基于library-free映射的电路面积快速优化算法
2018-11-26喻奇王伦耀夏银水
喻奇,王伦耀,夏银水
(宁波大学 信息科学与工程学院, 浙江 宁波 315211)
逻辑电路综合的效果,很大程度上取决于所使用的标准单元库(standard cells library)包含的单元电路的质量、种类和数量[1].集成电路技术的迅猛发展、工艺的不断更新,给标准单元库的维护和升级带来了巨大挑战.另一方面,标准单元库中功能有限的单元电路与电路功能的矛盾,也限制了逻辑电路在映射过程中进一步优化的可能性.而基于library-free映射,使用大型虚拟库代替预先设计好的标准单元库[2-3],所有的门单元都是动态且按需生成的,映射过程中不必考虑使用的门单元是否存在,因此具有更大的解空间.同时,library-free映射因较灵活,常被应用于新器件的映射[4-5].
基于library-free映射的面积优化,主要包含动态单元电路的生成与性能评估[6-8]以及覆盖策略[9-11]两方面.在覆盖策略方面,文献[9]将电路表示为由“与/或/非”等基本逻辑运算组合而成的n元树(n-ary tree),并以串并联晶体管数量为约束条件,使用动态规划对电路延时进行优化.文献[10]使用多米诺逻辑进行library-free映射,首先使用节点映射算法获得多米诺逻辑的初始映射,再沿关键路径对逻辑单元重新排序,进而实现延时优化.文献[11]使用逻辑努力(logical effort)对动态单元电路的延时进行估算,并以延时为约束条件使用动态规划实现面积的最优覆盖.动态规划是一种常用的覆盖策略方法,求解过程中须穷举解空间的所有解,故随着问题规模的增大,求解难度和时间复杂度将呈指数上升,导致运算时间过长.因此,在求解大电路时,须引入其他算法,并在求解速度与优化结果上进行折中处理[12].
本文提出了一种基于library-free映射的面积优化算法,包括动态单元电路的面积估算和覆盖策略两部分.在动态单元电路的面积估算中,通过动态单元电路对应的“与/或/非”图(and-or-inverter graph,AOIG),结合逻辑努力对其面积进行估算.在覆盖策略上,将动态规划与遗传算法(genetic algorithm,GA)相结合,实现电路的library-free映射.实验结果表明,混合算法与动态规划的优化效果相差无几,但能有效缩短求解时间.
1 动态单元的面积估算
1.1 AIG的切割
不同于基于标准单元库的映射,在library-free映射过程中,所有用于映射的单元电路都是动态生成的,本文将用于映射的子电路统称为动态单元电路.这些动态单元电路均与待映射电路网表中满足无输出锥集(free fanout cone,FFC)[9,12]约束的切割相对应.待映射电路的初始表示数据结构为与非图(and-inverter graph,AIG),电路的覆盖过程即为对AIG的切割过程,而切割得到的子AIG必须满足FFC约束,即子AIG中,除根节点外,其他内部节点的输出不作为锥外节点的输入.为更好地满足FFC约束,同时减少切割数量,笔者将待切割AIG中的多扇出节点作为切割后子AIG的根节点,将整个AIG切割成多个以电路根节点和内部多扇出节点为根节点的最大无输出锥集(maxinum free fanout cone,MFFC)[9].以图1为例,图1(a)为一个6输入、2输出的待映射电路的AIG,每一个圆圈表示1个“与”运算,与圆圈相连的虚线表示取反运算.节点4和5是AIG的2个根节点,节点2存在2个扇出,因此,本文也将节点2作为一个切割的根节点,于是得到如图1(b)所示的3个MFFC.

图1 满足FFC约束的切割Fig.1 The cuts of meeting FFC constraint
在获得电路根节点以及内部多扇出节点的MFFC后,再对各个MFFC做进一步切割,由MFFC切割出来的子AIG均满足FFC约束,然后将子AIG转化成用MOS晶体管实现的单元电路,从而完成电路的library-free映射.
1.2 基于AIG的CMOS电路生成方法
CMOS电路由产生高电平的pMOS和产生低电平的nMOS网络组成.在输入信号控制下,当pMOS网络导通时,CMOS电路输出为逻辑1,反之输出为逻辑0.此外,逻辑“与”可以用串联的MOS管实现,逻辑“或”可用并联的MOS管实现,利用MOS管的串并联可实现逻辑函数的功能.
文中,待映射电路的逻辑功能用AIG表示,AIG结构中无“或”运算,方便起见,将AIG表示的逻辑功能用CMOS晶体管来实现,可以将AIG转换为“与/或/非”图,即AOIG.AOIG中的“与”节点对应晶体管串联,“或”节点对应晶体管并联,当叶子节点输出为虚边时,表示该节点对应的输入带反相器.
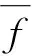

图2 AIG转化为AOIGFig.2 Convert AIG to AOIG
由AOIG得到对应的CMOS电路的方法如下:
(2) AOIG中的每一个叶子节点对应一个MOS管.“与”节点对应MOS管串联,“或”节点对应MOS管并联.
(3) 下拉网络的AOIG中,叶子节点对应的输入将作为整个CMOS电路的输入.
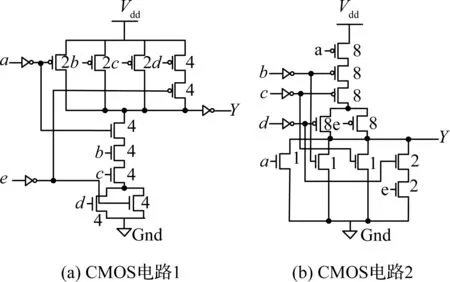
图3 由AOIG得到的CMOS电路Fig.3 CMOS circuits from AOIG
1.3 CMOS电路面积估算
在library-free映射中,用CMOS晶体管构成的动态单元电路的面积,由电路各输入的逻辑努力之和来衡量[13]:

(1)
式(1)中,S表示CMOS电路面积,I为CMOS电路的所有输入的集合,gx为电路第x个输入端的逻辑努力.
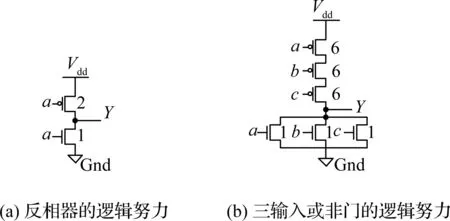
图4 CMOS电路逻辑努力的计算方法Fig.4 Calculation method of logic effort in CMOS circuits
以图4电路为例,图中晶体管上的数字表示沟道宽长比W/L.图4(a)为CMOS反相器,考虑到pMOS管与nMOS管的电阻率,将pMOS管的沟道宽度设置为nMOS管沟道宽度的2倍,使得电路上拉或下拉的驱动电流基本一致.图4(b)为3输入或非门,其上拉网络为3个串联的pMOS管,下拉网络为3个并联的nMOS管.在晶体管沟道长度相同的情况下,为使图4(b)电路的最小驱动电流强度与图4(a)相同,须将3个串联的pMOS管的沟道宽度扩大3倍.现定义单输入的反相器面积为1个单位面积,由式(1),则3输入的或非门的面积为
S=(gA+gB+gC)/(2+1)=21/3=7个单位面积.
根据AOIG中逻辑运算与CMOS电路中MOS管连接的对应关系,由式(1)可直接在AOIG中计算各输入的逻辑努力,进而求解CMOS电路面积.电路面积估算规则如下:
1) 考虑到下拉nMOS网络与上拉pMOS网络的电阻率,令下拉网络AOIG的根节点沟道宽长比初值为1,上拉网络AOIG的根节点沟道宽长比初值为2.
2) 从AOIG的根节点到叶子节点逐层递归计算.对于“与”节点: 往下遍历各节点,当某条路径遍历到“或”节点或叶子节点时,该条路径遍历截止.当所有遍历路径都截止时,该“与”节点的遍历结束.若初始“与”节点的晶体管沟道宽长比为λ,该“与”节点共遍历t个“或”节点以及叶子节点,则这t个节点的沟道宽长比均为λ′=tλ.对于“或”节点: “或”节点的2个输入节点的沟道宽长比等于该“或”节点的沟道宽长比.
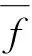
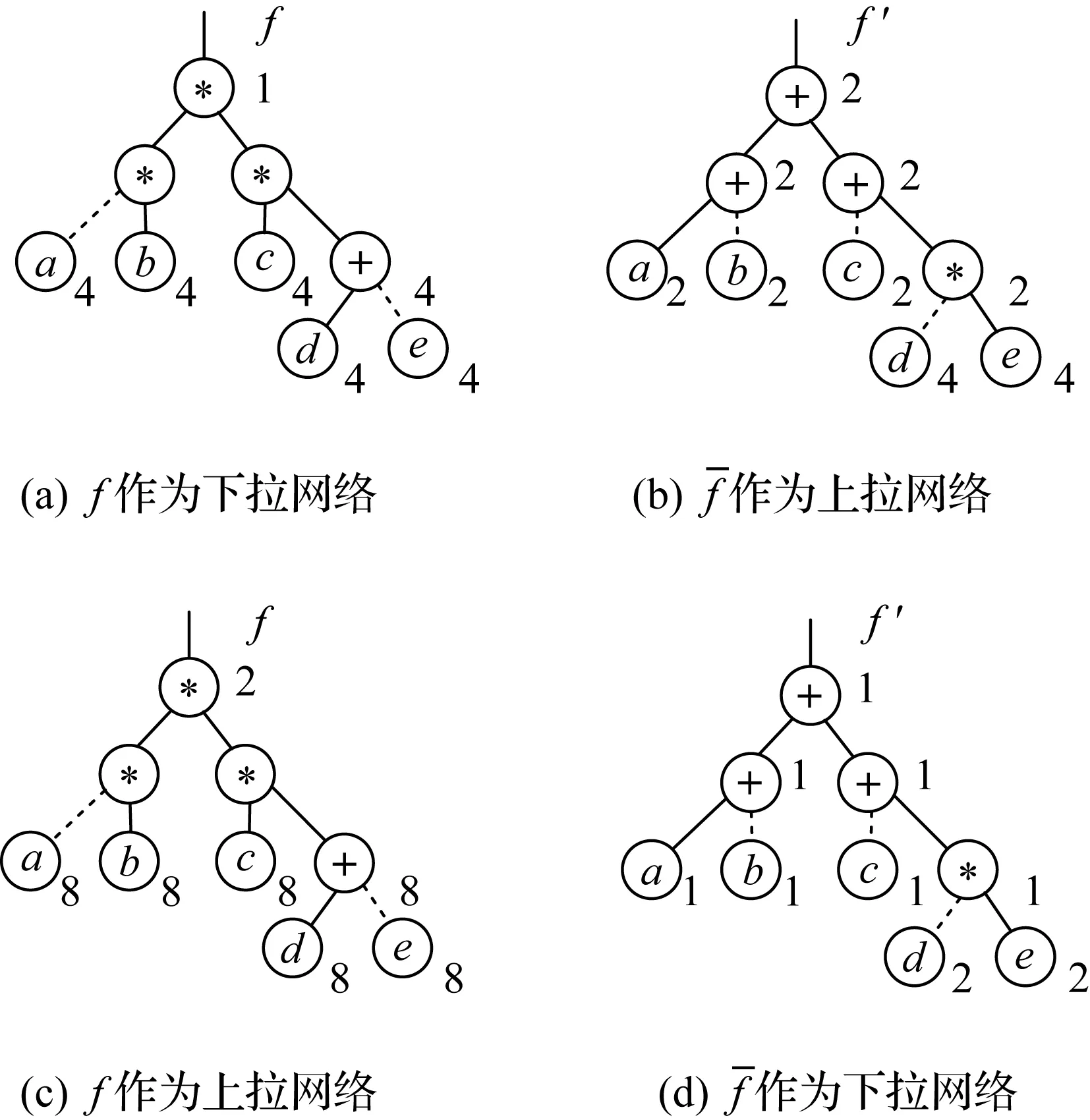
图5 在AOIG上计算逻辑努力的方法Fig.5 Calculation method of logic effort in the AOIG
CMOS电路的总面积可由式(2)计算:
S=Sp+Sn+Sinv-in+Sinv-out,
(2)
其中,Sp表示上拉网络面积,Sn表示下拉网络面积,Sinv-in表示输入反相器面积,Sinv-out表示输出反相器面积.
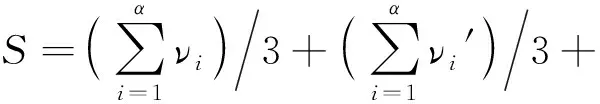
(3)
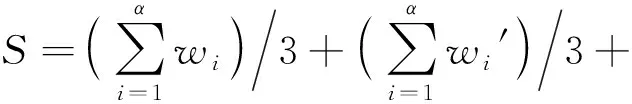
(4)
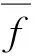
由式(3)可得,图3(a)中的CMOS电路总面积S=20/3+14/3+2+1=43/3个单位面积;由式(4)可得,图3(b)的CMOS电路总面积S=40/3+7/3+(5-2)=56/3个单位面积.计算结果表明: 适当选择上下拉网络可优化CMOS电路面积.
本文提出的面积估算方法的伪代码如下,其中子函数Cal_WL(pNet,nNet)为按照电路面积估算规则在AOIG上计算叶子节点的晶体管沟道宽长比,pNet表示用于实现上拉网络的逻辑函数,nNet表示用于实现下拉网络的逻辑函数.子函数Cal_Area_1()为用式(1)计算的CMOS电路面积.子函数Cal_Area_2()为用式(2)计算的CMOS电路面积.
Algorithm1Calculate area of dynamic cell
Inputf.AIG
OutputArea of dynamic cell
FunctionCal_Cell_Area
f.AOIG←De·Morgen Theorem (f.AIG);
S1=Cal_Area_1(AOIG_WL_1);
S2=Cal_Area_2(AOIG_WL_2);
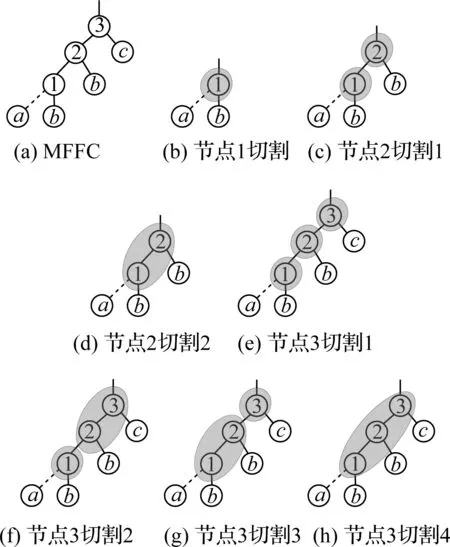
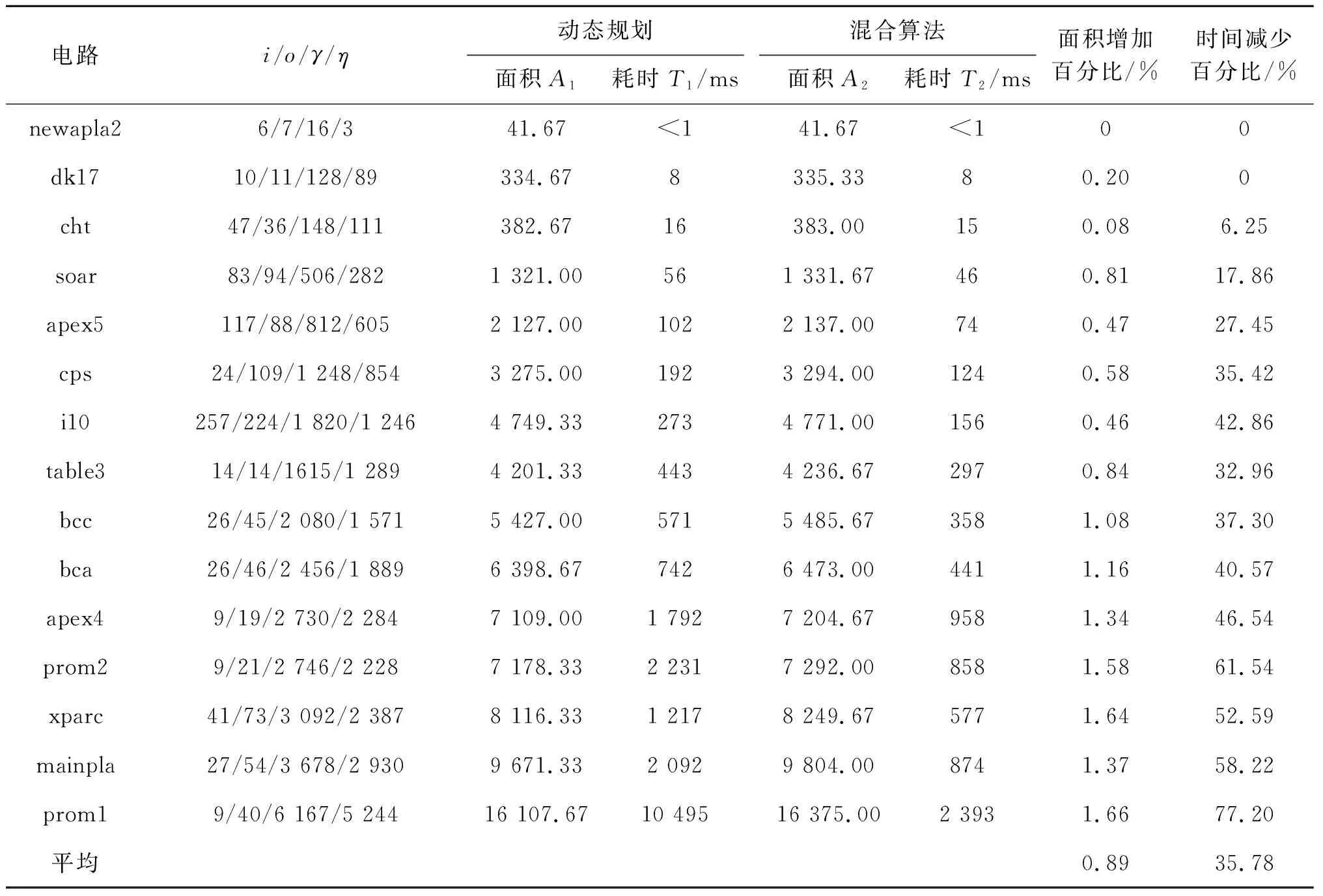
if(S1 returnS1; else returnS2; endif 动态规划是常用的一种覆盖算法,首先自顶向下将整个电路切割成以电路根节点和内部多扇出节点为根节点的多个MFFC.对于每一个MFFC,动态规划会再次自底向上遍历每个节点所有可能的切割方式,从而完成对MFFC的切割[13].假设图6(a)为某MFFC,动态规划会依次遍历节点1、2、3,切割方式如图6(b)~(h)所示. 图6 使用动态规划对MFFC进行切割Fig.6 Cut the MFFC using dynamic programming 当MFFC中有n个内部节点时,整个MFFC有2n种不同的切割方式,覆盖的计算量和时间复杂度将随着MFFC内部节点数的增多呈指数上升.因此,当某个MFFC中包含的节点较多时,就需要平衡覆盖速度和解的质量,为此,本文使用一种混合算法对电路进行覆盖,即根据MFFC的大小(内部节点数量)选择不同的覆盖算法.当MFFC较大时,使用GA进行覆盖,此时启发式算法的速度优势得以发挥;而当MFFC较小时,依然使用动态规划进行覆盖.因为MFFC较小时,MFFC的可行切割方式数量有限,其计算成本也不会太高,此时动态规划所耗时间和GA相差不大,但求得的解的质量优于GA. 图7 染色体编码及其对应的覆盖Fig.7 Chromosome’s code and its cover 当使用GA对MFFC进行覆盖时,每一根染色体对应MFFC覆盖过程中的1个可行解.染色体采用0-1二进制编码方式,编码的基本思想是: MFFC中每一个内部节点对应染色体中的一位基因,染色体Xi表示一个有δ位的0-1序列串,Xi=(xi1,xi2, …,xiδ).其中,染色体长度δ等于MFFC的内部节点数加上根节点的数目,即MFFC的内部节点数加1.xiτ表示染色体第τ个基因位上的取值,τ≤δ,也代表AOIG中编号为τ的节点的取值,xiτ=1表示以节点τ为根节点生成当前编码约束下的MFFC.以图7为例,图7(a)是图7(b)中MFFC使用GA覆盖对应的7位0-1染色体编码,染色体1生成的覆盖如图7(b)所示.染色体1中第2、6、7个基因位的值为1,分别生成以节点2、6、7为根节点的3个MFFC.同理,染色体2对应的覆盖中将生成以节点5、7为根节点的MFFC.但在染色体3中只有5、6基因位的值为1,根节点7对应的基因位的值为0,因此该染色体编码不能覆盖整个电路,为错误染色体编码.为避免出现上述错误的染色体编码,在生成染色体初期,将MFFC根节点对应的基因位的值统一设置为1. 遗传算子操作主要包括染色体的选择、交叉和变异.在MFFC的覆盖过程中,交叉会产生新的染色体,其主要目的是为了探索不同的切割方式;选择过程将会在种群中留下相对优秀的切割方式;变异除了会探索新的切割方式外,更重要的是,防止种群早熟.而在变异过程中,为了使每一根染色体对应MFFC的完整覆盖,预先设定MFFC根节点对应的基因位不发生变异. GA的求解目标是面积的最小覆盖,适应值函数为 (5) 其中,p表示将整个电路切割成p个MFFC,Si表示第i个MFFC的面积.覆盖面积越小时,其适应值f越大. 算法2为GA和动态规划相结合的面积优化覆盖算法,伪代码如下: Algorithm2GA+DP covering InputBenchmark circuits(BC) OutputMinArea FunctionCalculate minimization area of BC AIG=read_blif(BC); MinArea=0; fori=1 topthen// Step B n=Inner_node(Vi); ifn>kthen// Step C popsize=n*2; oldpop=initial(popsize); fitness(oldpop); find_MinArea(oldpop,best_chrom); forj=1 to NGthen mate1=slection(oldpop,popsize); mate2=slection(oldpop,popsize); crossover(mate1,mate2,newpop); mutation(mate1,mate2,newpop); fitness(newpop); find_MinArea(newpop,best_chrom); update_pop(oldpop,newpop); endfor else foreach Node c inVithen// Step D find_MinArea(c); endfor Vi_MinArea=Ni_MinArea; endif MinArea=MinArea+Vi_MinArea; endfor 混合算法中,step A将整个电路切割成多个MFFC,其作用如图1所示.而MFFC的大小将影响算法的选择.若MFFC内部节点大于阈值k,则执行step C,即GA覆盖,每一个染色体对应MFFC的一种可行切割方式,fitness( )函数为计算种群中每个染色体的适应值,而计算由MFFC切割出来的子电路的面积使用本文中的Algorithm 1;若MFFC内部节点小于等于阈值k,执行step D,使用动态规划自底向上遍历MFFC中各个节点所有可能的切割方式,直至遍历MFFC的根节点. 最终,整个电路的最小面积等于所有MFFC的最小面积之和. 本文提出的混合算法用C语言实现,待映射电路的AIG结构由逻辑综合工具ABC生成,所用的计算机配置为Windows 7/64位操作系统,8 GB内存和3.30 GHz处理器.遗传算法的相关参数为: 交叉率为0.8,变异率为0.05,最高迭代次数为500.电路覆盖过程中,为了提高遗传算法的效率,其他参数将根据MFFC的大小设置.本文中设置种群规模为MFFC内部节点数目的2倍;当MFFC内部节点数小于等于20时,连续3代种群最优解不发生变化时算法终止;当MFFC内部节点数大于20时,连续5代种群最优解不发生变化时算法终止.另外,通过多次实验,在兼顾解的质量和覆盖速度下,将触发2种算法切换的阈值k设为10. 表1为使用混合算法和动态规划针对MCNC电路的实验结果对比,其中动态规划的运行环境与混合算法的运行环境相同.考虑到MFFC的大小和数量与待优化电路的内部节点数和单扇出节点数有关,因此,本文也将上述数据列入表1.表1中的i/o/γ/η分别代表电路的原始输入、原始输出、内部节点以及内部单扇出节点数.面积增加百分比指混合算法较动态规划求得的面积最优解增加的百分比,时间减少百分比指混合算法较动态规划所用时间减少的百分比. 面积增加百分比=(A2-A1)/A1×100%, (5) 时间减少百分比=(T1-T2)/T1×100%. (6) 表1 混合算法与动态规划的实验结果对比 从表1中可以看出,当电路规模较小时,本文的混合算法作用不明显,如电路newapla2.这主要是因为电路较小时,其内部不存在大型MFFC,对每一个MFFC,混合算法也只是使用其中的动态规划策略进行覆盖.对于中小型电路,如电路dk17,其内部只有少量MFFC会使用GA进行覆盖,混合算法减少的时间未超过1 ms,统计时间均为8 ms,速度优势不明显.由于GA的求解精度不如动态规划,此时,用混合算法求得的面积最优解亦不如动态规划.也即,本文的混合算法不适合中小型电路. 同时,从表1中也可以看出,混合算法能有效减少大电路的覆盖时间,如表1中最大的电路prom1,混合算法的覆盖时间较动态规划减少了77.20%.这是由于当电路面积增大时,其内部用于GA覆盖的MFFC数量相对增多.除此之外,当电路中存在特别大型的MFFC时,GA相对于动态规划的速度优势也非常明显.以电路i10为例,其内部单扇出节点较为集中,有些MFFC包含的节点非常多,此时使用混合算法获得的时间优化程度甚至超过了一些规模更大的电路. 混合算法较于动态规划电路覆盖时间大幅度缩短的主要原因是在处理内部节点较多的MFFC时使用了GA.当电路中的大型MFFC较多时,或者当电路中某个MFFC内部节点特别多时,使用混合算法可明显缩短覆盖时间.当然,速度的优势是以牺牲解的质量为代价的,实验结果也表明,混合算法解的质量下降并不大. 若将映射时间“<1”统计为1 ms,相较于动态规划,混合算法平均只牺牲了0.89%的优化百分比,但求解时间却节省了35.78%. 所提出的电路面积优化方法包含电路覆盖策略和基于MOS晶体管的动态单元电路面积估算方法.其中,覆盖策略是为了平衡求解速度与优化效果而提出的将动态规划与遗传算法相结合的混合方法.此混合方法同时具有动态规划算法在求解小电路时优化效果较好和遗传算法在求解大电路时速度较快的特点.为了提高电路面积的估算精度,利用逻辑努力和基于AOIG动态单元生成方法,提出了用MOS晶体管沟道宽长比作为衡量电路面积的关键参数.实验结果显示,该优化算法在面积增加不到1%的情况下,求解时间节省了35%以上.2 Library-free映射的覆盖算法

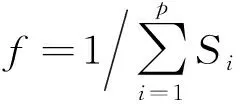

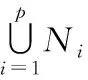
3 实验结果与分析
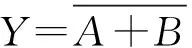
4 结 论

