基于自适应MCMC和子集模拟的非能动系统热工水力可靠性评估
2019-04-22蒋立志张永发
蒋立志,蔡 琦,张永发
(海军工程大学 核科学技术学院,湖北 武汉 430033)
与能动系统相比,非能动系统驱动力较小,设计参数、初始条件等因素波动带来的不确定性以及对相关物理现象认识的不充分,均可能造成热工水力过程失效、无法实现设计功能。对非能动系统进行热工水力可靠性(TH-R)评估能从可靠性角度增强对非能动系统热工水力过程不确定性的认识,相关分析结果可作为系统性能评估与优化的参考。最初非能动系统TH-R评估主要采用以蒙特卡罗(MC)为基础的模拟方法[1-2],需大量调用系统热工水力模型进行计算,以获取足够的输入、输出数据,但以RELAP5为代表的热工水力程序运行耗时较长,带来极高的运算代价和较低的评估效率。重要抽样(IS)方法的引入[3-4]一定程度缓解了运算代价的问题,但在高维问题中重要抽样密度函数的构造十分困难且存在维数灾难问题[5]。子集模拟(SS)方法[6]适用于高维小失效率模型,它的引入[7-8]在评估效率和稳健性之间带来了一种均衡,其基本思想是将较小失效概率分解为较大失效概率的乘积并依次估计这些条件失效概率。SS中条件失效概率的估计需对各中间失效事件的条件概率密度函数进行精确采样,通常采用修正Metropolis-Hastings(MMH)[9]算法实现。MMH算法中建议分布的选择对算法的效率和失效率估计精度影响很大,最优建议分布的选择较为困难,且随失效率水平的降低算法性能会出现退化。文献[10-11]讨论了Metropolis-Hastings(MH)算法建议分布的最优问题和自适应马尔可夫链蒙特卡罗(MCMC)的合理框架,但相关优化结论针对特定目标分布假设,并不完全适用于子集模拟的中间条件分布。文献[12]基于标准正态空间内的条件采样(CS)算法提出一种适用于SS的自适应MCMC方法,称为自适应条件采样(aCS)方法。该方法在当前链状态和候选样本间引入相关性,避免了建议分布选择的复杂工作[13],能在条件采样过程中直接和灵活地调整算法参数,使候选样本接受率在目标值附近保持稳定,以获取更高的算法效率和失效率估计精度。
本文引入aCS-SS方法,提出一种基于自适应MCMC和SS的非能动系统TH-R评估方法,以某型核动力装置二次侧非能动余热排出试验系统为例进行验证。
1 基本理论
1.1 SS的基本思想
假设系统输入变量的联合概率密度函数为fX(x),则系统的失效率PF为:
(1)
式中:x=(x1,x2,…,xn)∈Rn为输入参数向量,Rn为n维输入参数空间;F为失效域;IF(x)为示性函数,x∈F时IF(x)=1,否则IF(x)=0。采用MC方法时系统失效率的估计值为:
(2)

(3)
式(3)中条件失效概率的估计值为:
(4)
式中,fX(x|Fj-1)=fX(x)IFj-1(x)/P(Fj-1)为x落入Fj-1内的条件概率密度函数。由于F0是一个必然事件,P1的计算可采用标准的MC模拟进行。当j≥2时Pj的估计需根据条件分布fX(x|Fj-1)进行采样,高效的条件采样是SS的核心。
1.2 基于MMH算法的SS
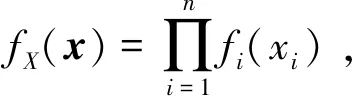

3) 重复上述步骤,直至样本数量满足要求。

1) 设定各层的样本数N及条件失效概率p0,应该尽量保证p0N为正整数。
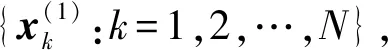



1.3 CS的基本原理


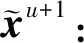
上述基于CS算法的MCMC策略其稳态分布渐进收敛于条件分布fX(x|Fj-1),文献[12]给出了详细的证明过程。CS算法的效率和性能仅依赖于相关系数ρi的选择,与MMH算法相比避免了建议分布形式、参数的选择,避免了预候选样本的接受/拒绝过程,算法形式更加简洁、灵活,运算代价更低。但针对不同的系统类型和失效率水平,如何合理选择相关系数ρi依然是一个困难的问题,较高和较低的相关系数均会导致条件样本的相关性过高,降低算法效率和估计精度。
1.4 基于aCS的子集模拟
文献[10-11]的相关研究表明,目标分布为一维正态分布时MH算法存在一近似的最优接受率a*≈0.44,文献[15]的算例表明SS中MMH算法的最优接受率在0.3~0.5之间。CS算法中候选样本的接受/拒绝仅依赖于系统极限状态函数的响应,因此从条件分布fX(x|Fj-1)采样可等效为一维条件采样问题,文献[12]提出一种aCS方法,能使候选样本接受率较稳定地保持在目标值附近。利用aCS算法从条件分布fX(x|Fj-1)采样的详细流程如下。

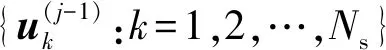
2) 自适应迭代过程:令迭代次数r=1,2,…,Ns/Na,重复执行以下步骤。
(1) 根据标准差初值σ0i和当前尺度参数λr计算相关系数:
σi=min(λrσ0i,1)
(5)
(6)

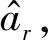
(7)
(8)

2 算例分析及结果讨论
本文以某型核动力装置二次侧非能动余热排出试验系统[16-18]作为算例验证aCS-SS算法的有效性,系统原理如图1所示。采用文献[16]建立的热工水力模型并选择启动工况5为运行工况进行分析,该模型使用RELAP5/Mod3.2作为建模工具。由于缺少充足的试验数据和运行经验,通过专家分析及工程判断方法识别影响系统热工水力行为的32个不确定性输入参数,参数分布类型列于表1。由于试验系统未模拟反应堆一回路,因此选择关注的系统输出为系统运行期间(20 000 s)冷凝器管侧压力峰值pMAX:若运行期间pMAX不大于管道所能承受的压力上限值pm,则认为蒸汽发生器模拟体中的热量能被成功排出至冷却水箱,即g(x)=pm-pMAX<0时系统功能失效,否则系统功能正常。

图1 非能动余热排出系统原理简图Fig.1 Simplified figure of passive residual heat removal system

表1 不确定性参数分布类型Table 1 Distribution type of uncertainty parameter
注:N表示正态分布,U表示均匀分布
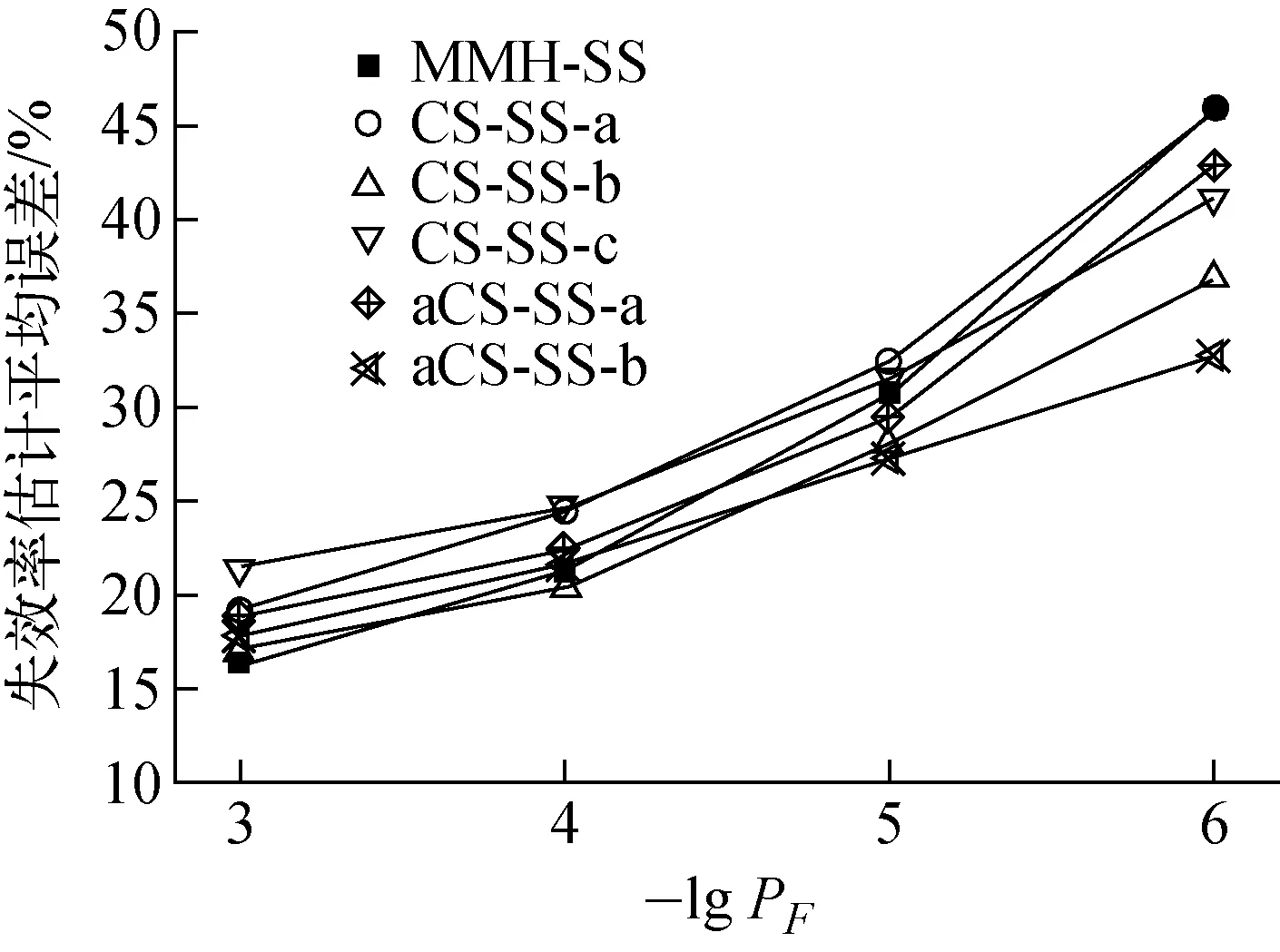
为比较不同失效率水平下的算法性能,设置4组压力上限值pm1 1) MMH-SS:采用MMH算法产生条件样本,建议分布选取为正态分布,其标准差根据种子样本计算得到。 2) CS-SS:采用CS算法产生条件样本,为分析不同相关系数对失效率估计精度的影响,各分量相关系数取3种配置:ρi=0.7、ρi=0.8、ρi=0.9,分别记为CS-SS-a、CS-SS-b和CS-SS-c。 3) aCS-SS-a:采用aCS算法产生条件样本,标准差初值取σ0i=1,尺度参数初值取λ1=0.8。 4) aCS-SS-b:采用aCS算法产生条件样本,标准差初值根据种子样本计算得到,尺度参数初值取λ1=0.8。 由于a*≈0.44是在目标分布为一维正态分布的假设下获得的结论,并不完全适用于本文所评估的系统。经过测试,系统失效率为1.94×10-3时MMH-SS算法的候选样本接受率约为0.5,且失效率估计精度较高,因此将aCS-SS的目标接受率设定为a*=0.5。设定N=1 000、p0=0.1,在不同失效率水平下,利用4种策略各进行100次失效率估计,各策略下采用相同的100个随机数种子。最终得到整个SS过程中候选样本的平均接受率随失效率水平的变化,如图2所示。失效率估计平均误差随失效率水平的变化如图3所示,失效率估计平均变异系数(SS变异系数的近似估计方法参考文献[7,13])随失效率水平的变化如图4所示。 图2 平均接受率随失效率水平的变化Fig.2 Average acceptance rate plotted against varying failure probability level 图3 失效率估计平均误差随失效率水平的变化Fig.3 Average error of failure probability estimate plotted against varying failure probability level 图4 失效率估计平均变异系数随失效率水平的变化Fig.4 Average coefficient of variation of failure probability estimate plotted against varying failure probability level 由图2可知:随系统失效率水平的不断降低,4种估计方法的平均接受率均有所下降,但aCS-SS-a和aCS-SS-b能使接受率在目标值附近保持稳定水平;CS-SS的平均接受率与相关系数的取值有直接关系,相关系数越大平均接受率越高,反之亦然。结合图3、4的结果可知:随失效率水平的降低,4种方法的平均估计精度均降低、平均变异系数均增大,这是由于较低失效率水平下失效区域非常狭小,有效的条件采样变得更加困难;失效率处于较高水平时4种方法精度差别不大,但失效率处于较低水平时aCS-SS-b的平均精度最高、平均变异系数最小;CS-SS算法中相关系数ρi取不同值时失效率平均估计精度和平均变异系数变化剧烈,对于本文算例ρi=0.8时失效率平均估计精度较高、变异系数较大,但在实际工程应用中对于不同的研究对象很难准确地找到一个比较合理的相关系数取值;与aCS-SS-a相比,aCS-SS-b的平均精度更高、变异系数更小,这是由于aCS-SS-b中标准差初值σ0i由种子样本估计得到,这一过程本质上是对失效区域的一种自适应探索,当各输入参数对系统性能的影响不相同时aCS-SS-b的性能必然高于aCS-SS-a,但当各输入参数对系统性能的影响基本相同时二者的性能无明显差别。 SS的失效率估计精度取决于各子集边界的准确划分和条件失效域的高效采样。采样过程中候选样本接受率过低或过高,均会导致条件失效样本间相关性较高、重复样本较多,最终导致各子集边界划分出现偏差以及最后一层子集的失效率估计误差增大。在失效率为2.90×10-6的水平下,分别利用MMH-SS、CS-SS-b、aCS-SS-a和aCS-SS-b进行1次失效率估计,第2~6层子集对应的候选样本接受率变化列于表2。由表2的变化规律可看出:随各子集的逐渐划分,候选样本接受率逐渐降低,这是由于后续子集对应的区域越来越狭小、采样也越来越困难;MMH-SS和CS-SS算法中各子集接受率的降低较为剧烈,这是因为各子集的条件采样使用的均是相同的策略或相关系数;aCS-SS中接受率的下降较为缓慢,即使在最后一层子集也能保持接近0.5的水平,这是由于aCS-SS的自适应调节过程可令各子集对应的相关系数逐渐增大,特别是aCS-SS-b中对失效区域的自适应探索过程还可使各输入参数对应的相关系数随参数重要度的不同自动调节。 表2 各子集候选样本的接受率Table 2 Acceptance rate of candidate sample for each subset 本文引入一种基于aCS的自适应MCMC算法,提出一种基于自适应MCMC和SS的非能动系统热工水力可靠性评估方法,以某型核动力装置二次侧非能动余热排出试验系统为算例进行验证,对4种估计方法的性能进行了比较。计算结果表明:aCS-SS避免了MMH-SS中建议分布形式和参数的选择,算法形式更加简洁、灵活,算法中的参数可自适应调整以保持稳健性;aCS-SS能更好地使候选样本接受率在目标值附近保持稳定水平,在较低失效率水平(10-5、10-6)下aCS-SS的估计精度和稳健性均高于目前常用的MMH-SS算法。随非能动技术的不断发展、运行经验的不断积累以及各类非能动安全系统的不断改进,反应堆非能动系统的物理过程失效会进一步降低,本文方法对于较低失效率水平下非能动系统TH-R评估问题是非常有前景的。


3 小结
