基于排序集样本和双辅助变量的比率估计改进方法
2018-10-29张建军吕海燕乔松珊
张建军,吕海燕,乔松珊
(1.河南农业大学 信息与管理科学学院,河南 郑州 450002;2.中原工学院 信息商务学院,河南 郑州 450007)
总体参数估计是统计推断中的一个常见问题,涉及农业、经济、医药以及人口等诸多方面,基本方法是利用获取到的样本观测数据估计总体未知参数,一般而言观测数据越多估计效果越好.然而,由于实验时间和经费等因素制约,人们不可能从大量样本中获取所需观测数据,这就对样本的代表性提出了更高要求.1952年,McIntyre[1]在估计总体均值时首次引入一种更高效的抽样方法——排序集抽样,随后,一些学者在理论上进行了补充,证明了该抽样方法下样本均值仍然是总体均值的无偏估计量,并且估计的均方误差要比简单随机抽样更小[2].基于排序集样本的统计推断已经有不少结果,内容涉及参数估计[3]、非参数检验[4],以及在多个领域的应用[5-7].
辅助信息在提高总体参数估计精度方面具有十分重要的作用,对于只有一个辅助变量的情形,已经有一些学者提出了总体均值的比率、乘积和回归估计方法[8-10]以及一些改进形式[11].在实际抽样调查中,往往会存在与研究变量相关的两个甚至多个辅助变量,这些辅助变量有些和研究变量是正相关,有些是负相关,充分利用这些辅助信息,可以建立多种均值估计形式[12].我们注意到,现有文献的抽样基础都是简单随机抽样,并没有在抽样设计阶段考虑估计量的优化问题.文中以排序集抽样代替随机抽样,基于双辅助变量建立总体均值比率估计量,并进一步对估计量进行优化;通过计算估计量的估计偏差和均方误差,从理论上比较了两种抽样方法下比率估计的均方误差.结果表明,在一定条件下,基于排序集样本和双辅助变量的比率估计可以较好地提高估计量的精度;最后借助数值计算,比较了几种不同估计量的估计效果.
1 随机抽样下总体均值的比率估计
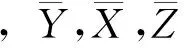
为了提高估计精度,文献[12]通过选择适当的权重,提出了基于双辅助变量的比率估计方法:
其中w1+w2=1.估计量的均方误差为
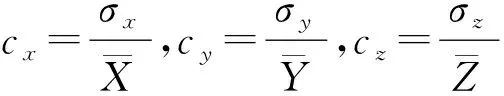
2 排序集样本和双辅助变量的比率估计
下面利用排序集样本代替随机抽样,研究采用双辅助变量的均值比率估计方法.排序集抽样过程可按照如下方式进行:首先,从三维总体(Y,X,Z)中一次抽出m2个体,随机划分为m组;接着依据辅助变量X对每组个体进行排序,从第i组抽取秩为i的个体作为观测样本,记为(y[i],x(i),z[i]),i=1,2,…,m,其中圆括号表示完美排序,方括号代表有偏差排序.类似过程重复r次,得到容量为mr的三元排序集样本,记为
(y[i]j,x(i)j,z[i]j),i=1,2,…,m;j=1,2,…,r.
类似地,当两个辅助变量的总体均值已知时,排序集抽样下变量Y的均值比率估计量为[8]
其中
分别为排序集抽样下的样本均值.
类似文献[12]的构造方法,同时利用两个辅助变量,基于排序集样本也可以建立双辅助变量的比率估计:
另外,辅助变量的变异系数、相关系数和中位数对估计精度有一定影响[13-16],故当辅助变量的这些参数已知时,得到如下估计量的改进形式:
估计量的精度依赖参数的选取,参数的不同取值对应不同估计形式,为了比较这些估计形式的效率,分4种情况讨论:
情形1.a1=a2=1,b1=ρxy,b2=ρzy,其中ρxy,ρzy为相关系数,即
情形2.a1=a2=1,b1=mx,b2=mz,其中mx,mz为辅助变量中位数,即
情形3.a1=cx,a2=cz,b1=ρxy,b2=ρzy,其中cx,cz为辅助变量变异系数,ρxy,ρzy为相关系数,即
情形4.a1=cx,a2=cz,b1=mx,b2=mz,其中cx,cz为辅助变量变异系数,mx,mz为辅助变量中位数,即
特别地,当a1=a2=1,b1=b2=0时,估计量ymbr,rss=ybr,rss,故下文仅讨论估计量ymbr,rss的估计偏差和均方误差,其他估计量类似可得.
3 估计量的性质
估计的偏差和均方误差是衡量估计量精度的重要指标,为此首先分析估计量的估计偏差和均方误差计算方法.
利用文献[8]中的计算结果,排序集抽样下样本均值的方差计算公式如下:
其中σx,σy,σz分别为变量的总体方差.协方差公式为:
定义如下误差项:
根据样本均值的无偏性[17],得到E(e0)=E(e1)=E(e2)=0,利用样本均值的方差和协方差公式容易得到
式中


注意到
其中
所以
假定|λ1e1|<1,|λ2e2|<1,则
在一阶泰勒近似下,有
估计量的偏差为
注意到E(ep)=0,p=0,1,2,代入误差项可得
根据定理1的结论容易看出,选择适当参数α,估计量ymbr仍为近似无偏估计.特别地,当α=1,a1=1,b1=0时,此时λ1=1,得到单辅助变量比率估计量yr1,rss的偏差计算公式为
同理,当α=0,a2=1,b2=0时,此时λ2=1,得到比率估计量yr2,rss的偏差计算公式为
定理2当|λ1e1|<1,|λ2e2|<1时,在一阶泰勒近似下,估计量ymbr的近似均方误差为

证明根据定理1,在一阶泰勒近似下,有
定理2的计算结果说明,估计量的精度与参数α的选取密切相关,不同取值得到的偏差和估计误差都不相同.为了确定最优的参数值,将估计量均方误差表达式视为参数α的函数,根据公式
得到
此时估计量的均方误差达到最小.
4 估计效率比较
一般而言,在相同样本容量下,估计量的均方误差越小,效率越高.以下比较排序集抽样和简单随机抽样下利用双辅助变量比率估计的均方误差.
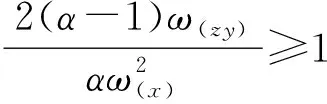
证明在MSE(ybr)计算结果中,取w1=α,w2=1-α,cxy=ρxycxcy,czy=ρzyczcy,cxz=ρxzcxcz得到
由于a1=a2=1,b1=b2=0时,估计量ybr,rss=ymbr,rss,此时λ1=λ2=1,根据定理1的计算结果,代入υ00,υ11,υ22,υ01,υ02,υ12的具体表达式,当两种抽样样本容量相同,即n=mr时,容易看出
由于
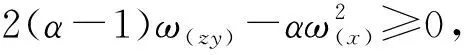
5 随机模拟
选取三维正态分布为研究总体,相关系数分别为ρxy=0.90,ρyz=0.80,ρxz=0.70,不妨取μX=2,μY=4,μZ=6,σX=σY=σZ=1.首先基于R软件生成5 000个三维随机数,设定随机数种子后,采用随机抽样和排序集抽样两种抽样方法进行比较,利用R软件进行100次的统计模拟.令m=3,4,循环次数r=10,15,20,样本量n=mr,分别计算估计量的估计值和均方误差,误差计算公式为


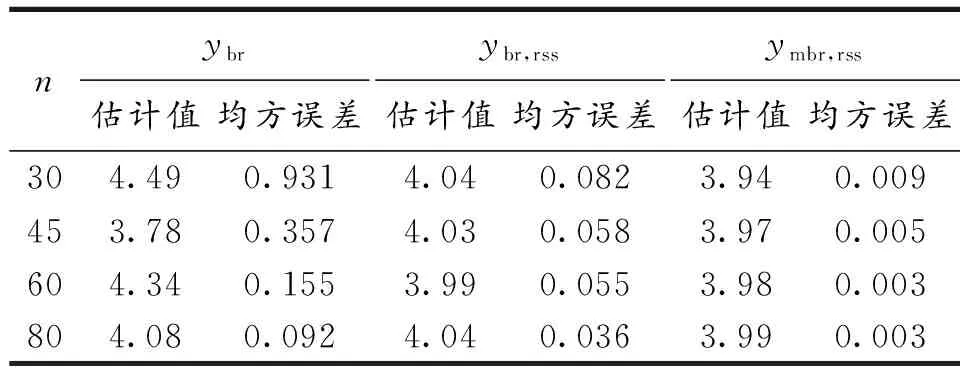
表1 排序集抽样和随机抽样下比率估计比较
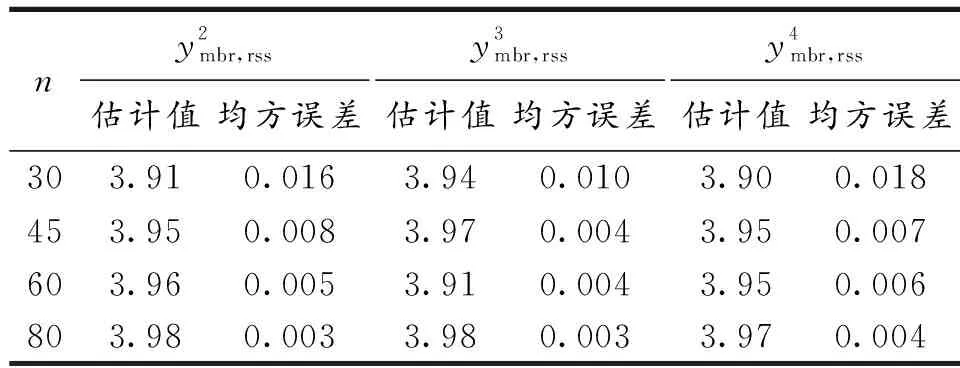
表2 排序集抽样下改进估计量比较

表3 单辅助变量和双辅助变量的比率估计比较
6 实例分析

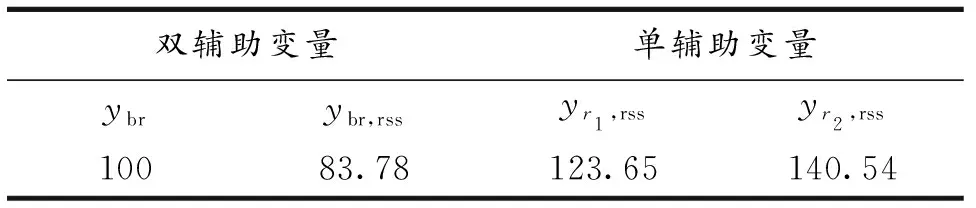
表4 不同比率估计的相对效率
计算结果说明,不论随机抽样还是排序集抽样,采用双辅助变量的比率估计的估计效果整体高于单辅助变量;从单辅助变量估计结果看出,比率估计精度和辅助变量与研究变量相关系数成正比;基于排序集样本的改进比率估计量估计效率明显优于简单随机抽样下的双辅助变量比率估计,说明在抽样设计阶段采用新的抽样方法可以有效提高比率估计精度.
7 结束语
在排序集抽样下利用双辅助变量构造了总体均值的比率估计方法,比较了两种抽样方法下估计量的均方误差,最后,利用随机模拟和实际例子进行数值分析.计算结果表明,排序集抽样下利用双辅助变量的比率估计在精度上高于随机抽样或者单辅助变量.另外,对于两个辅助变量相关系数有正有负的情形,读者可做进一步研究.
