基于混沌特性的语音信号分类
2019-01-21张其进张玉梅
张其进,张玉梅
(1.陕西师范大学 现代教学技术教育部重点实验室,陕西 西安 710119;2.陕西师范大学 计算机科学学院,陕西 西安 710119)
0 引 言
在语音信号处理中,分类问题一直是基础性的但又难以解决的课题之一。语音分类在语音预测、语音编码和解码等领域中都有广泛的应用。语音的产生依赖于发音器官,包括肺、气管、声带、口腔、鼻腔和嘴唇等[1]。语音信号具有混沌特性,这是因为语音信号会在声道边际层产生涡流,并最终形成一种湍流,而湍流本身已经证实就是一种具有混沌特性的现象。Lyapunov指数[2]能够给出系统分类对系统初始化值的依赖度。现有研究多是基于特征量对语音信号进行识别与预测,而基于混沌特性的语音信号分类研究则较少。
文中以混沌理论中相空间重构[3]为基础,采集同人群、不同发音的各类语音信号,计算出延迟时间和嵌入维数后求出其最大Lyapunov指数,探究其规律,找出各类信号的最大Lyapunov指数的分布区间,完成基于最大Lyapunov指数的语音信号分类。该方法将采集来的语音信号根据其最大Lyapunov指数进行分类,进一步说明了语音信号与混沌理论的切合性,并为语音信号的分类提供了新依据。
1 语音信号混沌特性的方法分析
1.1 相空间重构
研究语音信号的混沌特性需要还原出混沌特性系统的复杂动力学特征。Takens嵌入定理[4]中证明了混沌系统最重要的两个参数—嵌入维数m和延时时间τ的存在,通过相空间重构技术提取出混沌语音信号的性质和规律。相空间重构的原理如下:
设x(t),t=1,2,…,N为混沌语音信号时间序列,在m维相空间中的状态转移形式为:
Y(t+1)=f(Y(t))
(1)
其中,Y(t)为相空间中的点,τ为延迟时间,且
Y(t)=(x(t),…,x(t+(m-1)τ))
(2)
展开得:
(x(t+1),…,x(t+1+(m-1)τ))=f(x(t),…,x(t+(m-1)τ))
(3)
在重构的相空间中,第n+τ个向量的前m-1个分量为第n个向量的后m-1个分量(τ为时间延迟,m为嵌入维数)。如表1所示的时间序列{1,2,3,4,5,6,7,8,9,10,11,12,13,14,15},假设其嵌入维数m为6,延时时间τ为3,则对其重构相空间得到向量。第四个向量x4的前3个分量为第一个向量x1的后3个分量,第五个向量x5的前三个分量为第二个向量x2的后三个分量。
通过求取出表1中语音信号正确的嵌入维数m和延迟时间τ,可以恢复语音信号的非线性动力学特征。文献[5]总结介绍了多种方法,其中互信息法[6]是估计延迟时间τ的有效方法,Cao方法[7]是嵌入维数m选取最常用的方法,在相空间重构中有广泛应用。因此,文中分别采用互信息法求取延迟时间τ,用Cao方法来选取嵌入维数m。

表1 相空间重构
1.2 互信息法计算延迟时间
在理论上,对一个理想的无限长和无噪声的语音信号时间序列,延迟时间的选取是任意的,但是实际中的语音信号序列是有限长度且存在噪声的,所以在实际应用中,延迟时间并不能随意取值。设观测时间序列为{x(i),i=1,2,…,N},则在i和i+τ时刻观测量之间的互信息函数为:
(4)
其中,P[x(i)]为点x(i)的概率密度;P[x(i),x(i+τ)]为点x(i)和x(i+τ)的联合概率。一般选择I(τ)求取到的第一个局部最小的τ为延迟时间,此时产生的冗余最小,并具有最大独立性,能够很好地还原混沌系统的动力学特性。
1.3 Cao方法计算嵌入维数
假设有一组时间序列x1,x2,…,xN,延迟时间向量可以被重构为:
yi(d)=(xi,xi+τ,…,xi+(d-1)τ),i=1,2,…,N-(d-1)τ
(5)
其中,d为嵌入维数;τ为延迟时间。记yi(d)为当嵌入维数为d时的第i个重构向量。类似的,yi(d+1)是嵌入维数为d+1时的第i个重构向量。
如果d是合适的嵌入维数,那么d维重构相空间中邻近的任意两点,如果在d+1维重构之后的空间中仍然邻近,称这样的一对点为真邻近点;否则,称其为虚假邻近点[8]。正确的嵌入意味着没有虚假邻近点存在,通常通过判断a(i,d)是否大于给定的阈值来确定是否是虚假邻近点,其中
a(i,d)=|xi+dτ-xn(i,d)+dτ|/‖yi(d)-yn(i,d)(d)‖
(6)
从a(i,d)的定义来看,对不同的点i,至少在理论上a(i,d)应该有不同的阈值。不同的时间序列可能有不同的阈值。这说明只依靠嵌入维数d和每个轨线上的点以及给定的时间序列来得出正确且合理的阈值是很困难的。为了避免这个问题,定义:
(7)
E(d)只取决于嵌入维数d和延迟τ。为了研究E(d)从d到d+1的变化,定义:
E1(d)=E(d+1)/E(d)
(8)
当d比某一d0大时,如果E1(d)停止改变,那么d0+1即为最小嵌入维数。理论上,在随机的时间序列中,随着d的增长,E1(d)永远不会达到饱和值停止变化。但是由于可供观测的数据样本有限,虽然时间序列是随机的,E1(d)有可能在某一d值时停止变化。因此,为了减小计算误差,使结果更加准确,需要再计算E2(d)。
定义:
(9)
E2(d)=E*(d+1)/E*(d)
(10)
由于未来的新值与之前的值无关,E2(d)在这种情况下对任何d来讲,值都为1。但是,对确定的时间序列,E2(d)是确实与d相关的。所以,必定存在某一d值,使E2(d)≠1。当E1(d)和E2(d)都在1附近稳定时,即得到了最小嵌入维数。要确定时间序列的最小嵌入维数,必须计算E1(d)和E2(d),以便从随机时间序列中区分出确定的时间序列。
2 小数据量法计算最大Lyapunov指数
Lyapunov指数是指系统邻近两个或者多个轨道整体分离速率指数的评估,是对产生时间序列数据的系统混沌特性大小的衡量标准之一。最大Lyapunov指数作为混沌系统的一个重要特征量,是混沌特性识别的主要依据之一。当最大Lyapunov指数小于零时,系统具有部分稳定的点;当最大Lyapunov指数等于零时,则对应着多个呈现周期性循环的解集或者存在系统分离点;系统的最大Lyapunov指数作为衡量是否具有混沌特性的标志,当最大Lyapunov指数大于零时,认为符合混沌系统的特点。
1993年Rosenstein等[9]提出了用于计算小数据量样本最大Lyapunov指数的小数据量法。它具有计算速度快、抗噪声能力强的特点。其计算过程如下:
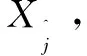
其中,j=N0,N0+1,…,N,N0=(m-1)τ+1,dj(0)表示到第j个点的最近距离,P为混沌时间序列的平均周期,则最大Lyapunov指数可通过重构之后的相空间中每个点的最近邻点的平均发散速率进行估计。最大Lyapunov指数[10]估计公式为:
(12)
其中,i=N0,N0+1,…,N,Δt为样本周期,dj(i)是第j个最近邻点经过i个离散时间步长的距离。
后来Sato等将该估计公式改进为:

(13)
其中,k是常数,最大Lyapunov指数在此时的含义为系统总体混沌水平的量的估计。结合Sato等的估计式有:
dj(i)≈Cjeλ1(Δt),Cj=dj(0)
(14)
将上式两边取对数得到:
lndj(i)≈lnCj+λ1(i·Δt)
(15)
最大Lyapunov指数相当于上式直线的斜率,可通过最小二乘法[11]逼近这组直线而得到,即:
(16)
其中,q为非零dj(i)的数目,y(i)为距离dj(i)对q累积和的平均值。
3 实验分析与比较
实验采用计算机内插声卡,外接一个麦克风和两个喇叭,以组成文中的研究系统。利用该系统,采集了各种类型的语音,其中包括5个男声和5个女声。对语音采用8 kHz采样频率,8位的采样精度。经过大量的语音采集和人工剪切工作,得到了包括长单元音和所有双元音在内的样本共300个,作为实验样本。
由于辅音时长较短,致使误差较大,且辅音信号的送气强度及其与声道壁的摩擦程度均比元音信号要强,因此可以认为辅音信号的混沌程度[12]大于元音信号的混沌程度,在此不再测算辅音信号。
对采集的信号进行语音信号与处理、参数计算、语音筛选、特征归类这几个具体的步骤。对采集的语音信号分别选取延迟时间、嵌入维数,然后计算最大Lyapunov指数,并根据已有国际音标[13-14]的发音类型,寻找其最大Lyapunov指数的规律,得到其语音分布。
3.1 参数计算
延迟时间的求取使用互信息法,得到语音的嵌入维与误差的关系图,得到的第一个极小值,此时该值即为该语音的最小延迟时间。文中求取了说话者1/a:/的语音,延迟时间为2。
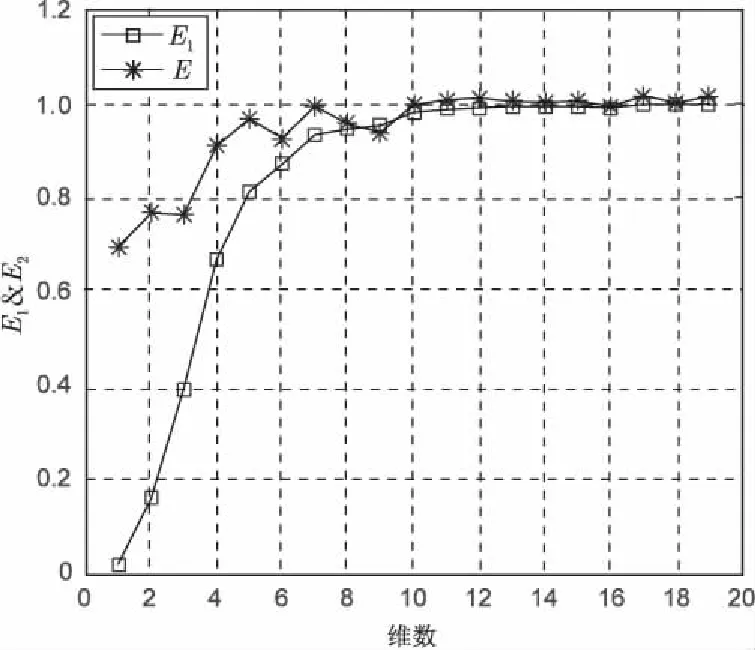
图1 说话者1/:/音的嵌入维数
图中下方的曲线代表E1(d),上方曲线条代表E2(d)。选取两者在纵坐标1附近趋于稳定的点,该点对应的横坐标即选取为嵌入维数。从图中可看出说话者1的/:/音的嵌入维数为11。
图2为求取说话者2的/ai/音的最大Lyapunov指数。如图所示,选取图中趋近于直线段的部分进行拟合,即100~300段,得到说话者2的/ai/音的最大Lyapunov指数为0.816 5。

图2 说话者2的/ai/音的最大Lyapunov指数
3.2 男声和女声的最大Lyapunov指数
对采集到的语音信号,按男声、女声分类,计算每一类各组发音的最大李雅普诺夫指数的平均值。
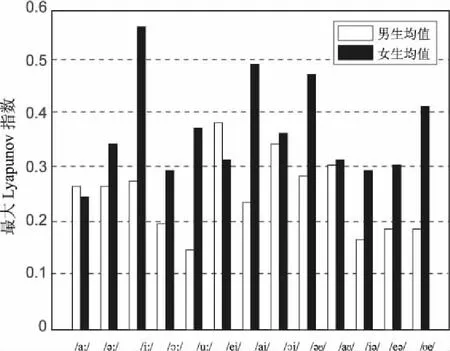
图3 各音素的男女均值比例
通过实验发现男生和女生的最大Lyapunov指数范围分别为0.138~0.377与0.313~0.560,结合图3可以发现,男声均值分布在0.14~0.38之间,女声均值分布在0.31~0.56之间。在这13组语音信号中,除了/a:/音和/ei/音的最大Lyapunov指数男声大于女声外,其余的音素的最大Lyapunov指数都是女声大于男声。而且/a:/音和/ei/音女声和男声的最大李雅普诺夫指数差值在0.03以内。因此在误差允许的范围内,可以确定对于同一个发音,女声的最大Lyapunov指数大于男声的最大Lyapunov指数。
3.3 各类元音的最大Lyapunov指数分类
英语音标中,按发音时舌活动的范围分类:长单元音分为前元音/i:/,中元音/:/和后元音/:/、/u:/、/a:/;双元音分为合口双元音/ei/、/ai/、/i/、/u/、/au /和集中双元音/i/、/ε/、/u/。计算得到每个音素的最大Lyapunov指数的平均值,如表2所示。
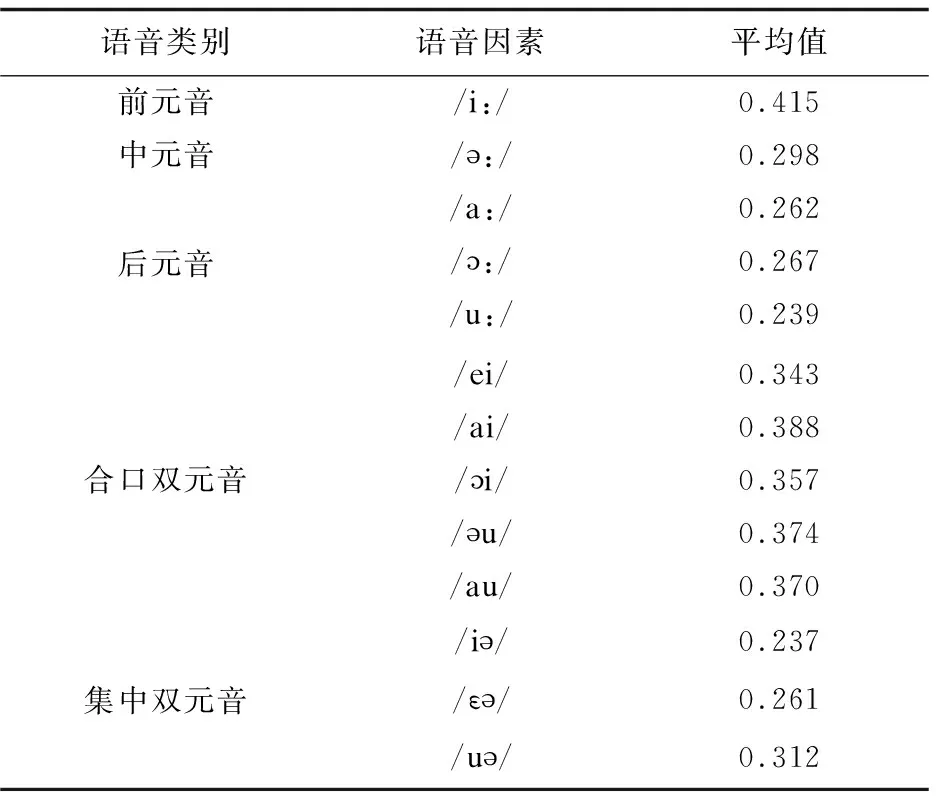
表2 各音素最大Lyapunov指数的平均值
可以看出:前元音的值在0.40~0.43之间,中元音的值在0.28~0.32之间,后元音则位于0.22~0.28;合口双元音的值在0.34~0.40之间,而集中双元音则在0.24~0.32之间。由此可以得出结论,长单元音中的前元音、中元音、后元音以及双元音中的合口双元音和集中双元音有明显的Lyapunov指数分界。
通过数据比对与分析,得出各类语音信号的最大Lyapunov指数具有以下特征:女声的最大Lyapunov指数大于男声的最大Lyapunov指数;前元音>中元音>后元音;合口双元音>集中双元音。
共采集300个样本,根据对元音最大Lyapunov指数的分类,求出各语音信号恰好落在对应分布区间的概率(见表3)。可见估计的分布区间都有高于90%的对应性,进一步证明了该结论的正确性。

表3 各类元音的最大Lyapunov指数分类区间
4 结束语
混沌理论在本质上是非线性的,可以弥补传统线性分析方法的不足,因此对于语音信号处理具有重要作用。文中通过采集大量语音样本,并进行大量的实验,进一步探究了语音信号的混沌特性,利用Lyapunov指数这一特征量,总结了各类语音音素的最大Lyapunov指数区间,寻找其规律,并实现了分类,为语音信号的进一步处理提供了数据基础,取得了比较满意的效果。
