网络学术文档细粒度关联与聚合的信息组织机制研究
2019-02-25马翠嫦司徒俊峰曹树金
马翠嫦 司徒俊峰 曹树金


摘要:[目的/意义]随着人们对检索文档之间关联关系的理解越來越多样化和细粒度化,检索文档内信息单元间关联关系的构建显得越来越重要。本研究旨在以学术文档内信息单元间关联关系为基础,构建文档的细粒度聚合与关联机制。[方法/过程]本研究从跨体裁聚合单元知识体系所蕴涵的各类关联关系出发,从信息组在的角度阐述支持情景和语义关联的细粒度聚合理论框架、知识组织系统构建和聚合单元元数据标注等关键问题,并提出聚合机制。[结果/结论]研究认为构建蕴含聚合单元语义关系、学科领域语义关系、任务和文本关系的本体,采用可反应聚合单元层级与关联关系的聚合单元元数据,是细粒度聚合机制发挥效用的关键。
关键词:网络文档;学术资源;信息聚合;聚合机制;细粒度聚合;信息组织
DOl: 10 .3969/j .issn .1008 -0821 .2019 .12 .005
[中图分类号] G203 [文献标识码]A [文章编号]1008-0821( 2019) 12-0037-09
无论是从Vannevar Bush提出的Memex到TimBerners-Lee提出的语义网,从互联网出现初期的超链接到最近的关联数据,在网络信息发展的各个时期,人们从没停止对网络信息资源之间关联关系的探索,使得人们对网络资源之间关联关系的理解越来越多样化和细粒度化。因此,网络环境下信息单元之间关联关系的构建就显得非常重要。
在网络信息组织中,人们常常按照资源之间或资源与用户之间的各类关联关系进行组织。最基本的是按照学科领域概念间的语义关系进行组织,如分类法、主题法、学科领域本体等知识组织系统提供的概念间的语义关联关系。与此相对,还可按照用户需求与信息之间的关联关系进行组织,如根据用户需求进行相似网络产品的组织与呈现。这两种类型的关联关系正好对应广义和狭义的语义关联关系一狭义的语义关系仅指概念间的语义关系,如王知津的定义[1],而广义的语义关联关系包含多种类型语义关系,如Assefa S G的定义[2]的包含概念间的语义关系和基于用户需求的关联关系。由于单纯基于概念间关系的主题相关性检索匹配只能从语义层面确保检索结果的准确性,而无法完全确保这些信息对于用户的有用性,因此广义的关联关系更有利于提高信息组织的效用。
语义网环境下,基于概念间语义关联关系的知识发现、知识关联、知识组织系统构建等网络信息组织既有理论、方法与工具可为基于语义关系的知识组织提供良好的基础,关联数据理论和实践的盛行使得基于语义关联的网络资源组织粒度由资源载体细化到数据、信息本身,再加上学术文献内部结构单元的识别和自动化分技术的发展(如:[3-5]),使得语义信息组织朝着细粒度方向发展。然而,基于用户需求的资源之间的关联关系研究基本停留在资源或文档整体的层面,如基于用户需求的文档推荐或商品网页推荐等,因此难以建立用户需求与细粒度资源之间的关联,更不能实现面向用户需求和概念语义关联的广义的语义关联与聚合。
面向语义关联关系的细粒度聚合,是指以通用的或特定领域的知识体系为基础赋予资源语义,并根据语义关系对资源进行重新序化与组织,使原本分散的、异构的资源和资源的片段形成面向用户需求的、具有一定知识结构的序化知识。为了进一步实现基于概念与用户需求的学术文档细粒度关联与聚合,本文将面向细粒度聚合的网络学术文档内不同层级的信息单元称为聚合单元。作者在前期研究中探索了学术文档聚合单元划分的理论与方法,尝试建立用户需求与若干类体裁文档聚合单元之间的关联关系,但如何从信息组织和知识组织的角度构建基于概念语义关系和用户需求的语义关联与聚合机制?这一问题仍未得到回答。
为了解决这一问题,本文首先对聚合单元间关联关系以及细粒度聚合相关理论进行梳理和总结,提出面向情景关联与知识发现的细粒度聚合信息框架,进而探索细粒度聚合知识组织系统构建、聚合单元元数据语义标引等关键问题,最终提出聚合单元细粒度聚合的整体框架与机制。
1 理论基础
1.1 体裁理论与聚合单元划分
功能语言学中的体裁结构理论可为网络文档聚合单元的划分提供面向用户认知的普遍性基础。网络学术文档按照体裁类型不同而有各自的社会交际目标(可理解为作者的写作目的),遵循相应的语篇结构和话语意图,这就使得资源除了具有基于主题的语义关联关系外,同时也具有体裁交际目标所承载的结构化语言功能特征。例如:研究论文会包括摘要、引言、研究方法、研究结果、讨论/结论等一系列规范的体裁结构规则。因此,网络学术信息资源的知识组织中,除了可采用传统的基于学科领域术语本体外,还可以进一步利用文档体裁结构规则所蕴含的语义关系,从而实现语义关系更丰富的、更面向用户需求的细粒度聚合。
体裁早期的利用源于知识组织领域,早至亚里士多德就认识到体裁对文献分类的功能[6]。在图书情报学领域,体裁被广泛用于自动分类[7]、知识组织[8-10]、网页设计[6,11]和信息搜寻[12-13]等方面。
Zhang L借鉴功能语言学家Swales关于体裁分析的理论和CARS模型[14],利用体裁形式和结构特征,对心理学领域的研究论文的语言功能单元进行划分,探索信息使用任务与不同类型的语言功能之间的关系,从而辅助信息利用[15]。在此基础上,Zhang L更探索了信息使用任务情境下不同类型语言功能之间的关系,从而为知识组织提供参考[10]。Ma C-C和Cao S-J则借鉴体裁分析的理论对网络环境下的题录摘要、期刊论文、网络百科词条和学术博客文章进行体裁层级和类型的划分,建立了面向细粒度聚合的聚合单元分类体系[16]。
因而,体裁理论可为网络学术文档聚合单元的划分提供理论与方法依据:一方面可为聚合单元语言功能的解释、语义的赋予和聚合应用乃至基于学科领域体裁知识的聚合单元知识模型构建奠定基础;另一方面为聚合单元与用户信息获取任务的关联构建、面向特定任务的聚合单元之间关联关系的构建提供理论与方法基础。
1.2 信息资源聚合
信息资源聚合研究探索信息資源之间的各类语义关联关系,从而提高资源组织和利用效率。按照资源类型划分,信息资源聚合研究面向馆藏资源、微博、网络商业信息等多种类型。这些研究中,对基于聚合单元的细粒度聚合具有较高参考价值的研究包括:聚合单元元数据研究、多粒度语义标注机制研究、多维语义聚合、深度聚合研究等。
曹树金等构建面向聚合搜索的细粒度聚合单元元数据,以深入描述聚合单元的特征及其关系,从而促进知识发现并提升知识服务效率。作者主张聚合单元元数据涵盖访问元数据、物理元数据和语义元数据。其中,访问元数据包括标识符、关键词、来源等核心元素以及标题、主要责任者、日期、语种等资源与篇章方面的个别描述元素;物理元数据包括聚合层级.存储路径等核心元素以及阶段单元层级、图表类型等个别描述元素;语义元数据则包括话语意图和语义功能两个元素。该研究虽然构建了聚合单元元数据的框架,但并不涉及细粒度聚合信息组织框架下聚合单元元数据的标注和组织问题[17]。
多粒度语义标注机制研究方面,朱嘉贤、白伟华与李吉桂提出信息元的概念,提出构建信息元本体和信息元知识体系,并按照树状组织结构组织网络资源及其内部文档的内容。其中,资源信息元的概念与本文关注的聚合单元元数据类似,是对相关内容单元的信息描述,但该研究只要考虑网络资源本身和网络资源内部文档两个粒度层级,并未对文档内部内容进行进一步划分[18]。
多维语义聚合相关研究主要包括面向馆藏资源的聚合和面向网络资源的聚合研究。面向馆藏资源聚合的研究中,相关研究可包括:邱均平团队研究了基于资源本体的馆藏资源语义聚合,如:资源本体构建、语义化与存储研究[19]、馆藏资源语义化模型与技术研究[20]、资源本体构建理论研究[21]等,为基于主题以外的多维语义关系知识系统的构建与应用提供重要参考。何超等提出了基于本体的图书馆数字资源语义聚合与可视化模型,为图书馆数字资源的深度语义聚合提供语义知识的支持[22]。与之相似,欧石燕等提出一个基于本体与关联数据的图书馆多类型异构文献资源语义整合框架,实现语义网环境下图书馆资源的语义整合[23]。
在网络资源语义聚合方面,相关研究主要针对资源特征探索聚合的工具和方法,相关研究可包括:微博文本的内容、时间、空间、人物等多维度主题聚合[24]。基于语义关联和情景感知的信息资源推荐研究等[25]。
通过基于细粒度聚合相关研究我们可知,语义网络环境下,面向细粒度聚合的元数据和本体构建是实现多源异构资源整合、多粒度标注和语义聚合的基础和关键。其中,信息单元本体和树状组织管理结构的多粒度语义标注研究可为聚合单元本体的构建及其组织提供理论和方法参考,聚合单元元数据为网络资源细粒度聚合提供基本的描述框架,语义聚合相关研究则为各类语义关联的发现、构建和应用提供参考。
2 信息组组织基本理论框架
2.1 情景关联与知识发现
网络资源细粒度聚合作为面向用户的应用,在于按照用户需求对网络资源进行不同粒度的重组,从而更准确地满足用户信息获取的需求并支持知识发现。
与广义语义关联关系对应,用户信息获取需求的满足可在两个层次上实现,即:主题相关性性和资源的有用性。由于资源获取的准确性是传统信息检索系统的核心,用户查询主题和资源描述主题的匹配在信息检索研究中已有成熟的研究结论,可为信息聚合研究提供参考。而本文提出的信息聚合则在主题相关性的基础上,进行聚合单元划分及及其用户任务情景的关联的探索,从而提高信息的有用性,这就使得基于聚合单元的信息组织与呈现具备了情景性的要求。由于本体可为概念的匹配和关联提供准确性和全面性的保障,因此基于聚合单元分类体系与其任务关联属性的聚合单元本体,可为细粒度聚合提供主题以外更丰富的依据,使得聚合结果体现用户和资源的情景和语义关联。
在主题相关性和资源有用性的基础上,学科领域本体支持概念匹配和相关性扩展,再加上聚合单元本体所赋予的聚合单元更丰富的语义和关联关系,从而为细粒度信息单元的语义聚合提供更多的依据,使聚合单元形成具有一定知识结构的新聚合体。由于这些聚合资源之间具有知识语义关联,可以通过多种聚合网络来呈现资源之间的语义关联,并与用户进行可视化的呈现和交互。因而可为新信息和新知识的发现提供可能,这就使得基于聚合单元的信息组织与呈现具备了支持知识发现的要求。
2.2 网络学术文档细粒度聚合的信息组织框架
在信息资源聚合相关研究的基础上,本文着眼于网络资源细粒度聚合对于情景关联与知识发现的支持,提出网络资源细粒度聚合的信息组织框架,包括:网络学术文本的采集与预处理一主题与聚合单元识别一本体构建一资源描述一面向用户语义与情境需求的聚合与呈现5个主要步骤,如图1所示:
1)采集与预处理。对多源异构网络资源进行基于主题和非主体特征的采集,在此基础上完成细粒度聚合前的规范性描述。
2)主题与聚合单元识别。网络资源聚合单元是聚合的主要对象,对于采集的网络文档须按其体裁规则进行识别和划分,并对不同粒度的聚合单元进行主题识别,从而为资源的细粒度组织提供对象。
3)细粒度聚合本体构建。细粒度语义聚合需以本体作为语义描述和聚合处理的主要知识体系,如:聚合单元知识体系、学科领域知识体系、文档与任务知识体系等。
4)语义标注。依据领域本体和聚合单元本体对聚合单元的语义进行标注。其中,通过聚合单元本体划分细粒度聚合单元,通过领域本体,识别聚合单元的语义。每个聚合单元通过多个与之相关的概念进行标注,形成了一个多维、复合的语义概念。此外,通过聚合单元元数据,可对聚合单元进行全面描述与索引。
5)聚合与呈现。将用户需求语义空间与资源描述的语义空间进行语义匹配后,把满足用户需求的资源按照聚合单元之间的语义关系进行重组。聚合处理过程主要是语义匹配的过程,在此基础上可采用多种模式进行可视化呈现,并与用户进行交互。
3 支持细粒度聚合的信息组织关键问题
由于细粒度聚合要求组织对象从文本整体细化到文本局部,且须建立各层级文本之间以及各层级文本与用户需求之间的关联,这就要求信息组织理论与方法在细粒度知识组织系统构建、基于聚合单元元数据的标注与索引等关键环节进行适应性的改进和发展。
3.1 细粒度知识组织系统构建
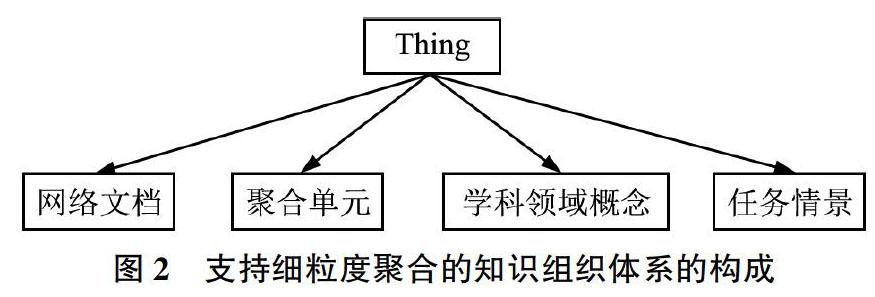
按照网络资源细粒度聚合的信息组织框架,支持细粒度聚合的知识组织系统除包括学科领域概念术语组成的面向主题聚合的知识体系,还应包括面向用户需求的、任务情景关联的聚合单元分类体系,此外还应建立面向文档描述与组织的文档本体,如图2所示。
其中,学科领域知识体系的构建已有较为成熟的理论和方法,其概念之间的等级和非等级关系可从资源内部的句法、共现、耦合等关系中识别建立。以下主要对知识体系的粒度特征、聚合单元知识体系的构建两个主要方面,对细粒度聚合的信息组织理论与方法进行探讨:
学科领域概念与聚合单元概念均具有粒度特征。對于领域概念粒度而言,其粒度按照概念间的知识关系与逻辑关系(如:属分关系、包含与被包含关系等)划分;对于聚合单元概念所反映的粒度而言,聚合单元按照上下级之间语言功能与语义上的包含与被包含关系划分粒度层级。
在聚合单元知识体系方面,邱均平团队提出基于非主题因素的资源本体的馆藏资源语义聚合研究,可为本文中基于聚合单元关系的多维语义知识组织系统构建路径提供参考。Ma C-C和Cao S-J借鉴体裁结构理论划分网络学术文档的聚合单元,从而构建跨体裁类型的聚合单元分类体系。该研究利用体裁的结构规定性和多粒度特性,构建包含不同层级、不同类型体裁实例的概念体系;体裁的特定社会交际目标,使得不同层级和类型体裁实例之间存在语言功能上的关联关系。由于用户对于学术体裁的格式和内容能产生相对一致的认识和期望,按照用户对于聚合单元的认知,调查特定任务情景下体裁及体裁单元的有用性,可构建任务相关性知识体系[16]。因而细粒度聚合知识组织系统中包括用户任务情景概念。
在概念间关系构建方面,按照细粒度体裁实例划分聚合单元,所形成的聚合单元概念之间存在3种主要的关联关系:一是同一体裁下围绕特定交流目的的同组聚合单元之间的推进关系。同组聚合单元之间通过推进关系实现上级聚合单元的交际目标;二是用户任务情景与各层级、各类型聚合单元之间的有用性差异形成的相关关系:三是围绕特定任务情景而形成的体裁实例之间的关联关系。如Zhang L的研究指出,在特定任务下,感知有用性程度高的语言功能单元之间实际上已经存在相关关系,包括同一构内的功能单元和不同构成间的功能单元。这些功能单元之间的关系,实际上可以通过语义关系来解释,也就是这些聚合单元之间围绕着某一任务,可以形成一定的语义关系[15],而任务下相关功能单元之间的关系更可形成语义相关的关系,从而帮助期刊论文内功能单元的语义信息组织[10]。
可见,聚合单元知识体系的构建的关键在于:建立基于体裁理论的、反应用户情景需求的聚合单元知识体系;对聚合单元分类体系的概念、概念之间关系和实例进行形式化,就可形成反应聚合单元知识体系的本体,从而支持对于文本信息单元的组织和检索。
3.2 基于聚合单元元数据的标注与组织
聚合单元元数据,是指聚合单元元数据框架下经标注的文档聚合单元,是标注与搜索的基本粒度单元。按照信息组织的基本理论,元数据是信息组织的重要工具。对细粒度聚合而言,对文档粒度属性的描述,对各层级聚合单元的描述和索引,乃至对聚合单元内容间的关联与利用,都依赖于元数据。因此,基于聚合单元元数据的标注与组织,是实现细粒度聚合的基础。
本文以曹树金等提出聚合单元元数据框架为主体[17],参考朱嘉贤、白伟华与李吉桂提出的基于资源信息元的组织方式[18],从聚合单元元数据标注的角度完善基于聚合单元元数据的语义标注与组织理论与方法。
聚合单元元数据的标注本质上是元数据方案的形式化,便于计算机对元数据信息进行存储、查找和处理。在确定元数据属性元素集后,先利用关系数据库系统实现标注元数据的查询、管理功能,再进一步进行XML置标,即:在标注元数据与文档聚合单元之间加一层基于XML的内容管理层,以便于将来独立于系统的长期保存、与其它系统的互操作等。
通过关系数据库对不同层级的聚合单元进行标注,可按照聚合单元知识体系的层级构建篇章一章节一句群三层数据库表,并按照聚合单元元数据的3类元素:物理元数据、访问元数据和语义元数据设置数据表字段。其中,篇章数据库表的主要字段应包括:Article ID. Title. Authors. Institution.Sources. Reference. Content. Last—Update. KeyWord、 Genre Type等。章节数据库表的主要字段包括:Section_ID. Article ID. Section_beginning_loca-tion. Section_Length. Last_Update. Key Word andSection_Genre_Type等。句群数据库表的主要字段包括:Unit_ID. Section_ID. Article_ID. Unit_be-ginning_ location、 Unit—Length、 Last—Update、 KeyWord and Unit_Genre_Type等。
通过3个数据表之间的关联,构建不同层级文本聚合单元之间的包含与被包含关系:数据表中标引的体裁类型信息(即聚合单元元数据中语义元数据类要素)与聚合单元本体中的聚合单元概念对应,使得不同体裁类型下不同层级聚合单元之间基于语言功能的语义关联成为可能:数据表中标引的关键词信息(即聚合单元元数据中访问元数据包含的要素)与学科领域本体对应,使得各体裁下各层级聚合单元实现基于主题的语义关联。3个层级聚合单元数据表及其之间的关联关系如图3所示:
通过XML对聚合单元元数据进行标注,可采用RDF/XML来描述元数据信息。RDF的基本数据模型是由三元体组成:资源( Resource)、属性( Property)和陈述(Statement)。其中,资源是主语( Subject),属性是谓词(Predicate),属性值则是对象( Object)[26]。使用RDF作为元数据的描述工具,可支持元数据进行语义互操作,这是细粒度聚合单元未来需要实现的,另一方面也可以与多种元数据进行交换不改变其语义。根据聚合单元元数据方案,以下以一个带有图文的句群级别聚合单元为例,来实现它的形式化描述。
<?xml version=”1.0”?>
xmlns: rdf= http: //www. w3. org/1999/02/22 - rdf-syntax-ns#
xmlns: ns= http: //www. sysu. edu.c n/2015/meta-dataaboutAS#>
Rdf: about=”http://www. sysu. edu. cn/2015/metadataaboutAS/Picture/A1 -P01>
图片单元
片段
网络环境下论文间的引用关系模型
A1_P 01
国外网络引文研究的现状及展望_1前沿
我们发现,网络环境下文献发生了巨大变化,形成了传统文献(print,P)和网络文献(web,W)两大类型。一方面,传统的学术论文仍是人们进行学术交流的主阵地;另一方面,网络资源和网络交流手段以其无可比拟的优点受到人们的青睐,其关系见图1。
jpg
16K
框架图
C:\Users\Administrator\Desktop\数据库\图片单元
在聚合单元对文档进行聚合单元划分后,采用自下而上的方法,借助聚合单元本体实现聚合单元元数据的语义标注。以聚合单元元数据为结点,逻辑上按照树状结构组织聚合单元知识库,将相互关联的聚合单元元数据最终构成的知识体系,从而为检索和聚合提供基础。
4 基于细粒度聚合本体的语义聚合与组织机制
在明晰细粒度聚合信息组织关键问题的基础上,本文在语义网环境下讨论网络资源细粒度聚合机制,从信息组织的角度进一步完善网络资源细粒度聚合的理论体系。语义网环境下,基于聚合单元本体、元数据等知识组织工具的细粒度语义聚合机制如图4所示。
从图4可见,在对网络文档资源进行聚合单元的划分、抽取、元数据标注和索引后,通过细粒度聚合本体赋予聚合单元更丰富的语义关联关系和情景关联关系,从而支持用户聚合语义相关的细粒度网络文档资源。
网络文档细粒度聚合既需要学科领域本体的支持,同时也需要任务情景关联的聚合单元本体的支持。领域本体一方面可通过其概念体系更全面地、更多维地构建语义空间描述网络资源;另一方面,依据领域本体中概念之间的各种等级和非等级的关系,建立资源之间的语义关联网络。通过本体提供的语义空间和语义关系,可进一步设计语义匹配算法,将资源和用户的聚合检索提问进行语义匹配,并根据匹配结果将相关资源重组成内在语义关联的聚合结果,通过可视化等形式呈现给用户,以便用户通过知识结构发现更多可能的、隐藏的新资源和新知识;聚合单元本体则可为网络文档信息单元的划分、关联关系构建提供知识参考,建立资源之间以及资源与用户之间的语义关联网络,成为学科领域本体的补充。
在明晰语义关系的基础上,对聚合单元、元数据和本体均通过RDF、XML或XML Schema进行标引,将其纳入语义网体系结构框架内,从而实现语义网环境下的资源描述、组织与揭示。 从信息组织机制来看,聚合单元元数据与细粒度聚合本体通过不同类型索引数据库的组织,为细粒度聚合提供支持。网络文档细粒度聚合的信息组织机制如图5所示。
从图5可见,网络文档细粒度聚合的机制始于不同层级聚合单元元数据的构建,而聚合单元元数据的构建则以细粒度聚合本体为基础。对于网络文档原始信息,通过聚合单元元数据描述主文档、构成单元和聚合单元3个层级的信息对象,从而形成主元数据文档、构成单元元数据文档和聚合单元元数据文档。同时,根据细粒度聚合本体提供的不同层级聚合单元之间的包含与被包含关系、同组内聚合单元之间的语义推进关系、学科领域概念之间的等级关系、相关关系、学科领域概念与聚合单元之间的描述关系,任务情景与聚合单元之间的不同强度的相关关系、文档与聚合单元之间的描述关系等,构建聚合关系索引。
为了支持多途径快速检索,根据聚合检索元数据项构建检索点,按照检索点对元数据文档进行关键字段的抽词、排序、归并、装配倒排文档,从而建立多组面向不同层级聚合单元的倒排文档和倒排文档索引。
用戶向聚合系统提出聚合检索需求后,系统将其检索需求映射到检索元数据中,并从细粒度聚合本体获得语义关系和关联关系。系统按照检索元数据对各层级聚合单元的各组倒排档索引进行检索,按照聚合关系索引实现在不同层级和不同维度的聚合单元之间进行跳转,从而实现高效的多维度和细粒度聚合。
可见,要实现基于聚合单元分类体系的情景关联和语义关联的细粒度聚合,构建蕴含聚合单元语义关系、学科领域语义关系、任务与文本关系的细粒度聚合本体是关键。
5 讨论
语义网环境下,网络资源之间的关联关系更复杂多样,网络资源识别、组织与利用的粒度更加细化,基于网络文档主题概念的语义关联关系已经不能完全满足用户需求。本文在基于主题的关联关系的基础上,提出利用用户与多粒度体裁实例间关联关系实现资源重组的信息组织路径,以实现情景与语义关联的细粒度聚合:按照语篇体裁结构划分聚合单元,以建立用户与聚合单元之间的关联关系为突破口,构建反应聚合单元知识体系及其与用户需求关联的细粒度聚合本体和与相应的聚合单元元数据,从而形成支持面向用户特定情景的、支持知识发现的细粒度聚合机制。
該研究不仅能推动网络学术资源细粒度聚合趋势下信息组织和知识组织理论的完善和发展,还可丰富网络学术资源细粒度聚合的理论。实践上,结合聚合单元知识体系、聚合单元元数据相关研究成果,本研究可为各学科领域网络资源细粒度聚合的实现提供整合的路径和方法,从而提供学科领域信息资源组织与利用的效率与效用。
该研究明晰了细粒度聚合本体构建的必要性、可行性与本体构建的目标,因而,后续研究可进一步探索反应聚合单元之间,聚合单元与用户之间以及聚合单元与源文档之间多维语义关系的细粒度聚合本体,提高网络学术文档细粒度聚合的效用。
参考文献
[1]王知津,郑悦萍,信息组织中的语义关系概念及类型[J].图书馆工作与研究,2013,(11):13-19.
[2] Assefa S G.Human Concept Cognition and Semantic Relations inthe Unified Medical Language System: A Coherence Analysis[D].
University of North Texas, 2007.
[3]王佳敏,陆伟,刘家伟,等,多层次融合的学术文本结构功能识别研究[J].图书情报工作,2019, 13:1-10.
[4]于丰畅,陆伟.基于机器视觉的PDF学术文献结构识别[J].情报学报,2019, 38 (4):384-390.
[5]方龙,李信,黄永,等.学术文本的结构功能识别——在关键词自动抽取中的应用[J].情报学报,2017, 36 (6):599- 605.
[6] Santini M, MehlerA,SharoffS. Riding the Rough Waves of Cenreon the Web: Concepts and Research Questions[ A]. In MehlerA, Sharoff S,&Santini M(Eds.), Cenres on the Web: Com-putational Models and Empirical Studies. Dordrecht, The Nether-lands: Springer, 2010: 3-30.
[7] Montesi M, Navarrete T.Classifying Web Cenres in Context:ACase Study Documenting the Web Genres Used by a Software Engi-neer[J]Information Processing and Management, 2008, 44:1410-1430.
[8] Crowston K,Kwasnik,B H.Can Document-Genre Metadata Im-prove Information Access to Large Digital Collections?[J]LihraryTrends, 2003, 52: 345-361.
[9] Nahotko M.Text Genres in Information Organization[C]//lnfor-mation Research, 2016, 21(4):732. http://lnformationR.net/ir/21 -4/paper732.html,
2019-05 - 04.
[10] Zhang L Linking Information through Function[ J]. Journal ofthe American Society for Information Science and Technology,2014, 63 (3):469-480.
[11] Vaughan M W, Dillon A.Leaming the Shape of Information:ALongitudinal Study of Web-News Reading[A].In Numberg P J,Hicks D L,FurutaR.(Ed.). Proceedings of the Fifth ACM Con-ference on Digital Libraries, New York: ACM, 2000: 236-237.
[12] Freund L.A Cross-Domain Analysis of Task and Cenre Effects onPerceptions of Usefulness[ J]. Information Processing and Man-agement, 2013, 48 (5):1108-1121.
[13] Hajibayova L,Jacob E K.An Investigation of the Levels of Ah-straction of Tags Across Three Resource Genres[J].InformationProcessing&Management, 2016. 52 (6): 1178-1187.
[14] Swales J M. Genre Analysis: English in Academic and ResearchSettings[M].Cambridge, UK: Cambridge University Press,1990.
[15] Zhang LGrasping the Structure of Joumal Articles: Utilizing theFunctions of Information Units [J]. Journal of the American Societyfor Information Science and Technology, 2012, 63 (3): 469-480.
[16] Ma C - C, Cao S -J. ldentifying Structural Genre ConventionsAcross Academic Web Documents for Information Use[A].Pro-ceedings of the Association for Information Science&Technology,Washington, 2017, 54 (1): 260-267.
[17]曹树金,李洁娜,王志红,面向网络信息资源聚合搜索的细粒度聚合单元元数据研究[J].中国图书馆学报,2017, 43(4):74-92.
[18]朱嘉贤,白伟华,李吉桂.Web资源的多粒度语义标注及其应用技术研究[J].计算机科学,2011, 38(8):83-87.
[19]邱均平,楼雯,余凡,等,基于资源本体的馆藏资源语义化研究[J]图书馆论坛,2013,33 (6):1-7.
[20]楼雯.馆藏资源语义化关键技术及实证研究[J].中国图书馆学报,2013,39 (6):27-40.
[21]邱均平,杨强,楼雯.资源本体构建理论与实证研究[J].情报理论与实践,2014,37 (5):1-6.
[22]何超,张玉峰.基于本体的馆藏数字资源语义聚合与可视化研究[J].情报理论与实践,2013,36 (10):73-76,39.
[23]欧石燕,胡珊,张帅.本体与关联数据驱动的图书馆信息资源语义整合方法及其测评[J].图书情报工作,2014,58(2):5-13.
[24]成全,周兰芳,面向语义关联的微博信息多维主题聚合研究[J].情报理论与实践,2018,41 (7):136-142.
[25]李楓林,陈德鑫,梁少星,基于语义关联和情景感知的个性化推荐方法研究[J].情报杂志,2015,34 (10):189-195.
[26] RDF Primer[ EB/OL] http://www.w3.org/TR/2004/REC-rdf -primer-20040210/,2019-05-04.
(责任编辑:孙国雷)
收稿日期:2019-09-21
基金项目:中央高校基本科研业务费项目“支持跨学科知识发现的学术论文信息单元识别与聚合研究”(项目编号:17wkpy56);国家社会科学基金重大项目“基于特定领域的网络资源知识组织与导航机制研究”(项目编号:12&ZD222)。
作者简介:马翠嫦(1981-),女,副研究馆员,研究方向:信息组织与行为、资源建设。司徒俊锋(1980-),男,副研究馆员,研究方向:信息组织、知识组织。曹树金(1962-),男,教授、博士生导师,研究方向:信息组织与行为。
