信息检索中支持隐式时间查询的文档排名方法
2018-11-17王晶晶吴胜利
王晶晶,吴胜利
(江苏大学 计算机科学与通信工程学院,江苏 镇江 212013)
0 引 言
时态信息检索(temporal information retrieval)[1]中部分查询的内容未包含明确形容时间的词汇,但符合此查询检索需求的文档大多数在某个特定的时间区间,称这种类型的查询为隐式时间查询。如用户提交一个查询“上海世博会”,用户感兴趣的时间区间很有可能是世博会的举办时间:2010年5月1日至10月31日。针对这种类型查询,研究人员提出一些分析查询时间意图的方法,如Kanhabua等通过前k个文档的时间戳分析查询的时间意图[2];Gupta等提出一种模型,同时考虑文档的发布日期和文档内容中的时间词汇对检索结果的影响,在不同时间区间(如年、月、日)下分析满足用户检索需求文档对应的时间区间[3];Kanhabua等利用查询日志识别事件对应的实体,然后通过机器学习算法对实体进行分类[4];Lin等建立了一个能够提取时间表达式的检索模型,同时考虑查询和检索结果之间的时间相关性以及文本相关性因素[5]。
本文结合DBpedia知识库和排名前k个文档内容中的时间词汇这两种方法分析查询时间意图,在此基础上计算各文档的时间相关性得分,最后线性结合内容相关性得分和时间相关性得分对文档重新排序。
1 方 法
文档集C={d1,d2,d3,…,dn},其中文档di={w1,w2,w3,…,wm,t1,t2,t3,…,tn},关于文档主题词汇wm的集合记作dword,文档中与时间相关的词汇tn的集合记作dtime[8]。
针对隐式时间查询,计算文档相关性得分排序的流程如图1所示,主要过程如下:
(1)在文档集中构建索引,计算文档集中每个文档与用户查询的相关性得分,从高到低排序,得到初始排名结果;
(2)利用DBpedia语义网和初始排名结果中排名前k个文档中的时间词汇,分析查询时间意图,通过排名模型计算文档与用户查询在时态方面的相关性得分;
(3)线性结合内容相关性得分和时间相关性得分对结果重排。
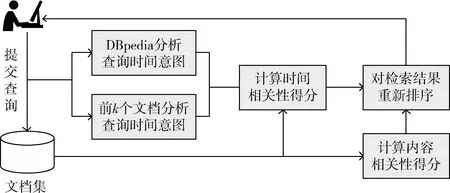
图1 隐式时间查询排名算法流程
此算法中主要包括分析查询时间意图和利用检索模型对文档排序两部分,下文中将分做详细介绍。
1.1 确定查询时间意图
假如用户希望查询某位公众人物或者历史上曾经发生的某个重大事件,本文提出利用语义网DBpedia获取与该查询相关的时间信息,并作为该查询的时间意图;否则通过排名前k个文档内容中的时间词汇确定查询的时间意图。
1.1.1 利用DBpedia确定时间意图
DBpedia知识库是一种特殊的语义网络,从维基百科页面中提取的结构化的信息,存储了大量的由资源描述框架描述定义的实体[6]。除此以外,可以通过链接访问网络上的其它数据集,强化检索功能[7]。
在本文中,我们通过SPARQL语言查询DBpedia知识库中某位公众人物或者历史上曾经发生的某个重大事件的具体日期,确定查询的时间意图。
1.1.2 排名前k个文档确定时间意图
若查询的内容不是关于历史事件或者人物,首先对文档集构建索引,检索得到仅考虑内容相关性的前k个文档,这些文档中出现频率较高的时间点能够满足用户查询时间意图的概率较大。因此,把前k个结果中出现频率超过m次的时间点的集合作为用户查询的时间意图[8]。
1.2 检索模型
隐式时间查询q由查询主题qword和时间意图qtime两部分组成,通过如下公式计算每个文档d的最终得分S(q,d)
(3) 动物园的安全警示是否充足。根据城市动物园管理规定第三章第二十一条:动物园管理机构应当完善各项安全设施,加强安全管理,确保游人、管理人员和动物的安全。动物园方应该设置足够多且位于醒目位置的警示牌、在危险区域安排足够多的巡逻车、安装数量充足的监控摄像头保证二十四小时的不停歇监控, 在发现游客有危险举动时应立即上前劝阻与阻拦。
S(q,d)=α·S′(qword,dword)+(1-α)·S″(qtime,dtime)
(1)
α是调节内容相关性和时间相关性的参数,下文中介绍3种计算时间相关性得分的方法。
1.2.1 语言模型
基于语言模型计算时间相关性得分的方法如下[9]

(2)
在某些情况下,两个时间点Q和T表现形式不同,但实际上指向同一个时间段,即具有相同的时间意图。所以在计算P(Q|T)值时有必要考虑时间因素存在的不确定性,下文介绍两种计算P(Q|T)的方法。
第一种方法是比较Q与T两个时间点的时间间隔,如果两个时间点Q与T的时间间隔在n天内,P(Q|T)为1,否则结果为0

(3)
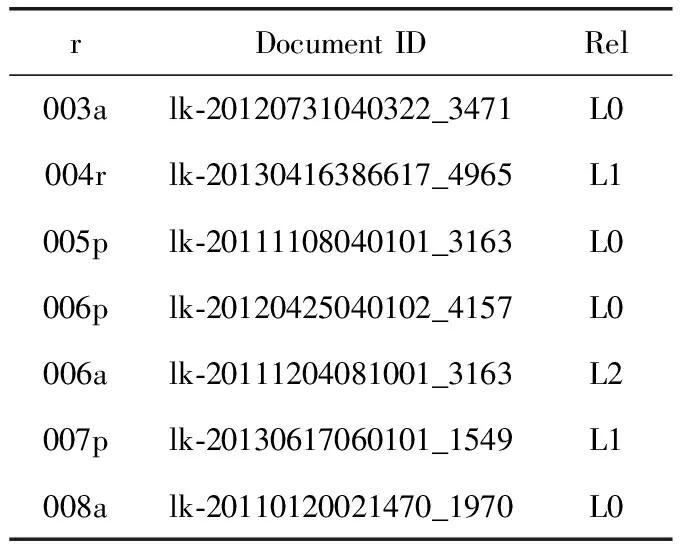
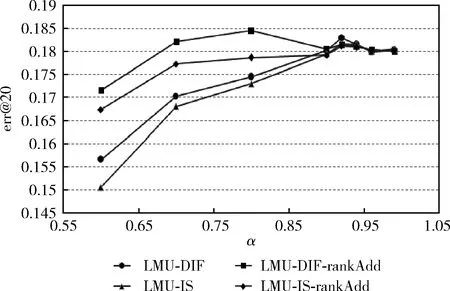
第二种方法把与查询中的某个时间点Q前后相差n天的区间内的时间点组成一个集合Q′={t|Q-n (4) 1.2.2 度量空间模型 Matteo等提出在度量空间下计算时间相似性,计算查询和文档中时间点的曼哈顿距离[10]。文档d中的时间区间[a,b],查询q时间意图区间为[c,d],使用式(5)计算查询q与文档d时间区间的曼哈顿距离 δsym([a,b]Q,[c,d]D)=|a-c|+|b-d| (5) 通过曼哈顿距离值对文档降序排序,使用式(6)得到的结果即为时间相关性得分 (6) 其中,rank是文档对应的排名位置。 查询:实验中共使用50个查询,每个查询由标识符id,查询关键词title,查询意图的详细描述description,查询子主题subtopic(用户可能希望通过检索了解的问题,包括不考虑时间因素的子主题atemporal、关注过去发生事情的子主题past、关注近期发生事件的子主题recency和关注未来发生事件的子主题future)等组成,查询示例见表1。本文选取各个查询中时间意图在过去时间区间的past子主题进行实验。 表1 查询示例 评价相关性:NTCIR会议文档集为每个查询提供了判断文档与查询相关性的评价文件,部分评价文件的内容见表2。“r”为评价相关性子主题标识,由查询编号和子主题类型组成;Document ID为文档的唯一标识; Rel是判断文档在该子主题下的相关性,L0代表文档与查询不相关,L1代表文档与查询部分相关,L2代表此文档与查询非常相关,完全满足查询需求。 表2 部分评价文件示例 实验中使用的几种排名方法定义如下:LMU-DIF方法通过式(3)计算P(Q|T)从而计算时间相关性得分,内容相关性得分为Indri的原始得分进行0-1规范化后的结果;LMU-DIF-rankAdd和LMU-DIF使用同一个方法计算时间相关性,但是区别在于LMU-DIF-rankAdd方法首先使用公式score=1/(rank+60)把初始排名转换为分数,然后通过式(7)0-1规范化得分。相似地,LMU-IS和LMU-IS-rankAdd方法利用式(4)计算P(Q|T)得到时间相关性得分并规范化。使用式(5)计算时间相关性得分,两种不同规范化得分的方法分别记作Metric和Metric-rankAdd。除此以外,本文还与Kanhabua等[2]提出的两种方法性能进行比较, QW方法利用查询内容中的关键词分析时间意图,NLM使用前k个文档的创建日期分析查询时间意图,然后在查询时间意图的基础上计算时间相关性得分 (7) 考虑时间不确定性的因素,本文实验中设置时间间隔为7天,k值为200[8]。 前文1.1.1节中提出一种通过DBpedia分析查询时间意图,038号查询是此类查询的一个示例,线性结合内容相关性和时间相关性得分重排后结果的MAP,RP,nDCG@20这3个指标值如图2所示。比较发现,各方法的指标值都高于基准值,表明在检索模型中考虑时间因素有利于提升检索性能,本文提出的通过DBpedia分析查询时间意图方法具有可行性。 图2 利用DBpedia计算时间相关性得分重排后指标值 使用前文中得到的最优参数进行实验,结果表明,考虑时间相关性重排后排名结果中个别指标比Baseline略低,其它模型的性能都有所提升,说明在检索模型中考虑文档与查询在时间方面的相关性具有一定的意义,有利于检索出更多符合用户需求的文档。在所有的排名模型中LMU-DIF和LMU-DIF-rankAdd方法中大多数的指标值比其它方法高,表明以式(3)为基础计算时间相关性得分作为内容相关性得分,然后对文档重新排序的方法性能更优[12]。 图3和图4显示不同内容相关性和时间相关性权重(α值)对LMU-DIF,LMU-IS,LMU-DIF-rankAdd,LMU-IS-rankAdd这4种方法err@20指标的影响。这两个指标变化趋势都是先上升到峰值后下降,数据表明检索模型中应合理分配内容相关性和时间相关性权重,否则会降低检索结果的性能。 分析图3中4种方法的变化趋势可以得出结论,当α小于0.9时,LMU-DIF-rankAdd方法指标值更高;而α值大于0.9以后,各方法的性能比较相近,LMU-DIF略胜一筹。综合比较,LMU-DIF-rankAdd在取最优时间相关性权重时,指标值高于其它方法,性能更优。 图3 不同α值下err@20指标值变化趋势 图4中展示不同α值下P@20指标的变化趋势,LMU-DIF-rankAdd和LMU-IS-rankAdd这两个使用式(6)规范化时间相关性得分的两个方法变化趋势比较相似,另外两个规范化Indri系统得分的方法变化趋势比较相似,可见不同分数规范化方法对检索新能存在影响。当各方法取最优的时间相关性权重时,LMU-DIF和LMU-IS方法指标值更高,性能更优。 图4 不同α值下P@20指标值变化趋势 本文提出一种提高隐式时间查询文档排名性能的方法,该方法首先分析隐式查询的时间意图,计算时间相关性得分,最后线性结合时间相关性和内容相关性得分对文档重新排序。实验结果表明我们提出的方法一定程度上有利于提高隐式时间查询的检索性能,返回更多满足用户查询意图的检索结果。然而,有些用户检索的内容可能是周期性举办的事件,如奥运会、世界杯等,查询的时间意图可能是多个时间区间。如何分析此类查询的时间意图,满足查询时间意图的多样性,是今后工作中需要研究的问题。
2 实 验
2.1 实验设置

2.2 实验结果


3 结束语
