基于Wi-Fi探针的地铁车站拥堵点客流量估计方法
2019-04-01劳超勇刘志钢
劳超勇 胡 华 刘志钢
(上海工程技术大学城市轨道交通学院 上海 201600)
0 引 言
地铁网络化运营面临早晚高峰常态化或突发事件下的大客流压力下,在拥堵位置如何有效采集客流数据、实时监控客流状态是防止突发事件引起交通瘫痪乃至演变成社会危机的关键。
站内拥堵位置是指站内通行措施的输出客流和输入客流之间的客流量超过其通行能力,形成客流拥挤的瓶颈区域,包括安检机处、闸机处、楼扶梯处、站台处等。在早晚高峰或突发性情况下,站内拥堵点处客流常表现出高密度、不确定性、波动性等特征,增加客流采集的难度且影响采集的精度。地铁车站采用的AFC(自动售检票)系统只得到乘客进出站的刷卡数据且无法准确获取站内出行路径,而依赖于人工经验和应急预案开展车站的大客流管控,已经难以确保其效率和运营的安全。因此,需利用模型清分的方式对站内客流数据进行估计或预测。
为实现站内客流流量的采集,视频监控的图像识别、红外客流检测等客流检测技术[1-3]已经在轨道交通地铁车站进行探索与应用。这些采集技术在特定的区域内具有一定的应用价值,但由于技术的瓶颈尚不能精确地进行客流流量的采集,且成本较高,无法有效地在站内推广。Wi-Fi探针采集技术是AP(无线接入点)与Wi-Fi设备(如手机、电子阅读器)的信息交互,实现对携带Wi-Fi设备对象进行采集,解决红外检测、视频采集等技术精度不高的问题,且具有实时性强、布设灵活及设备成本低等特点。目前,关于客流估计方法相关研究[4-6]侧重对历史数据或短期时间客流数据进行模型估计,但针对站内客流流量的实时采集及分析则处于起步阶段。
本文对Wi-Fi探针采集的原理、数据结构、数据的预处理进行详细分析,然后对采集数据的分析模型进行详细阐述,最后以上海徐泾东地铁站为例进行客流数据的获取及客流量估计模型的有效性进行验证。
1 Wi-Fi探针客流数据采集与过滤
1.1 Wi-Fi探针采集原理
基于IEEE 802.11协议的Wi-Fi探针是采用WLAN(无线局域网)技术实现对于开启或连接Wi-Fi的设备进行采集,采集原理为:AP会周期性地向四周发送BEACON(信标)帧,通知周围的Wi-Fi设备(如手机、笔记本电脑等)AP的存在;Wi-Fi设备也会周期第发送PROBE(探测)帧,其中包含Wi-Fi设备的MAC地址(Medium Access Control)、信号强度(RSSI)等信息。当AP检测到Wi-Fi设备传送的PROBE帧,即记录Wi-Fi设备传送的信息。因此,在Wi-Fi探针区域内打开或连接Wi-Fi则可收集Wi-Fi设备信息。
1.2 Wi-Fi探针采集数据的基本属性
在工作状态下,对于开启Wi-Fi功能或连接上Wi-Fi的电子设备,Wi-Fi探针能检测其发送的信号且记录生成数据文本,包括Wi-Fi设备MAC地址、RSSI和数据抓取的日期和时间等基础信息,如表1所示。Wi-Fi设备的MAC地址为乘客唯一的标识符;RSSI表示捕获具有Wi-Fi功能设备的信号强度,表示设备与Wi-Fi探针间的远近。

表1 Wi-Fi探针设备记录的数据
1.3 源数据预处理
在地铁车站内,非地铁乘客的干扰或乘客个人行为等会影响Wi-Fi探针捕获的数据总体样本量,导致输出不可靠的结果,包括以下情况:(1) 在地面或高架车站可能采集非站内乘客的Wi-Fi设备;(2) 站内存在具有Wi-Fi功能的固定设施设备;(3) 车站工作人员自身携带的电子设备;(4) 乘客在站内长时间停留。为筛除上述数据识别有效的MAC地址,设计数据过滤算法如下:
(1) 消除数据中10 min时间间隔内重复出现的MAC地址,据此可筛除探针捕获的非移动设备,如员工携带具有Wi-Fi功能的设备以及测试期间未移动的任何其他智能设备;
(2) 依据设备供应商提供的RSSI与距离的关系表,如表2所示。RSSI低于-80 dBi的设备,RSSI为-80 dBi的Wi-Fi设备大约对应于距离Wi-Fi探针的40 m,据此可筛除非站内或距离拥堵点较远的Wi-Fi设备。
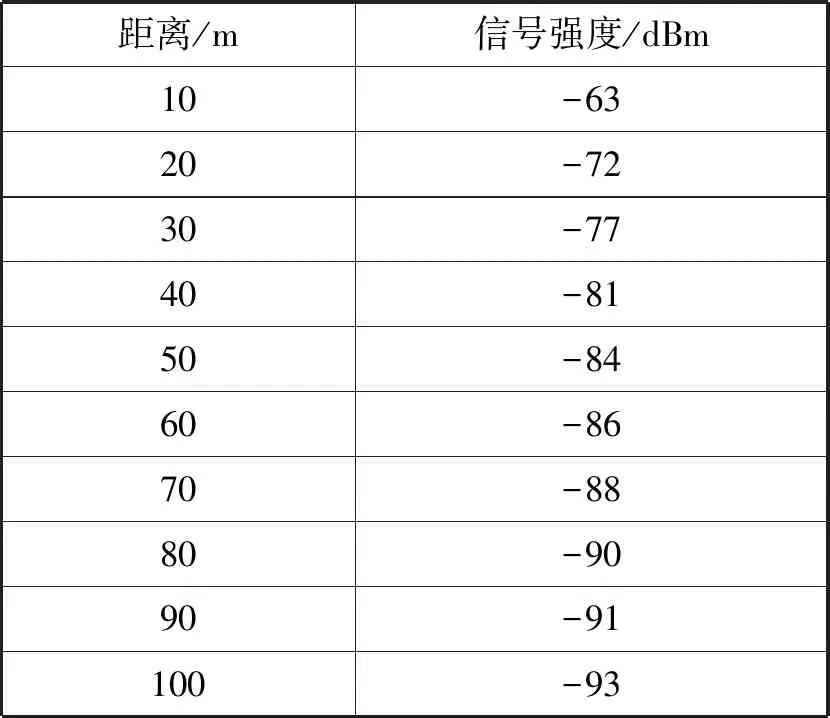
表2 RSSI与距离间的关系表
(3) 为了解决由于工作人员或乘客在站内来回走动而产生的重复计数问题,步骤如下:
第一步以第1 min到第5 min的MAC地址创建第一个循环块。
第二步检测第6 min与第一个循环块中是否出现相同的MAC地址,若重复则剔除。
第三步以第2 min到第6 min的MAC地址创建第二个循环块,并检测第7 min与第二个循环块,若重复则剔除。重复以上步骤对5 min时间间隔的MAC地址进行检测去重。
2 基于Apriori算法建立关联探针组
在地铁站内,各拥堵点间的客流量存在相关性,临近探针的检测范围也可能存在重叠性。因此,应对探针数据间与拥堵点区域实际客流数据间进行相关性分析,从而获得能用于估计拥堵点实际客流量的独立关联探针组。为了探究拥堵点间的Wi-Fi探针是否存在相关性,以拥堵点间布设探针采集的MAC地址建立关联数据库,采用Apriori算法进行关联探针规则挖掘。
Apriori算法是关联规则常用、经典的数据挖掘频繁集的算法,其核心思想是通过连接产生候选项及其支持度,然后通过剪枝生成频繁项集[7]。关联规则的一般形式:
(1) 关联规则的相对支持度:项集A、B同时发生的概率:
Support(A→B)=P(A∪B)=
(1)
(2) 关联规则的置信度:项集A发生,则B发生的概率:
Confidence(A→B)=P(A∪B)=
(2)
判断强规则的依据:最小支持度和最小置信度。最小支持度是衡量支持度的阈值,表示项目集在统计意义上的最低重要性;最小置信度是衡量置信度的阈值,表示关联规则的最低可靠性。同时满足最小支持度与最小置信度的阈值称为强规则。
探针关联规则建立包括数据的采集、数据过滤、建立Apriori关联规则模型、产生强规则、得到关联探针组,如图1所示。
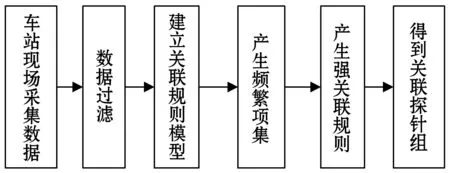
图1 关联规则建立流程
3 客流量估计模型
神经网络算法具有较强的非线性处理的能力,能够很好地解决随机性与非线性问题,但BP神经网络的本质为梯度下降法的求最优的问题,容易陷入局部无穷小,造成局部收敛或无法收敛的问题[8-9]。因此,本文添加动量因子及自调整学习速率对传统的BP神经网络进行改进,以过滤学习训练过程中高频振荡,使得学习速率以取得较大的值,加快学习速率。
3.1 网络结构设计
本文利用关联规则得到的关联探针组作为神经网络的输入层,采用三层的神经网络结构进行实际客流量估计模型的建立。拥堵点客流量估计神经网络结构图如图2所示。
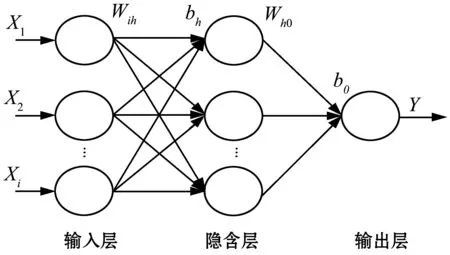
图2 拥堵点客流量估计神经网络结构图
x1,x2,…,xi为关联探针组在工作日早高峰两小时每5 min检测的MAC地址数,其中:i表示关联探针组中探针的个数;wih为输入层与隐含层连接权值;wh0为隐含层与输出层连接权值;bh为隐含层各神经元的阈值;b0为输出层各神经元的阈值;Y为拥堵位置客流量的估计值。
输入神经元个数和输出神经元个数决定隐含层的个数。已有建议值为:
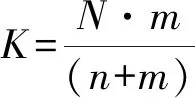
(3)
式中:K为隐层的神经元个数,n、m分别为输入神经元数和输出神经元数,N为样本容量。本预测模型的隐层神经元个数在上述建议值的基础上经多次计算试验得到。
3.2 网络学习规则
为了有效解决BP神经网络易陷入局部极小值与无法收敛等问题,本文添加动量和自动调整学习速率的学习规则,经过多次试验该学习规则预测精度最高,学习规则修正权值Δwij的表达形式如下:
(4)
式中:e为期望输出与实际输出的误差;η为网络的学习速率(η>0),当η取值过小时,网络收敛慢;当η取值过大时,学习过程变得不稳定导致误差过大;γ是动量因子(0<γ<1),通过引入γ可避免学习的不稳定和局部收敛。
学习率η和动量因子γ的恰当选取通常凭经验和实验选取。本文中γ的值将结合具体算例经过计算实验选取得出,而η是自适应调整的。经验表明,学习率的增加量最好是常数,但它的减小应按几何律减小,本文采取的自适应函数如下:

(5)
式中:Δe为每次迭代误差函数的变化;a、b为适当的常数。
3.3 网络训练停止规则
本预测模型以N个样本的方差小于收敛阈值作为训练的收敛条件,公式如下:
(6)
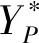
4 算例验证
以上海徐泾东地铁站作为数据采集的实验车站,采集站厅层安检至进站闸机区域内的客流数据。该区域内包括安检、进站通道、售票区、出入口和进站闸机五个易发生拥堵的位置,共布设5台AP设备,布设方案如图3所示。基于2017年5月某工作日连续五天早高峰两小时的客流数据约800万条作为样本数据,并通过站内监控录像人工计数获取实际客流量。
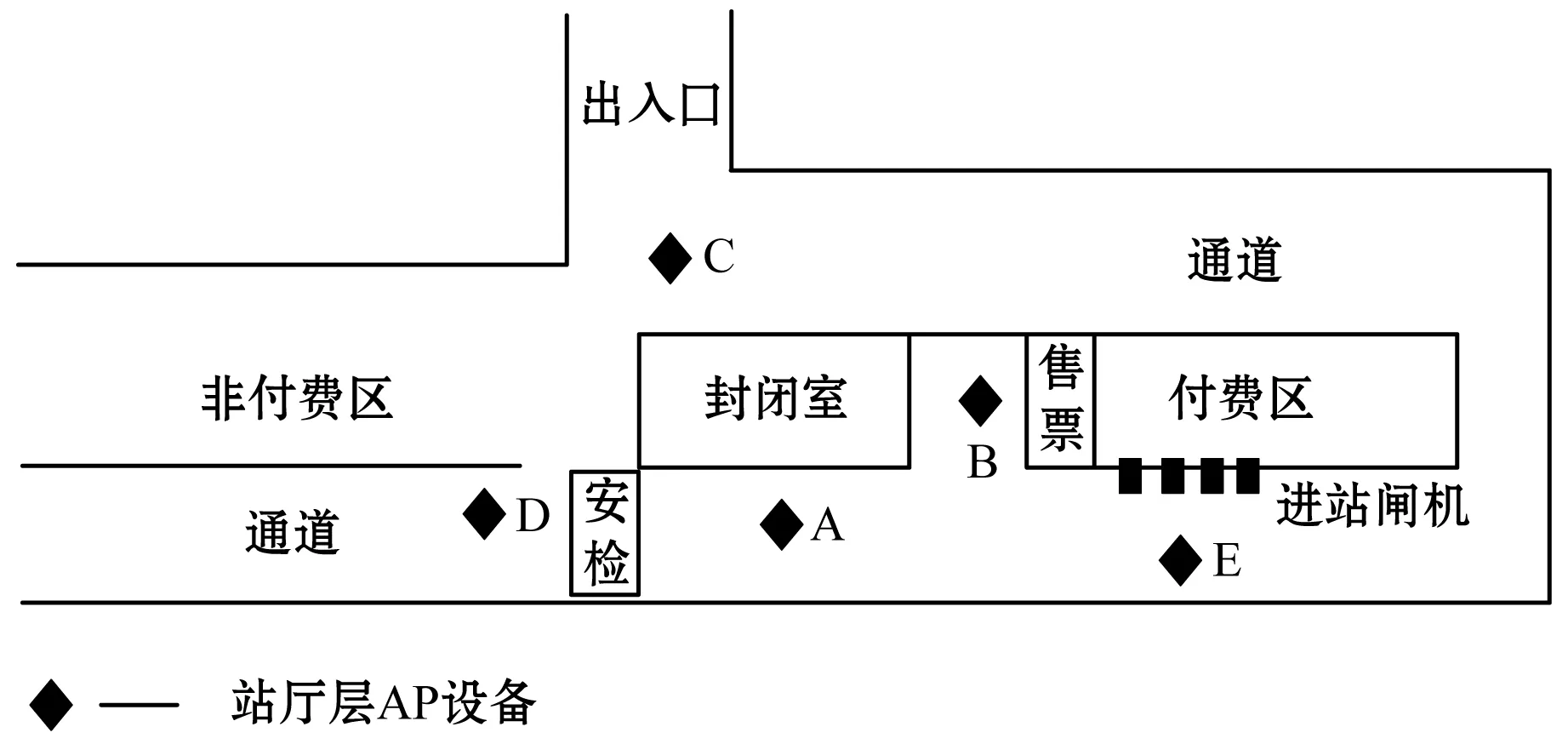
图3 站厅层Wi-Fi探针布局图及探针布设方案
4.1 算法设计
步骤1采集源数据,本算例以站厅层进站安检至进站闸机区域的五个探针(A、B、C、D、E)作为分析对象,获取五个探针在工作日早高峰两小时的MAC地址,并统计每5 min的MAC地址数。
步骤2源数据预处理。利用过滤算法剔除Wi-Fi探针在采集环境中捕获的干扰数据,包括非站内、频率过低、来回走动的设备。图4为Wi-Fi探针A数据在高峰一小时内过滤前后的对比图,可见经过预处理后,探针A的数据在0~200范围内波动且波动较为平缓。
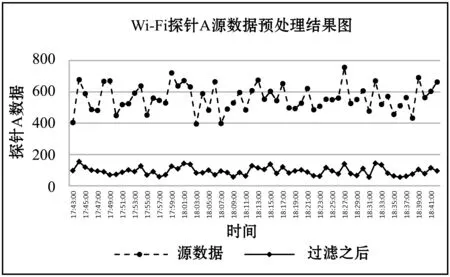
图4 Wi-Fi探针A采集数据过滤前后对比图
步骤3利用Apriori算法对拥堵点间五个探针进行关联挖掘:
将采集五天早高峰两小时的MAC地址建立关联规则挖掘的数据库,作5 min间隔统计并记录间隔内出现相同MAC地址的探针。若5 min间隔内出现共同MAC地址则记录相应的代表字母。
根据关联数据库产生频繁项集,首先产生候选集Ck,即可能成为频繁项集的项目集合,集合{A,B,C,D,E}为初始频繁项集。然后利用候选集Ck计算支持度确定最大频繁项集Lk。设定最小支持度为0.2,最小置信度为0.5,运用Python实现结果如表3所示。从表可见,B、D→A的置信度为0.714 8>0.5,A、D→B的置信度为0.833 3>0.5,说明探针A、B、D为强关联,则探针A、B、D为该拥堵点的关联探针组。
表3 Apriori算法关联结果统计表
步骤4构建神经网络模型。选取关联探针组作为神经网络的输入,实际客流量作为实际输出,根据训练调整相关参数,建立神经网络预测模型。相关参数初始设置如表4所示。
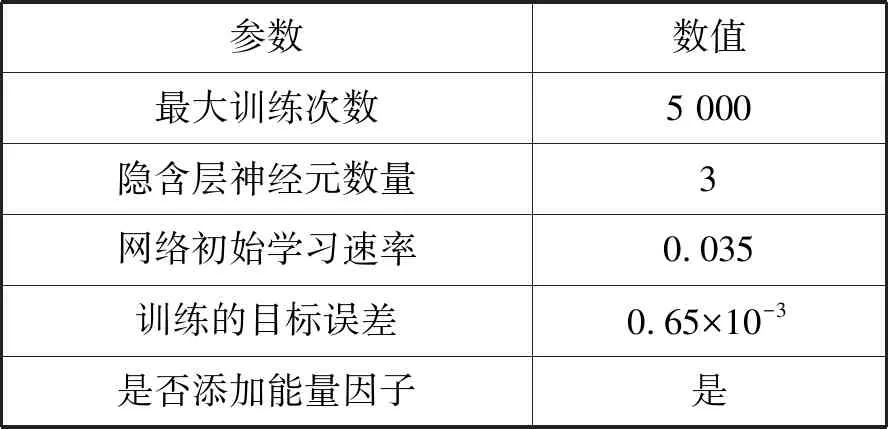
表4 网络训练参数设置
步骤5预测结果误差分析。
4.2 结果分析
建立的关联探针组与实际客流量建立BP神经网络在MATLAB 2015b中实现训练,神经网络训练的过程如图5所示。
图5 神经网络训练过程
(1) 稳定性评价:将120组到站时间预测值与实际值进行对比,如图6所示。
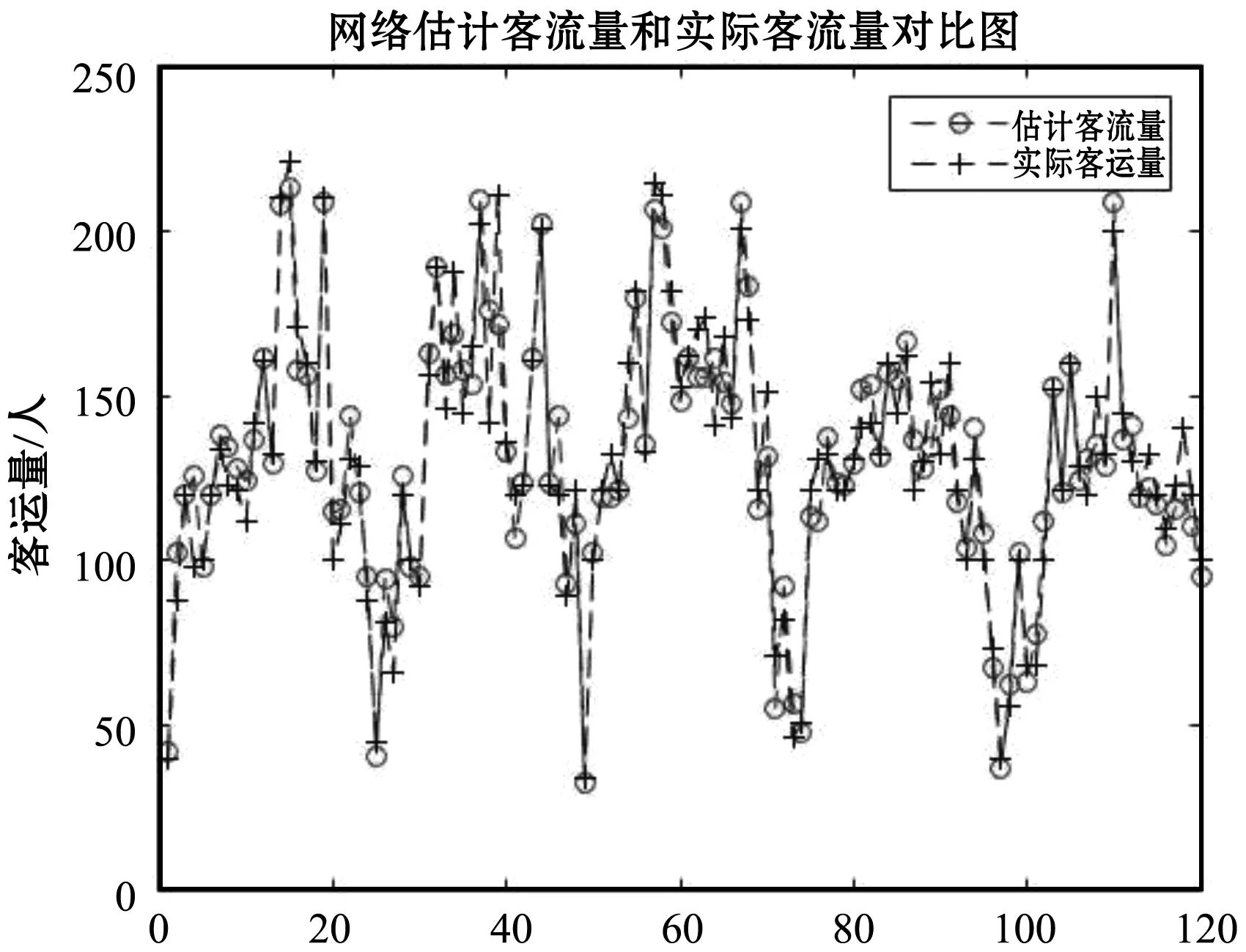
图6 网络输出预测客流量和实际客流量对比图
从图中可以看出,预测值曲线与实际值曲线的重合度较高,根据预测客流量与实际客流量得到最大绝对偏差值为28人,在可接受的预测误差阈值以内,说明该模型的稳定性较好。
(2) 精确性评价。预测结果的相对误差箱型图如图7所示。
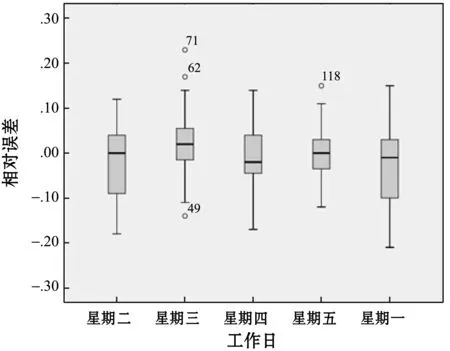
图7 预测结果的相对误差柱状图
由图7可见:
(1) 在工作日中,相对误差绝大部分数据在[-20%,20%]区间内波动。星期三的平均相对误差较高,而星期四的平均相对误差较低。
(2) 星期三、星期五的相对误差分布比较集中且非常对称,星期一、星期二及与星期二的相对误差较分散且非常不平衡。
(3) 星期三对应的箱形图出现了3个异常点,分别对应8:50~8:55的5 min内相对误差为23%、8:05~8:10的5 min内相对误差为17%、7:00-7:05的5 min内相对误差为-14%;星期五出现1个异常点,对应8:45~8:50的5 min内相对误差为5%。
为了对比标准BP神经网络与改进后BP神经网络算法在客流估计训练过程中优异,本文采用不同的精度进行训练仿真,结果如表5所示。显然,在训练学习速率和训练精度上改进BP算法要优于标准BP神经网络算法。
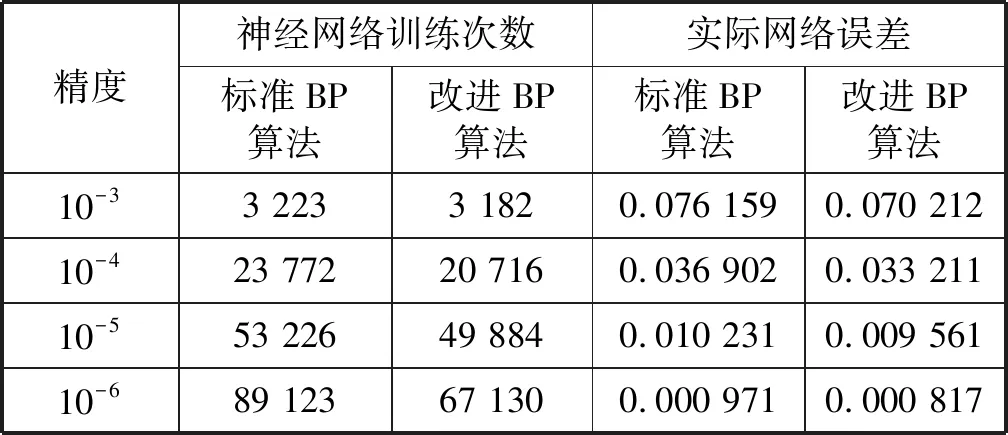
表5 改进BP神经网络与传统神经网络对比
5 结 语
基于上海轨道交通地铁车站,本文对Wi-Fi探针获取拥堵点的Wi-Fi设备数据进行了初步的分析及客流量估计模型的初探。从分析结果看,Wi-Fi探针采集客流的技术条件已经具备且采集的客流数据质量基本满足客流模型分析的要求。但由于部分乘客不携带Wi-Fi设备或不开启Wi-Fi模块功能等因素造成数据缺失的问题,再加上针对数据的加工处理、数据还原、估计模型精度的提高依然面临极大挑战,这也是未来研究的重点方向。
