虚假评论检测技术综述①
2019-03-11尤苡名
尤苡名
(浙江理工大学 信息学院,杭州 310018)
互联网的迅速发展使线上平台在人们购物、旅游、用餐、住宿等各个方面占据了重要的作用.这些线上平台拥有大量评论.评论信息作为桥梁联结消费者和产品,不仅可以影响消费者的决策,还能作为反馈来促进商家改善产品细节.然而,评论者个体因为利益关系、品牌偏见等原因发布了许多虚假评论.他们甚至会协同合作发布虚假评论,组成虚假评论群组.据调查显示[1],美国版大众点评网站Yelp上欺骗性评论的比例已从2006年的5%涨至2013年的20%.虚假评论误导消费者决策,破坏消费体验,危害性大.
2008年,Jindal等[2]首次对产品虚假评论开展研究并给出虚假评论的3种类型:
(1)不真实评论.评论制造者为了提高某产品的销量,不管产品真实的特性大肆赞美该产品,或者为了压制某产品的销量诋毁该产品.
(2)只关注品牌的评论.评论者因为产品的品牌、厂商和销售商对产品带有偏见.
(3)无关评论.一般分为两类:广告和其他与评论无关的文本.
由于评论内容多为短文本,虚假评论比垃圾网页和垃圾邮件更难识别[3].国内外学者重点研究第一类虚假评论.
虚假评论检测难点在于找出有效的特征来更好地区分虚假评论与真实评论.最早的时候,研究者从评论内容提取语言特征(例如,词袋特征)用于检测.然而,有经验的评论者编写虚假评论模仿真实评论,所以利用评论内容识别虚假评论,准确性不高.于是,研究者结合行为异常信息来提高检测准确性.虚假评论检测另一难点在于缺少标准标注数据集评估算法性能.研究者引入图结构,利用评论者、评论、产品之间的关系特征,把检测任务转为排序或者联合分类问题,已知节点的信息通过连接的边传递到未知节点.此类方法适用于标注数据集少的情况.da方法检测的效率不高.于是,研究者利用表示学习方法让模型学习表示评论,减少人为设计特征的繁琐性.
本文第1节从检测的一般流程、特征分类、检测方法三部分介绍虚假评论检测技术,重点比较了各类方法的优缺点.第2节列举了研究者们使用的合成数据集和真实世界的数据集.第3节对全文进行总结,同时探索了未来的研究方向.
1 虚假评论检测技术
1.1 检测流程
虚假评论检测的一般流程分为:数据收集、数据预处理、特征设计、模型设计、模型评估.数据收集指自己爬取网页数据或者下载他人整理的语料库.数据预处理对后续的虚假评论检测性能有着很大的影响[4].该阶段去除了不相关信息,并对文本进行分词、去除停用词、词性分析.为了尽可能精确有效地表示评论,需要对数据的特征进行分析设计,特征设计主要包括特征提取和特征选择.评论特征通过归一化或者规范化后输入到设计的虚假评论检测模型中.模型评估用于检验模型的泛化性能.常用的评估指标有:AUC值、F1值、准确率Accuracy、精确率Precision、召回率Recall.
1.2 特征分类
研究中常用的特征可分为四类[5]:评论者的语言特征、评论的语言特征、评论者的行为特征和评论的行为特征,具体如表1所示.前两类来自评论内容,后两类由元数据产生.这些特征是在以往的研究工作中统计出来的,依赖于专家们对不同领域数据的经验知识.
1.3 检测方法
1.3.1 基于语言特征与行为特征的方法
基于语言学特征的方法属于早期的研究方法.词袋特征(unigram/bigram/trigram)是虚假评论识别最为常用的语言特征[6-8].Jindal等[2]提取重复评论的bigram特征,在亚马逊数据集训练回归模型,识别只关注品牌的评论和评论文本无关的两类垃圾评论,AUC值高达90%.
Ott等[7]仅使用bigram特征在合成的黄金标准数据集训练支持向量机SVM模型,分类结果Accuracy达到89.6%.Feng等[9]利用unigram、深层句法特征和SVM模型对同一合成数据集进行验证,将Accuracy提高到91.2%.
Li等[10]扩充了黄金标准数据集,研究了虚假评论检测领域迁移性问题.研究者利用Hotel数据集的Unigram特征训练SVM模型和稀疏相加生成模型(SAGE),然后在Restaurant和Doctor数据集上测试模型.Hotel数据和Restaurant数据相比有较多相似的属性,而和Doctor相比相似性较少.实验发现两个模型在Restaurant数据集上的分类Accuracy都能达到75%左右,而在Doctor数据集上Accuracy只有50%左右.实验说明词袋特征用于虚假评论检测领域迁移性差.
由于人工标注样例误差大,任亚峰等[11]提出PU学习算法 (Positive-Unlabeled learning algorithm)识别虚假评论.作为半监督性学习算法,PU算法在评论数据包含少量正例P和剩余全为未标注样例U的情况下构造分类器,自动标记未标注样例U.核心是确定间谍样例的类别标签.该方法首先从未标注评论样例中抽取了可信负例,利用LDA主题模型抽取了它们的主题分布特征,并使用K-Means聚类主题分布相似的可信负例.然后,用Rocchio分类器识别出10个代表性正负样例,并以代表性正负样例为基准,混合种群性和个体性策略确定间谍样例的类别标签.最后,利用多核学习算法建立最终的分类器.实验在黄金标准数据集上进行,识别Accuracy达到 83.21%.然而,如果间谍样例所在子类正负样例数目相近,并且间谍样例与代表性正负样例的相似度都不高,算法就难以确定间谍样例的类别标签.此外,多核学习算法将特征映射到高维空间区分,效率不高,不适合处理大规模评论数据.
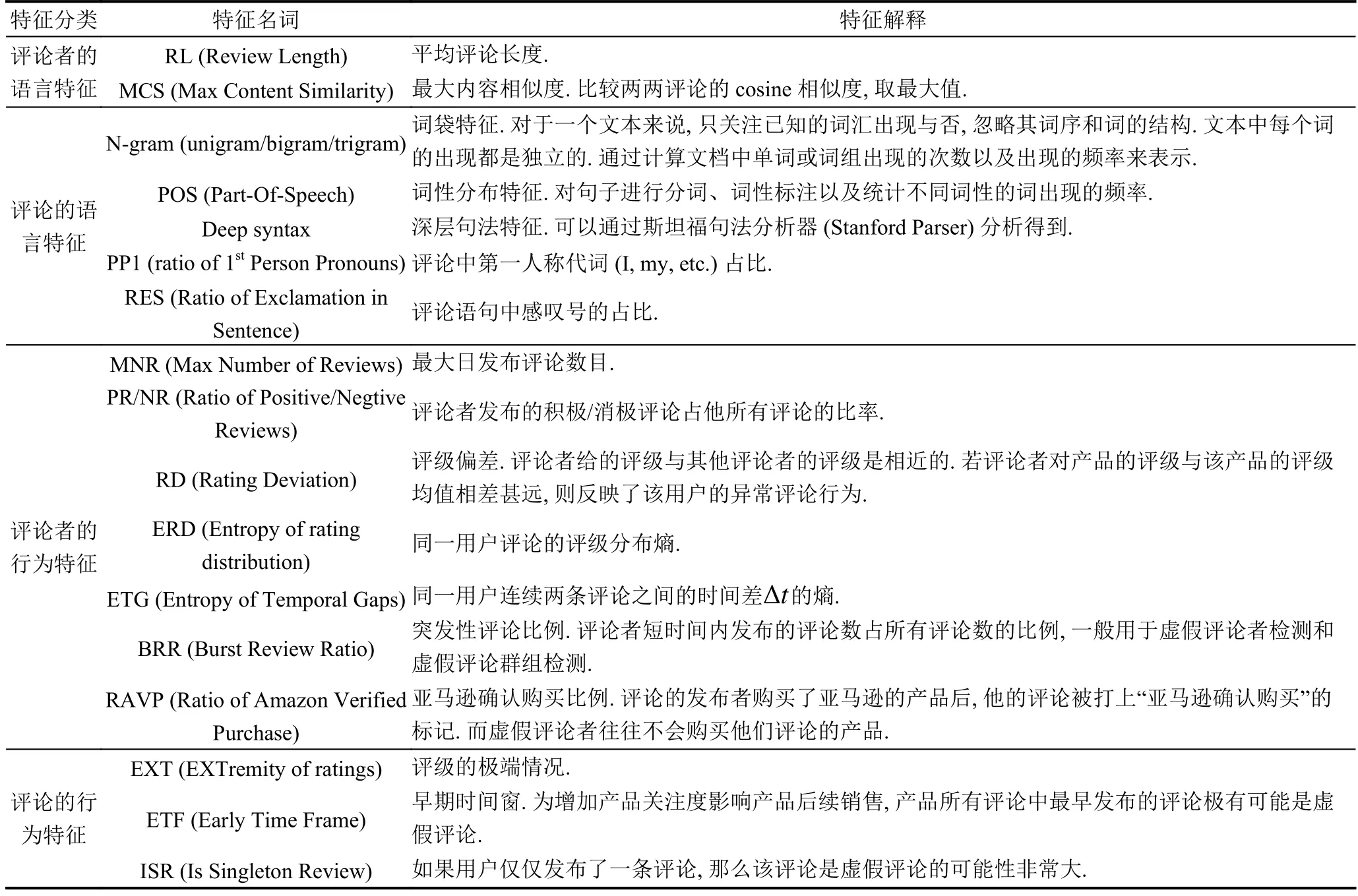
表1 常用的评论、评论者的语言特征和行为特征
赵军等[12]提出融合情感极性和转折词的逻辑回归模型识别虚假评论.该方法使用优势比和逐步回归变量筛选方法,比较了10个文本特征和行为特征变量的显著性水平,最后选择了6个对逻辑回归模型影响最为显著的特征.实验在Amazon数据集上进行,发现文本长度、情感强度和是否包含转折词的优势比最高.将转折词和情感特征融入模型有效地提高了检测的准确性,因为真实评论者在评论时往往比较全面.然而,该模型只是粗略地计算句子的情感极性,忽略了不同副词带来的情感强度的差异.此外,所选择的特征中不包含时间相关的特征,而实际上虚假评论存在爆发时间窗.模型仍需要改进.
基于语言特征的方法应用于点评网站中的评论数据时检测效果较差.Mukherjee等[13]使用bigram特征在黄金标准数据集上训练SVM模型,然后将训练好的模型在Yelp点评网站的Restaurant评论数据集上测试,仅取得 68.5% 的准确率.研究发现[2,13,14],将行为特征与语言学特征结合起来可以提高检测准确性.虽然虚假评论者在语言表述上模仿真实评论者,但是他们不能掩盖异常的评论行为.
以往的研究多次利用评论爆发性[15-18]和评论评分异常性[19-21]构建虚假评论检测模型.评论的分布一般是随机的,如果评论者的突发性评论集在所有评论集合中占的比例高,那么这些评论者极有可能是虚假评论者,而评论者发布的突发性评论极有可能是虚假评论[22].然而,Li等[23]指出,同时出现的评论不一定都是虚假评论.例如,当电视广告大肆宣传产品时,许多消费者会同时购买相同的产品,该产品在这时间段内会产生大量的评论.他们在大众点评的餐厅数据集上发现一种co-bursting行为模式,即虚假评论者在同一小段时间内积极地对同一批餐厅发布虚假评论,而其他时间段虚假评论者的评论行为比较消极.
Yang等[24]发现虚假评论群组中评论者的兴趣相似(指评论包含的方面和情感).研究中首先找出评论内容相似的评论者集合.然后,利用Author-Topic模型[25]提取剩余评论者的评论主题分布作为评论者的兴趣向量;使用亚马逊网上商城浏览器目录接口找出同一个目录节点下并且发表时间窗为一天内的评论.找出兴趣向量相似且评论时间窗相近的评论者作为候选者.最终,由三位专家判断候选者是否为虚假评论者.实验随机选择了方法检测出的50名虚假评论者和50名真实评论者,然后由三位专家判断真假性.实验结果中,虚假评论者和真实评论者的Precision分别为84%、80%.但是,研究者并未评估所选的3个特征的有效性,或者找出更多特征来提高模型分类的准确性.
将行为特征与语言特征结合可以改善虚假评论检测效果,然而前提是需要足够的数据抽取行为信息.Wang等[26]在Yelp酒店和餐厅两个领域的评论数据上研究了冷启动问题,旨在即时检测出虚假评论者,降低危害.他们发现行为信息有限时,评论长度、评论者的评级偏差、最大评论内容相似度和bigram特征结合较于仅使用bigram特征,检测准确率提高了5%(酒店领域),但是F1值降低了约5%、召回率降低了约19%,而提高后的准确率也只达到60%左右.这说明行为信息不够充分的情况下,虚假评论误判率增加,行为特征对于虚假评论的区分度有限.
1.3.2 基于图结构的方法
基于图结构的方法利用评论、评论者、产品等对象之间的关系特征,将虚假评论者和虚假评论的检测看作联合分类或者排序问题[27].在该类方法中,对象被映射为图结构中的节点,不同对象之间的依赖关系被映射为图结构中的边.对象与对象之间存在直接或间接的关联.
为了研究虚假评论者的检测问题,Wang等[28]提出了异构型评论图的概念来描述评论者、评论和线上商店之间的关系.文章采用了基于网络的算法并利用异构图各节点之间的关系来排序.如图1所示,图中存在三种类型的节点:评论者、商店和评论.一个评论者节点同其所写评论之间有一条边连接,一个评论节点同该评论所关联的商店有一条边相连接.而一个商店节点是通过评论者对该商店发表的评论与这个评论者节点间接关联.
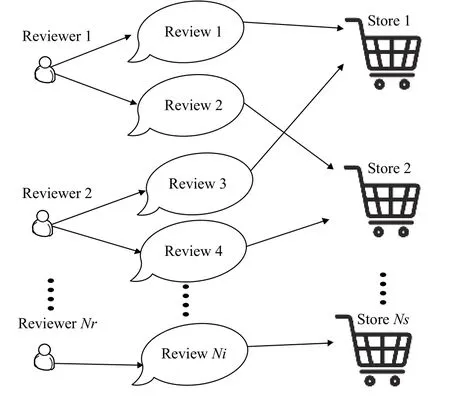
图1 评论者-评论-商店关系图
他们还提出一个有效的迭代计算模型,该模型采用了节点加强的方法对评论者的可信度、商店的可靠性、评论的真实性进行计算.研究者认为评论的真实性取决于以下两点:1)商店的可靠性.2)一定时间窗内该评论与其他评论的一致性.商店的可靠性与评论者的可信度正相关.评论者的可信度与评论的真实性正相关.经过多次迭代后,各节点的信誉度将逐渐收敛,系统也会趋于平衡.最终,得分较低的评论者归为虚假评论者候选人.评论者可信度T(i)的计算公式如公式(1)所示.
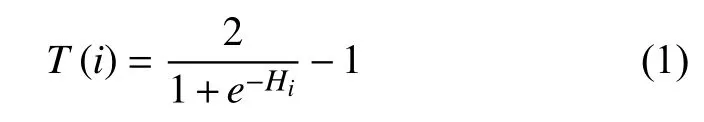
其中,Hi表示评论者i的所有评论的真实性的总和.但是,缺点在于算法只根据计算的分数对可疑的评论者进行排序,最终还得依靠人来评估可疑对象,标注虚假评论者.人工标注基于给定的规则,在多数复杂的情况下,还需依靠人类的直觉和大量相关信息来判断,因此准确性有待商榷.
余传明等[29]构建个人-群体-商户模型,量化关系特征,迭代计算个人、群体和商户的虚假度并将其排序.该方法构建商户-个人关系模型、商户-群体关系模型、个人-群体关系模型,并分别计算商户和个人、商户和群体以及个人和群体的相互影响程度.所用特征包含评论者个人行为特征、评论者群体行为特征、商家行为特征.实验从国内大型电商平台上选取93家店铺、9558个不同IP代表的不同评论者以及97 804条评论数据作为样本,虚假评论者识别的Precision值为92.86%,Recall值为 86.47%,F1 值为 87.89%.该方法不需要手动标记训练集,消除了分类模型的训练时间,可扩展到大型数据集.但是,关系模型在计算虚假度时只是简单地对特征取平均值,忽略了不同行为特征的重要性差异.
邵珠峰等[30]构建用户之间关系的多边图模型,计算用户的不可靠分数来识别虚假评论者.用户节点之间存在两种类型的边.若两个用户对同一商品评分相同或相似,用户节点之间用支持边连接,反之则用反对边连接.该方法利用用户的8种行为特征计算用户初始特征分数,然后归纳用户之间的支持边、反对边集合并利用TrustRank算法量化用户之间的关系分数,这两部分之和为用户的不可靠分数.最后将不可靠分数值较小的用户作为虚假评论者候选者,邀请3位专业人士评估判断出虚假评论者.缺点是,在计算初始特征分数时,特征权重的分配没有可靠的理论依据,特征组合也未证明最优.另外,该方法凭借情感词典简单计算不同用户之间的情感特征,分析不够全面.
Akoglu等[31]提出Fraudeagle模型,利用产品、用户、评论之间的关系识别虚假评论者.该模型在LBP(Loopy Belief Propagation)算法的基础上改进.LBP 是基于信息循环传递的算法.用户和产品映射为图节点,评论映射为边连接节点.对于未标记的用户,检测过程主要分为计算分数和分组两部分.该方法利用最大可能性概率来计算分数、标注节点.节点的标记依赖于评论的积极或者消极情感极性.方法的扩展性好,运行时间与网络的大小成线性关系.缺点在于,加入新的节点之后就得重新迭代计算已有连接节点的概率分数.此外,可以考虑加入时序特征、评论文本特征来初始化节点概率分数,提高模型识别的准确性.
Saeedreza等[32]提出NetSpam模型,利用异构型信息网络 (HIN,Heterogeneous Information Networks)对Yelp和Amazon的评论数据集进行分类.研究者将特征分为四类:评论-行为特征、评论-语言特征、用户-行为特征、用户-语言特征.该模型利用元路径量化特征重要性,构建模型时为特征分配不同的权重.通过实验发现,四种类型中评论-行为特征表现最好.选取重要的特征建模既能保证模型性能,又降低了算法的时间复杂度.除了基于评论者与评论的特征,研究者指出基于产品的特征的重要性也值得分析,但是该方法并未涉及.
1.3.3 表示学习方法
以上两类研究方法致力于设计有效的特征来区分虚假评论与真实评论,特征设计依赖于专家的先验知识.如果算法可以自动学习表示评论,就可以减少人为设计特征的时间,降低引入的噪声.
Wang等[33]利用张量分解算法在低维向量空间表示学习评论者和产品的关系,利用bigram表示评论文本,然后将这三部分连接成一个评论整体,作为SVM模型的输入.全局特征的矢量化有效地提高了检测性能.在Yelp的Hotel和Restaurant的数据集[13]上选取相同数目的虚假评论与真实评论进行实验,F1值分别达到了87.0%、89.2%,Accuracy分别为 86.5%、89.9%.但是,该方法用bigram特征表示评论文本仍不够有效.
Wang等[34]又进一步研究了虚假评论是语言异常还是行为异常的问题.针对虚假评论的现状,即有些评论者富有经验,在发表评论时善于伪装,此时主要利用虚假评论者异常的行为区分虚假评论;另一些评论者则相反,评论中往往包含更多的语气词、情感词,体现出较强的情感强度,所以只要利用语言特征就容易区分出虚假评论.研究方法利用MLP多层感知机学习行为特征向量,利用CNN卷积神经网络学习语言特征向量,并引入Attention机制动态学习行为特征和语言特征的权重.最终相比于Mukherjee等[13]使用现成的SVM 分类模型,F1 值提高了 1.5%,Accuracy提高了1.2%.这说明了现有模型对虚假评论检测效果仍然有限.另外,相比于研究者此前工作[33],F1 值、Accuracy分别提高了1.9%和2.3%.Attention机制有效地区分了虚假评论属于语言异常或是行为异常.至今为止,该方法在Yelp评论数据集上检测的F1值和Accuracy值最优.然而遗憾的是,研究者未在其它实验数据上验证所提算法的健壮性.
张李义等[35]结合深度置信网络DBN和模糊集识别淘宝的虚假交易.该方法利用用户的历史评论和交易记录提取表示用户行为的12个特征.首先,无监督地训练每一层受限玻尔兹曼机网络.然后,根据输入特征向量和顶层降维后传递的重构特征向量之间的误差对整个DBN网络进行有监督反馈微调.接着,采用模糊集描述用户“是刷客”或者“不是刷客”的隶属度.最后,将识别出的“刷客”的交易认定为虚假交易.实验结果中准确率、精确率、召回率、F1值分别达到89%,84.21%,96%和89.72%.DBN作为深层网络学习结构,能够学习抽象特征,弱化浅层结构的错误特征,从而缓解过拟合现象,提高模型分类效果.局限性在于,该方法分别选取了100名“刷客”和正常用户进行算法验证,相比于电商平台海量的用户,数据量过少.
Dong等[36]提出端到端(end-to-end)混合神经网络和随机森林的模型来识别虚假评论.随机森林作为集成学习算法,在训练时能防止每一决策树过拟合.该方法利用Autoencoder算法自动表示评论特征,作为随机森林的输入.该方法巧妙地结合了深度学习和传统分类模型,为虚假评论检测提供了新思路.在Amazon数据集[37]上实验,Accuracy达到 96%.但是,该方法需要设置合适的参数平衡时间消耗和预测性能的关系.这需要反复实验调整.此外,Autoencoder算法也被用于微博垃圾评论检测[38].
1.3.4 小结
基于语言学特征和行为特征的方法使用的模型一般较为简单,检测的效果相对较好,但是特征设计过程耗时且具有挑战性.不同数据集的数据稀疏程度、涉及的领域、语言的表述、评论者的关注面不同.所以,针对不同的数据集,需选取不同的特征进行实验.另外,特征设计一般依靠专家的经验,而专家们的经验也不完全可靠.
基于图结构的方法利用了评论、评论者、产品和商店之间的网络关系,使用传播算法、迭代算法等计算节点的分数.这类方法适用于标注数据稀少或者无标注数据的情况.在虚假评论检测问题上,优点是可以不依赖于人工标注数据,扩展性好.缺点是计算信誉度时利用的规则往往比较单一,新加入的节点影响已有节点的分数,所以需要重新迭代计算已有节点的分数.该类方法适用的网络规模不宜过大,而且检测效果还有待提升.
以上两类方法用到的特征通过统计得到,而表示学习方法能自动学习表示评论,既能提高实验效率又能提升检测效果.虚假评论者为了躲避网站算法检测,可能会增加评论的细节信息,或者利用账号积攒信用后发布虚假评论.可见虚假评论的语言特征与行为特征是动态变化的,不可预知的.表示学习方法不需要依赖经验设计特征,因此鲁棒性好.这类方法作为最新的研究趋势,检测效果优于传统的方法,然而这方面的研究较少而且不够深入.
三类方法的比较具体见表2.
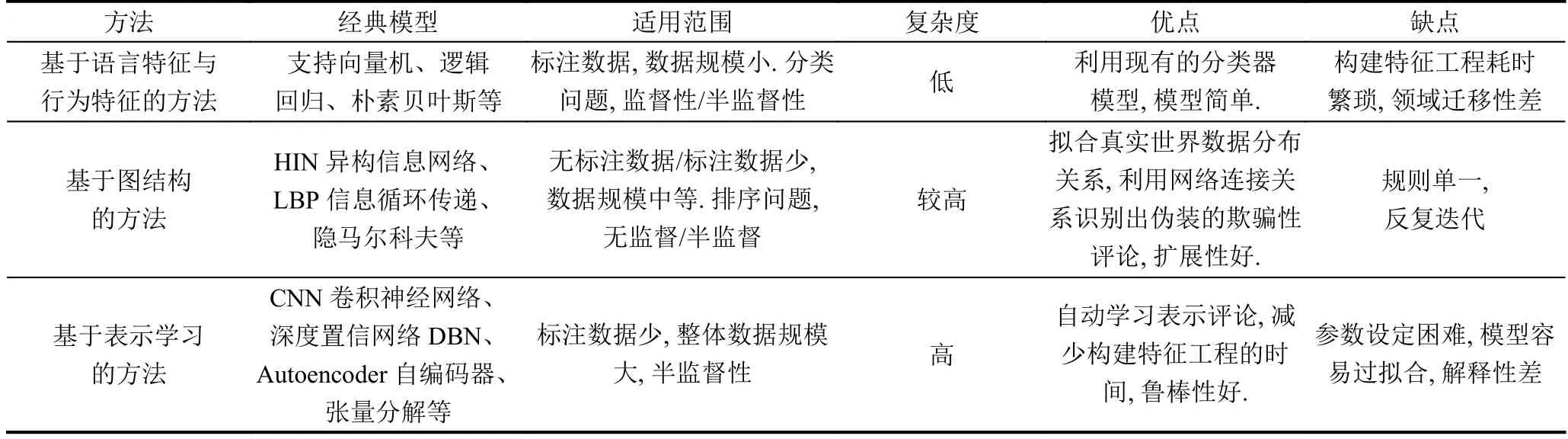
表2 三类方法的特点比较
2 数据集
研究者们不但致力于选择有效的特征表示评论/评论者,寻找合适的模型提高检测效果,而且探索研究多领域数据.但是,虚假评论检测研究主要问题是:缺少标准标注数据集来评估算法性能.目前,研究者们主要利用众包平台构造的评论数据或者真实世界点评网站的评论数据.
2.1 众包平台构造的数据集
众包平台通过向员工分配需求任务,依靠人类的智慧来完成计算机还不能完成的任务.例如,从许多照片中挑出最棒的商店前台的照片,编写产品描述性评论,或者区分出音乐CD封面上的歌手等[39].
Ott等[7]利用亚马逊众包平台获取黄金标准数据集,这是唯一公开可用的数据集.研究者通过向线上人员支付1$酬金令他们对20个受欢迎的芝加哥酒店构建想象型的积极评论,共收集了400条虚假评论.此外,研究者在TripAdvisor.com上收集了这20家酒店的400 条积极评论作为真实评论.之后,Li等[10]为了研究分类器在不同领域的迁移性能,扩充了这800条评论数据集,构造了跨酒店、餐厅、医院3个领域的黄金标准数据集.该黄金标准数据集包含了3种类型的评论:领域专家的虚假评论,众包平台的虚假评论以及消费者的真实评论.实验结果表明,酒店评论数据集训练成的分类模型在餐厅和医院评论数据上分类效果不佳.
众包平台的员工并未刻意模仿真实评论的表述,构造出的虚假评论和现实世界中的评论存在着较大差异.
2.2 点评网站的数据集
点评网站一般有自己的虚假评论过滤算法,这些过滤算法是商业机密,不向外部开放.表3概括了来源于点评网站的研究常用数据集.其中,Yelp评论数据集[13]作为近似标准标注数据集被广泛用于虚假评论检测的学术研究中.而Amazon评论数据集[37]由于数据量大极具研究价值,主要应用于情感分析、观点挖掘、产品推荐、虚假评论检测等各个领域.
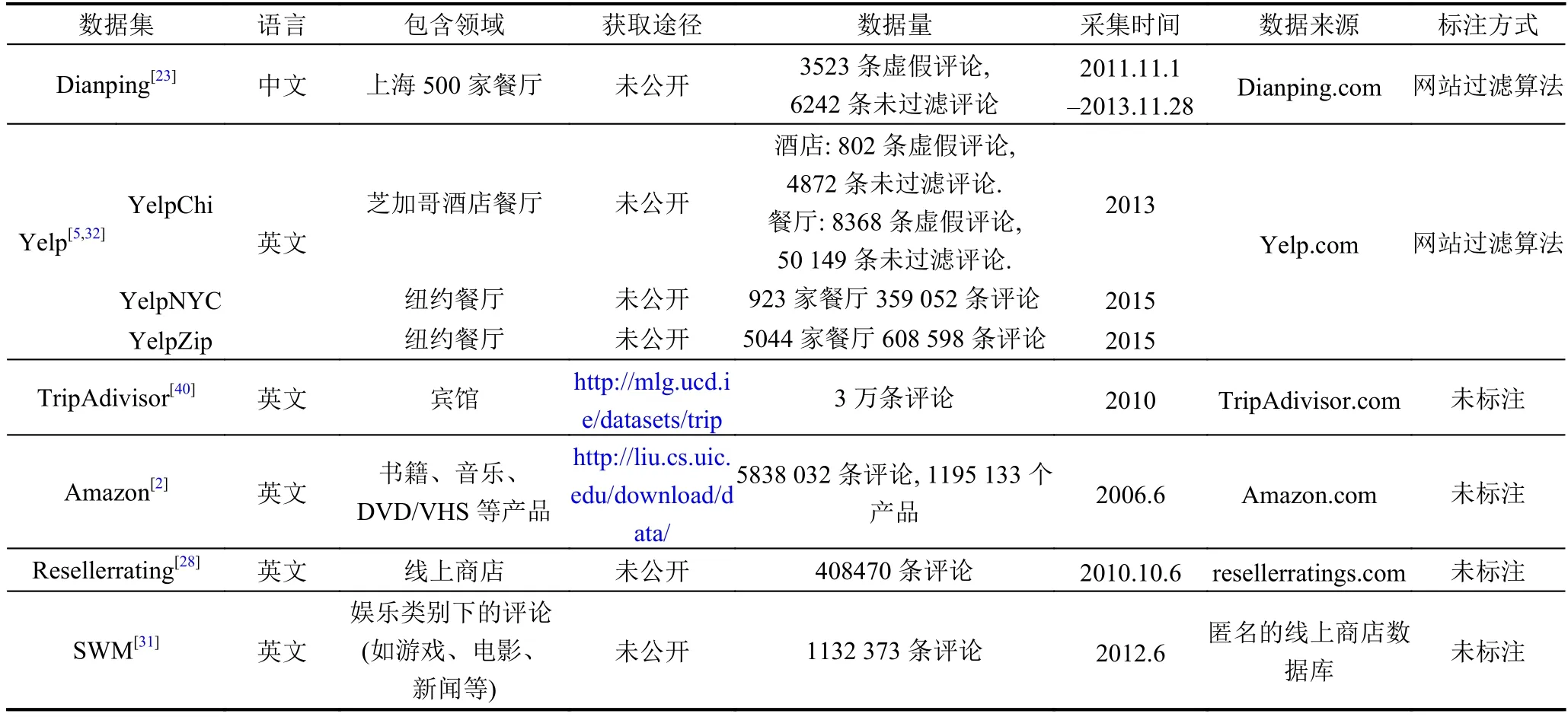
表3 点评网站评论数据集
3 总结展望
近年来,线上消费者在做出决策前都会参考商业网站的产品评论.真实可靠的评论既能改善消费者体验,也能促进商家良性竞争.本文主要概括了研究常用的四类特征,总结了国内外研究者提出的虚假评论检测方法,并从特征工程的角度对比了基于语言特征和行为特征的方法、基于图结构的方法、基于表示学习方法的优缺点,最后列举了研究中使用的数据集.从现阶段的检测技术来看,虚假评论检测仍有很大的探索空间,具体归纳为以下4点:
(1)针对来自不同领域的数据集,研究者们需要选取不同的特征来构建分类器,重复特征选择这一工作.这说明未来需要探索跨领域实验来优化特征选择的过程,减少重复性的人工操作.此外,最优的特征选择也是未来的探索方向.
(2)真实世界中虚假评论数据与真实评论数据不平衡,不平衡的数据训练出的模型效果较差.以往的研究通常利用采样达到数据平衡.然而,训练的模型在测试自然分布的数据集时检测效果下降.未来可以探索更多适用于真实世界中不平衡数据的技术.
(3)公开的真实评论网站的数据集较少,以往的研究大多使用了人工构造的数据集.但研究证实,经人工构造的数据集训练出的分类器在对真实世界的评论数据进行分类时效果不理想[13].所以,可以进一步探索如何利用真实世界大量未标注数据来获取合理的虚假评论数据集.
(4)虚假评论的冷启动问题.Wang 等[26]针对这个未被前人探索过的问题,提出了一个基于图结构与CNN卷积神经网络的模型.评论的真实性越早判别,造成的不利影响越小.新用户只发布一条虚假评论时,如何利用先验知识准确地判别评论的真实性具有重大意义.未来可以探索更多有效的检测模型.
