分析基于Hadoop的医疗信息存储及检索技术研究
2018-12-18南阳医学高等专科学校
南阳医学高等专科学校 张 琪
本文在研究中以Hadoop医疗信息管理系统为核心,分析Hadoop技术的应用价值,构建基于Hadoop的医疗信息管理系统,提出医疗信息储存技术和检索技术,实现医疗信息管理的现代化和智能化,并为相关研究人员提供一定的借鉴和帮助。
在国民经济不断发展中,医院经营管理逐渐朝着信息化的方向发展,像电子病历或是PACS系统等临床信息系统都逐渐应用,大大提高了运行效率。在信息化发展中,医疗信息储存和检索中的问题逐渐暴露出来,传统分散式数据储存模式的弊端较大,无法保证数据的安全性和可靠性,再加上数据备份流程过于繁琐,无法发挥出数据信息的潜在价值。传统数据中心主要以Unix服务器为主,运行成本高,数据读取速度较慢,再加上计算能力低,无法满足医疗信息的管理需求和使用需求。对此,本文依托于Hadoop技术,构建基于Hadoop的医疗信息管理系统,优化医疗信息储存技术和检索技术,有助于医疗信息的利用,进而提高医疗水平。在这样的环境背景下,探究基于Hadoop的医疗信息存储及检索技术具有非常重要的现实意义。
一、Hadoop技术的应用价值
(一)安全而可靠
医疗信息储存的安全性和可靠性直接关系到医院各项医疗业务的连续性,一旦医疗信息系统发生故障,数据储存能力、备份能力以及恢复能力就显得至关重要,安全性和可靠性是医疗信息储存的首要标准。Hadoop系统可以提供十分可靠的数据储存,各个类型的数据存在三份备份,这对数据储存形成保障。同时,数据中心会对医疗信息数据进行统一保存,临床信息系统不会直接保存数据,而是将产生的数据传输到数据中心保存,临床所需数据会直接从数据中心调取,避免数据丢失的情况发生,保证数据的完整恢复。
(二)储存成本低
以Unix为主的传统服务器具有价格高、扩展储存空间小的特点,以SSD固态储存器为核心元件,不仅价格贵,在扩展容量的过程中,会受到服务器柜容量的影响,而服务器的软件成本也很高。而基于Hadoop为主的数据中心,选择传统PC集群进行数据中心的构建,无论是整个电脑还是传统硬盘,价格较低,便于达到动态扩展的效果。与此同时,Hadoop平台可以支持和开发开源软件,无需软件费用,节省不必要的软件成本。在构建基于Hadoop的数据中心容量中,一般存在两种方式,一是扩充传统PC硬盘容量,便于操作;二是添加廉价PC,为信息挖掘和利用提供根本保障。
(三)查询速度快
传统服务器以机械硬盘为主,数据读取速度慢,若选择固态硬盘,其建设运营成本较高,无法长期负担。而基于Hadoop分布式框架为基础的数据中心,底层为分布式文件系统,可以让文件储存与查询同步进行,以多线程的方式,提高系统的运行速度,数据读写速度也远远高于传统服务器,协助医生快速获取到PACS映象文件速度,进而保证工作效率。
二、构建基于Hadoop的医疗信息管理系统
(一)系统框架
如图1所示,为基于Hadoop的医疗信息管理系统框架,由MapReduce、HDFS等组件构成,其中Hadoop Common为支持项目运行的功能模块,MapReduce组件协助Map与Reduce处理,而HDFS分布式文件系统以文件分布式储存为主要功能,ZooKeeper则为分布式锁服务,支持分布式应用程序的构建。
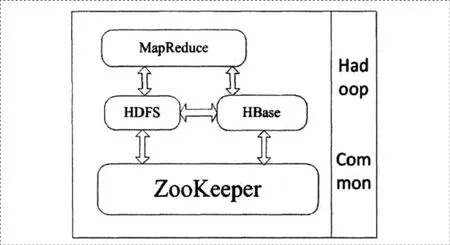
图1 基于Hadoop的医疗信息管理系统框架
在这一系统框架中,各种功能模块和应用程序为海量医疗数据读取与计算提供支持,用户不需要关注程序就可以实现,特别是在分布式系统运行中,PC集群属于硬件资源池,可以拆分即将执行的任务,安排空闲机器资源进行数据处理,通过并行计算的方式,提高系统运行速度,使得任务分解后逐一完成,并通过Reduce来整合结果,进而实现医疗信息的存储和检索。
(二)HDFS系统
HDFS系统是一种分布式文件系统,具有命名空间单一、数据专一性强、可以被分割和分配等特性,主要以master/slave架构为主,由命名节点、数据节点以及客户端等模块构成,内部通信以TCP/IP协议为主。在实际运行中,命名节点与数据节点均运行在商用机器上,而商用机器主要运行Linux操作系统,可以兼容其他机器的DataNode,通过集群单一命名的方式,简化整个为系统构架,将NameNode作为HDFS元数据的判定者,提高系统运行的稳定性。
(三)MapReduce系统
MapReduce为编程模型,应用在大规模医疗数据集并行运算中,依托于Map和Reduce思想,借鉴于函数式编程语言与矢量编程语言,针对函数式编程语言而言,map为列表中的各个元素计算,Reduce为列表中的各个元素迭代计算,利用传输函数的方式实现计算,Map和Reduce主要是提供计算框架。在MapReduce系统运行中,map会对原始数据进行处理,每个原始数据间无任何关联,在Reduce阶段中,数据会通过key下的若干Value进行组织,各个Value间已经形成一定的关联性。对此,MapReduce就是将一些无规律数据根据某一特征进行归纳和处理之后的结果,map针对无规律不关联的数据信息,对各个数据进行解析,提炼出key与value,找到数据特征,再通过归纳和处理得到结果。
三、基于Hadoop的医疗信息存储和检索
(一)信息储存
在医疗数据分析处理中,Hadoop平台能够实现分布式存储,并且对大量廉价计算机进行集合整理来存储数据,实现PB数据集数据的存储。理论意义上来说,Hadoop平台能够尽可能满足海量电子病历文档以及医疗信息数据的存储需求。另一方面,云计算具有较强的灵活性,而Hadoop平台的扩展性好,当出现突发情况,特别是患病高发期或者集体性医疗事件会导致医疗数据剧增的问题,这时Hadoop平台就可以快速、有效的向集群中添加计算机节点和储存资源。
在医疗信息储存中,分别有读写控制模块、写入模块和删除模块进行控制,包括结构化数据和非结构化数据,及时将数据写入到系统中,通过创建数据表接口与写数据接口,结合读写模块制定的规定进行信息重构,将时态集合当成操作对象,把信息数据周期性传输至Hadoop储存模型中,获得标识变量与指定数据包属性,并把对应数据记录到HBase中,保证数据信息的一致性,并添加至索引结构中,对HDFS中的原始数据进行处理得到存储数据,再利用写数据接口对处理后的数据进行存储。
(二)信息查询
Hadoop平台提供了强大的分布式并行处理数据的能力,Hadoop平台主要是针对海量数据的批处理进行操作。并且它具有一次写入多次读取的特点,能够满足医生、专家在海量的医疗数据或者电子病历数据中查找阅读有关的信息。医疗数据检索查询可以通过Hadoop的计算资源对医疗数据及电子病历文档进行处理,不仅速度快、准确性高,从而大大提高医疗信息数据的检索效率。
在医疗数据储存系统中,数据查询包括基于主键的非时态数据查询与时态数据查询,利用显示层应用接口支持可扩展API,实现填充式数据读取,用户可以根据需求在显示界面窗口中设定关键词进行数据整合和读取,通过并行计算机框架Map/Reduce编程进行数据查询。针对用户查询请求而言,系统会预先判断,在不干扰时态查询操作的基础上,把查询结果直接输入到用户程序中,通过可视化界面进行查阅。若干扰时态查询操作,则需要将Map/Reduce处理所产生的基于关键字的查询结果导入到与原始存储数据结构一致的另一张HBase数据表中,在时态元素的标量化处理后调用数据查询模块进行时态关系代数演算处理,完成数据的查找操作。(封朝永.导师:左亚尧基于Hadoop的时态信息存储与检索策略的研究[D].广东工业大学硕士论文,2014-05-01)
四、结束语
综上所述,在医疗信息存储和检索中,为了改变传统医疗信息管理系统的避免,需要引入Hadoop系统,构建基于Hadoop的医疗信息管理系统,提高系统运行效率,减少运行成本,并通过系统构架的简化,提高计算运行速度,进而保证信息存储和检索的综合效率。
