利用动态多池卷积神经网络的情感分析模型*
2018-07-13喻涛,罗可
喻 涛,罗 可
长沙理工大学 计算机与通信工程学院,长沙 410114
1 引言
随着互联网相关技术的飞速发展,用户通过微博等媒体自由地在社交网络中表述自己的观点,在电子商务平台对购买的商品进行评价,在豆瓣等网站进行电影评论等行为已成为日常生活的一部分。如何利用机器学习、深度学习技术对海量信息进行分析,获得文本的观点倾向、情感极性成为自然语言处理领域的一个重要研究课题[1]。
情感分析(sentiment analysis,SA)又称倾向性分析和意见挖掘,它是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。传统的情感分析技术可分为两类,第一类为基于情感词典的方法,第二类为基于机器学习的方法。前者从语言学的角度出发,每个词或短语由专家赋予情感极性或者情感强度,研究者结合情感词典数据,构建人工规则,判断目标文本的情感极性。在这类方法的研究上,谢松县等人[2]采用混合特征的情感词典方法进行情感分析,杨小平等人[3]采用基于word2vec的情感词典构建方法完成情感分类。后者机器学习算法[4]借助于大量人工标注的特征来确定给定文本的情感极性。该算法实现了很好的性能,但需要大量的人工操作和领域知识。近年来,随着深度学习的研究不断深入,将词语编码为词向量,利用深度神经网络技术对文本进行分析成为研究的新领域。例如,Kim[5]提出使用卷积神经网络(convolution neural network,CNN)进行句子建模;Socher等人[6-8]利用递归神经网络(recurrent neural network,RNN)提取句子的语义特征,进行情感分析等。
在情感分析领域,词作为最基本的研究单元,词向量训练的好坏对情感分析任务的精准度有重大影响。因此,研究者们提出了许多卓有成效的词向量训练方法,主要包括基于主题模型的方法和基于语言模型的方法。基于主题模型的方法是指每个词被表示成不同主题下的概率分布,较为典型的是基于LDA(latent Dirichlet allocation)的主题模型方法。如Mikolov等人[9]使用LDA方法,在大量的语料数据中学习到预定义数量的主题,每个词在不同主题下的概率分布即为该词的语义向量。基于语言模型的方法中经典之作为Bengio等人[10]采用三层神经网络构建语言模型的方法,把词映射到低维实数向量,通过词与词之间的距离来判断它们之间的语义相似度。Mnih等人[11]提出一种层级的思想,采用Hierarchical Log-Bilinear模型来训练语言模型。Mikolov等人[12-13]提出了word2vec框架,构建了Continuous Bag-of-Words(CBOW)模型和Continuous Skip-Gram模型。
传统基于词向量的卷积神经网络模型在情感分析任务上取得了很好的效果,但存在两个缺点:第一,传统的词向量仅考虑了文本中的语义或语法信息,未考虑词语本身的情感极性,往往导致一些具有相同用法,情感极性却相反的词语被映射到相近的向量中,这对情感分析任务是致命性错误。第二,传统卷积神经网络由卷积层(convolution layer)、最大池化层(max-pooling layer)和全连接层(full connection layer)组成,卷积层提取句子特征,最大池化层选择局部最大特征,全连接层完成任务分类。但是传统模型中最大池化层是从整个句子的局部特征中提取最大值,没有针对句子的结构进行多段分析。例如在某一转折句中,情感极性为转折后的消极,若转折词前正面情感词多,提取的最大特征将句子误分类为积极,这对情感分析任务同样也是致命性错误。根据中文倾向性分析评测COAE2014(Chinese opinion analysis evaluation)数据集统计发现,这种转折类的句子占数据集的17.3%,这是一种不能忽略的现象。
针对以上两点不足,本文提出一种基于情感词向量的动态多池卷积神经网络(dynamic multi-pooling convolution neural network based on sentiment word vector,SDMCNN)模型。与仅以语义和句法为焦点的传统词向量学习不同,情感词向量能够根据它们的情感以及它们的语义和句法信息来区分单词。同时卷积神经网络采用动态多池层[14]策略,以转折词分割,分段获取句子每个部分的最大值,即保留多个局部最大特征值,更准确地完成情感分析任务。
本文组织结构如下:第2章介绍传统的卷积神经网络结构;第3章介绍基于情感词向量的动态多池卷积神经网络模型(即SDMCNN模型);第4章实验证明SDMCNN模型的性能;最后总结本文。
2 相关基础
卷积神经网络是一种前馈神经网络,由卷积层、池化层和全连接层3种类型的神经网络层组成。每一层的输出作为下一层的输入。卷积层是特征提取层,通过滤波器提取局部特征,经过卷积核函数产生局部特征图,输入到池化层。池化层是特征映射层,对卷积层提取的特征图进行采样,输出局部最优特征。全连接层对最优特征进行任务分类。
依据文献[15],简化的卷积神经网络结构如图1所示。

Fig.1 Simplified CNN structure图1 简化的CNN结构
给定长度为n的输入句子s,每一列代表一个词向量,句子s中的第i个词xi∈Rd为d维词向量,则s表示为:

其中,⊕是串接操作符,即xi:i+j是指词xi,xi+1,…,xi+j的水平串接。卷积是权重矩阵w∈Rh×d与句子s中xi:i+h-1串接矩阵的点乘积运算。卷积的目的是获得表示为句子s的最终特征图C(C∈Rn-h+1),利用大小为h×d的滤波器对输入特征矩阵进行卷积操作,计算如下:

其中,f(·)为卷积核函数,例如双曲正切;w为卷积滤波器;h为滑动窗口大小;b为偏置项。卷积后得到的特征图C为:

其中,ci表示特征图中第i个特征值。为了捕获每个特征映射ci的重要信息,呈现了几种池化方法,如最大池化(即c=max{ci})和平均池化
由于每个滤波器在卷积过程之后仅获得一个特征映射C,卷积神经网络模型通常通过使用多个不同窗口大小的滤波器,或者随机地初始化具有相同窗口大小的几个滤波器来产生多个特征。如图1所示,使用窗口大小为3的6个滤波器。池化后生成的特征(即)进入softmax层,来预测在预定义标签中的概率分布,计算公式如下:

卷积神经网络中的参数通过反向传播微调[16]。
3 模型构建
针对传统卷积神经网络模型未考虑词语的情感信息和句子结构两点不足,本文提出的基于情感词向量的动态多池卷积神经网络模型包括两部分:第一部分是构建情感词向量;第二部分是训练动态多池神经网络模型。
3.1 情感词向量
词语语义信息部分使用skip-gram模型[12]来训练语义词向量xsem。其中skip-gram模型是根据给定中心词预测它周围的词。假设句子中词组序列为x1,x2,…,xn,其目标是最大化式(5)中的条件概率:

其中,c是以当前词语为中心的上下文词数,c值越大模型训练效果越好,同时也会增加训练时间。
在skip-gram模型训练语义词向量的基础上,情感信息部分根据词语本身的情感特征,利用情感词典来构建情感属性向量xsen。
同时针对转折句结构,模型采用标注转折连词的方式训练情感属性向量。表1和表2分别列出模型考虑转折句式中使用的转折词和模型考虑的情感属性特征。

Table 1 Turning word list表1 转折词列表

Table 2 Attributes of sentiment information表2 词语情感信息的属性特征
给定长度为n的输入句子s,把句中每个词语xi,1≤i≤n,映射到一个k维的0,1向量空间,即xi∈Rk。其中k代表模型考虑词语本身具有的属性特征个数,每一维用数值0,1表示。0表示词语不具有此属性,1表示词语具有此属性。
假设x为情感词向量,则表示为:

3.2 动态多池卷积神经网络模型
情感词向量组成文本特征矩阵,作为动态多池卷积神经网络的输入。传统的卷积神经网络模型没有分析句子结构,采用最大池化层提取整个句子的最优特征,针对情感转折句式问题,往往会忽略转折之后情感极性的变化,导致情感分析错误。因此,本文采用动态多池的卷积神经网络模型,以转折词进行分割,分段提取句子局部最大特征,通过模型训练完成情感分析任务。
本文提出的基于情感词向量的动态多池卷积神经网络模型的整体架构如图2所示。模型包括4个层次,依次为情感词向量输入层、卷积操作层、动态多池层和情感分类输出层。

Fig.2 Dynamic multi-pooling convolution neural network model based on sentiment word vector图2 基于情感词向量的动态多池卷积神经网络模型
(1)输入层。由情感词向量X构成文本特征矩阵,语义词向量长度为dsem,情感向量长度为dsen,令xi∈Rd是对应于句子中第i个词语的d维向量表示,其中d=dsem+dsen。长度为n的句子表示如下:

因此,组合语义词向量和情感向量,将句子变换为特征矩阵X∈Rd×n。
(2)卷积操作层。卷积层旨在捕获整个句子的组成信息,并将这些有价值的信息压缩到特征映射中。xi:i+h-1是词xi,xi+1,…,xi+h-1组成的局部特征矩阵。本文利用大小为h×d的滤波器对输入特征进行卷积操作,即:

其中,ci代表特征图中第i个特征值,1≤i≤n-h+1;f(·)为卷积核函数;w∈Rh×d为滤波器;h为滑动窗口大小;b为偏置项。为了捕获不同的特征,通常在卷积中使用多个滤波器。假设使用m个滤波器W=w1,w2,…,wm,卷积运算可以表示为:

其中,1≤j≤m,卷积结果为矩阵C∈Rm×(n-h+1)。
(3)动态多池层。为了提取每个特征图中最重要的特征,传统卷积神经网络采用一个特征图作为池值。然而单个最大池不能很好地完成情感分析任务,因为一个句子可能包含两个相反极性的情感。为了准确预测,需要捕获情感改变中最有价值的信息。因此,在转折句中,对转折词前后的情感词进行分割并多段保留最大值,将其称为动态多池。与传统的最大池相比,动态多池可以保留更多有价值的信息,而不会错过最大化池值。
如图2所示,特征映射输出cj被“但”划分为两部分cj1、cj2。动态多池可以表示为:

其中,1≤j≤m和1≤i≤n。
通过动态多池层,获得每个特征图的pji。然后连接所有的pji形成一个向量P∈R2m。其中m是特征映射的数量,P称为句子级特征。
(4)输出层。由动态多池层得出的特征向量P作为softmax层的输入。softmax层的训练过程中引入了Dropout策略,即随机地将分段池化的结果向量按照一定比例ρ置0,没有置0的向量进行运算和连接,它将神经网络转换成多个模型的组合,提高了模型分析的准确率。最后得到情感分类的预测概率,同时根据训练数据的实际分类标签,对卷积神经网络的参数采用反向传播算法进行梯度更新,即:

3.3 目标函数
模型需要训练的参数包括词向量和卷积神经网络的参数。设词向量为X,卷积操作的参数为W,分类器的参数为F,令θ={X,W,F}。设训练集样本集合,其中Si表示第i个句子,yi表示句子的情感类别,k表示训练集样本的个数。p(yi|Si,θ)表示在已知参数θ时,将句子Si的情感分类为yi的概率,则优化的目标函数为:

为了防止过拟合并提高泛化能力,模型利用L2正则化对网络参数进行约束,其中λ为正则化的参数。模型训练中,采用mini-batch梯度下降法进行训练,即每次更新权值只需要一部分样本参与计算,保证尽可能寻找到最优解,并提高训练速度。则参数θ的更新方式为:

其中,α为学习率。
4 实验及结果分析
4.1 实验环境
本文实验环境配置具体如表3所示。

Table 3 Experimental environment configuration表3 实验环境配置
4.2 实验数据
情感属性向量使用的情感词典为HowNet情感词典和大连理工大学细粒度情感词典。本文实验数据采用COAE2014微博数据集(http://download.csdn.net/detail/u013906860/9776509),数据集分为训练数据集和测试数据集。训练数据集选取手机、翡翠、保险3个话题,总共7 000条微博,其中正面情感3 776条,负面情感3 224条。测试数据选取1 838条同一主题微博,其中正面情感1 004条,负面情感834条。本文采用多次重复实验来评估各个模型的性能,最终测评结果为实验的平均值。
为了充分测试SDMCNN模型的性能,除了在COAE2014微博数据集上进行情感分类,本文还将选取数据集4 286条,分为转折句式(1 069条)和非转折句式(3 217条)两部分,分别在SVM(support vector machine)、W2V+CNN模型和SDMCNN模型上进行情感分类实验,来考察SDMCNN模型在转折句上的分类性能。
4.3 数据预处理
数据集划分之后,在训练过程中采用mini-batch训练模型,因此需要对句子进行固定操作,对于长度小于句子最大长度lmax的句子进行补零处理。对数据集进行预处理过程包括:过滤所有的标点符号和特殊字符;格式转换;利用python中的jieba分词工具进行分词处理,将每条微博转化成以空格分隔的词语序列;训练词向量。一条微博为一行进行词向量学习,本文词向量采用word2vec工具(http://code.google.com/p/word2vec)中的skip-gram模型,它由2 000万条的微博语料训练产生,保证了词向量的高质量。
4.4 实验参数设置
本文实验中卷积核函数采用Rectified linear函数,模型中的参数由多次重复实验进行调节。参数主要有词向量的维度d,卷积核滑动窗口大小h,卷积核数量m,Dropout算法的比率ρ,mini-batch算法的学习率α。其中d的取值范围为{50,100,200},h的取值组合为(2,3,4)、(3,4,5)和(4,5,6),m在卷积操作的3个通道中保持不变,取值范围是{100,200,300}。这3个参数构成了27种参数组合,实验通过网格搜索方法调参,确定平均实验结果最优的参数组合。本文实验参数设置如表4所示。

Table 4 Model optimal parameter settings表4 模型最优参数设置
图3为目标函数随mini-batch迭代次数的变化曲线,当迭代次数达到50次以上时,目标函数最小且保持不变,因此实验设置训练迭代次数为50次。
4.5 实验对比
为了验证模型的有效性和准确性,设计实验与以下模型进行性能对比:

Fig.3 Change of objective function图3 目标函数变化曲线
(1)传统机器学习。在相同的数据集上,为了保证实验的可比性,构建输入特征采用本文训练情感词向量的方式,分别用线性回归(Linear Regression)、随机森林(Random Forest)、支持向量机(SVM)方法进行情感分类来证明卷积神经模型在情感分析任务上的性能优势。其中Linear Regression通过学习一个线性模型来预测实值输出标记。Random Forest是一个包含多个决策树对样本进行训练并预测的分类器。SVM通过构造一个超平面或无限维空间将训练样本正确分类,在情感分类任务中取得过较好的结果[17]。
(2)Rand+DMCNN模型。按高斯分布随机初始化词向量,采用动态多池层的卷积神经网络(dynamic multi-pooling convolution neural network,DMCNN)模型,证明由skip-gram模型训练的词向量在描述原始数据特征分布上的性能优势。
(3)skip-gram+DMCNN模型。采用skip-gram模型训练的词向量作为二维特征矩阵输入动态多池层的卷积神经网络模型,证明融合情感信息的情感词向量在情感分析任务上的性能优势。
(4)SWV+CNN模型。采用情感词向量(sentiment word vector,SWV)作为二维特征矩阵输入传统卷积神经模型,证明动态多池层在处理情感转折句式上的性能优势。
(5)W2V+CNN模型。文献[5]中Kim提出了基于word2vec训练的词向量的卷积神经网络模型,证明采用情感词向量和动态多池策略的SDMCNN模型比传统卷积方法更胜任情感分析任务。
4.6 实验结果与分析
在机器学习(machine learning,ML)、自然语言处理(natural language processing,NLP)、信息检索(information retrieval,IR)等领域中评估是一个必要的工作,而其评价指标往往有如下几点:精确率(Precision)、召回率(Recall)和F1-Measure。Precision衡量的是查准率,Recall衡量的是查全率,这两个指标共同衡量才能评价模型的输出结果,F1值就是精确值和召回率的调和均值,即综合评价指标。各个模型在COAE2014微博数据集上对3个指标的测评结果如表5所示。

Table 5 Experimental results on COAE2014 data set表5 COAE2014数据集情感分析测试结果
实验结果表明,后4种采用CNN的模型在情感分类任务上总体优于机器学习方法,SDMCNN模型在Precision上取得最好的结果,较Linear Regression、Random Forest和SVM有很大提升,比取得第二好的SWV+CNN模型提高了2.81%。仅采用情感词向量的SWV+CNN模型和仅采用动态多池层的skip-gram+DMCNN模型较经典模型W2V+CNN在Precision和Recall上都有提升。最终,在F1上SDMCNN模型分别高于SWV+CNN模型和skip-gram+DMCNN模型2.14%和2.10%,取得了最好的实验结果。
分别将实验模型进行对比,得出以下结论。
结论1将 Linear Regression、Random Forest和SVM方法与W2V+CNN模型对比,在情感分类任务上,针对词向量这种分布式的特征表示,机器学习方法构建和匹配特征的优势不如卷积神经网络模型,且卷积神经网络通过局部感知野和权值共享,减少了模型参数,同时降低了模型复杂度。W2V+CNN模型在F1上明显高于其他3种模型,证明了卷积神经网络在情感分类上的出色表现。
结论2将SDMCNN模型与Rand+DMCNN模型和skip-gram+DMCNN模型对比,在保持动态多池层卷积神经网络结构不变的前提下,融合情感信息的情感词向量能有效提升文本情感分析的准确率。相比按高斯分布随机初始化词向量,word2vec训练词向量能够在更抽象的层面上描述原始输入数据的特征分布情况,而串接情感属性向量的情感词向量在模型迭代训练中不断更新,按最优的方向收敛得到最优解,更适合情感分析任务。skip-gram+DMCNN模型比Rand+DMCNN模型在F1上提升了5.61%,在输入特征为情感词向量矩阵的基础上,SDMCNN模型比skip-gram+DMCNN模型在F1上提升了2.10%。
结论3将本文提出的SDMCNN模型与SWV+CNN模型对比,在保持情感词向量不变的前提下,动态多池卷积神经网络模型在转折句式上能有效提升文本情感分类的准确率。SDMCNN模型采用动态池化分段提取句中最大值,比最大池化方法能更准确地完成情感转折句式的情感分类。
结论4将SDMCNN模型与W2V+CNN模型对比,SDMCNN模型很好地结合了情感词向量和动态多池层两种方法的优势,在F1上比W2V+CNN模型高出5.67%,分类性能得到极大提升。
针对转折句式和非转折句式数据集来考察模型实验性能,结果如图4、图5和图6所示。
从整体来看,SVM和W2V+CNN模型的转折句式的Precision、Recall和F1评价指标都明显低于非转折句式,表明在含有几个情感词的转折句中,这两种模型训练特征并正确分类的性能较差。而SDMCNN模型在转折句上的性能指标极大提升,与非转折句式保持很小的差别。特别从图6得出,在总微博数、转折句式和非转折句式数据上的F1变化不大,同时也是实验的最好结果,表明SDMCNN模型在转折句式上准确处理情感分类任务的充分优势。
5 结束语

Fig.4 Precision of experiment test data图4 实验测试结果的精确率
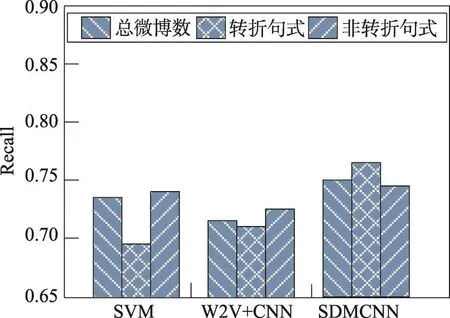
Fig.5 Recall of experiment test data图5 实验测试结果的召回率

Fig.6 F1 of experiment test data图6 实验测试结果的F1
针对词向量缺乏情感信息和传统卷积神经网络未考虑句子结构问题,本文提出了一种基于情感词向量的动态多池卷积神经网络模型。一方面,在skip-gram模型训练包含语义和句法的词向量的基础上,利用情感词典获取词语本身的情感属性来训练情感词向量。另一方面,在传统卷积神经网络模型的基础上,采用动态多池策略,以转折词分割多段提取最大特征值。在COAE2014数据集进行训练和测试,证明基于情感词向量的动态多池卷积神经网络模型比传统卷积神经网络模型能更准确地完成情感转折句式的情感分析任务。本模型在真实的数据上进行实验,因而具有普遍的实用性。但微博中的网络用语更新速度快,词语的情感属性依赖于情感词典,因此研究情感词典的扩展方法,进行情感词向量训练将成为以后的一个方向。
