多维数据特征相似性测量的目标预测方法
2018-05-22李国祥夏国恩王继军
李国祥,夏国恩,王继军
(广西财经学院a.教务处;b.信息与统计学院,南宁 530003)
0 引言
目标变量预测广泛应用于工业过程控制、经济数据处理、政府宏观规划等领域。比如GDP的预测、区域物流需求量的预测、交通流预测等。目前根据对于预测目标变量所采取的数据类型,可以将目标变量分为两类,一类是与属性变量强关联的目标变量,该类目标变量理论上认为是由多维属性变量建立线性或非线性关系共同作用的结果[1,2]。该类目标变量的预测通常选用不同的模型建立属性变量与目标变量的映射关系并拟合。这一类方法考虑了目标变量和属性变量间的关联关系及各因子间的相互制约等,但是属性变量获取的滞后性,使得目标变量很难有效地在时间轴上进行拓展。另外一类目标变量则是与其他变量没有关联映射关系的单独数据个体,通过对其在时间轴上的前后延伸,形成该变量的时间序列,进而建立模型探寻历史数据的规律来完成其时间轴上未来几点的预测。一些经典的时间序列预测方法,诸如AMIMA、灰色系统理论、SVM(支持向量机)等,便是该类方法的代表。但是这种以目标向量构造时间序列的预测方法,自身数据源既是训练样本又是测试样本,其数据节点预测依赖于前期若干维数据节点,该结果又作为下一节点预测的数据基础,预测误差也容易传递下去,而造成最后结果的偏离。
以上预测方法不同的适用范围,使得广大研究人员开始对不同方法的集成和新算法的融合进行研究,文献[3]构建ARIMA和SVR组合预测模型,对道路交通事故相关指标进行趋势预测。文献[4]提出了一种基于快速子空间分解方法的回声状态网络预测模型。文献[5]利用隐马尔科夫模型中的隐状态来表示产生时间序列数据时的系统内部状态,实现对多步时间序列的预测。这些研究方法进一步拓展了目标变量的预测理论,但是不难看出,当前的研究方法都集中在预测模型建立的方法论上,鲜有文献对多维属性数据特征本身进行研究,而数据源本身才是整个目标预测的基础。究其原因,一方面可以归结为全数据特征的高维数容易使智能学习算法陷入维数灾难,另一方面是难以在大数据环境下寻找属性特征与目标变量间的映射关系。
为此,本文以目标数据关联的高维属性特征为研究对象,通过比对不同属性特征直方图的相似性差异,将其转化为线性规划的运输问题,探寻高维数据特征与目标变量的非线性关系。
1 相似性测量
目前相似性测量的研究主要集中在时间序列的数据挖掘和模式识别领域。在数据挖掘方面,时间序列的相似性测量的重点是不同序列间的匹配程度,主要包括子序列匹配(Subsequence Matching)和整体序列匹配(Whole Sequence Matching),在此基础上进而聚类、分类、以及关联规则的抽取。文献[6]通过比较两个地震序列的L1距离与设定阈值的大小并加权,完成不同地区地震序列相似性判断。文献[7]根据查询序列和数据库时间序列中的不确定性进行组合,分别提出对应组合的相似性匹配算法。文献[8]提出了基于斜率表示的时间序列相似性度量方法。文献[9]则通过对时间序列逐段线性化,取两序列的最长公共子序列LCSS(longest common subsequence),作为其距离度量方法并进行相似性搜索。伴随着人工智能技术的不断发展,多种智能算法组合优化的研究也得到了广泛的开展。文献[10]基于二维奇异值分解进行了多元时间序列相似性匹配。文献[11]提出了一种基于形态特征相似性度量的方法来近似度量时间序列。但是这些方法主要研究对象往往为不同序列间的匹配,对既包含时间变量又包含属性变量的多维度面板数据研究较少。
在模式识别方面,相似性测量的研究主要应用于高维特征比对中,通过测量不同特征向量的相似性程度进而对不同模式分类。Adrian Ion[12]使用L2距离对特征向量做分类,Marcin Marszałek[13]采用重叠区域比率的方法衡量其特征shape mask的差异距离。Julien Rabin[14]针对于部分二三维图像研究了不同相似性测量方法的有效性。目前相似性测量主要通过距离函数来计算,如MinkowskiDistance、Euclidean Distance、x2Distance、Kullback-Leibler Divergence等,但是这些计算方式依赖于相对应属性或时间节点的特征,从局部地绝对运算来比较序列的相似,因此对于特征波动较为敏感,或者对于属性的一致性要求较高。为了能够更好地在属性变量之间进行平衡,越来越多的高维优化算法也得到了广泛的研究,从全局的角度对比序列的相似[15-17],且取得了较好的测量效果。同时,也不难发现无论是时间序列还是模式识别领域,相似性测量的本质都是N维向量的不同距离函数的比对计算。
2 基于相似性测量的目标预测方法
在多维属性特征与目标向量强关联的预测中,不同的研究方法对于指标的选取往往不同,以物流需求量的预测为例,文献[1]选用第一、二、三产业产值等六个指标,文献[18]采用GDP作为主要指标。文献[19]则采用物流成本比例作为指标。上述文献对于指标的选取并没有量化选择,主观分析居多,其主要原因在于全指标数据维数较高,当前的机器学习方法难以把握各属性特征间的映射关系且计算量大。而直方图是高维特征的有效表示方法,结合目标预测的特点,本文通过将高维属性特征的相似性测量问题转换至模式识别中图形特征分类的解决方案,实现时间序列和模式识别的有效结合。
2.1 属性直方图的相似性测量
令某不同时间节点下归一化后的各数据特征向量直方图分布分别为p={(p1,wp1)},…(pm,wpm)},Q={(q1,ωq1),…(qn,ωqn)},分别包含m和n个聚类中心,其中w表示其聚类权重。D=[dij]表示特征向量间的测度矩阵,dij表示向量聚类pi和qj中心间的测度距离,其距离的定义根据所求问题而具体化。Ruber[15]将特征向量比对问题转化为线性规划的运输问题,通过找到双向网络最优路径的选择方案F=[fij],计算两类特征分布的差异程度,fij表示供
给i到需求j的运输量,从而使运输费用最小。
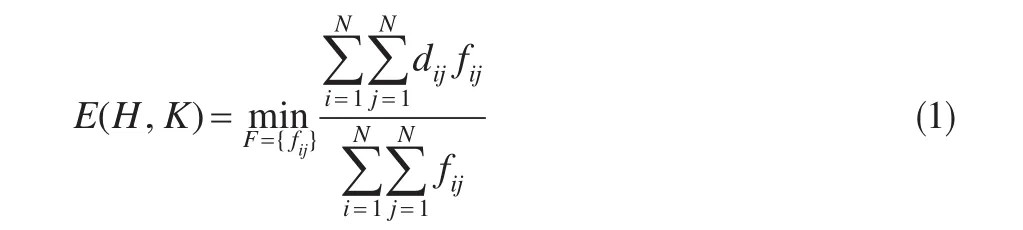
满足以下约束条件:

对于归一化后的多维属性分布,设其分布特征H存在m×n个栅格,栅格坐标集合定义为I={(i,j),i≤i≤m,1≤j≤n},运输流方向表示为J={(i,j,k,l):(i,j)∈I,(k,l)∈I},即从栅格 (i,j)运输至 (k,l),待匹配直方图矩阵P={pij:(i,j)∈I},Q={qij:(i,j
)∈I},且其约束条件
从而属性特征的相似性测量问题转化为线性规划的运输问题:
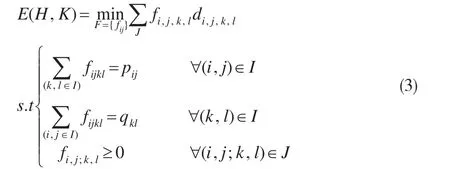
其中的距离可以是任意的距离计算方法,考虑到目标预测的实际情况,本文采用简单的L1距离即:

其模型如图1所示:

图1 经EMD转化后的运输问题模型
2.2 属性直方图的测量优化
定义集合:Js={(i,j,k,l):(i,j,k,l)∈I,di,k,l=1}表示直方图分布中相邻属性栅格运输流,且相邻距离为1。通过将直方图中两点间的测度距离L1分解为相邻点的累积和,非相邻属性栅格间距离转化相邻属性栅格距离之和,即进一步减少变量数目和约束条件,这样任何非相邻属性栅格距离fi;k,l可以被相邻栅格距离路径 [(i,j),(i,j+1),…,(i,l),(i+1,l),…,(k,l)]所取代[20]。
最终得优化后的EMD模型:

相对于原算法,其变量数量减少至4N,约束条件也减少了一半,线性规划的运算复杂度和空间复杂度就得到了明显的下降。
2.3 构建多维数据特征的相似性序列
设不同时间下的属性直方图分布为H(i≤n),计算两两时间节点相似性距离:
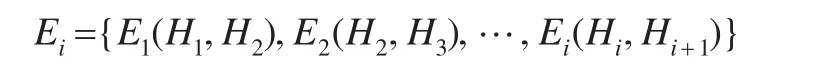
其中i=1,2,…,n-1。令E0=0,对上述序列累加求和:
从而将高维数据约简为多维属性特征的相似性序列:
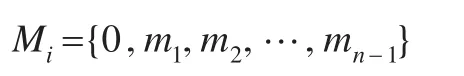
2.4 利用支持向量回归机对该序列与目标向量拟合预测
拟合预测算法流程如图2所示。

图2 算法流程图
3 实验结果与分析
为了验证上述算法的有效性,本文以区域物流需求预测为研究对象,以文献[21]构建的指标体系作为目标预测的属性变量,以广西、广东两个地区数据集为例,考虑到数据的完整性,最终构成横轴25个属性变量,纵轴为1990—2012年的时间序列二维面板数据。采用平方和误差(SSE)、平均绝对误差(MAE)、均方误差(MSE)、平均绝对百分比误差(MAPE)、均方百分比误差(MSPE)作为误差检验指标。
该算法主要将属性数据归一化为直方图分布,将预测问题转化为模式识别的差异性分类问题,测量两两年份的相似性差异,构建新的差异性序列代替原高维数据特征,最后利用支持向量回归机对该序列与目标向量拟合预测。
实验一:广西区域物流预测
(1)对该二维面板数据消除量纲归一化,将25个属性指标转换为5*5二维直方图分布。如图3所示。
(2)利用上文的方法横向测量时间纵轴两两年份属性分布的相似性差异,如表1所示。
(3)令序列首期基数为0,对相似度测量值累加减运算,构建相似性序列,如表2所示。

图3 属性特征的直方图分布

表1 不同时间节点间的相似性距离
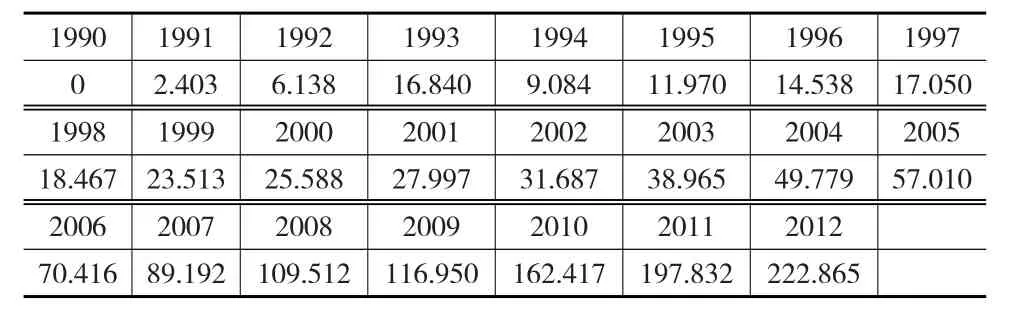
表2 相似性序列
(4)利用相似性序列对货运量进行拟合预测。
为了验证该预测算法的有效性,本文分别与传统预测算法(灰色模型)、人工智能学习算法(广义回归神经网络、原始支持向量回归机和PCA降维的支持向量回归机)做了比较。如下页表3和表4所示。
实验二:广东区域物流预测
同理,在广东地区数据集上进行实验,结果如下页表5所示:
实验三:不同距离函数的拟合精度
本文分别采取MinkowskiDistance、Euclidean Distance、χ2Distance、Kullback-Leibler Divergence构建相似性序列,同样采用SVR在两广地区数据集中进行拟合预测,结果如
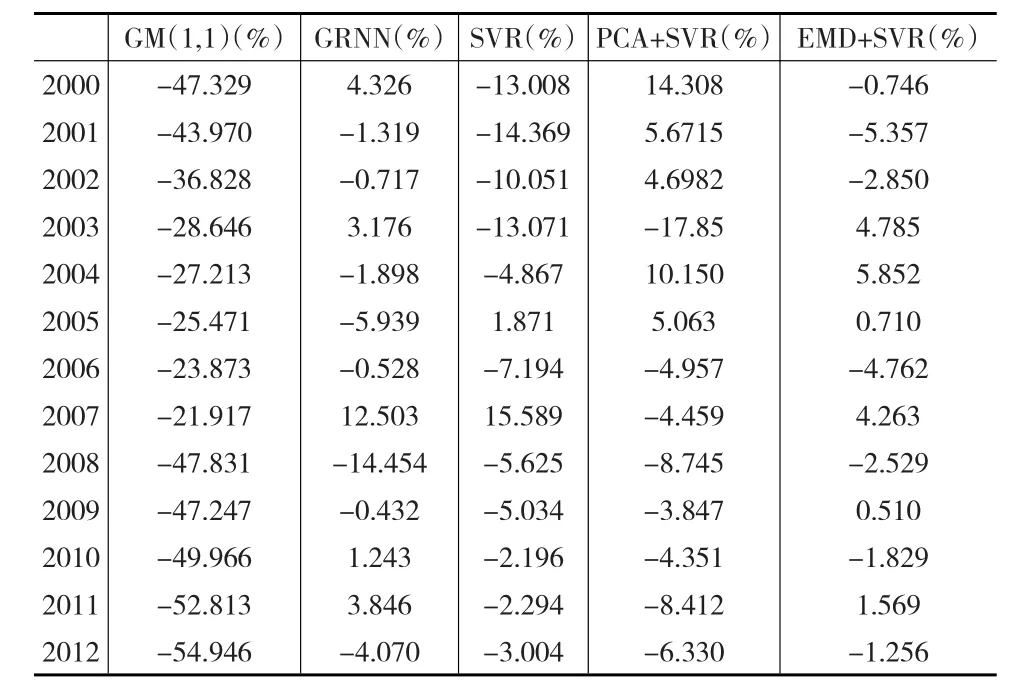
表3 区域物流预测精度比较

表4 预测评价
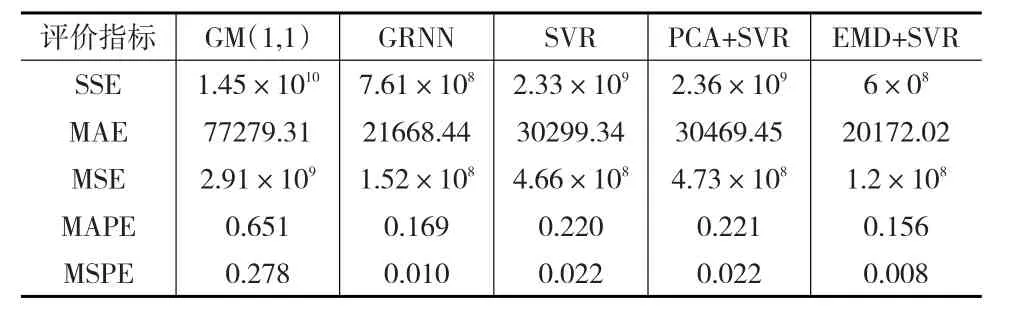
表5 广东区域物流评价表
表6所示:

表6 不同距离函数的预测评价
通过上述实验数据可以看出基于相似性测量的预测方法所提取的新的时间序列特征表达意义强,较之原始SVR和主成分分析的SVR,在保证精度的情况下,能够有效降低大规模样本数据的计算维度,避免“维数灾难”和“过学习”的问题,预测精度较高。而传统的灰色模型则对数据的平稳性要求较高,实验中数据的突然变化,对于灰度模型影响较大,可见灰色模型对于数据波动的适应性较差。而人工智能算法中的GRNN神经网络较之BP神经网络的逼近能力、学习速度等方面有着较强优势,但是该类学习算法神经元个数的确定,参数的选择优化一直是其使用的难点,且其预测精度也是有限的。在与传统的距离函数构建的相似性序列比对中,也证明了该算法对于全局指标特征的把握能力和良好的预测效果。
4 结束语
本文以与目标预测值强关联的多维数据特征为基础,将目标预测问题通过属性特征直方图分布的形式转化为模式识别的相似性测量问题,与传统方法相比,该算法不再从预测模型的层面上进行改进,而是回归至数据源本身特征,通过数据特征的相似性测量,有效结合时间序列和模式识别方法的优势。优化后的测量方法能够更好地从全局的角度比对直方图特征差异,兼顾了全数据特征与目标变量之间的映射关系,使得在大数据环境下全数据特征的运算成为了可能,避免了特征选择主观性对于目标预测的偏差,大量试验证明了该方法的有效性,为目标预测问题提供一种新的思路。
参考文献:
[1] 常飞,乔欣,张申,许华栋.基于MFCC特征提取的故障预测与评价方法[J].计算机应用研究,2015,32(6).
[2] 钟炜,宋洋.基于FCM的小波神经网络模型在径流预测中的应用[J].系统工程学报,2009,(1).
[3] 孙轶轩,邵春福,计寻,朱亮.基于ARIMA与信息粒化SVR组合模型的交通事故时序预测[J].清华大学学报:自然科学版,2014,(3).
[4] 韩敏,许美玲,王新迎.多元时间序列的子空间回声状态网络预测模型[J].计算机学报,2014,(11).
[5] 章登,欧阳黜霏,吴文李.针对时间序列多步预测的聚类隐马尔科夫模型[J].电子学报,2014,(12).
[6] 郑华.基于时间序列相似性匹配算法的地震预测研究[J].四川地震,2010,26(2).
[7] 吴红花,刘国华,王伟.不确定时间序列的相似性匹配问题[J].计算机研究与发展,2014,(8).
[8] 张建业,潘泉,张鹏等.基于斜率表示的时间序列相似性度量方法[J].模式识别与人工智能,2007,(2).
[9] Vlanhos M H M,Gunopulos D,Keogh E J.Index⁃ing Multi-dimensional Time-series With Sup⁃ports of Rmultiple Distance Measures[C].Pro⁃ceedings of the In:Procof the 9th ACM SIGKDD,Washington,F,2003.
[10] 吴虎胜,张凤鸣,钟斌.基于二维奇异值分解的多元时间序列相似匹配方法[J].电子与信息学报,2014,(4).
[11] 李海林,郭崇慧.基于多维形态特征表示的时间序列相似性度量[J].系统工程理论与实践,2011,(31).
[12] Ion A,Peyre G,Haxhimusa Y,et al.Shapematching Using the Geode⁃sic Eccentricity Transform-a study[C].Proceedings of the In:Proc Workshopof the Austrian Association for Pattern Recognition,,F,2007.
[13] Marszalek M,Schmid C.Accurate Object Recognition With Shape Masks[J].International Journal of Computer Vision,2012,97(2).
[14] Rabin J,Peyre G,Cohen L D.Geodesic Shape Retrieval via Optimal Mass Transport[M].Amstedam:Computer Vision-Eccv,2010.
[15] Rubner Y,Tomasi C,Guibas L J.The Earth Mover's Distance as a Metric for Image Retrieval[J].International Journal of Computer Vi⁃sion,2000,40(2).
[16] Haibin L,Okada K.Diffusion Distance for Histogram Comparison[C].proceedings of the Computer Vision and Pattern Recognition,2006 IEEE Computer Society Conference on,F 17-22 June 2006.
[17] Bronstein M M,Bronstein A M.Shape Recognition With Spectral Distances[J].Ieee Transactions on Pattern Analysis and Machine In⁃telligence,2011,33(5).
[18] 刘秉镰.基于价值量的物流需求分析与预测方法研究[J].中国软科学,2004,(5).
[19] 孙有望,周福东.我国宏观物流市场预测与分析方法研究[J].同济大学学报:自然科学版,2005,(1).
[20] Ling H,Okada K.An Efficient Earth Mover's Distance Algorithm for robust Histogram Comparison[J].Ieee Transactions on Pattern Analy⁃sis and Machine Intelligence,2007,29(5).
[21] 李国祥,夏国恩,高荣等.基于属性约简的区域物流需求预测[J].计算机应用与软件,2013,(11).
