计算机视觉研究综述
2018-12-26张晓亮梁星驰
张晓亮 梁星驰
计算机视觉研究综述
张晓亮 梁星驰
中国人民解放军32140部队,河北 石家庄 050000
研究综述了计算机视觉中分类与回归、目标跟踪、图像分割、图像超分辨率、风格转移、着色、行为识别、姿势预估和关键点监测等重要算法的原理和架构。
计算机视觉;神经网络
1 分类与回归
从ILSVRC 2017发布的分类与回归问题的结果(图1)可以看出,在分类与回归问题上的错误率又有了较大幅度下降。分析原因主要是网络的加深和对网络结构的优化。以往对网络优化,多从空间维度上进行。例如Inside-Outside考虑了空间中的上下文信息,还有将Attention机制引入空间维度。ResNet[1]很好地解决了随着网络深度的增加带来的梯度消失问题,将网络深度发展到152层。Inception[2]结构中嵌入了多尺度信息,聚合多种不同感受野上的特征来获得性能增益,目前已经发展到inceptionV4并由于ResNet融合。DenseNet[3]比ResNet更进一步,对前面每层都加了Shortcut,使得Feature map可以重复利用。每一层Feature被用到时,都可以被看作做了新的Normalization,即便去掉BN层,深层DenseNet也可以保证较好的收敛率[4]。
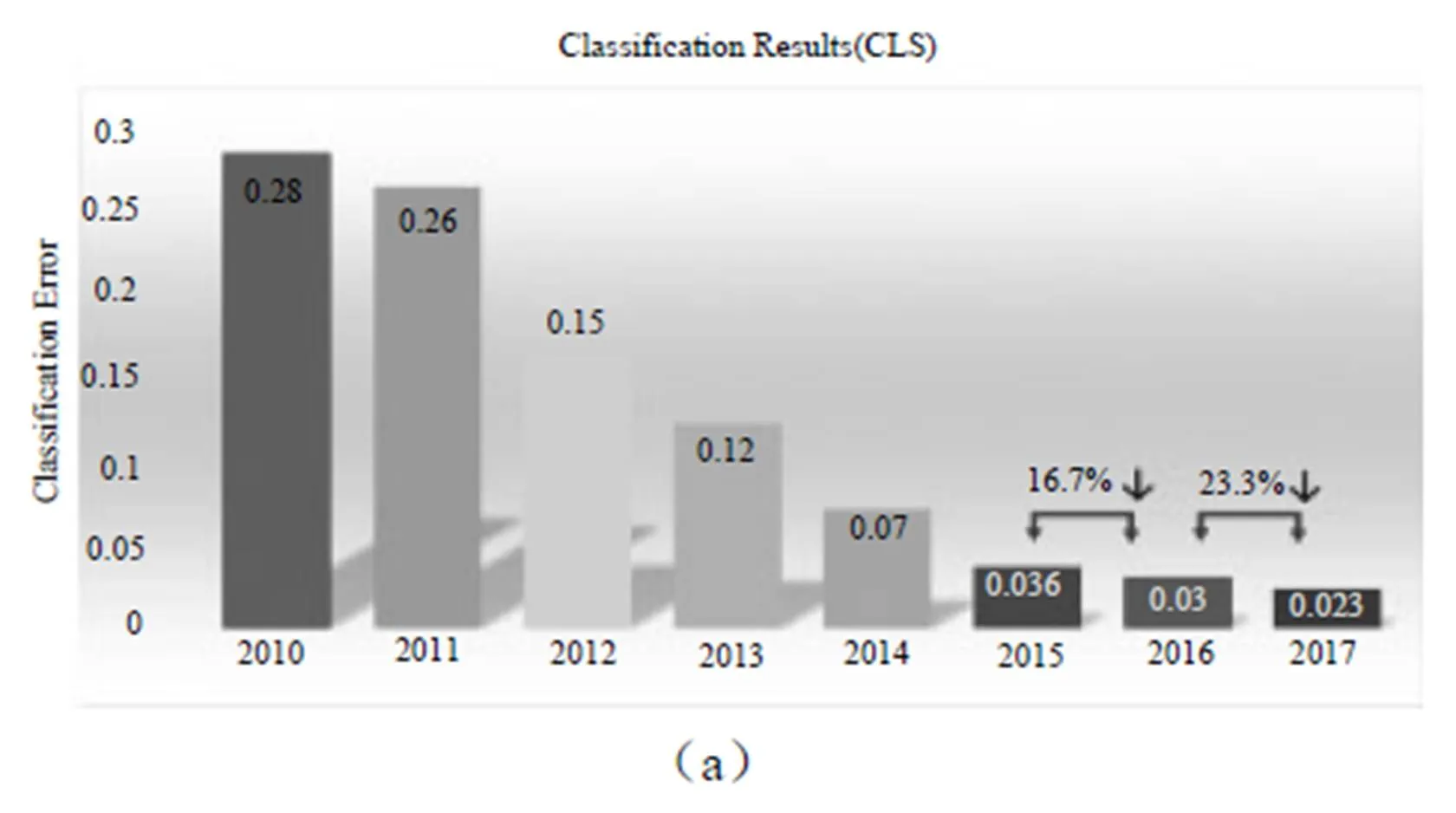
图1
今年的分类冠军是国内自动驾驶公司Momenta研发团队(WMW)提出的SEnet架构。与从空间角度提升网络性能有所不同,SEnet的核心思想是从特征通道的角度出发,为特征通道引入权重,通过学习权重参数来提升重要特征通道的地位。
SEnet架构如图2所示。在Squeeze步,将每个特征通道变成一个实数。这个实数某种程度上具有全局感受野,使得靠近输入的层也可以获得全局信息,这一点在很多任务中都是非常有用的。Excitation步是一个类似于循环神经网络中门的机制,通过参数w来为每个特征通道生成权重。最后是Reweight操作,我们将Excitation输出的权重看作特征选择后的每个特征通道的重要性,然后通过乘法逐通道加权到先前的特征上,完成在通道维度上的对原始特征的重标定。目前只见到相关介绍,还未见到成稿的论文发表。
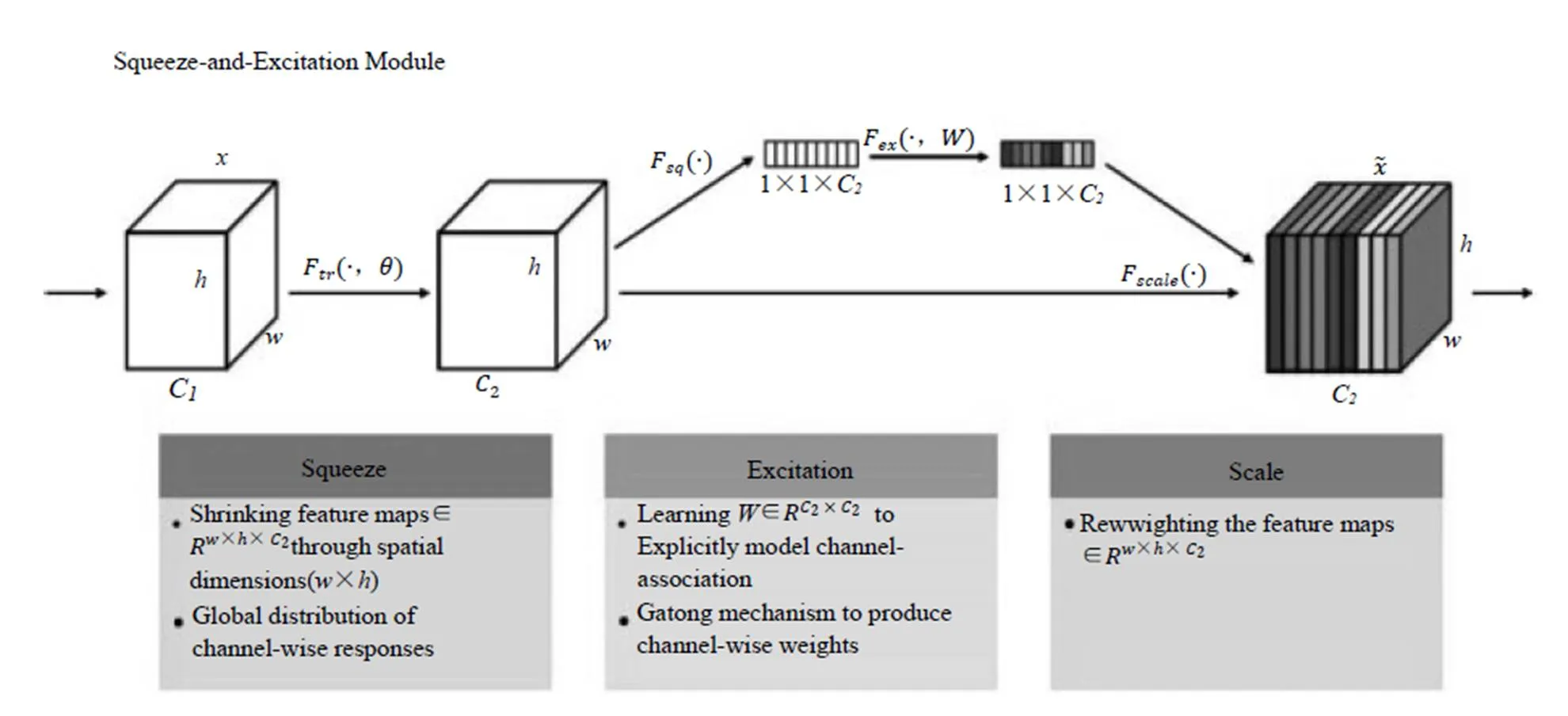
图2
2 目标检测
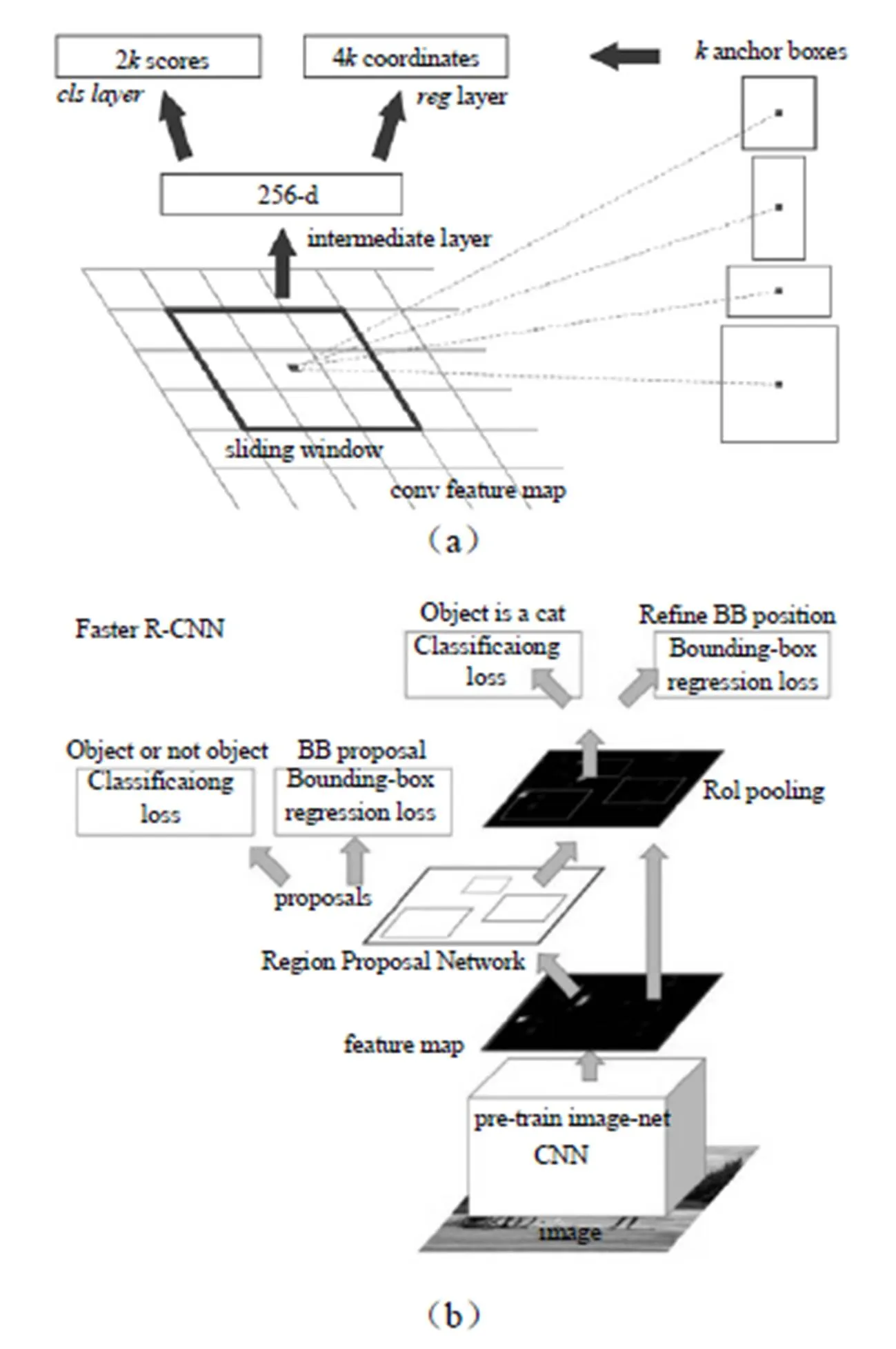
图3
随着自动驾驶、智能监控、人脸识别等大量有价值的应用逐步落地,快速、精准的目标检测系统市场也日益蓬勃,模型不断创新。Faster R-CNN、R-FCN、YOLO、SSD等是目前应用较广的模型。Faster R-CNN[5]的架构如图3所示,主要创新是用RPN网络代传统的“选择搜索”算法,使速度大幅提升,如图3所示,在最后卷即得到特征图上使用一个3×3的窗口滑动,并将其映射到一个更低的维度上,(如256维),在k个固定比例的anchor box生成多个可能的区域并输出分数和坐标。
分类需要特征具有平移不变性,而检测具有一定的平移敏感性。Faster R-CNN在ROI pooling前都是卷积,是具备平移不变性的,在ResNet的91层后插入ROI pooling,后面的网络结构就不再具备平移不变性了,而R-FCN[6]架构如图4所示,在ResNet的第101层插入ROI pooling,并去掉后面的average pooling层和全连接层,构成了一个完整的全卷积网络,提升了响应速度。其创新点在于ROI pooling中引入位置敏感分数图,直接进行分类和定位,省去了Faster R-CNN中每个Proposal图像单独计算的计算量。Faster R-CNN和R-FCN以及以前的其他变化的模型都是基于Region Proposal的,虽几经优化,在精度上达到最高,但无法做到实时,而SSD和YOLO兄弟都是基于回归思想的检验算法,精度不及Faster R-CNN,但是速度快(45 FPS/155 FPS)。YOLO V1[7]利用全连接层数据直接回归边框坐标和分类概率,YOLO V2[8]不再让类别的预测与每个cell(空间位置)绑定一起,而是让全部放到anchor box中,提高了召回率(从81%到88%),准确率略有下降(从69.5%到69.2%),文献[8]中还提出使用WordTree,把多个数据集整合在一起,分类数据集和通过实验过这个算法,识别速度特别快,能做到实时,检测数据集联合训练的机制,可检测9000 多种物体,缺陷就是准确率还有待提高,特别是小目标的识别效果不好。
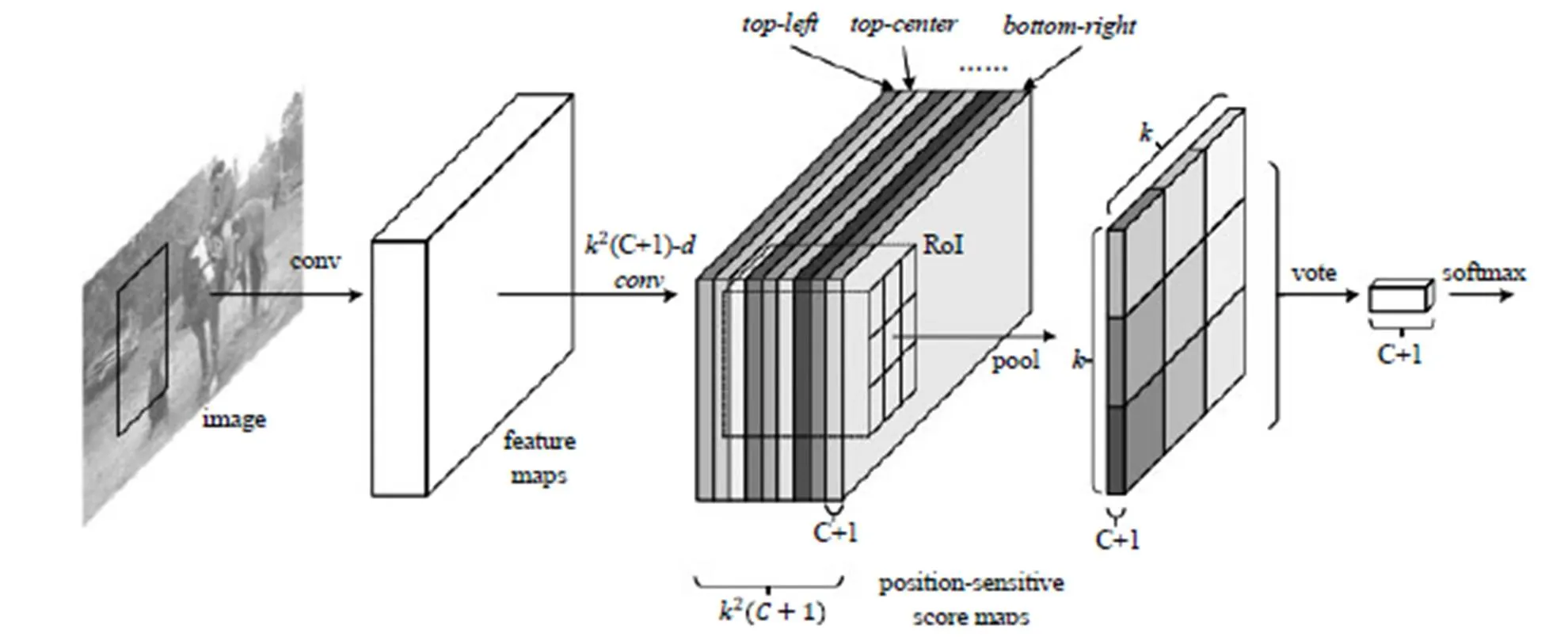
图4
图5
ILSVRC2017的目标检测冠军是BDAT团队,该团队包括来自南京信息工程大学和伦敦帝国理工学院的人员,目前尚未见到相关论文发表。
3 目标跟踪
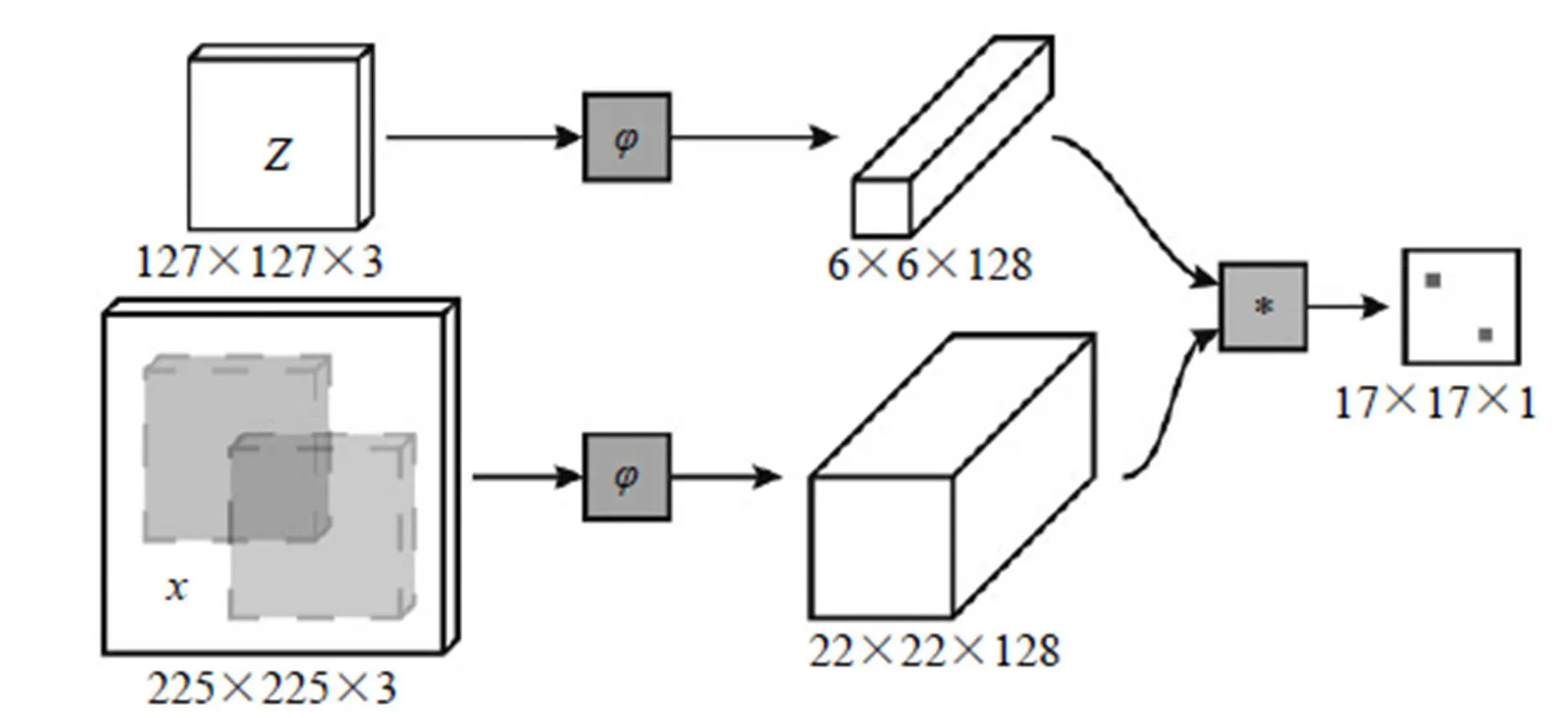
图6
在OpenCV 3.2集成了六种目标跟踪API,可以很方便地调用。其中BOOSTING、MIL、KCF、TLD和MEDIANFLOW都是基于传统算法的,GOTURN是基于深度学习的。通过实验,CV里集成的算法普遍存在对快速移动物体跟踪失效的问题。虽然目前深度学习算法与传统算法的距离没有拉开,相信后续还会有突破,这里只介绍基于深度学习的算法。GOTURN[9]是发表在ECCV 2016的一篇文章,也是第一个检测速度速度达到100 FPS的方法。
算法框架如图5所示,将上一帧的目标和当前帧的搜索区域同时经过CNN的卷积层,然后将卷积层的输出通过全连接层,用于回归当前帧目标的位置,文献作者发现前后帧的变化因子符合拉普拉斯分布,因此在训练中加入了这个先验知识,对数据进行了推广,整个训练过程是Offline的。在使用时只需要进行前馈运算,因此速度特别快。
SiameseFC[10]算法也是一个能做到实时的深度学习算法。如图6所示,算法本身是比较搜索区域与目标模板的相似度,最后得到搜索区域的score map。其实从原理上来说,这种方法和相关性滤波的方法很相似。
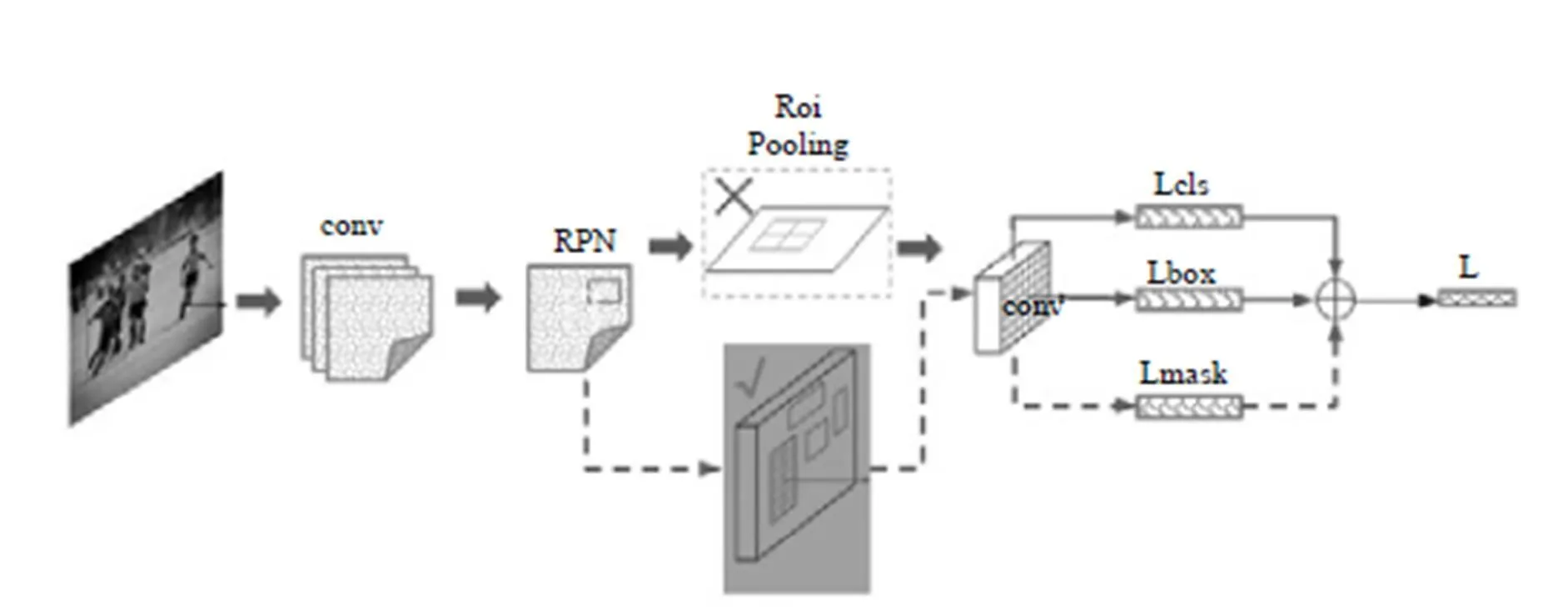
图7
4 图像分割
图像分割技术是自动驾驶的基础,具有商用价值。在这一领域贡献较大的是Facebook的人工智能研究中心(FAIR),该团队2015年开始研究DeepMask,生成粗糙的mask作为分割的初始形式。2016年,推出SharpMask[11],它改进了DeepMask提供的“蒙板”,纠正了细节的损失,改善了语义分割,除此之外MultiPathNet能标识每个掩码描绘的对象。
特别值得一提的是,今年何恺明又研究出一种新的架构Mask R-CNN[12],即一种基于像素级别的分割算法。
为便于理解,对Mask R-CNN原文图示进行了简单的修改,如图7所示,其主要思路是在Faster-RCNN的基础上进行拓展,将ROI Pooling层替换成ROI Align,使用双线性内插法,解决了像素对齐问题,并添加了mask层用于输出二进制掩码来说明给定像素是否为对象的一部分。通过我们的实验master R-CNN确实产生了非常精妙的分割效果,但对于某些样本的边缘分割,还存在像素分配错误的情况,尤其是对照低照度下成像的样本更明显。
5 图像超分辨率、风格转移、着色
大多数现有的SR算法将不同缩放因子的超分辨率问题作为独立的问题,需要各自进行训练,来处理各种scale。VDSR[13]可以在单个网络中同时处理多个scale的超分辨率,但需要双三次插值图像作为输入,消耗更多计算时间和存储空间。SRResNet[14]成功地解决了计算时间和内存的问题,并且有很好的性能,但它只是采用ResNet原始架构。ResNet目的是解决高级视觉问题。如果不对其修改直接应用于超分辨率这类低级视觉问题,那么就达不到最佳效果。微软的CNTK里提供了VDSR、DRNN、SRGA和SRResNet四种API,通过我们的实验确实能达到文献中描述的效果。
EDSR[15]是NTIRE 2017超分辨率挑战赛上获得冠军的方案。其架构如图8所示,去掉了ResNet中BN层,减少了计算和存储消耗。相同的计算资源下,EDSR就可以堆叠更多层或者使每层提取更多的特征。EDSR在训练时先训练低倍数上的采样模型,接着用得到的参数初始化高倍数上的采样模型,减少了高倍数上采样模型的训练时间,训练结果也更好。这个模型我们也试验过。与微软API里的SRGAN和SRResNet模型相比确实有差别,但肉眼很难区别得特别清楚,也可能是我们选择自己生活照为样本的原因。
Prisma在手机里的应用让更多人了解图像风格转换。文献[16]第一个将神经网络用在风格转换上,基于神经网络的风格转换算法得到更多的发展。在文献[17]中将风格转换应用到了视频上,画面风格转换,还是很完美的。文献[18]实现了基于像素级别的风格转换。
旧照片着色是很有趣的,文献[19]利用CNN作为前馈通道,训练了100万张彩色图像。在“彩色化图灵测试”评估中骗过32%的人类,高于以前的方法,正如文中所讲任何着色问题都具有数据集偏差问题。不是所有照片都能呈现完美效果。文献[20]利用低级和语义表示,训练模型预测每像素颜色直方图。该中间输出可用于自动生成颜色图像,或在图像形成之前进一步处理。文献[21]提出了一种新颖的技术来自动着色灰度图像结合了全局先验和局部图像特征,与基于CNN的大多数现有方法不同,该架构可以处理任何分辨率的图像。
文献[21]的框架如图9所示,由四个主要部分组成:一个低级特征网络,一个中级特征网络,一个全局特征网络和一个着色网络。这些组件都是紧密耦合的,并以端到端的方式进行训练。模型的输出是与亮度融合形成输出图像的色度。
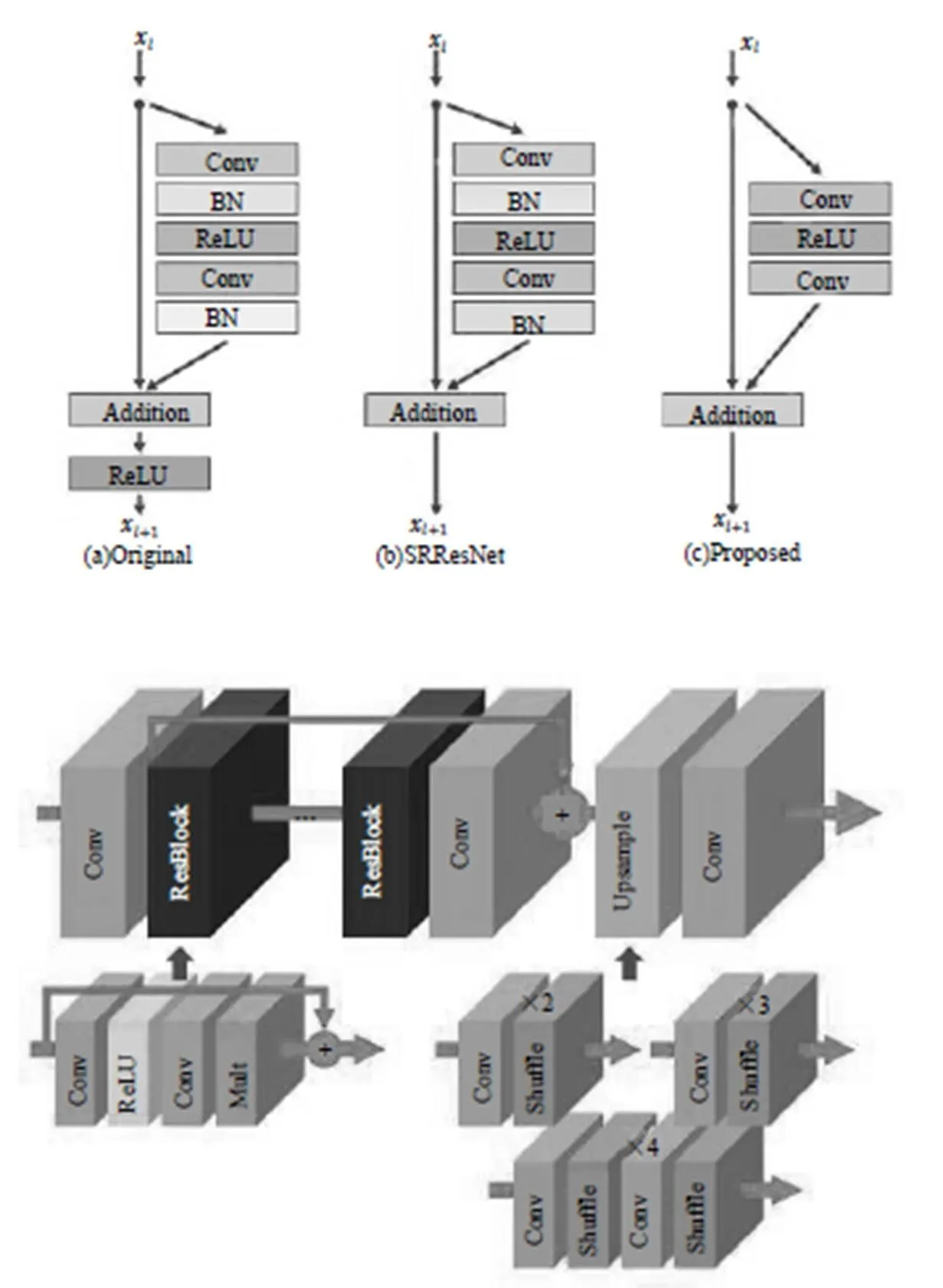
图8
图9
6 行为识别、姿势预估和关键点监测
文献[22]利用人类行为的时空结构,即特定的移动和持续时间,使用CNN变体正确识别动作。为了克服CNN长期行为建模的缺陷,作者提出了一种具有长时间卷积(LTC-CNN)的神经网络来提高动作识别的准确性。文献[23]用于视频动作识别的时空残差网络将双流CNN的变体应用于动作识别任务,该任务结合了来自传统CNN方法和ResNet的技术。文献[24]是CVPR 2017的论文,也是MSCOCO关键点检测冠军。使用Bottom-Up的方法,先去看一张图有哪些人体部位(Key Point),接着再想办法把这些部位正确的按照每个人的位置连起来算Pose。如图10所示,输入一幅图像,经过卷积网络(VGG19)提出特征,得到一组特征图,然后分成两个岔路分别使用CNN网络提取Part Confidence Maps和Part Affinity Fields,得到这两个信息后,使用图论中的Bipartite Matching将同一个人的关节点连接起来,得到最终的结果。
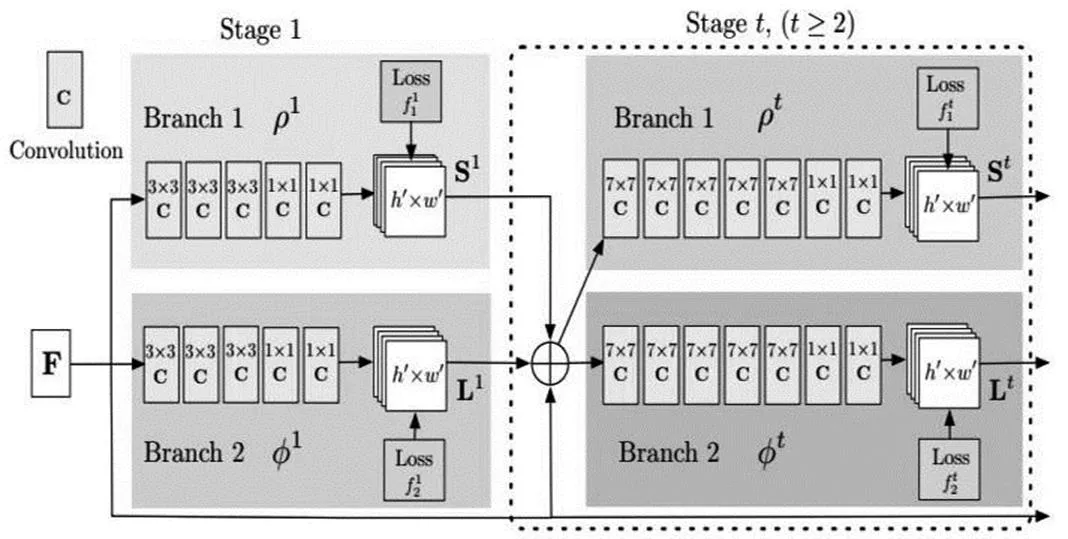
图10
7 卷积网络结构
卷积网络结构是基于深度学习的计算机视觉基础,从图11中可以看出2012年AlexNet网络取得历史性突破以来得到很大发展。
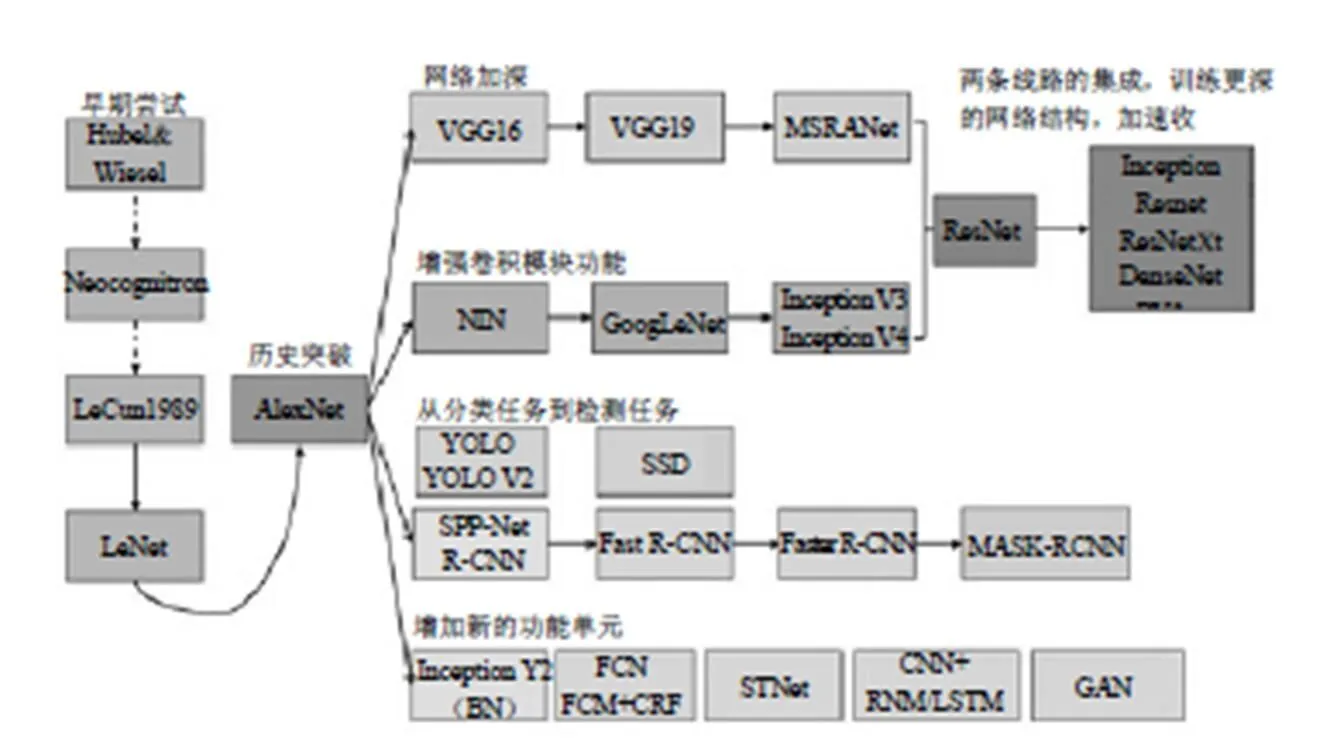
图11
我们都知道深层CNN存在梯度消失问题。ResNet通过“skip connection”。结构一定程度上促进了数据在层间的流通,但接近输出的网络层并没有充分获得网络前面的特征图。DenseNet[3]在前向传播基础上,网络每一层都能接受它前面所有层的特征图,并且数据聚合采用的是拼接,而非ResNet中的相加。网络模型如图12所示。
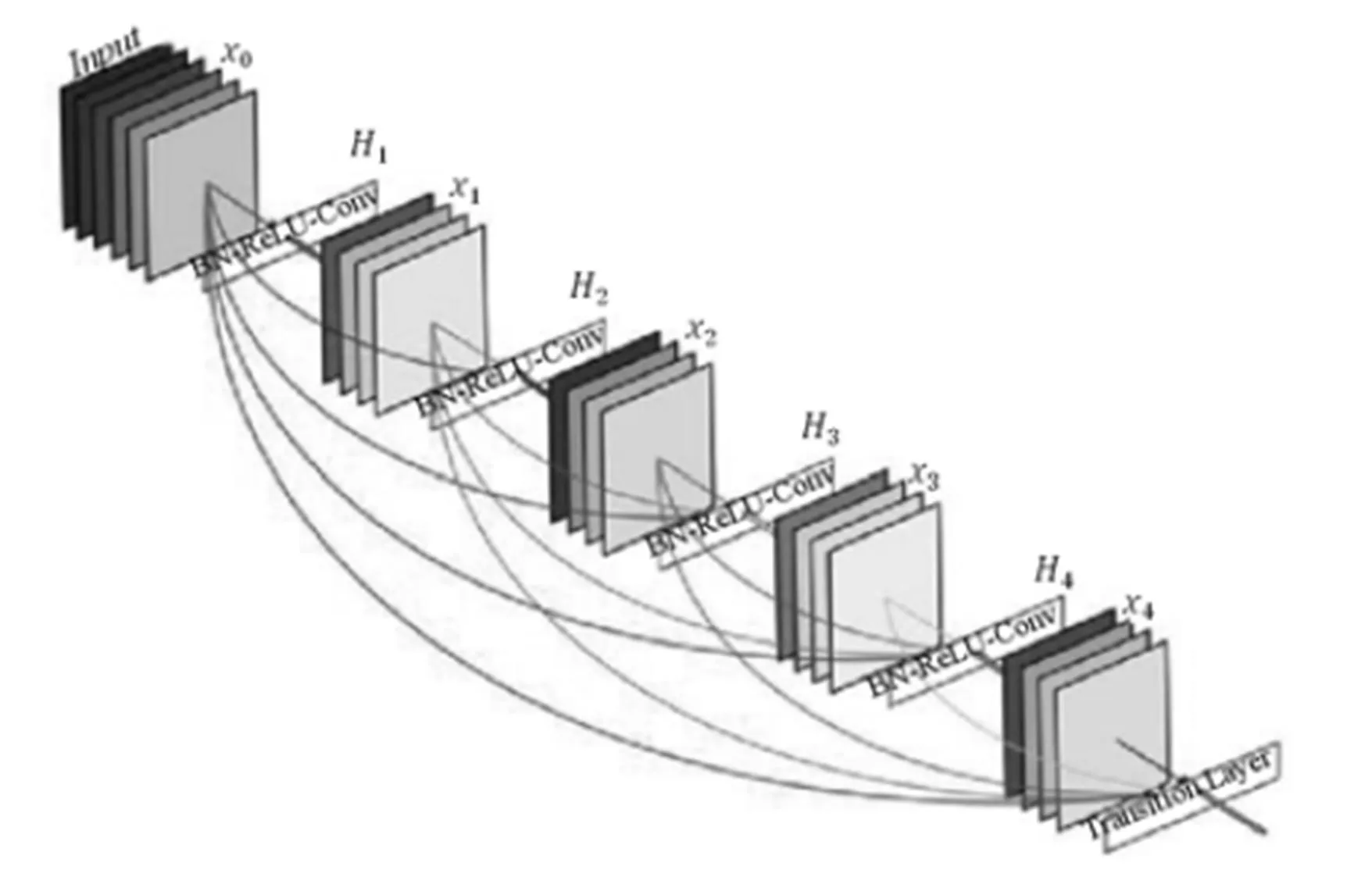
图12
这种连接方式有一个很大的优点:前向传播时深层网络能获得浅层的信息,而反向传播时,浅层网络能获得深层的梯度信息。这样最大限度促进了数据在网络间的流动。另外,这种结构存在着大量的特征复用,因此只需要很少的参数,就可以达到state-of-the-art的效果,主要是体现在特征图的通道数上,相比VGG、ResNet的几百个通道,DenseNet可能只需要12、24个左右。
[1]He km,Zhang XY,Ren SQ,Sun J.Deep Residual Learning for Image Recognition[C]. 2016 CVPR,2016:770-778.
[2]SZEGEDY C,Liu W,Jia YQ,SERMANET P,REED S,ANGUELOV D,ERHAN D,VANHOUCKE V,RABINOVICH A.Going Deeper with Convolutions[C]. 2015 CVPR,2015:1-9.
[3]Huang G,Liu Z,VAN DER MAATEN L,Kilian Q,WEINBERGER KQ. Densely Connected Convolutional Networks[C]. 2017 CVPR,2017:2261-2269
[4]Li H,li W,Yang O,Wang X. Multi-Bias Non-linear Activation in Deep Neural Networks[C]. arXiv: 1604.00676.
[5]Ren XQ,He km,GIRSHICK,ROSS. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal networks[C]. IEEE TRANSATIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE,2017,39:1137-1149.
[6]Li Y,He K,Sun J,Dai J.R-FCN:Object Detection via Region-based Fully Convolutional Networks[C]. ADV NEURAL INFORM PR,2016:379-387.
[7]REDMON J,DIVVALA S,GIRSHICK R,FARHADI A.You Only Look Once:Unified,Real-Time Object Detection[C]. 2016 CVPR,2016:779-788.
[8]REDMON J,FARHADI A.YOLO9000:Better,Faster, Stronger[C]. 2017 CVPR,2017:6517-6525.
[9]HELD D,THRUN S,SAVARESE S. Learning to Track at 100 FPS with Deep Regression Networks[C]. COMPUTER VISION-ECCV 2016,2016,9905:749-765.
[10]Bertinetto L,Valmadre J,Henriques JF. Fully-Convolutional Siamese Networks for Object Tracking[C]. COMPUTER VISION-ECCV 2016,2016,9914:850-865.
[11]PINHEIRO PO,LIN TY,COLLOBERT R,DOLLAR P. Learning to Refine Object Segments[C]. COMPUTER VISION-ECCV 2016,2016,9905:75-91.
[12]HE km,GKIOXARI G,DOLLAR P.Mask R-CNN[C]. 2017 ICCV,2017:2980-2988.
[13]KIM J,LEE JK,LEE km.Accurate Image Super-Resolution Using Very Deep Convolutional Networks[C]. 2016 CVPR,2016:1646-1654.
[14]LEDIG C,THEIS L,HUSZAR F,CABALLERO J, CUNNINGHAM A,ACOSTA A,AITKEN A,TEJANI A,TOTZ J,Wang ZH,Shi WZ. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network[C]. 2017 CVPR,2017:105-114.
[15]LIM B,SON S,KIM H,NAH S,LEE K. Enhanced Deep Residual Networks for Single Image Super-Resolution[C]. 2017 CVPR,2017:1132-1140.
[16]GATYS L,ECKER A,BETHGE M.A Neural Algorithm of Artistic Style[M]. CoRR abs,2015.
[17]RUDER M,DOSOVITSKIY A,BROX T.Artistic style transfer for videos[C]. GCPR 2016,2016,9796: 26-36.
[18]Liao J,Yao Y,Yuan L,Hua G,Kang SB. Visual Attribute Transfer through Deep Image Analogy[C]. ACM TRANSACTIONS ON GRAPHICS,2017,36.
[19]Zhang R,LSOLA P,ALEXEI A,EFROS A A. Colorful Image Colorization[C]. ECCV 2016,2016,9907: 649-666.
[20]LARSSON G,MAIRE M,SHAKHNAROVICH G.Learn Representations for Automatic Colorization[C]. ECCV 2016,2016,9908:577-593.
[21]LIZUKA S,SIMO-SERRA E,ISHIKAWA H. Let there be Color!:Joint End-to-end Learning of Global and Local Image Priors for Automatic Image Colorization with Simultaneous Classification[C]. ACM Transactions on Graphics,2016,35(4).
[22]VAROL G,LAPTEV I,SCHMID C. Long-term Temporal Convolutions for Action Recognition[C]. IEEE TRANSACTION ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE:2018,40(6):1510-1517.
[23]FEICHTENHOFER C,PINZ A,RICHARD P,WILDES RP. Spatiotemporal Multiplier Networks for Video Action Recognition[C]. 2017 CVPR,2017:7445-7454.
[24]Cao Z,SIMON T,Wei S,SHEIKH Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields[C]. 2017 CVPR,2017:1302-1310.
A Survey of Computer Vision Research
Zhang Xiaoliang Liang Xingchi
32140 Troop of People’s Liberation Army of China, Hebei Shijiazhuang 050000
The paper reviews the principles and architecture of important algorithms such as classification and regression, target tracking, image segmentation, image super-resolution, style shifting, coloring, behavior recognition, pose estimation and key point monitoring in computer vision.
computer vision; neural network
TP391.4
A
