分布式异构数据库数据同步工具∗
2019-04-18徐梓荐
徐梓荐,叶 盛,张 孝
1(教育部数据工程与知识工程重点实验室(中国人民大学),北京 100872)
2(中国人民大学 信息学院,北京 100872)
关系型数据库的数据存储方式一般有行式存储和列式存储两种.对于行存储数据库,支持海量数据的高效更新,然而,当需要分析数据库中隐含的信息时,就可能会涉及一些针对数据库表中某一或某些属性上的聚合,而这是行式存储数据库的不足.列式存储数据库对于海量数据更新没有很高的处理效率,而对数据分析,特别是在某些属性上进行分析,往往有很好的查询优势.如果能够构建由行列数据库共同组成的分布式数据库系统,用行存储数据库接受来自业务线的数据,再通过数据同步将这些数据同步到列存储数据库中进行数据分析,就可以弥补数据库的上述不足,为真实的业务场景提供一个优化的解决方案.
本文以 MySQL为对象,开展基于该数据库的数据同步技术研究工作,主要实现了一款基于数据库 Binlog的分布式数据库中的数据同步工具 Cynomys.鉴于当前并没有一种针对行存储数据库到列存储数据库的实时同步工具,本文提出了一种基于SQL还原的实现方法,利用标准的SQL语句避免底层数据库引擎差异可能导致的无法进行数据库同步的问题.
本文的主要贡献包括:(1) 设计并实现了Binlog解析器BinParser以及还原器BinReducer,解析器解析并获取Binlog的日志信息,还原器将BinParser解析的日志内容还原为可执行的SQL语句;(2) 提出了基于BinParser和 BinReducer的异构分布式数据同步方法 TD-Reduction,并开发了基于 TD-Reduction的数据同步工具Cynomys;(3) 针对ColumnStore的存储结构提出了延迟提交(delay commit)的优化技术;(4) 本文针对Cynomys的性能、功能等方面做了大量实验,结果表明该工具有效且能够正常运行.
1 相关工作
对于分布式架构的数据库及其数据同步解决方案,研究人员提出了若干种体系架构以及基于此的各类问题的解决方案,如:Stonebraker提出了一种广域的分布式数据库系统[1],Chen等人提出了一种基于分布式数据库的在线数据分割方法[2],Google开发了可扩展、多版本、全球分布式和同步复制的数据库Spanner[3],Wang等人提出了基于中间件的分布式数据同步技术[4].
在商用数据库中,Oracle和SAP HANA都提出了解决异构数据存储的方案.其中,Oracle在其12c版本中加入了解决异构数据存储问题的新特性In-memory Option[5].在12c版本以前,Oracle所有的数据都是以行形式进行存储的.该特性引入后,Oracle允许用户将指定的表空间内所有的表以列形式存储在单独开辟的一块内存空间In-memory Area中[6],从而在查询分析数据时,对涉及某些属性上聚合的查询操作速度加快,并且这种双格式架构多占用的内存开销被控制在单一格式架构内存开销的20%以内[7].SAP HANA是混合型的内存数据库,它同时支持行存储以及列存储[8].与 Oracle不同的是,它需要在创建新表时指定行式或列式存储,两种不同的存储架构使用不同的存储引擎.这两种商用数据库的方案是针对行列存储数据库有不同的优势所提出的数据存储方案,而Cynomys则是将行存储数据库中的数据实时同步或者迁移到列存储数据库中,与以上两种异构存储的方案定位不同.
当前,常规意义上的数据迁移已经发展得较为成熟,解决方案也已经较为明确,例如基于负载均衡的数据迁移方法[9].而数据同步可以看做是实时的数据迁移过程.一般的数据同步可以基于数据库日志[10,11]、触发器[12]等,其中,以日志法最具代表性和可行性.然而由于不同数据库的日志格式差别很大,可供日志分析的接口也有所不同,所以基于日志法的数据同步也局限于同种数据库,甚至要求版本相同或相近,这限制了数据同步技术的发展.有人曾提出使用SQL还原的方法[13],但该方法是基于SQL Server触发器实现的,人工干预程度大、维护困难.Cynomys的基于标准SQL语句进行数据同步的方法受到该工作的启发.
在分布式环境下,许多数据库或分布式系统如Google的Chubby,MegaStore,Spanner,Hadoop中的Zookeeper等,都依赖Paxos算法[14]来保证不同结点之间事务的一致性.Cynomys是一款数据同步工具,是从主数据库(行存储数据库)到从数据库(列存储数据库)的数据同步,需要保证的是同步操作前后数据的一致性,而非同步过程中事务同步执行的一致性.
MySQL提供了 Group Commit机制(https://dev.mysql/com/doc/refman/8.0/en/commit.html),在 MySQL的InnoDB引擎中,为了保证数据库的事务持久性不被破坏,在每个事务被提交之前都会先刷redo日志,而redo日志是要刷到磁盘上的,在多事务并发的情况下会造成性能的瓶颈.总的来说,Group Commit是将多个并发的事务一次性写入日志来减少 I/O,而 Cynomys的延迟提交机制是将一段时间内多个实现类似功能的事务合并在一起,以减少列存储数据库数据文件的访问,从而提升同步性能.
2 Cynomys的关键技术
2.1 二进制日志Binlog
Binlog的全称是Binary Log(https://dev.mysql.com.doc/internals/en/binary-log-overview),即二进制日志文件,是备份的基本要素之一,对于基于时间点的恢复更是必须的.一般而言,日志会比数据小很多,更适合于需要频繁备份的场景.MySQL的Binlog从记录格式上可以分成3种类型:Statement,Row,Mixed.其中,Mixed格式默认以Statement格式作为记录格式,针对Statement格式不能准确描述的数据变化再以Row格式进行记录,综合了两者的优点,适于本文的场景,即:在不依赖Master节点具体环境的情况下使用Statement格式,在依赖Master节点具体环境的情况下使用Row格式,保证基于Binlog的业务可以快速准确地开展.
2.2 Binlog解析器BinParser
Binlog提供的事件(event)类型复杂多样,对各种事件归纳出若干种有重要特征的基本事件,针对这些事件再进行下一步的处理.本文将 28种事件类型归纳为 10种基本事件类型,并为每种基本事件类型设置相应的属性,使得每种事件类型可以完整准确地表述自身的信息,10种基本的事件类型及其描述见表1.

Table 1 10 types of basic event表1 10种基本的事件类型
基于上述对Binlog事件类型的综合归类,形成了本文的解析规则算法.由于事件种类繁多,处理过程中难免会出现过多的分支.为了避免这种情况,在设计算法时本文采用了数据驱动[15]的编程方式.BinParser的算法伪代码见算法1.
算法1.解析器(BinParser)算法.
输入:Binlog;
输出:Stringlog_info.


2.3 Binlog还原器BinReducer
Cynomys对Binlog的还原遵循最简原则.所谓最简原则,即对于Mixed格式中的Statement日志直接还原为原SQL语句,对于Row日志还原为能表述日志内容的最简单的SQL语句(如图1所示).

Fig.1 Flow chart of Binlog reduce图1 Binlog还原示意图
日志还原器BinReducer的算法伪代码见算法2.
算法2.还原器(BinReducer)算法.
输入:Stringevent;
输出:StringSql.

具体还原步骤如下.
1) Cynomys监听Master节点的数据变化,并依据第2.2节的解析规则对Binlog信息进行实时解析;
2) 针对不同的事件类型分别进行还原;
3) 对于QueryEvent,其中涵盖了具体执行的SQL语句,实际上是以Statement格式记录的日志信息,对此可以进行直接还原;
4) WriteRowsEvent,UpdateRowsEvent,DeleteRowsEvent等几类事件,需要经过一定的处理,将其还原为SQL语句.
总的来说,根据最简原则来进行 SQL还原的时候,如果事件信息中包含具体的 SQL语句,那么直接提取出SQL语句即可,如下面这个例子.
日志示例1

该事件中包含SQL语句,将该行insert into test(a) values(2)直接提取出来即可(对应算法2的第1行、第2行).如果没有具体的 SQL语句,那么根据事件的类型信息以及包含的具体数据,将 SQL语句还原成 INSERT,UPDATE或者DELETE等DML语句即可(对应算法2的第4行~第6行),举例如下.
日志示例2

该事件是WRITE_ROWS_EVENT,但该日志内没有能够直接提取出来的SQL语句,这种情况则需要通过正则表达式提取出事件信息中数据的变化,还原成原始或等价的SQL语句.该事件能够还原出以下SQL语句:
insert into test values(1,‘c’), (2,’c’)
2.4 延迟提交
2.4.1 ColumnStore存储模式
不同的数据库引擎有不同的存储模式,而根据存储模式的不同,对目标数据库的存储结构可以优化数据加载的策略.行存储主要应用在一些事务型数据库,如 Oracle,MySQL,PostgreSQL等;而列存储主要应用在分析型数据库上,如 Mariadb ColumnStore,MonetDB[16],Infobright等.本文要解决的主要问题是从 InnoDB到ColumnStore引擎之间的数据同步,ColumnStore的存储结构如图2所示(https://mariadb.com/kb/en/library/columnstore-storage-architecture/):
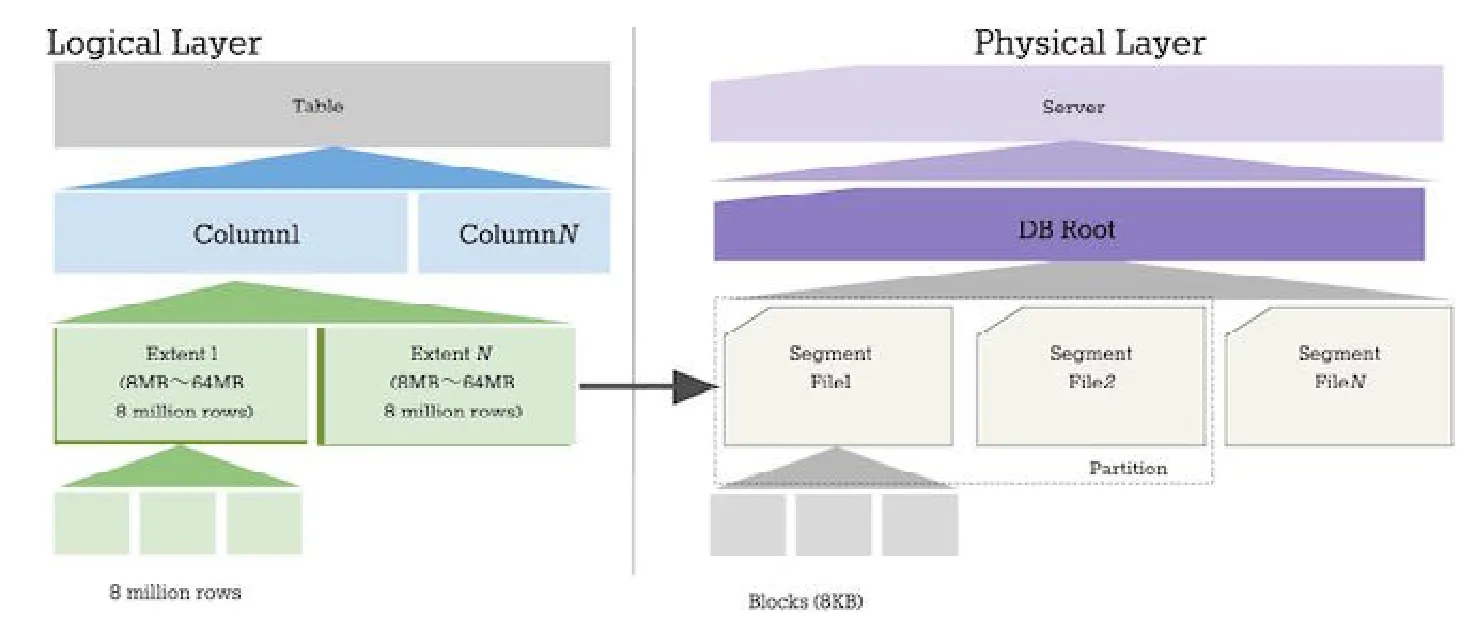
Fig.2 Structure of ColumnStore图2 ColumnStore存储结构
2.4.2 Delay思想
由于ColumnStore等列存储引擎的特殊存储架构设计,对于行存储架构支持完善的SQL语句就会带来同步速度不匹配造成的性能瓶颈等问题.
假设存在表Student(见表2),并且需要执行以下插入语句:
INSERT INTO Student (StuId, Lastname, Firstname, Score) VALUES (4, Lucy, Alex, 100);
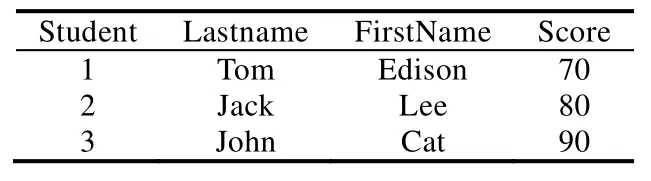
Table 2 Example of Student table表2 示例Student表
在行存储数据库中可以发现:插入一行新的数据十分简单,只要再添加一条完整的记录就可以,对于之前的记录毫无影响.Student表信息在行存储数据库中存储,那么其逻辑结构就如图3所示的结构.而对于同样的Student表,如果存在列存储引擎中,那么其逻辑结构如图4所示.在执行例子中的INSERT语句时,将会涉及到表中的每一列数据,首先取出 StuId所在的数据块,插入新数据“4”,然后再取出 Lastname所在列,插入新数据“Lucy”,以此类推.而列存储引擎在通常情况下都会对数据进行压缩,每更新一次数据都会导致数据的解压缩与再压缩操作;同时,列存储数据库作为分析型数据库,通常每张表都有较多的字段.可想而知,通过常规插入手段的性能是极差的.而当用户基数大,用户操作零散,在一些峰值情况下会产生大量用户同时访问一张表的情况,如果以先来先服务的形式逐一满足用户的请求,尽管主库的数据一定会同步到备库中,备库的同步效率将会由于主库的零散插入行为而大幅降低.

Fig.3 Example of row-based database图3 行存储数据库数据组织示例

Fig.4 Example of column-based database图4 列存储数据库数据组织示例
图5是一般的同步处理过程,基本是一语句一提交.以这种方式进行事务提交,直接导致区间(extent)处在不断的解压缩与压缩的状态,降低了同步效率,在主库InnoDB达到查询峰值的时候,备库ColumnStore基本属于瘫痪状态.基于行列存储的差异,必须提出一种新的思路,以解决SQL语句在处理列存储数据性能不足的问题.
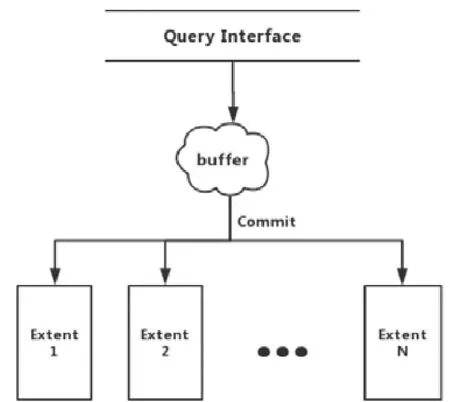
Fig.5 Flow chart of query processing图5 一般查询处理流程图
MySQL的Group Commit目的是为了在并发的情况下通过将待commit的事务分组刷到redo日志中来减少I/O,而延迟提交则是为了缓解行存引擎和列存引擎在数据插入性能上的差异.通过binlog来进行行列同步的过程中,如果不引入延迟提交机制,那么行存作为数据源产生 binlog的速度会远远高于列存能读取 binlog的速度.
假如将行存看做生产者,列存看做消费者,那么正常情况下,消费者是没有办法去完成消费生产者的内容的,这就导致消费者始终处于忙的状态,且与binlog的差距越来越远.延迟提交机制的实质是通过将大量的待提交的插入事务进行缓存,待到缓存区域达到一定的数据规模的时候再对这一批数据进行统一同步,通过一次解压操作,将各列待插入的数据追加到相应的Extent中去.
举例来说,假如行存有3个事务,都是往同一个表中插入数据.

对于行存储数据库来说,进行这3个事务的提交很快就能完成.但是对于列存储数据库来说,提交3个事务远比提交 1个事务的代价高得多,因为列存储数据库的存储结构与行存储数据库有本质区别.为了避免类似事务多次提交,延迟提交机制就是将一段时间内对同一表进行的操作进行归并.比如,例子中的3个INSERT语句等同于以下语句:
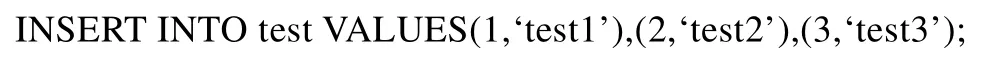
这样就可以减少对列存储数据文件的访问次数和解缩/压缩次数,提高列存吞吐量.
如图6所示,Query Interface负责接收外界待插入的数据,在当前事务提交之前,Column Buffer会将数据进行缓存,缓存的大小由用户根据实际需求决定.

Fig.6 Flow chart of delay commit图6 延迟提交流程图
相较于图4所示的单语句提交的方式,延迟提交解决了列存储数据库由于存储模式限制导致插入性能较差、在交易高峰可能导致瘫痪的风险.以批量的形式进行语句提交,减少了存储引擎与磁盘的 I/O,也降低了ColumnStore本身的压缩与解压缩频率,满足了现实的交易场景.
2.5 数据同步正确性分析
对于数据同步工具来说,保证数据同步操作完成后目标数据库(列存储数据库)表数据与源数据表中数据的一致性是最为重要的指标.下面简单分析数据同步的正确性.
数据同步分为两种情况.
· 第1种情况是只有一个用户(进程).从实现的角度看,Cynomys实际上是设置了一个监听器(listener),实时地监控日志文件的变化,一旦日志文件新增了事件,监听器就会将这个事件捕捉并发送给解析程序BinParser,然后执行后续的 BinReducer等操作.如果用户的请求中包含对同一表的 INSERT操作过多,Cynomys会采用延迟提交机制,在不超过Buffer Size的情况下,将这些INSERT语句保存到缓冲区中一起执行.单用户情况下,数据同步的正确性实际依赖的是BinParser的解析以及BinReducer还原的SQL语句的正确性,只要上述步骤中的各个环节没有错误,最后还原的SQL是正确的语句,同步到从数据库中的数据就是正确的;
· 第 2种情况是多用户(进程)并发的情况.多用户并发的情况下,不同的进程会同时向日志写入事件.Cynomys对日志监听并还原 SQL是一个串行的操作,即使多用户同时并发操作,解析事件的顺序与Cynomys监听到日志的顺序相同.即使并发的情况下,也不会影响数据同步的准确性.
算法3.延迟提交算法.
输入:Buffer_Size,Query;
输出:null.

3 Cynomys整体架构及实现
3.1 总体架构
系统的架构总体分为日志解析、日志序列化、消息传递、SQL执行等几个主要模块.
Cynomys是一个典型的“生产者-消费者”模型,日志解析模块就是整个工具的生产者,消息传递模块充当缓冲区的作用,而最终的SQL执行模块则是最后的消费者,如图7所示.

Fig.7 Whole architecture of Cynomys图7 Cynomys整体架构图
日志解析模块的作用是读取并解析日志,将日志内容还原为SQL语句;序列化模块的作用是为还原出来的SQL语句提供序列化支持;数据压缩加密模块的目的是应对可能出现的带宽不足及网络攻击等问题;消息传递模块主要是为了使消息能够按照既定的顺序或者规则进行传递,保证下游的应用不会因为消息传递不合理导致的错误;SQL执行模块的作用是将先前模块中得到的信息进行解压缩、反序列化等操作,将还原出来的SQL语句在目标数据库中执行,达到数据同步的效果.
3.2 日志解析模块
在第2.1节中已经提到MySQL的Binlog属于二进制文件,本身并不具有可读性,因此对基于Binglog的异构数据库同步,需先将Binlog中的内容解析成目标数据库可执行的相关内容.
首先从日志解析模块就进行事件的分类处理,Binlog解析器的一级子模块可以分为 RotateEventParser,QueryEventParser和WriteEventParser这3个部分,分别解析更换binlog文件事件、解析statement的事件以及数据更新相关的事件.根据解析出来的事件类型,EventFilter会将所有的事件分成更详细具体的事件类别,EventListener监听器会实时监听MySQL-Master节点的日志内容变化并通知业务线.具体解析流程如图8所示.
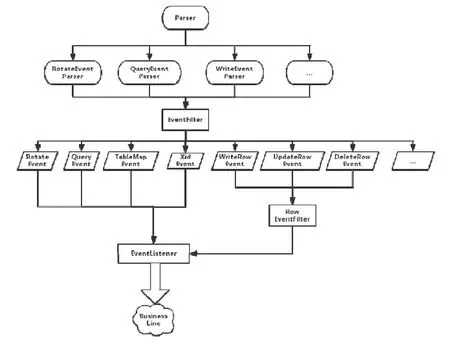
Fig.8 Flow chart of Binlog parser图8 Binlog解析器解析流程图
3.3 序列化模块
数据或者对象状态在分布式系统中的传输不可能直接以字符串的形式存在,必须根据一定的模式对数据进行序列化[17].
支持序列化的工具或方法有很多,例如Avro,Protocol Buffer,JSON等.Cynomys中选用Apache Avro作为序列化工具,主要是由于 Avro具有支持多样数据结构、可持久化、支持 RPC(远程过程调用)、能够与动态语言简单结合等特点.JSON在Avro中用来定义序列化模式文件,使用Avro的关键在于定义消息的模式,只要定义好消息模式并编译保存,Avro就会根据定义的模式进行相应的序列化和反序列化.
在Cynomys中,定义一个JSON格式的模式如下所示.

在JSON定义的模式中,分别定义了一条消息的几个域,为简洁明了表述消息内容,选择事务 ID(tid)、涉及的数据库名(database_name)、涉及的表名(table_name)以及还原出来的SQL语句(SQL).经过序列化模块产生的序列化文件会被传送到下一个处理模块进行进一步处理,序列化具体的流程如图9所示.

Fig.9 Flow chart of serialization based on Avro图9 基于Avro的序列化操作流程图
3.4 其他模块
除前面提到的日志解析模块和序列化模块外,Cynomys还包含数据压缩加密、消息传递、SQL执行等模块.在数据压缩加密模块中,本文所采用的GZip数据压缩算法[18],用AES算法对压缩包进行加密,RSA算法对AES算法的密钥进行加密,与被加密的压缩包一起发送到消息传递模块.数据压缩加密模块的流程如图10所示.在消息传递模块中,本文选择Redis作为消息队列,基于Redis实现消息的发布/订阅(简称Pub/Sub)模式[19].利用发布/订阅模式,解决了被压缩加密的消息包可能在网络传输过程中丢失或者消息发送方和接收方处理效率不一致带来的延迟等问题.

Fig.10 Flow chart of compression and encryption图10 数据压缩加密模块流程图
来自消息队列中的消息,需由消费模块对消息进行解密、解压缩并反序列化后使用消息.Cynomys不会直接执行消息中的SQL语句,而是根据情况决定是否启用延迟提交机制.
4 实验评估与分析
本节内容旨在检验Cynomys的可用性、高效性、兼容性和正确性.在可用性实验中,主要验证Cynomys对数据库基本操作的支持度以及Cynomys本身的稳定性;在高效性实验中,主要验证了延迟提交机制下Cynomys的INSERT性能;在兼容性实验中,主要验证了Cynomys的数据库兼容性和运行平台的兼容性;在正确性实验中,主要验证了多个事务并发情况下Cynomys同步数据的正确性.
4.1 环境配置
Cynomys的功能实验、性能实验在两台服务器上运行,其中,主服务器运行 MySQL等行存储数据库,备份服务器运行MariaDB ColumnStore等列存储数据库.所有实验的测试数据均采用TPC-C或TPC-H基准测试数据集.具体的实验环境参数见表3.

Table 3 Configurition of experiment表3 实验环境配置
4.2 功能实验
4.2.1 数据类型支持度
数据库基本数据类型是支撑表元素的基础,Cynomys对数据类型的解析是根据MySQL写日志的规则,不同的数据类型对应不同的 ID,对字符串类型和非字符串类型分别解析.本文对 MySQL的各个基本数据类型都进行了相应的测试.实验结果表明:Cynomys能够完全支持 MySQL的基本数据类型(MySQL的基本数据类型:https://dev.mysql.com/doc/refman/8.0/en/data-type-overview.html),MariaDB,MonetDB的基本数据类型和MySQL一致.
4.2.2 操作类型支持度
本文用例中涉及的SQL语句大都与具体的数据直接相关,所以在实验论证中只对DDL语句和DML语句进行实验验证证,而对DCL语句不做支持.实验结果见表4,可以看出,Cynomys能够支持所有DDL语句和DML语句.

Table 4 SQL statement support in Cynomys表4 Cynomys对SQL语句类型支持情况
4.2.3 系统稳定性
作为一个实时同步工具,对其稳定性要求一般较高,必须保证 7×24小时无间断的稳定运行和快速响应.本实验是将Cynomys部署在服务器上连续运行一周,在每天的4个时间点各发起一次同步请求,观察Cynomys的表现并进行采样,得出结论,Cynomys的稳定性达到了7×24小时及时响应,符合MySQL的运行状态和同步要求,实验结果见表5.

Table 5 Test table of operational stability表5 Cynomys运行稳定性测试表
4.3 性能实验
性能实验中,主要测试从行存储到列存储的同步效率,其中,列存储数据库选择前面提到的 MariaDB ColumnStore.测试集选用的是TPC-C产生的模拟数据.
MariaDB ColumnStore主要用于分析型数据库使用,所以Cynomys的同步只涉及INSERT,对UPDATE和DELETE性能不作要求,在性能实验中,主要是要检验Cynomys执行INSERT的性能.
在测试Cynomys的INSERT性能时将启用延迟提交功能,通过调整延迟提交的缓冲区大小,得到实验数据如图11所示.

Fig.11 Figure of DELAY buffer and INSERT effiency图11 DELAY缓冲区大小与INSERT效率关系表
依据上述实验结论,延迟提交确实可以提高 INSERT操作的同步性能.在内存容量充足的情况下,缓存的待插入数据越大,相应的同步效率越高.
根据 MySQL的现实场景,一般峰值的INSERT量在1 000条/s左右.由于表的列数对插入性能影响较大,所以对于延迟提交缓冲区大小的需要可依据表结构来确定.以一个拥有 20个字段的表为例,满足峰值 INSERT的缓冲区大小设置为3 000左右即可.
从数据中还能看出另一个问题:随着表的列数增加,INSERT操作效率的提升降低了.这是由于受测列式数据库的特殊存储结构,列式数据库中每一列都对应一个文件,这样的文件组织结构导致当表中的列增多时,会对性能有较大的影响.
4.4 兼容性实验
兼容性实验主要测试Cynomys在不同操作系统上是否能正常运行以及不同行列数据库能否正常同步.
Cynomys采用JAVA语言开发完成,目的就是为了能兼容各个操作平台.本节选取了当前主流的操作系统包括Windows 7,Windows 8,Ubuntu,CentOS等不同版本测试Cynomys在各个操作系统平台的运行情况,实验结果见表6.

Table 6 Experimental result of compatibility of Cynomys表6 Cynomys平台兼容性实验结果
从表6可以看出,Cynomys在当前主流操作系统上都能正常运行.此外,还对不同版本的行列数据库进行了软件兼容性实验.Cynomys是基于Binlog实现的,因此所有基于Binlog且能执行标准SQL语句的行数据库理论上都能运行,本节测试了MySQL与MariaDB(ColumnStore)的不同版本进行软件兼容性实验,实验结果见表7.
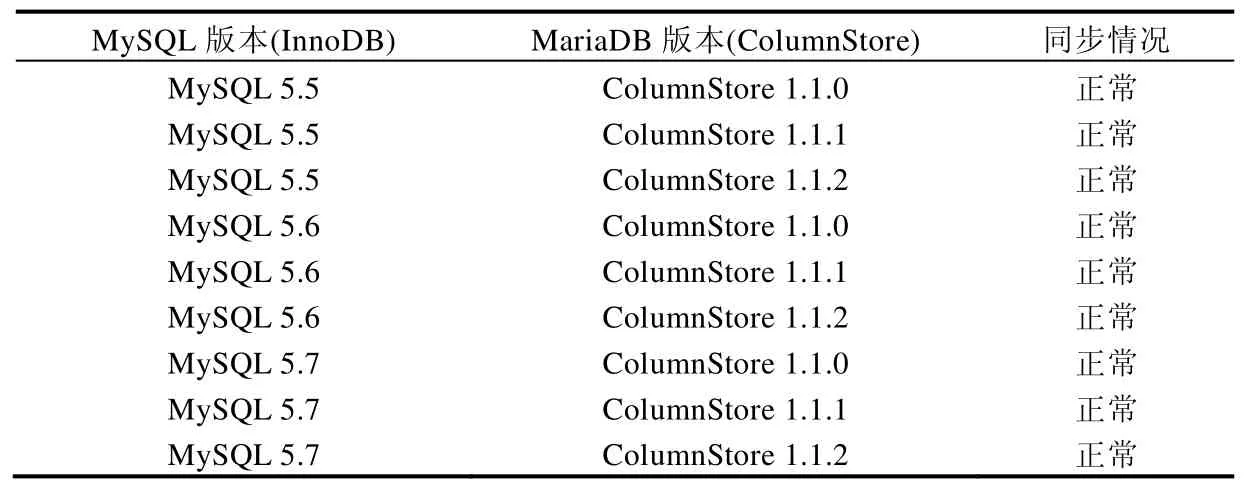
Table 7 Experimental result of compatibility of database in Cynomys表7 Cynomys数据库兼容性实验结果
除表7给出的MySQL和MariaDB外,还对其他列存储数据库如MonetDB进行了测试,在这些行存储数据库之间,Cynomys都能正常同步数据,不同列存储数据库对数据查询时间的影响如图12(以 MariaDB和MonetDB进行对比)所示.
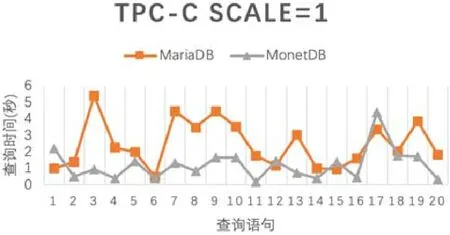
Fig.12 Influence of query time for different column-based database图12 不同列存储数据库对查询时间的影响
4.5 正确性实验
正确性实验主要测试在多用户(进程)并发的情况下,Cynomys同步数据的准确性与源数据是否一致.本节实验所选取的主数据库为MySQL5.6,列数据库为MonetDB11.27,数据集为TPCH-DBGEN生成的TPC-H数据中的LINEITEM表的前100万条数据.
实验假设有4个用户同时对MySQL写入共100万条数据,每个用户写入25万条.从MySQL写入数据一共用时5.68s,由于Cynomys对列存储数据库SQL语句提交的优化,数据写入MonetDB的速度与MySQL写入的速度几乎是同步的,仅用6.12s.实验为采样实验,测试采样为30%,50%,100%的情况下,数据响应速度与数据同步的准确率.对比是否与原数据相同采用将所有字段进行拼接,比较与原数据的字符串是否相同的方法.同步实验准确性结果如图13所示.

Fig.13 Accuracy of synchronization图13 同步准确性实验
实验结果显示,在不同采样大小的情况下,Cynomys同步到从数据库的数据都能与源数据保证完全一致的准确性,验证了第2.5节中对数据同步正确性的说明分析.
5 总 结
在当前分布式系统得到广泛应用的背景下,本文提出了一种利用数据库所提供的 Binlog机制,设计了日志解析器BinParser和日志还原器BinReducer.为了应对分布式场景,也为工具实现了包括序列化、压缩加密、消息分发等一系列的工作.同时,针对列存储数据库本身在INSERT性能上存在的不足,提出了延迟提交的思想.基于以上各项技术实现了同步工具 Cynomys,用于同步行存储数据库和列存储数据库之间的数据.该方法弥补了不同存储模式的异构数据库之间无法进行实时数据同步的空白,解决了从分布式行存储数据库到列存储数据库的同步问题,且在实验中表现出了良好的性能.
此外,目前Cynomys只支持部分版本的MySQL数据库,在MySQL5.6之后,由于Binlog引入了CRC校验,Cynomys对于如何适应CRC校验并没有给出解决方案,所以对于最新版本的MySQL数据库使用场景还不能做到同步,需要人为地对高版本MySQL进行配置才可以.这也是未来需要改进的方面.
