基于随机森林算法的水华预警模型
2018-09-10刘云翔吴浩
刘云翔 吴浩


摘要:针对湖泊水华预警模型中的数据具有噪声较复杂和非线性的特点,而传统预警方法难以解决稳健性差和过度拟合等问题,采用机器学习分类算法——随机森林,根据叶绿素a的浓度判断水华是否发生,选取水温(T)、pH值、氮磷比(TN:TP)、化学需氧量(COD)、总氮(TN)、总磷(TP)作为影响因子,构建基于随机森林分类算法的穩健性较好、泛化性能强、实用性强的水华预警模型。选取太湖西半湖作为研究区域进行实例分析,结果表明:该模型预测精度达到91.67%,泛化误差小,能够有效进行短期预测;在水华发生的各个影响因子中,总磷和总氮是相对重要的影响因子。
关键词:随机森林;CART决策树;水华;预警模型;太湖
中图分类号:X52; TP39
文献标志码:A
doi:10.3969/j.issn.1000-1379.2018.08.018
水华是淡水水体中藻类繁殖聚集到一定程度的一种自然现象,目前已成为全球性的水环境污染问题之一,并且随着经济的快速发展和人类活动范围的急剧扩大而越来越严重。我国多数江河湖泊和水库有不同程度的水华现象。利用有效的方法预测水华的发生并进行预警,有利于有针对性地采取预防措施。为了解决水体水华预警问题,国内外学者从不同角度、采取不同方法进行了研究,如多变量统计回归、模糊数学、遗传算法和神经网络方法等,不过这些方法各有不足,建立的预测模型存在不同的问题。
把水华暴发的影响因子作为输人变量,以叶绿素a的浓度为输出变量,构建水华预测模型,可以判断水体是否发生水华,进行短期预测。这种通过分析已有的水体水质、水文等数据来判断水华是否发生,是一个典型的分类问题,因此可以采用决策树算法生成水华预警模型。决策树算法具有模型简单和规则提取简单的特点,其中CART算法是决策树算法中的经典算法,但基于传统CART算法生成的水华预测模型在进行判断时,依然存在准确率不高、易过度拟合等问题。随机森林是一种基于CART算法的组合分类器,能够提高分类正确率并解决过度拟合问题,因此笔者基于随机森林算法建立水华预警模型,对水体水华是否发生进行预测。
1 研究方法
1.1 随机森林算法原理
随机森林算法是一种具有监督性的数据挖掘算法,随机森林是一种利用大量CART决策树形成的分类器。把当前样本集的所有属性的GINI指数计算出来,对所有属性的GINI指数进行排序,选择GINI指数最小的属性作为CART决策树的根节点,然后以该属性的GINI指数为分割阈值将样本集分割成两部分。在生成CART决策树的过程中要充分利用二叉树,在分割后的子集上不断递归重复上述操作,使得最终生成的非叶子节点都具有左有两个分支,直到所有叶子节点中样本的类别基本属于同一类,或者没有下一个分裂属性为止。
GINI指数反映数据分区E的不纯净程度,定义如下:式中:pi=|Ci|/|E|,为E中的样本属于类Ci的概率,|Ci|为E中属于Ci的数量;m为样本分类数。
当属性A将训练样本集E划分成E1和E2后,E的GINI指数公式为式中:|Ei|/|E|为样本集中样本属于第j(j=1,2)个子集的概率。
随机森林是由许多没有经过剪枝的CART分类树{h(x,@k)|k|=l,2,…}(x为输入变量,@k为服从独立同分布的随机向量)形成的一种组合分类模型。随机森林的构建具有两种随机化思想:一是根据bootstrap重抽样创建k个随机向量@1、@2、@3、@4,再将每个随机向量@i变为一个无剪枝的决策树h(x,@i)(简称hi(x)),得到k棵决策树序列{h1(x),h2(x),…,hk(X)},每棵决策树之间没有任何关联,第k棵树的形成流程见图1:二是在生成决策树时,选择的属性也是随机生成的,需要在所有的属性集中等概率随机选择特征属性值,构成特征属性子集,再利用这些特征属性子集中的特征属性构成需要的决策树。形成的大量决策树组合在一起称为随机森林,简称RF。假设y为输出变量,由(x,y)所构成的样本数据集称为原始样本数据集。最终的分类结果由上述序列中所有决策树的分类结果综合决定,本文采用的是最简单的投票决定法,输入变量x的类别为得票数最多的类别。最终的分类结果可用公式表示如下:式中:H(x)表示组合分类器模型;hi为第i个决策树分类模型;I(·)为示性函数(示性函数是指使集合中有该数值为1,没有则为0);argmax表示其后表达式取得最大值时对应的变量x、y取值。
1.2 随机森林算法模型的建立
随机森林算法模型建立的步骤如下。
(1)用bootstrap方法从原始数据中选取k个不同的样本集数据,每个样本集是每棵决策树的训练数据,且每个样本集的样本数量与原始数据集相等。
(2)用选取的k个样本集构建k个未剪枝的决策树。在生成每棵决策树的过程中,为了生成决策树的节点,需要从原始数据集中的所有M个特征属性中等概率选出m个(m≤M)特征属性作为候选特征属性。利用随机选出的m个候选特征属性构建决策树,并且使每棵树不进行剪枝地完整生长,得到k棵完整的决策树,每棵决策树都对输出变量做出分类,最终得到k个分类结果。
(3)根据得到的k种分类结果,对输出变量的最终分类进行投票,得票最多的类别为输出变量的最终类别。1.300B估计和属性变量重要性
采用bootsrap重抽样方法生成k个数据集时,在原始数据中将有近37%的样本可能没有被选中,这些样本称为Out-Of-Bag(OOB)数据。随机森林的每棵树都有一个OOB误差估计,取所有树OOB误差估计的平均值作为模型的泛化误差估计,用来检验模型的分类性能。大量试验表明,只要树的数量足够大,OOB误差与交叉验证得到的误差就相差不大。对于生成的随机森林模型,给其中某一个特征属性增加噪声,获取增加噪声前后的OOB准确率,用来检验模型性能,增加噪声后OOB值的减小幅度越大,这个特征属性就越有用。
2 实例应用
2.1 研究区域和数据来源
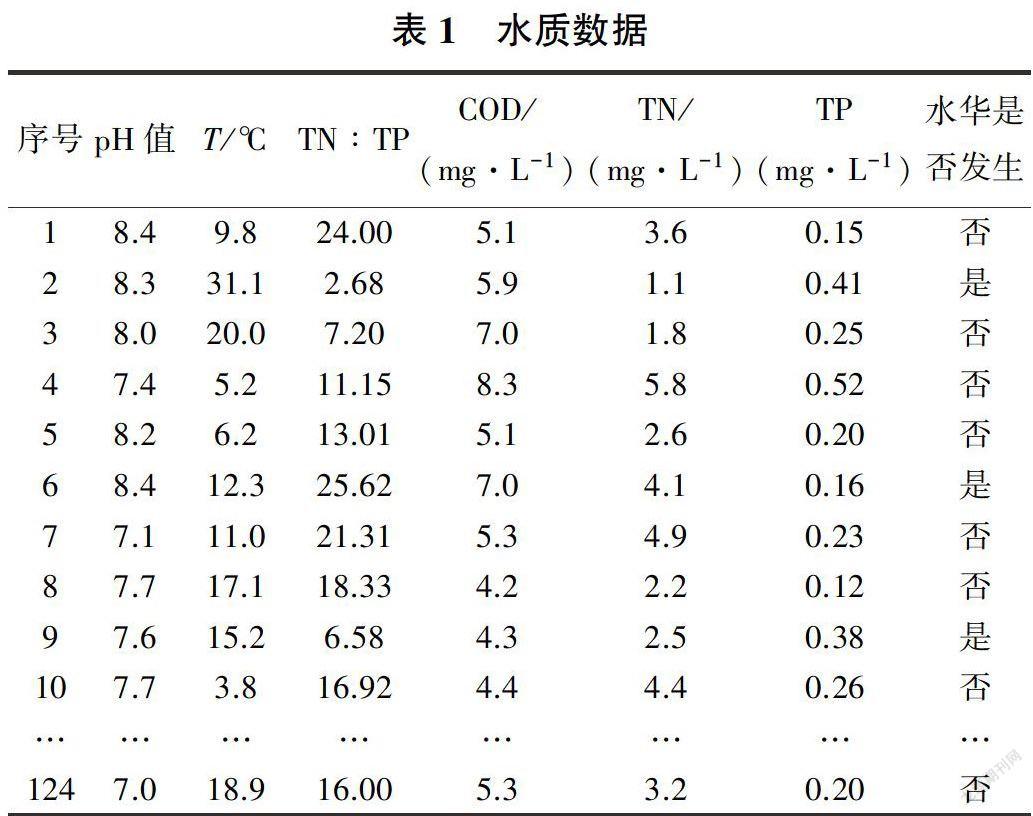
选取太湖西半湖作为研究区域,该地区曾多次暴发水华。研究所用水质数据来源于太湖水華在线监测基站。将叶绿素a的浓度作为判断水华发生的标准:大于0.003mg/L,表示有发生水华的可能性,需要进行预防:小于0.003mg/L,表示水环境状况良好,水华暴发的可能性不大。把水华是否发生作为随机森林模型的输出变量,将水温(T)、pH值、氮磷比(TN:TP)、化学需氧量(COD)、总氮(TN)、总磷(TP)等水质水文数据和输出变量一起构成原始数据集。共有124组原始样本数据(见表1,表中只列出一小部分),将其中前100组样本用于建立水华预测模型,后24组样本用于检验模型的分类性能。
2.2 模型分类性能评价标准
采用总体分类准确率(Acc)来评估RF模型的分类性能。Acc为最终分类预测值与真实值(实测值)的比值,其值越大表示模型的分类性能越好,计算公式为式中:Tp为正确分类的样本数;TN为总样本数。
2.3 随机森林模型的构建
采用RandomForest()函数来构造基于RF算法的水华预测模型,该函数有2个主要参数ntree和mtry,其中:ntree表示树的数量,其值越大表示过拟合的可能性越小,一般取100,经计算可以得到OOB误差与ntree的关系,见图2:mtry表示待选特征属性的个数,取值一般为所有特征属性个数的平方根,本研究特征属性个数为6,所以mtry的取值为2。由图2可知,当ntree>80时OOB误差趋于稳定,表明随机森林模型的分类性能较高。由文献可知,当ntree为100左有时,RF的分类性能与支持向量机相当,所以把ntree的值设为100,mtry的值设为2。用原始数据集的前100组数据进行训练,得到随机森林水华预警模型,把后24组数据作为测试数据输入随机森林模型,对这24组数据进行分类判定,最终的分类准确率为22/24,而支持向量机的分类准确率为21/24,说明随机森林水华预警模型行之有效。
另外利用随机森林预警模型还可以对水华影响因子的相对重要性进行比较,以获得太湖水华发生各影响因子的重要程度,结果见图3。由图3可知,在所有影响水华发生的因子中,TP浓度的相对重要性较高,其次是TN浓度,所以为预防水华暴发,要特别注意TP浓度和TN浓度。
3 结语
随机森林模型不需要先设定属性的权重、怎样去分类,模型需设置的参数少,计算过程简单、计算量较小,适合平台广泛,是一种快捷有效的机器学习模型。基于机器学习算法——随机森林,把影响水华发生的6个因子作为随机森林的输人变量、把叶绿素a的浓度作为输出变量,建立水华预警模型。测试结果表明,其最终分类准确率达到了91.67%,与支持向量机模型的分类性能相当,能够解决其他算法稳健性不足和过拟合等问题,能保证预测正确率且可以分析影响水华暴发的主要因子,为水环境管理提供理论支持。
