运用改进型LDA算法的电商微博热点话题研究
2019-02-06孟小璐
姚 洁,孟小璐
(福州外语外贸学院,福州 350202)
2018年6月阿里和微博联合发布了电商营销的“u微计划”,将打通双方平台的用户数据,实现微博种草、阿里拔草。也就是说,以后微博推送的内容会更符合消费者喜好,诱发消费者“剁手”的可能性也越大。目前,主流的电商企业也都想方设法利用微博进行品牌营销,其主要看中微博所带来的口碑营销、人际传播等效应。而微博用户数众多,所涉及的话题领域广,电商企业发布的营销微博往往被这些杂乱无章的信息淹没,因此对电商微博的主题挖掘就尤为重要。
近年来,主题模型是文本挖掘领域的一个热门话题,而LDA模型以其优秀的降维能力和良好的扩展性被广泛应用。例如,Phan等[1]通过LDA模型在Web片段文本搜索的准确度上有了进一步的提升;唐杰等[2-3]成功地将LDA模型应用到专利挖掘中。但是由于微博篇幅较短,通过共同出现的词来判断文本相似度的方法其准确度不高,挖掘效果不理想。为了规避短文本数据噪声大的问题,基于模型扩展的方法也层出不穷。例如,Zhang等[4]利用频率统计的方法让话题更靠前;Wayne等[5]提出了Twitter-LDA来规避非热点词汇,解决文本短和高频词的问题。但是这些方法需要事先训练和人工干预,而且主题少。
1 理论基础
1.1 传统LDA模型
LDA模型是由Blei等[6]提出的一种适用于话题提取的概率生成式主题模型,是一种无监督学习,主要依靠词之间的关联来挖掘主题的词袋模型。LDA基于分层式的贝叶斯模型,其中包含文档、主题和词3层。其模型如图1所示。
LDA 3层结构形成“文档-主题”和“主题-词”两个矩阵,其主要思想可以理解成两个物理过程:

图1 LDA模型

在现实中,文档及其每篇文档的词的组成都是已知的,再通过Gibbs抽样方法求得未知变量和。对于特定词t,可得:

1.2 LDA模型用于电商微博热点话题发现的形势分析
LDA主题模型能够有效地解决电商微博文本的稀疏性、高纬性、语法不规范性及主题分布不一致等问题。但同时,电商微博的文本形式也存在自身的特点,如标签(电商微博文本中采用哈希标签,其格式为“#话题名称#”。这类文本能够有效地表达热点话题,具有重要的用户特征和日期特征。)、时间戳、转发数及评论数。如果撇开这些属性直接在海量的微博消息中进行热点话题的挖掘,往往准确率和效率都不大理想。针对电商微博的这些特殊的文本形式,同时借鉴LDA主题模型,提出了一种新的电商微博热点挖掘模型MALDA(又称多属性的LDA)。
2 基于MA-LDA挖掘电商微博热点话题
2.1 框架结构
MA-LDA模型的主要思想:首先挑选高转发和高评论数的潜在热点电商微博(转发、评论数的阈值为1 000)[7]。接着通过时效性原则(即在某一特定时间内频繁出现),将一个关于时间因素的二值变量X引入MA-LDA模型中。最后我们将哈希标签也合并到MA-LDA模型中,从而提高主题的准确性。框架见图2。

图2 MA-LDA框架结构
2.2 MA-LDA模型
MA-LDA是在LDA的基础上扩展而来的,其模型如图3所示。该模型在原有LDA模型基础上增加了如下几个参数:
1)两种不同的主题类型,产生两个变量,即热点主题分布→和一般主题分布→。
2)为了判别电商微博主题是否为热点,保证时效性,加入了一个与时间相关的二值变量x,其中,xw表示词的时间分布的二值变量;xd表示文档的时间分布的二值变量。并引入某一词wi的时间特征值Sw,其计算公式如下:

其中:fw,t是词w在t∈(1,T)上出现的频率;favg是对应的fw,t的平均值。当Sw>0.5时,就认为该词为热词。模型中的xw和xd则可通过Sw判定:

最终,x的结果由xw和xd经过或运算得到(x=0时为热点主题,否则为一般主题)。
3)定义了词和文档的标签向量→λv={λ1,λ2,…,λw,…,λV}和→λm={λ1,λ2,…,λm,…,λM},主要用于热点主题相关的文档生成。

图3 MA-LDA模型图
其核心公式如下:

与LDA相同,MA-LDA模型的参数估计也同样使用Gibbs抽样。得到电商微博热点主题相关的两个变量如下:


3 实验结果与分析
3.1 实验数据收集及预处理
MA-LDA模型的评估实验数据主要通过腾讯微博官方API结构获得,通过人工收集和整理,得到较为影响力的30多家电商企业在2017-01-01—2018-01-01之间发布的微博数据,共58 973条,其中包含微博文本、用户ID、标签、时间、转发数及评论数等相关信息。
为了有效挖掘电商微博的热点话题,对这些数据进行了如下处理:
1)首先根据转发和评论数的阈值筛选热点话题,并计算词的时间分布特征,初始化Sw,xw,xd和x。
2)选用中科院计算基数研究所推出的中文分词系统ICTCLAS对微博文本属性进行预处理,包括对微博文本预料进行分词、词性标注、去除标点符号、停用词、表情词等。
3)抽取标签词,即微博中的“#……#”之间的内容,并对标签向量→λv和→λm进行初始化。
4)英文词汇进行词干化处理。
在参数设置上,根据相关文献的研究,分别对Dirichlet先验参数→α和→β设置为0.5和0.1[8-9]。
3.2 实验结果分析
1)电商微博热词概率降序排序。显示了MA-LDA和传统LDA主题模型的主题热词,并按照降序排序,如表1、2所示:
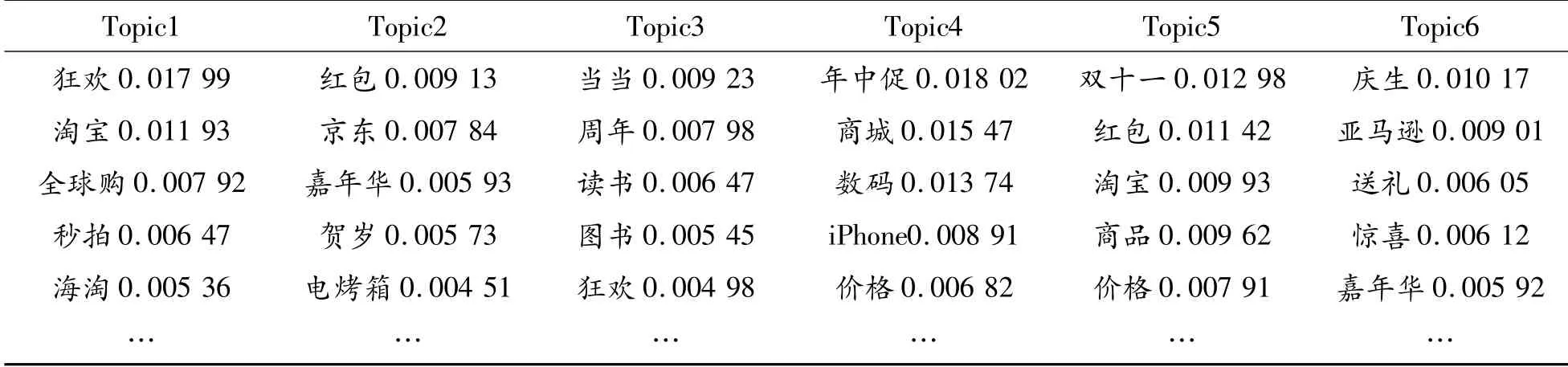
表1 传统LDA模型主题分布

表2 MA-LDA模型主题分布
表1、2分别显示了两个模型各自主题降序排序的热词,可以看出MA-LDA模型热词挖掘的准确率高于传统LDA模型,而且MA-LDA模型挖掘的热词均为数据集中的热词,而LDA模型并非都是热词。因此,MA-LDA模型可更准确且有效地挖掘各主题下的热词。
4 结束语
本文提出的MA-LDA模型是对传统LDA模型的扩展,其优势主要有:
1)对于电商微博文本,其热点话题挖掘准确率高。
2)通过设置转发数、评论数等参数过滤掉了不重要的信息,提高了运行效率。
3)主题数和迭代数对热点话题的识别影响较小。
MA-LDA模型能够有效解决稀疏性导致的文档关联相对较弱的问题;短文本语义信息有限;高纬性所带来的挖掘效率低;微博信息随机性强等问题。但是该模型对话题的生存周期较敏感,主要适应于短时间内被普遍关注的电商微博。同时,该模型需要对数据进行预处理,在整个主题挖掘的时效性上低于传统LDA模型。
