基于层次化的微博情绪分类
——以新浪微博为例
2018-11-17王向华
王向华,宋 欣
(天津职业大学 电子信息工程学院,天津 300410)
0 引 言
在所有的SNS(social network service)[1,2]平台中,微博是最受欢迎的平台。微博文章是用户观念的直接反映,但是微博文本通常十分简短。例如在中国最广泛使用的微博平台——新浪微博,允许用户在一篇博文中输入不超过140个中文字符。而微博文章的长度限制给情绪分类带来了难题,需要更有效的特征提取方法。此外,互联网俚语进一步增加了情绪分类和特征提取的难度。
情绪可以被定义为一个主观上的思想或感觉,比如高兴、生气等,目前,大多数的研究人员主要在6个粗粒度的类别上进行情绪分析和分类,这些粒度包括高兴、惊讶、愤怒、厌恶、恐惧和悲伤[3]。然而,粗粒度的情绪类别不能很好的解释文本中的情绪。为更好地描述情绪,需要在粗粒度的情绪类别中加入细粒度,这就形成了层次化结构。
除情绪粒度不同外,语料库的语言也不一样。迄今,大多数研究工作使用英语作为语料库。近年来,出现了一些以中文为语料的研究,例乌达巴拉等[4]根据依存句法的词语搭配特征和基于组合语义的深度特征应用于文本情绪分类,提出了一种以短语为主要线索的半马尔科夫条件随机场文本情绪分析算法。Jiang等[5]利用深度学习工具Word2vec对社会热点事件的微博语料通过增量式学习方法来扩展基准词典,并结合HowNet词典匹配和人工筛选生成最终的情绪词典。
现阶段许多研究人员着眼于使用正负向情绪分类或粗粒度基本情绪分类方法将文本分为6到7个情绪类别,而不是使用细粒度的情绪分类方法或情绪成分分析。本文采用4层的细粒度情绪层次化分类体系,包括19种底层情绪。提出了情绪成分分析(emotional component analysis,ECA)算法,以检测文章中的主要情绪,根据回归值和分类阈值之间的距离,计算该主要情绪在文中所占的相应比例。
1 情绪成分分析
通常,一篇微博文章包含着多种情绪,因此,单一的分类结果并不能准确地反映出情绪成分[5,6]。基于多类别分类中的置信理念,本文提出的ECA算法以检测主要情绪,并计算其所占比例。
情绪成分分析如算法1所示。本文首先对文章是否包含情绪以及该情绪为正向或者负向进行判定。接着对每种情绪在正向或负向类别中的原始得分进行计算和排序(第(1)~(4)行)。将排在前面的4种情绪挑选出,作为主要情绪(第(5)~(6))行),然后计算主要情绪的最终得分和所占比例(第(7)~(16)行)。
算法1: 情绪成分分析
(1) for每个 4层情绪[i]do
(2) 得分[i]= 4层分类器[i].分类()+
上层(4层分类器[i]).分类();
(3)endfor
(4) 排序(得分,4层情绪);
(5) 主要情绪= 4层情绪[1:4];
(6) 主要情绪得分=得分[1:4];
(7) 总得分= 0;
(8)for每个主要情绪得分[i] do
(9) 主要情绪得分[i] = exp(主要情绪得分[i]);
(10) 总得分+=主要情绪得分[i];
(11)endfor
(12)主要情绪占比[1:4] = 0
(13)for每个主要情绪占比[i]do
(14) 主要情绪占比[i] =主要得分[i]/总得分;
(15)endfor
(16)return主要情绪,主要情绪占比
2 具体实施
为了分析微博中的情绪,更准确地描绘出不同的情绪差异,有效提高情绪特征的提取与选择,完成情绪分类,提出层次化情绪分类耦合情绪成分分析的算法,该算法流程如图1所示。
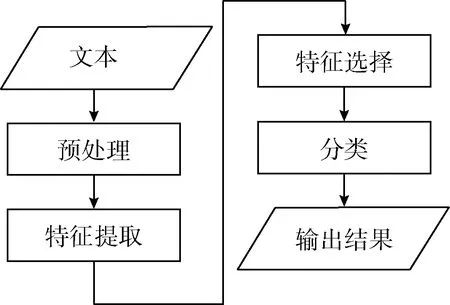
图1 本文算法流程
2.1 层次化体系
本文的层次化结构如图2所示。该层次化结构包含19个细粒度的底层情绪类别,若考虑到中性情绪则包含20个叶子节点,中性情绪表示没有任何情绪类别。
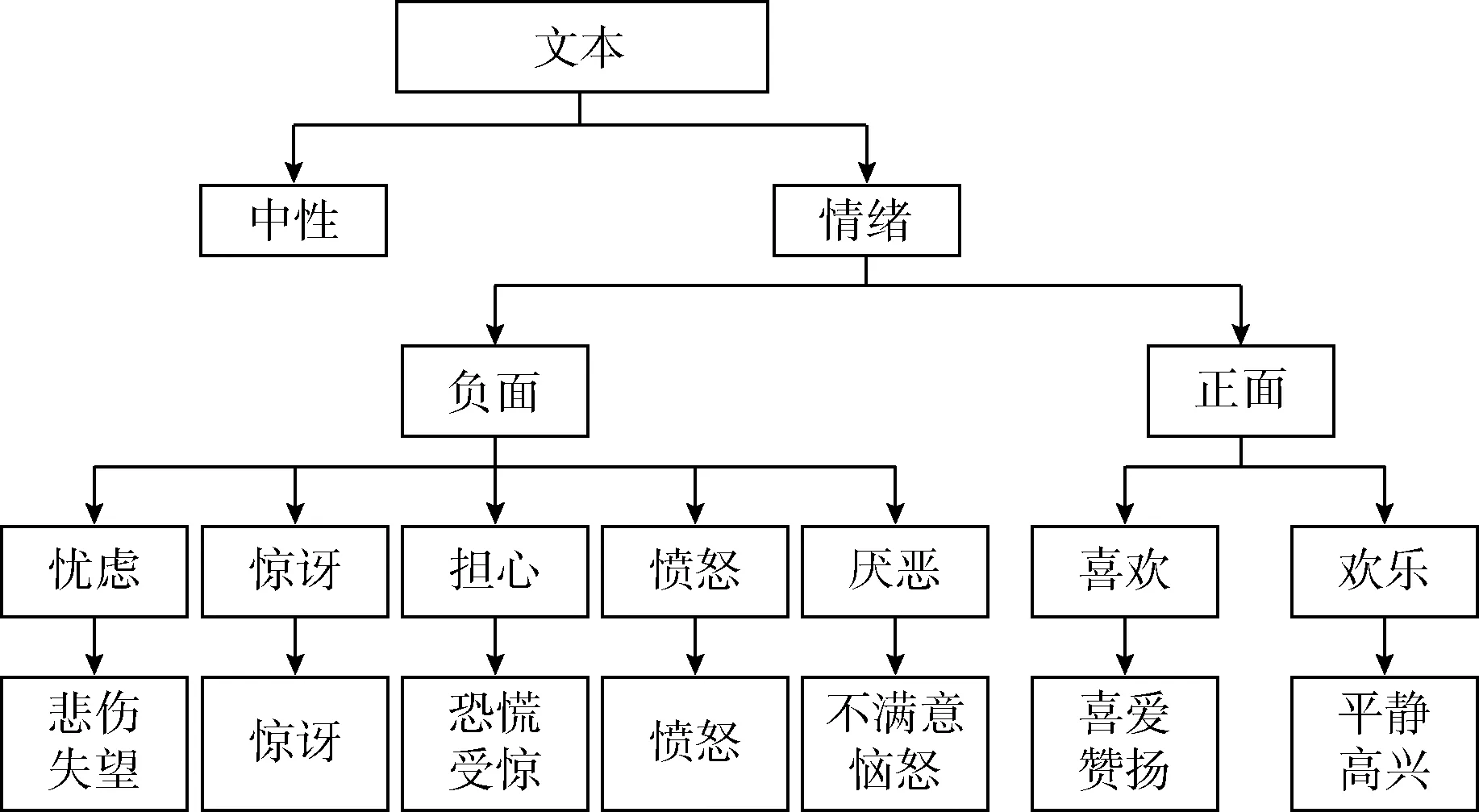
图2 四层的层次化结构
2.2 预处理
为了提高算法效率,在执行运算之前对文本进行预处理,移除4种类型的元素,即用户名、主题、链接和位置信息,这些均不包含任何情绪。
用户名:如果用户A希望和用户B分享一些东西,他将会在其文章中输入B的用户名,并在该用户名前添加一个@符号,这样用户B将会收到通知。然而,这一部分一定不包含任何情绪,因此本文通过检测@符号并将其和用户名一并移除,以略去该元素。
主题:每个用户都可以在某个特定的主题下参与讨论。为加入讨论,用户只需要在文章中输入该主题,并用两个“#”符号表示,例如#情绪分析#。这一部分当然不会包含任何情绪,且符号在预处理程序中被移除。
链接:用户的文章中可以包含链接。链接将会被微博平台转换成短链接,以减少占用空间。在新浪微博,短链接通常以http://t.cn/作为开头。
位置信息:微博平台允许用户在文章的末尾添加位置信息,该信息对于情绪分类没有帮助。位置信息具有固定的前缀,比如“我在这里:”或“我在:”,这使得预处理程序可以比较容易地识别该信息。
2.3 特征提取
微博用户常会使用不同的表情符号表达当前的情绪。一些用户使用表情符号“”以表示高兴,一些用户则使用“”以表示悲伤。总之,表情符号特征能够表达一些更为复杂的情绪,因此提取表情特征符号非常重要。
词性特征在文本情绪处理中是不可或缺的因素,该特征在情绪分析中通常发挥不同的作用[7]。通过挖掘词性特征,本文采用ICTCLAS分词工具包[8]对文章进行分割,随后提取形容词、名词和动词等,以形成特征空间。同时本文还应用了两个语义规则。第一个语义规则是提取重复的感叹号(!)和问号(?)。第二个语义规则是将否定词和相邻的形容词放在一起,比如与原形容词有着相反含义的短语。但是在两者之间可能会存在副词,根据中文的语言习惯,将距离阈值设为3。即当一个否定词和一个形容词之间的距离在3个词内,该否定词和形容词以及在其间的词语作为一个词语共同提取。
2.4 特征选择
通过上一节的特征提取会产生大量特征,因此,有必要从原始特征空间中选择有效的特征。本文在这里采用了实施卡方测试,以及词频和点互信息(point of mutual information,PMI)。PMI由以下公式定义[9]
(1)
式中:t表示词语,c表示类别,p(t)和p(c)为t和c的个体分布,而p(t,c)则是t和c的联合分布。
最终的特征集包括两个词集:高频词集和低频词集,这两个词集根据算法2分别生成。算法中的所有阈值均通过迭代决定[10]。
算法2: 特征选择算法
(1) 词.中文=x2(语料库,标签);
(2) 排序(词,中文);
(3) 词.频率_比例=频率_比例(语料库,标签);
(4)S高频=Ø;
(5)fori=0;i<词.大小();i++;do
(6)if词[i].频率_比例>正向_频率_比例_阈值then
(7)S高频.加入(词集[i]);
(8)endif
(9)if词[i].频率_比例<负向_频率_比例_阈值then
(10)S高频.加入(词[i]);
(11)endif
(12)if词[i].大小() ≥阈值then
(13)break;
(14)endif
(15)endfor
(16) 词.正向_点互信息=正向_点互信息(语料库,标签);
(17) 词.负向_点互信息=负向_点互信息(语料库,标签);
(18)S低频=R正向=R负向=Ø;
(19)for每个词[i]do
(20)if词[i].正向_点互信息>正向_点互信息_阈值
(21)S低频.加入(词[i]);
(22)R正向.加入(词[i]);
(23)endif
(24)if词[i].负向_点互信息>负向_点互信息_阈值
(25)R负向.加入(词[i]);
(26)endif
(27)endfor
(28)S=合并(S高频,S低频);
(29)returnS、R正向、R负向;
卡方测试能够选出与某类别高度相关的词语。然而,会受到词频的影响,因此词频比例作为附加信息采用。在本文算法中,首先在语料库和标签上运行卡方测试(第(1)行),并根据测试结果对词语进行排序(第(2)行)。接着计算所有词在正向和负向情绪的样本中的频率比例(第(3)行)。下一步,按顺序选择频率的比例高于正向阈值或低于负向阈值的词语,直到高频词集的大小达到大小阈值(第(4)~(15)行)。
低频词的选择取决于PMI,因为其对词频的敏感度较低。将所有PMI值高于正面阈值的词语挑选出,以形成一个低频词集。将正向和负向规则集一起生成,以在分类程序中对回归值进行修改。
2.5 分 类
为了更有效更准确分类提取的特征,本文引入了支持向量回归(support vector regression,SVR)工具包作为分类算法[11]。与SVM中只能使用一个固定阈值不同,SVR允许动态选择分类阈值。
SVR在训练程序中需要调整两个参数(算法3):模型参数v和分类阈值。本文使用10倍交叉验证方法,将数据集分为训练集和测试集[12]。当分类结果达到极值时由迭代决定参数值。分类()表示分类程序,评价()是对分类结果的精确率、召回率和F-测度进行评价。
算法3: 训练
(1)for(v=0.1;v<1;v+=0.1)do
(2) Libsvm_训练(v);
(3) 分类();
(4)for(t=-1;t≤1;t+=0.05)do
(5) 评价(t);
(6)endfor
(7)endfor
分类程序(算法4)中,在决定最终分类结果之前,通过PMI生成的两个规则集对回归值进行修改。由于规则犯错的可能性较小,本文将正向样本的修正值设为2.0,将负向样本的修正值设为-2.0,以使得分类结果不会受到阈值的影响,阈值范围从-1到1。
为实施多类别分类,本文训练每个类别的二元分类器。选择在回归值和阈值之间距离最大的类别作为最终结果,因为该类别的置信度最高。
算法4: 分类
(1) 结果=libsvm_预测();
(2)for每个文章[i] ∈训练_语料库do
(3)for每个词[j] ∈文章[i]do
(4) if 词[j]∈R负向then
(5) 结果[i]=-2.0;
(6)break
(7)endif
(8)if词[j] ∈R正向then
(9) 结果[i]=-2.0;
(10)break
(11)endif
(12)endfor
(13)endfor
(14)return结果
3 实验结果与分析
为了验证提出算法的优异性,选取不同的数据集进行实验。仿真平台所用的PC机为:Core i3双核CPU,2.49 GHz,8 GB RAM,Windows 10操作系统。开发工具:VS2010和Intel发布的开源计算机视觉,开发语言:C/C ++。为了对算法的性能定量评价,引入信息检索中常用的指标:准确率(Precision)、召回率(Recall)和F值(F测度)。准确率P表示正确检测特征与检测出特征的比。在本文中为检测正确的情感数(TN)与检测情感数(TF)的比例[13],即
(2)
召回率R为检测的相关特征数与实际相关特征数的比,即
R=检测的相关特征数/实际相关特征数
(3)
F值则是准确率与召回率结合的评价方法,即
(4)
F值是对P和R的调和平均值,只有P和R均高的时,才会产生较高的F。因此,F也表示算法的综合性能。
3.1 数据集
为了保持微博的真实性和实用性,从新浪微博中随机选择了9000个原始的中文微博文章,并将其作为数据集。由两个注解人员分别完成标注。有分歧的标注约占35%。考虑到情绪组合之间缺少明确的界限,这一数值是可以接受的。不一致的标注由注解者从产生分歧的标签中选择一个作为最终标签。
3.2 实验分组设置
本文在4个组(组1~组4)上进行实验。如表1所示,组1仅应用了扁平式分类方法。与之相反,组2应用了层次化分类方法。组3在组2的基础上通过特征选择进行优化。组4在使用了上文提到的所有优化方法后,在分割步骤中还应用了一个心理学情绪词典。在该心理学情绪词典中共有超过52 000个词汇,本文将这些词汇分为6组。每组能够分别描述一种类型的情绪。这些情绪分别为高兴、忧虑、担心、愤怒和厌恶。所有的结果均取5轮实验结果的平均值。

表1 分组设置
3.3 分层结果
分层结果被用于评价单一分类器的性能。对每个分类器进行训练,使其区分自身类别和相邻类别之间的样本。例如,对悲伤、内疚、失望和思念情绪的分类器进行训练时,对其提供属于这些情绪的上层类别(如忧虑类别)的训练样本。
第1层和第2层的二元分类结果见表2。结果表明应用所有的3个优化方法的组4性能最优。其中,组4在第2层的F-测度大约是0.9,这是一个非常高的数值。此外,其在第1层的F测度也达到了大约0.85。
通过比较组2和组3,能够观察出后者的性能优于前者。这表明了本文的特征选择方法是有效的,该方法在保留了高度相关的特征同时,移除了许多干扰特征。
组4在组3的基础上有一些性能改善,大多是在1%~3%之间。这表明心理学情绪词典对分类产生了积极效果,这是组3和组4之间唯一的区别。
第3层和第4层的分类结果见表3。在大多数情况下,组3的性能优于组2,这再次表明了特征选择方法的有效性。与第1层和第2层差别相似,组4在大多数情况下较组3有1%~3%的性能提高。组4在第3层和第4层的F-测度均超过0.85,而在第4层大部分都超过了0.9。这表明所有的分类器均表现优异,可以预测整体模型会发挥出良好的性能。
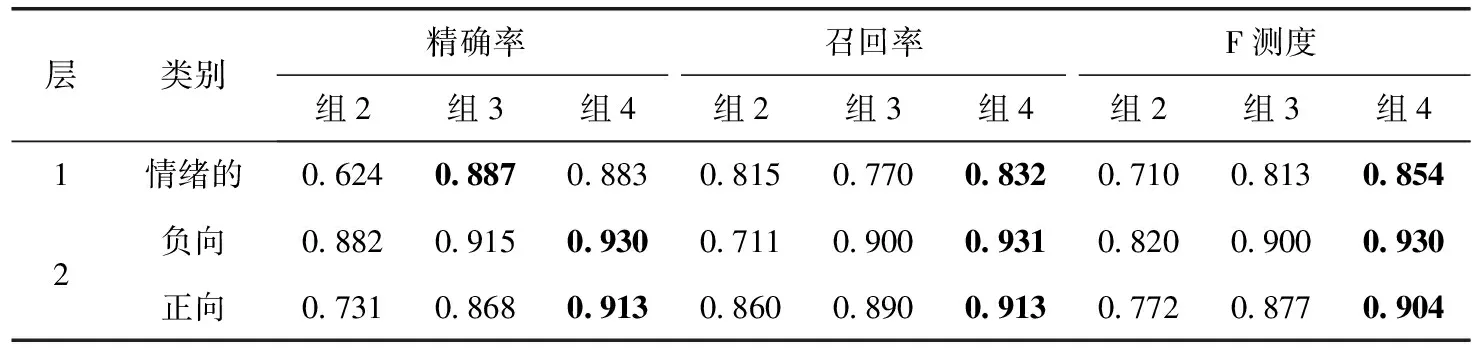
表2 第1层和第2层的结果

表3 第3层和第4层的结果
3.4 层次化结果
在层次化分类中,将每个训练样本从顶层到底层一次分类。分类结果见表4。
正如组1和组2之间的比较可以观察出,采用层次化分类方法能够在超过一半的情况下提高性能,在扁平化的分类体系中,当给出整个数据集时,每个分类器不能轻易区分自身类别样本和其它类别样本。与之相反,层次化的分类方法通过上层分类器移除了大多数不相关的样本,使得较低层的分类器可以轻易的分类。
从表4中可观察出,当应用特征选择和心理学情绪词典时,其性能有所提高,这与前文得出的结果一致。
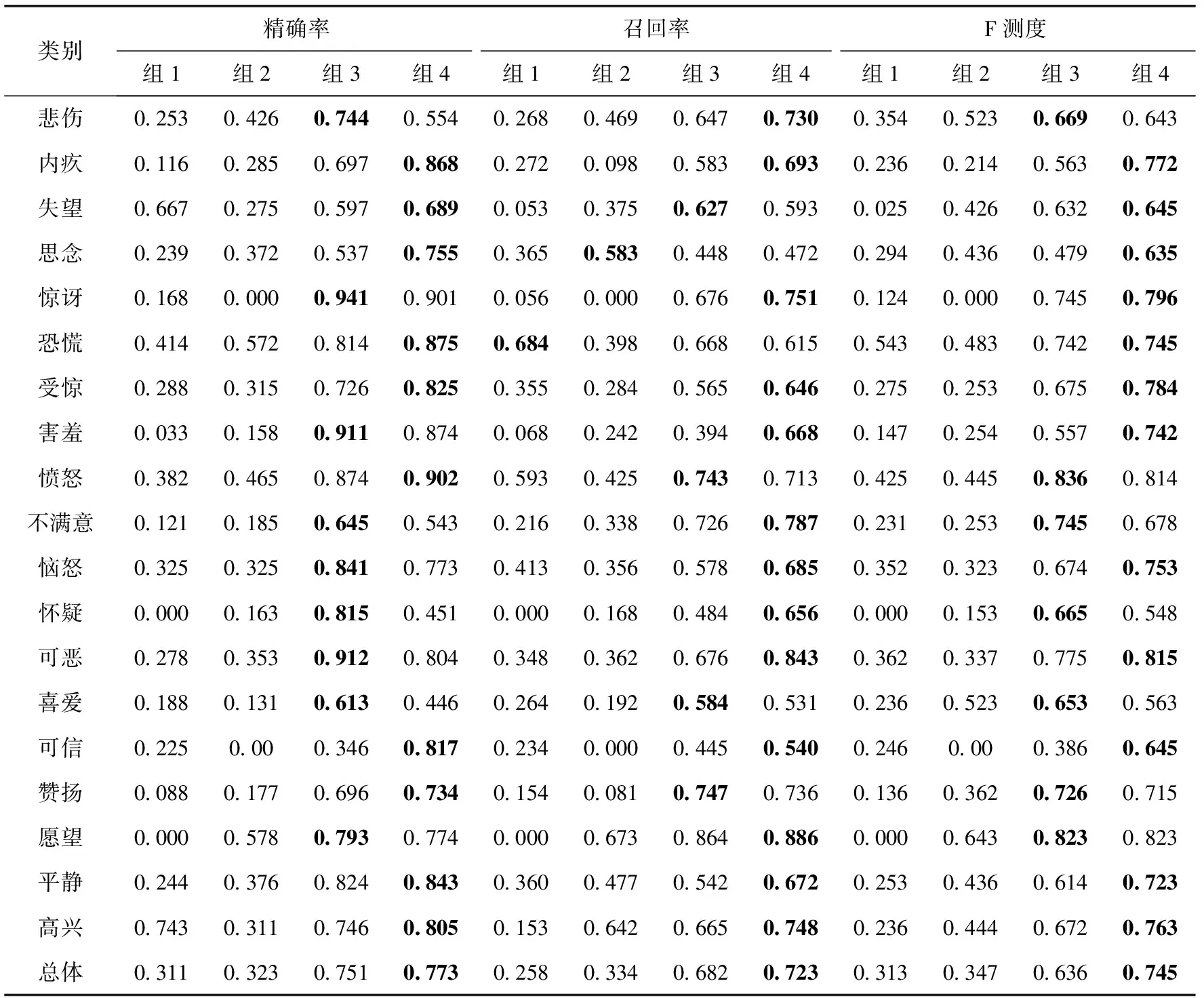
表4 层次化的结果
3.5 情绪成分分析结果
文本采用一般人类评判标准评估实验结果,如表5所示。一般来说,如果一篇文章的分析结果得到了超过半数评判员的支持,即被视为合理分析。实验中,评判员分别从测试集中随机挑选50篇文章进行评判。超过70%的结果得到了半数以上的评判员支持。此外,68%的结果得到了80%评判员的支持,将近一半的结果得到了所有评判员的支持,这表明了本文算法的有效性。

表5 情绪成分分析结果
4 结束语
为了更好识别中文微博文章情绪,并描绘出不同的情绪差异,提出了一种基于层次化分类耦合成分分析的情绪识别算法。为了更好描述情绪,在粗粒度的情绪类别中加入细粒度的情绪分类,建立了层次化情绪结构。针对单一的分类结果无法准确地反映出情绪成分,在多类别分类中的置信理念基础上,提出一种ECA算法,以检测主要情绪并计算其在文中的比例。新浪微博的情绪分类结果印证了算法的有效性。
微博中的讽刺性表达涉及更深层次的语义分析、情景分析和语境分析,这将是未来研究内容。
