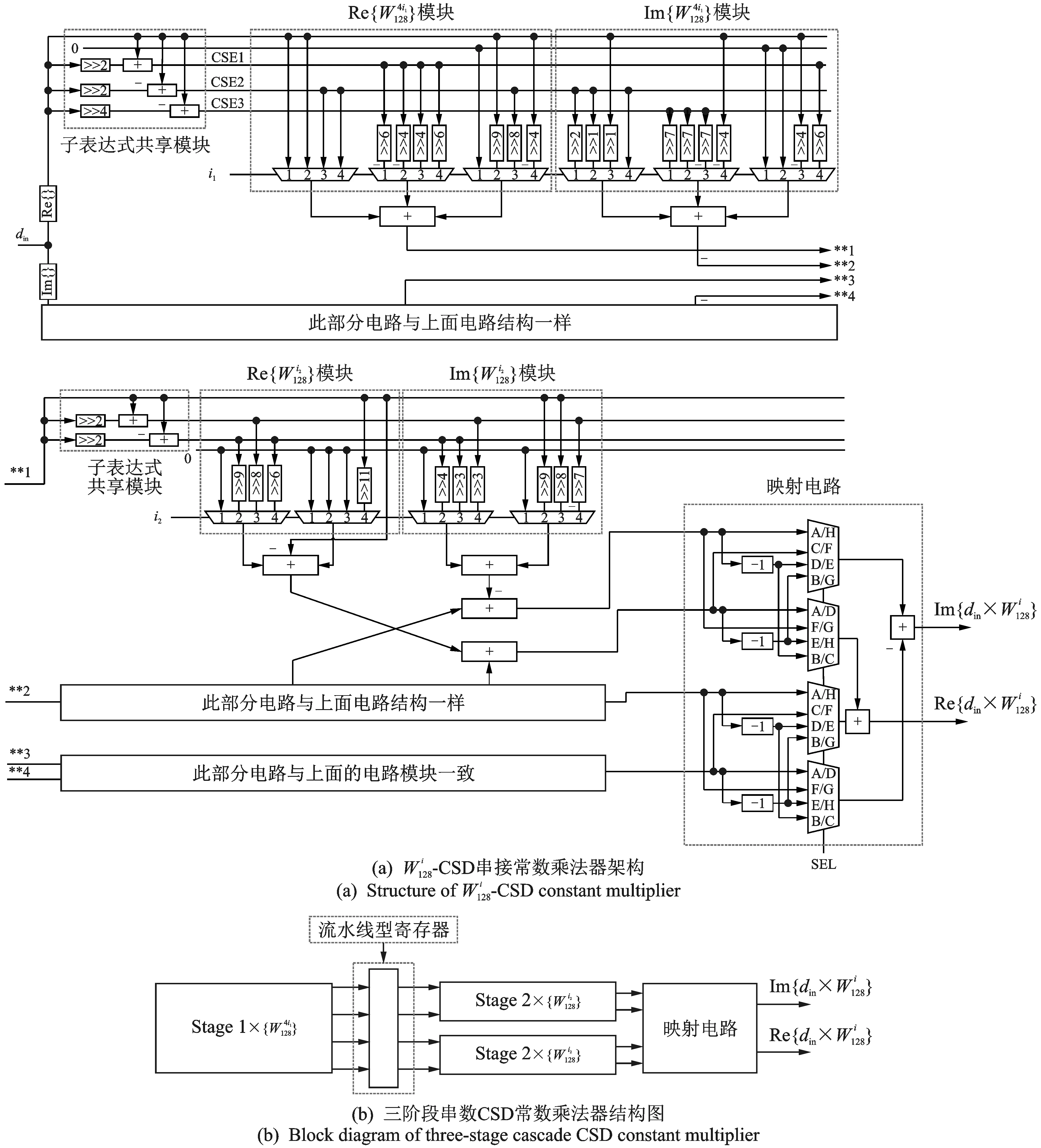
图9 128点串接CSD常数乘法器详细架构Fig.9 Detailed structure of 128-point cascade CSD constant multiplier
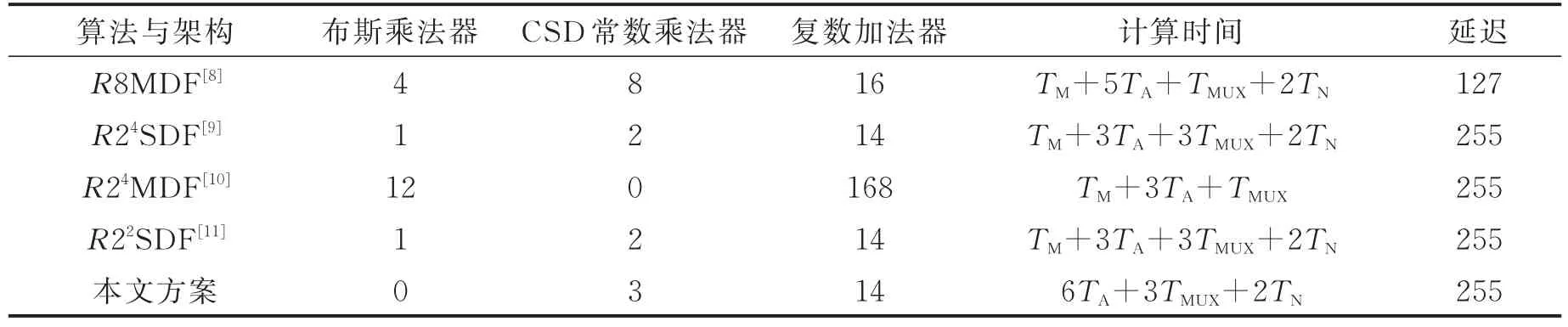
表4 不同方案128点FFT计算量比较Tab.4 Comparison of various schemes computation for 128-point FFT
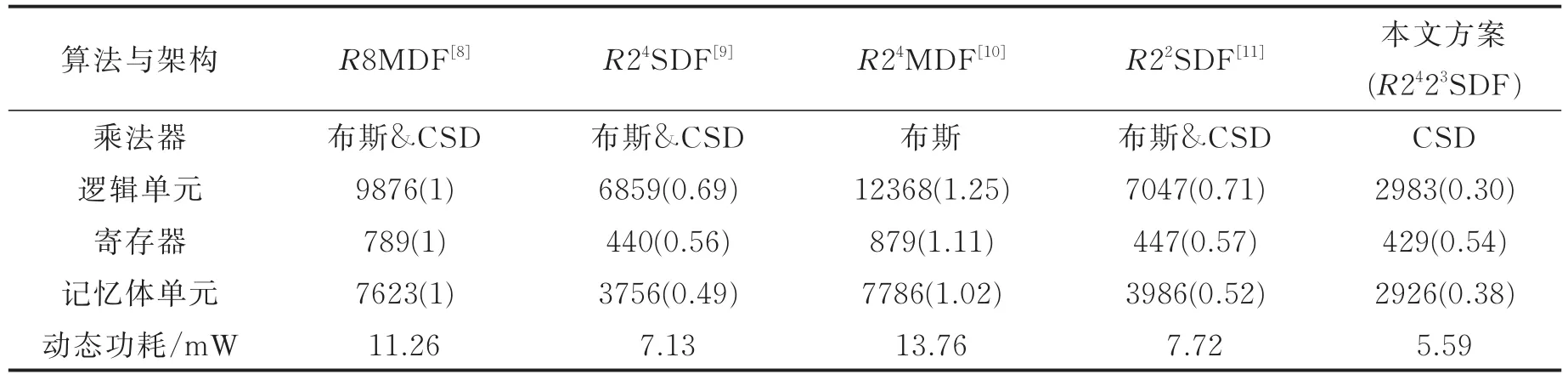
表5 不同方案综合结果比较Tab.5 Performance of the proposed scheme compared with previous implementation
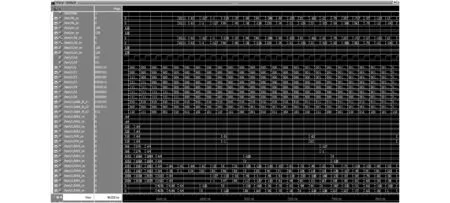
图10 基于本文方案的128点FFT处理器RTL级仿真结果Fig.10 RTL level simulation result of 128-point FFT processor based on proposed scheme
4 结束语
本文针对于128点FFT处理器的设计,算法上采用了混合基-24-23算法,硬件实现上采用了SDF架构,新型串接CSD常数乘法器替代传统的布斯乘法器完成与旋转因子Wi128的复数乘法运算,使得整个FFT处理器的复数乘法运算均由CSD常数乘法器完成,大幅降低了硬件资源消耗和功耗。同时,给出了复数乘法运算量的计算公式,让设计者可以更容易地选择适合的基-2k算法对FFT处理器进行设计。编译报告的结果显示本文的设计方案对比于已存在的设计方案在实现128点FFT上有较大优势。
