基于Multi-GPU平台的大规模图数据处理
2018-03-13张立波武延军
张 珩 张立波 武延军
1(中国科学院软件研究所 北京 100190)2(中国科学院大学 北京 100049)(zhangheng@nfs.iscas.ac.cn)
随着单指令集多数据流(single instruction multiple data, SIMD)并行架构的流行,采用Multi-GPU架构的服务器节点来支持高性能计算已成为趋势热点.这类服务器节点通常由若干Host处理器(CPUs)和多个GPU设备组成,各设备间通过通信总线互联(PCI-E总线或NVLink传输线),如图1所示.这样的架构相比单颗GPU服务器提供了更大规模的协处理器并行硬件环境和内存传输带宽,从而带来更高效的大规模数据聚合处理能力.
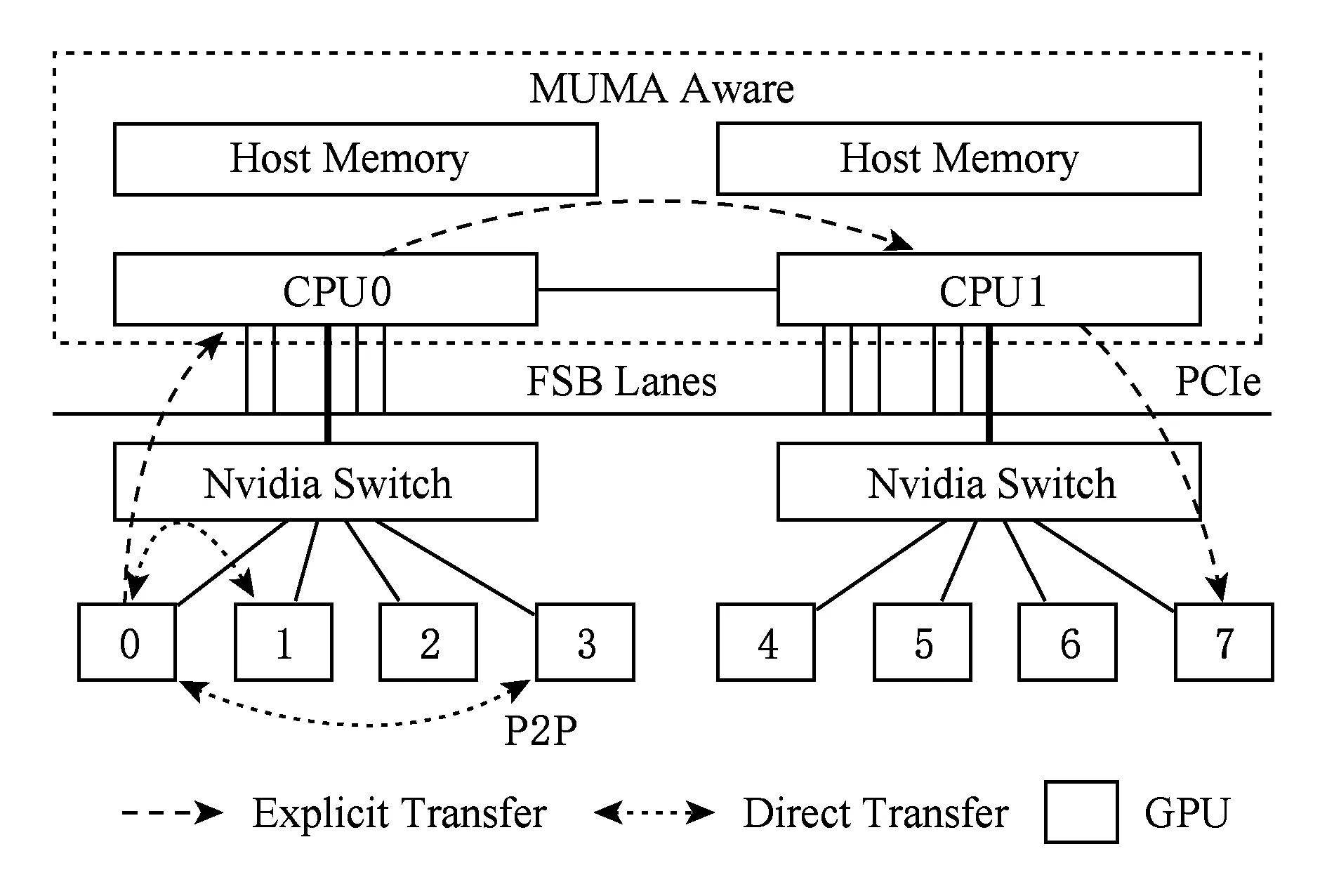
Fig. 1 The architecture of Multi-GPU platforms图1 Multi-GPU平台的硬件架构
近年来采用GPU服务器平台对大规模图数据进行处理已经日益成为研究热点[1-2],提出了大量的算法优化和在GPU服务器上的图数据处理系统设计,例如CuSha[3],MapGraph[4]和GunRock[5]等.根据所能支持图数据的处理规模,我们将这类GPU图数据处理系统分为了2个通用的类别:GPU设备访存图处理和外存(out-of-core)图数据处理方案.其中,访存内图处理系统类研究工作集中于GPU线程的并行优化策略来提升存储在设备访存内的不规则的图数据结构的访问和计算性能,最大限度地挖掘GPU线程组的并行处理能力.另外,其他研究提出了在单节点上支持基于外存IO的大规模图数据的处理,这类系统突破了GPU访存大小的限制,通过利用图数据切分策略,迭代式加载至GPU设备访存,完成处理后利用主存和持久化存储设备进行全局同步.GraphReduce[6]是第1个提出基于外存IO进行GPU下大规模图数据计算的系统,其对图数据采用混合型的稀疏矩阵压缩CSR(compressed sparse row)和CSC(compressed sparse column)表示方式以降低迭代过程中随机访问开销,进而对原图数据进行均衡切分后,逐个加载分块至设备内存处理.
然而,GraphReduce只支持单个GPU下的并行处理,这类基于外存IO的GPU下图数据处理的系统在扩展到Multi-GPU平台下仍然存在着挑战:1)如何进行均衡的图数据切分,以适用于Multi-GPU下各层级的内存存储;2)在多个GPU和CPU之间进行协同处理过程中,如何有效地利用局限的传输带宽(PCI-E)进行数据传输.
为了解决上述挑战,本文对基于Multi-GPU平台下的外存图数据并行处理系统提出了优化策略,在以存储顺序IO优化前提下,将图数据的属性数据集合(节点状态数据集,点边权重数据集)先缓存于各GPU的设备访存,后对图分块逐个顺序传输至各GPU处理后同步.本文进一步设计并实现了GFlow,在Multi-GPU平台上支持高效、可扩展的大规模图数据处理系统.本文在GFlow系统中主要提出了2点优化策略:适用于Multi-GPU下的图数据Grid切分策略和双层滑动窗口算法.具体地,GFlow在对大规模图数据进行Grid切分后,逐层从磁盘存储加载至GPU设备内存,并针对同步过程中的随机内存访问开销设计了Ring Buffer数据结构用以提升对各GPU并行处理过程所生成的Update消息数据集聚合传输和节点更新.
本文主要的创新和贡献点有如下3点:
1) 提出了一种适用于Multi-GPU平台图数据Grid切分策略,在采用最大化存储顺序IO的Streaming图切分的基础上,根据主存、各GPU设备存储的资源大小构建列分块(strip-shard)和格分块(grid-shard),优化PCI-E的IO传输的顺序数据块传输和各GPU之间的负载均衡;
2) 设计了双层滑动窗口并行化数据传输和处理策略(2-level streaming window),动态地加载数据分块从SSD存储至GPU设备内存,并顺序化聚合并应用处理过程中各GPU所生成的Updates;
3) 通过在4个图基准算法和9个真实图数据集上的实验验证,GFlow性能表现对比CPU下的GraphChi和X-Stream分别提升25.6X和20.3X,对比GPU下的GraphReduce单个GPU下提升1.3~2.5X,且可扩展性达到3.8~5.8X(6个GPU配置).
1 相关工作
随着单指令流多数据流并行架构(SIMD)的流行,利用超大规模核处理器GPU处理单元(graphical processing unit)的高性能节点进行大规模图数据的处理越来越为研究者们所关注.现实的图数据具有规模巨大、增量迅速且数据表征差异多样化的特点,在利用GPU对大规模图数据进行处理过程中,需要考虑到各方面的并行计算因素,如图结构数据的切分与遍历策略、图数据异构多线程并发的负载均衡以及图数据的存储和IO方式等.现阶段,这类研究工作主要集中于图数据处理的基本算法与系统类的研究.
在GPU加速的图算法优化中,主流高性能领域的标准测试集Graph500[7]采用广度优先遍历算法(breadth first search, BFS)对高性能计算节点和集群以及并行算法的性能与能耗进行评估,因此利用GPU对BFS算法的高并行加速的研究日益成为热点.其中,You等人[8]提出将自顶向下和自底向上的图遍历访问方法综合考量,根据遍历算法的收敛程度动态选择访问方法,优化GPU线程对异构图数据遍历.Merrill等人[9]提出针对GPU下BFS遍历的核心操作前缀求和(prefix sum)算法进行任务的细粒度化优化,降低多线程的访问冲突,其遍历性能达到单NVidia Tesla K40 GPU上33亿条边秒的TEPS访问速度.Hong等人[10]提出了虚拟Warp(GPU的逻辑线程组并行执行单元)为中心编程的思想,对GPU的BFS 等图算法并发执行过程中的负载不均衡和逻辑运算单元(arithmetic logic unit, ALU)负载过载问题进行优化.Liu等人[11]根据遍历过程中的活跃节点集Frontier对GPU下的BFS算法提出3点优化:对GPU执行线程流水线化降低多线程竞争、根据点的出度情况调整动态负载来达到并行化负载均衡、GPU下的 BFS 遍历方向优化.本文所设计的GFlow大规模图数据处理方法,主要针对Multi-GPU平台的大规模图数据进行数据传输、并行计算方面优化.GFlow在设计的过程中借鉴了上述的GPU下的算法优化策略,如虚拟Warp线程组调度计算以及图数据遍历动态策略等.
另一方面,现有的大量研究工作开始转向GPU平台下图处理的系统级设计[3-4,12-13],为图算法方便实现提供简化的编程接口API,支持各类图算法的GPU并行执行.在这类系统性的工作中,Medusa系统[12]第1次提出并设计实现了用于GPU平台的图计算简化编程系统,其提出了在CUDAC++编程框架基础上简化图的GPU编程API接口,底层采用BSP(bulk-synchronous parallel)并行模型对GPU的大规模线程并发执行细节隐藏,从而简化GPU下的图算法编程实现.CuSha系统[3]着重对高稀疏性自然图的切分及处理访问方式进行性能提升,在块切分基础上对图数据按照起点-终点索引、节点权重、边权重进行数据分块组织,构建连续窗口图处理达到动态的调整各处理间隔的大小.Gunrock[5]进一步优化了GPU下的高性能图处理接口,重构图处理原语,提供Advance-Filter-Computation三个操作来分别进行节点访问、过滤和计算的处理.为了在有限的单GPU访存空间上支持更大规模的图数据的处理,GraphReduce[6]第1次提出单GPU节点的外存下的图数据处理,在规模无法存储于GPU访存的大图数据采用固定大小切块切分,并在GPU设备访存与Host内存之间设计优化了异步传输与迭代计算.
本文工作在GraphReduce基础上进行设计和实现GFlow图数据处理系统,提升可扩展性利用Multi-GPU平台以支持基于外存IO的大规模图数据的并行计算模型,主要在2个方面设计了优化策略:图数据的切分分块以及各GPU在并行计算过程中的数据传输和结果集计算同步机制.相对比上述相关的研究系统,本文所设计实现的GFlow系统充分利用Multi-GPU节点的大规模并行环境的计算资源进行算法并行处理,在有限带宽PCI-E总线资源下降低图数据的同步和传输开销.同时,GFlow沿用了传统的GAS(Gather-Apply-Scatter)[14]的图数据并行编程模型,并提供大规模图数据的切分、存储、传输和计算,支持各类图计算的算法的GPU实现.
2 基于GPU下外存I/O的图数据并行处理
在本节中,我们主要介绍针对面向单GPU下的图结构上的方法应用.首先,对图数据在GPU下迭代处理过程中的表现形式进行了描述,主要分为3个数组部分进行存储,包括CSRCSC稀疏矩阵压缩结构格式、应用定义数据以及节点状态数据.其次,本文工作对单GPU下基于外存IO优化的大规模图数据计算系统的执行流程进行了简要描述.通过沿用传统的以点为中心的并行计算GAS(gather-apply-scatter)模型[14],在对原始图数据切块后顺序逐一载入GPU设备访存处理后,进行节点更新结果集同步.
2.1 图数据在GPU环境下的数据结构形式
考虑到GPU设备访存的资源有限性,基于GPU的大规模图数据处理研究工作沿用以CSR或CSC矩阵压缩的表现形式对大规模图数据进行格式化,降低了稀疏性图数据的存储开销.在图数据进行迭代化并行处理的过程中,主要分为如图2所示的3种类型数据:
1) 图数据的结构数据(topology data, TD).以CSR压缩的格式数据由各点的出边的索引数组(OutEdgeIdxs)和出边的值数据(OutEdgeIndex)构成.
2) 应用数据(application data, AD).存储图的各节点的当前值的数组,根据不同的算法和应用对数据定义.
3) 状态数据(state data, SD).标记了图中各节点在当前迭代轮的状态(0或1);标记为1表示节点状态活跃参与下一个迭代轮计算,标记为0则不参与计算.状态位的标记能够有效降低图数据并行化处理的无用计算.
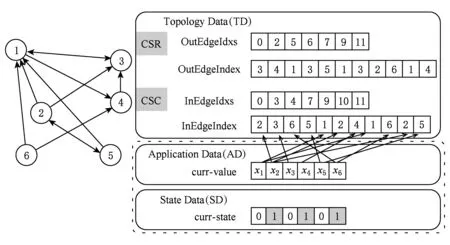
Fig. 2 Graph representation of CSRCSC based compression图2 以CSRCSC格式为例的图数据表现形式
2.2 单GPU外存计算的图处理系统执行流程
在第1节中,现有的GPU下的大规模图数据处理系统主要分为2类:访存内(in-memory)计算系统和外存(out-of-core)计算系统.随着图数据规模的增大,基于GPU访存内计算系统的执行受GPU设备访存大小的限制,而导致无法应对更大规模的图数据的并行处理.GraphReduce[6]系统第1次设计并支持了基于外存的单GPU下大规模图数据的并行处理.本文所设计的GFlow沿用GraphReduce的设计原则,进一步优化提出Multi-GPU下的图数据IO优化策略方案.本节对单GPU下支持外存图数据处理的执行流程进行了简要的归纳和总结,如图3所示.通过采用分布式图处理引擎PowerGraph[14]所设计的点为中心的GAS并行处理模型,GPU下外存图数据处理主要分为4个主要处理阶段,包括初始化数据加载、Gather阶段、Apply阶段和Scatter阶段.
1) 第1阶段(初始化数据加载,图3中1a和1b阶段).原始图转换为以CSR和CSC混合表示的图模型,并将边集切分为包含相等边数的分块Shard(入边+出边数量),进一步将各边集分块Shard以及对应的AD、SD数据块加载至主存空间;
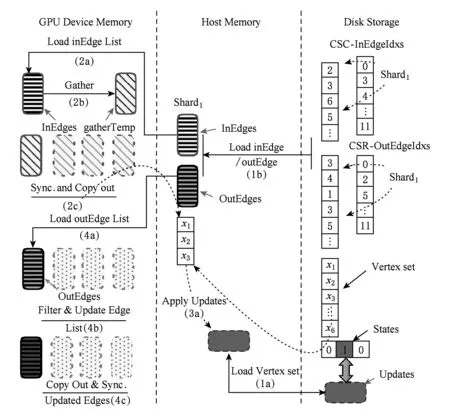
Fig. 3 Execution flow for large graph in single GPU图3 单GPU下大规模图数据处理流程
① https://sparse.tamu.edu/DIMACS10/coAuthorDBLP
② https://sparse.tamu.edu/Williams/webbase-1M
③ https://sparse.tamu.edu/SNAP/roadNet-CA
2) 第2阶段(Gather,图3中2a、2b和2c阶段).逐个将包含in-edge(入边)分块Shard加载至GPU访存后,对当前的对应活跃点集遍历获取对应的节点值,对所加载边集执行用户自定义gather.在对各个in-edge分块处理完毕同步后,获取本地化的gather操作结果更新(节点权值边值)集合;并进一步拷贝更新集合值内存;
3) 第3阶段(Apply,图3中3a阶段).对所聚合的局部updates集合执行apply操作,对磁盘存储的全局updates数组的对应项进行更新并标记相应节点状态位.
4) 第4阶段(Scatter,图3中4a,4b和4c阶段).在逐一拷贝out-edge(出边)分块Shard以及所对应更新的节点值集合至GPU访存后,执行scatter用户自定义函数对边集及其终点状态进行更新.
其中,值得注意的是,在做边集分块Shard的过程中,分块大小的确定以各分块能够完整存储于GPU的设备访存为准.另外,为了避免不必要的memcpy操作和kernel初始化开销,我们采用了对活动点集进行动态记录的策略,即首先调用CUDA指令any()探测在第1阶段计算过程中是否存在活动节点需要传输,然后在warp线程组内和组外逐步规约(binary reduction)来获取活跃节点集合.
3 支持Multi-GPU平台的大规模图数据处理
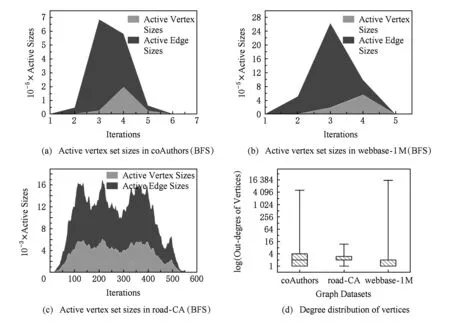
Fig. 4 Different representations for three graphs图4 3个图数据(coAuthor,webbase和road-CA)的不同特征
大规模图数据的类型多样化,包括社交网络数据、路网数据、协作者网络数据以及大量的Internet网页链接数据等.这类现实中的复杂网络所构建的图数据类型特征各不相同,我们采用实验中的数据对这类图数据进行了特征分析.其中coAuthor①为论文合作者网络,webbase②为网页链接数据,road-CA③为路网数据.从图4(a)~(c)中,各图数据在进行BFS广度优先遍历过程中各轮迭代过程中参与计算的活跃点集数量不尽相同,同时迭代轮次数差距也较大,如coAuthors和webbase在5~6轮迭代之后完成,而road-CA路网半径较大导致需要至少520轮迭代计算.进一步,我们对3个图的各节点出度情况进行统计,从图4(d)中可见,road-CA路网数据相比来看出度更为集中,大量节点的出度在2~4之间,这也反映了道路交通网络的节点度均匀特征.
在构建图数据处理系统过程中,为了支持多样化的图数据类型和各类图数据算法,在设计上需要着重考虑如下2个方面的因素:大规模图数据的均匀切分和图数据的并行处理.首先,为了Multi-GPU环境下的各设备的计算负载均衡,对多样化大规模图数据的均衡切分能够有效降低图数据并行处理过程中straggler开销问题;其次,在并行处理方面,GPU的外存数据传输开销往往占用大量运行时时间,因此在并行化的数据传输和计算过程中,采取重叠式轮转调度和异步式的数据传输能够大幅降低外存数据的传输与同步开销.
本节对GFlow支持Multi-GPU平台的大规模图数据的处理机制进行了详细描述,主要在图数据集均衡切分和基于窗口的异步并行处理2个方面提出了优化与改进.
3.1 GFlow系统设计思想和执行流程
在GPU服务器节点上,GPU的各层级内存由用于Warp单元间和线程块间的数据通信的共享内存(shared memory,L1 cache)和用于所有SMX(streaming multiprocessor)的全局内存(global memory)以及少量的L2 Cache缓存构成,而CPU端以主存为主.在进行Multi-GPU平台下的图数据处理系统构建时规划了各层内存的数据结构存储如下所示(以Nvidia GTX 980型号GPU为例):
1) 共享内存(shard memory).48 KB,用于存储各节点的状态数组和各SMX本地节点分块集合的应用执行结果集;
2) 全局内存(global memory).4 GB,用于存储分块图结构数据集(Shard),包括点、边数据,以及部分用作缓存(Buffer)存储临时结果集合.
3) Host主存(main memory).64 GB,用于存储部分图结构分块数据集合,以及对应的AD应用数据和SD节点状态数据集.
GFlow系统沿用GAS并行模型设计的思路,提供用户GatherApplyScatter接口函数以实现并行图算法.算法1~3分别给出了PageRank算法采用GatherApplyScatter函数的各自实现,其中,预定义边数据结构体ED(PageRank的边无权值)和点数据结构体VD包含节点权值rank和出边数值numOutEdges.GFlow系统总体的流程分为4个阶段:输入(Input)、核心执行(Core)、结果集合并(Merge)以及输出(Output).图5给出了GFlow的整体执行流程示意图.
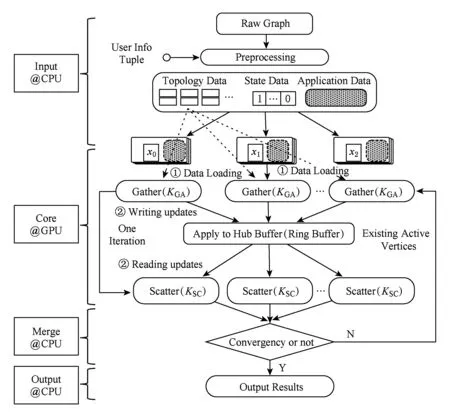
Fig. 5 Execution flow in GFlow of multi-GPU图5 Multi-GPU下GFlow的执行流程示意图
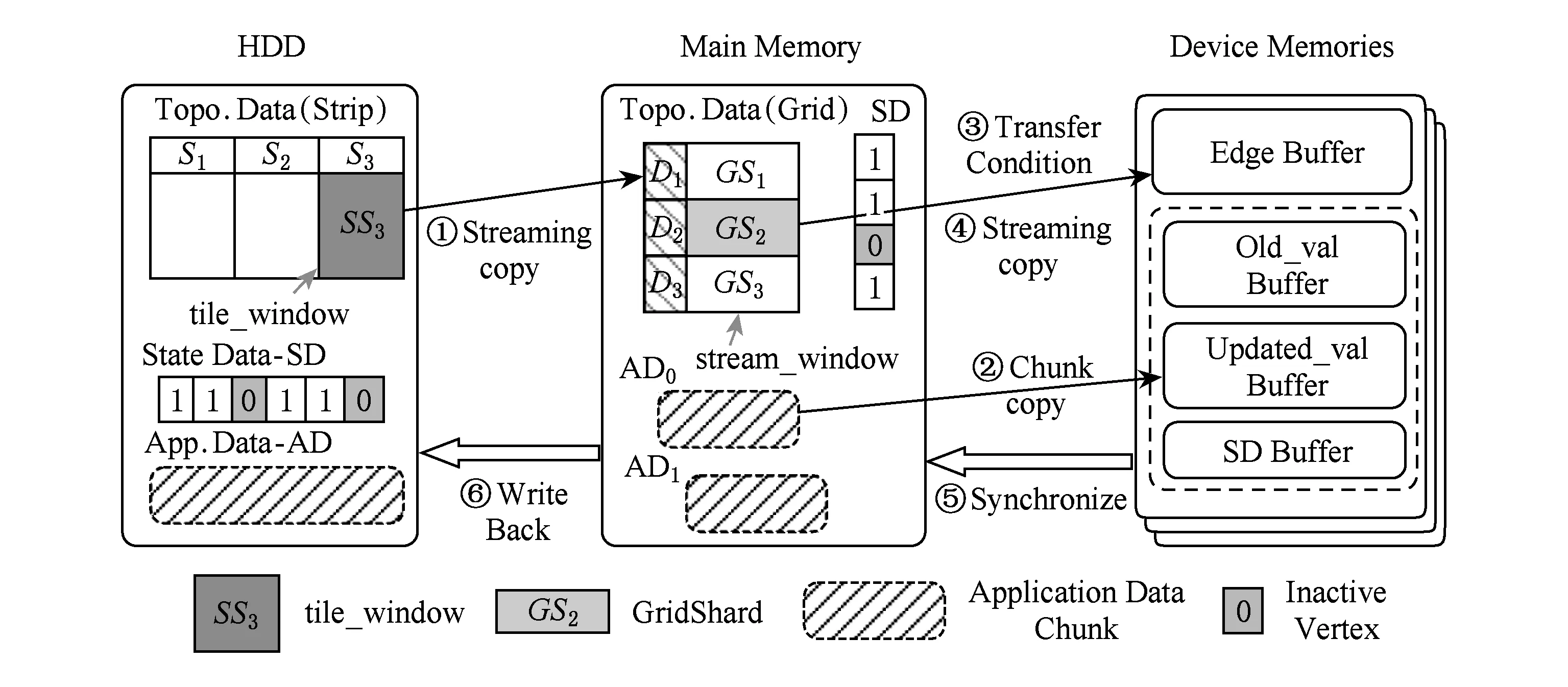
为了解决大规模图数据集无法完整存储于GPU设备内存的问题,本文采用了一种基于Grid切分策略对2.2节所提及的图分块(Shard)进行优化改进,主要设计目的在于以最大化PCI-E的IO传输的顺序数据块传输,优化各GPU之间的负载均衡同时保证了图数据的预处理的高效.进一步,将各分块对应的节点状态位数组信息SD和应用数据AD共同进行封装,以整体数据块形式来进行数据传输拷贝(memcpy).所设计的图数据Grid切分策略详细流程如3.2节所述.
算法1. GFlow中PageRank的Gather函数KGA.
输入:边的起点数据Du、终点数据Dv、边数据D(u,v);
输出:边的终点数据的累加更新.

算法2. GFlow中PageRank的Apply函数KAP.
输入:当前节点数据Dv、累加聚合结果gather-Result;
输出:更新后Dv的权值.
①α=0.85f; /*定义阻尼系数*/
②new_pr=1-α+α×gatherResult;
③ 更新Dv的权值rank=new_pr.
算法3. GFlow中PageRank的Scatter函数KSC.
输入:节点更新数据Dv、边数据D(u,v);
输出:节点Dv的活跃状态.
①THRESHOLD=0.01f;
/*定义节点活跃状态阈值*/
② 计算Dv当前权值与原权值的绝对差值Δrank;
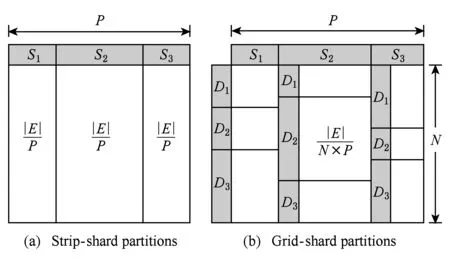
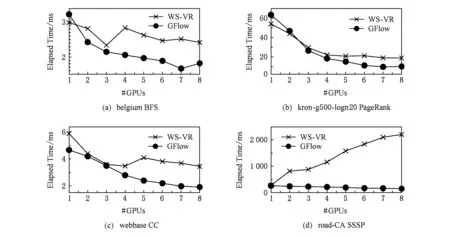
③ IF Δrank ④ return false; ⑤ ELSE ⑥ return true. 在CPU进行预处理过程之前,各个GPU设备各自分配初始化内存Buffer用于保存TD Buffer、SD Buffer、当前和生成的AD Buffer.接收Shard块传输之后,各GPU设备并行化执行GAS并行计算模型.其中,KGA函数和KSC函数分别为用户自定义实现的GPU的Kernel函数Gather和Scatter.在Gather执行完成后,GFlow分配全局的Hub Buffer保存各GPU节点生成的更新集合(updates),在计算完成对应的节点或边的更新权值之后组装成数据块分配至对应的GPU设备.此过程中,为了降低数据IO传输和更新的同步开销,GFlow着重对2个阶段的数据传输进行了优化,如图5所示的数据加载阶段(data loading)和各GPU之间并行执行所生成的Updates的读写操作(writingreading updates).GFlow提出并设计了双层数据读写滑动窗口对数据传输和并行计算阶段进行阶段,具体的实现细节介绍见3.3节. 在各GPU Kernel执行完毕之后,根据所生成的Updates集合对图数据的节点SD状态集标记,在Host Memory中更新合并,整体流程的迭代计算的收敛判断是否还存在活跃点集或者达到指定的迭代次数. 为了满足Multi-GPU下的各种类型不同的图数据的处理需求,GFlow提出并设计了一种适配多层级内存资源的Grid切分策略.现有CPU下外存图切分策略的研究[15-18]利用磁盘的顺序读取的高效性原理,在引入一定图切分的预处理开销下采取更为均衡和高效的图数据顺序化分块存储.GFlow借鉴其中Grid切分的思想[19],在对设备的内存层级资源探测后,构建适用于各层级内存存储的数据结构.具体地,GFlow构建了2层数据分块:列分块(strip-shard)和格分块(grid-shard). Fig. 6 Balanced grid-based graph partition in GFlow图6 GFlow的均衡Grid图切分 1) 列分块.存储于host memory大小,采用Streaming切分策略顺序读取所有节点的出边集合,按照各节点的ID范围Sn来分配,切分原则为各strip-shard的范围S内的边集大小相当. 2) 格分块.用于GPU的设备内存计算,切分准则采用各个grid-shard所包含的边个数相当.在对strip-shard进行二次切分为多个grid-shard,在综合考虑各个节点的活跃状态,各grid-shard在各迭代轮之间进行合理地调整,以对各GPU的负载进行均衡分布. 具体地,对边集中的各条边分别按照其起点和终点的范围进行组织,这样能够在引入一定预处理开销(O(|E|))的前提下获取合理负载均衡的分块.GFlow设计的切分算法在顺序化磁盘读取边之后即可将各边分配切分完成,因此其相对比其他外存系统(GraphReduce)能够大幅度降低引入的预处理开销.我们对基于Grid的图分块视图采用了CSRCSC格式的节点的2个边索引数组in-EdgeIdxs和out-EdgeIdxs进行图数据的切分策略实现.根据各图的CSR存储,GFlow通过out-EdgeIdxs数组获取各节点的度数组(d1,d2,…,dn).进而通过获取节点上host memory,share memory和global memory的资源大小(分别标记为Mh,Ms,Mg),GFlow根据各节点的ID(i)和节点出度di来进行strip-shard和grid-shard的切分.GFlow在满足各切分块的对应AD和SD数据和各grid-shard分块的边集能够存储入全局内存中,没有限制切分块的数量.进一步,我们也采用了更为直接的策略对切分块的数量进行了定义:给定GPU设备数量为N,主存、单个设备全局内存的大小分别为Mh,Mg,以及单个节点、边的应用和状态数据的大小均为U、节点ID大小B和点集和边集数量|V|,|E|,则所切分的节点区间S的个数P为满足strip-shard节点区间和对应grid-shard边集合的存储条件的最小整数中的较大者: 进一步,为了降低各shard内节点的索引查询的开销,我们对各点集范围S内的节点采用连续存储,只保存了第1个节点的偏移量(offset),将节点的状态和属性数据进行连续存储.这样有效地利用了CSRCSC存储格式提升空间利用率. 不同于传统的2-D的图切分策略[19-20],GFlow适用于GPU节点多层级内存存储,能够最大限度提高各层级内存的存储利用率和执行效率.另外,图7给出了grid切分后顺序读写过程.其中,在对同一strip-shard内的grid-shard执行过程中能够对内部各分块的起点范围内的节点集Si的各节点的状态和权值复用,而不需要频繁对节点子集在内存缓存和磁盘间的换入换出,降低了不必要的数据读写开销. Fig. 8 Experimental analysis in data movement strategies supported in Multi-GPU platform图8 Multi-GPU下数据传输策略分析 在Multi-GPU平台下,数据的传输在Host和各GPU之间可以通过H2D,D2H的CUDA接口定义进行数据拷贝(memcpy);而GPU与GPU设备之间的数据的交换和传输的方式能够通过显性传输定义(explicit transfer)和直接传输(GPUDirect)[21-23].为了进一步分析外存图计算系统在Multi-GPU平台下能够高效地进行数据传输,我们对CUDA编程接口的2个技术进行分析:1) 采用cudaMemcpy接口和H2DD2H方式的显性数据传输定义;2)由GPU硬件支持的统一虚拟地址技术(unified virtual addressing, UVA)所提供的GPUDirect直接数据传输.图8中显示采用显性数据传输定义接口能够先比UVA支持的GPUDirect策略能够提升5~6倍的数据传输带宽,同时Pinned分配的块内存传输相比页式内存更为高效.尽管UVA特性能够对GPU之间的数据传输的细节隐藏,但是其由于支持直接内存地址传输带来大量数据一致性访问所需加锁的开销.因此,我们在设计GFlow的数据传输策略时,尽量考虑采用Pinned后内存数据块的显性数据传输策略,这样也能在数据预取和GPU合并内存数据块并行处理方面取得性能优势. 在数据传输和计算执行过程中,GFlow将grid-shard数据块与相对应的属性数据(AD和SD)进行合并为结构化文件块,通过PCI-E总线分配至各GPU设备内存.考虑到PCI-E数据传输效率远低于GPU全局内存读写效率,因此本文提出并设计了基于顺序块IO的异步双层滑动传输和计算窗口(2-level streaming windows),主要对GFlow执行过程中的2个方面的执行效率如图5所示的数据加载阶段(data loading)和各GPU之间并行执行所生成的中间结果集的读写操作(writingreading updates)阶段优化设计. 首先,在①数据加载(data loading)阶段,为了对磁盘存储中的数据块组织,我们构建了tile-window对strip-shard进行管理.每一个tile-window的大小由Host主存大小决定,通常我们设定内存阈值δ来对总体主存的使用率进行设置(默认δ=0.8),因此在tile-window滑动数据加载和执行过程中,GFlow按照Z折线顺序化(zigzag order)逐列读取每个strip-shard. 其次,GFlow在主存中构建stream-window的第2层文件读写窗口对strip-shard内的Grid结构进行分块索引获取.stream-window窗口主要对grid-shard和对应的属性数据分块加载到GPU设备和管理每轮迭代计算过程各GPU中的中间结果集(on-the-fly).具体地,stream-window的窗口大小由多个grid-shard组成,各GPU内设备总内存所决定,并根据各grid-shard的节点状态数组(SD)调整所含大小边集.进一步,GFlow以stream-window为单位对各GPU所生成的本地更新值(AD)存储并进行同步至Host内存. 最后,在②中间结果集(updates)的读写操作阶段,各GPU并行地执行生成updates的分配和读写,考虑到各GPU所生成的updates消息的稀疏性,GFlow采用Hub Buffer机制来对各update消息组进行缓存和同步.Hub Buffer中,update的消息数量相对巨大(O(|E|))且各GPU生成的每个部分在拷贝至Hub Buffer的数量大小不尽相同(如图4所示活跃点集所决定).我们采用了一种固定大小、静态分配的数据结构进行Hub Buffer的构建,即Ring Buffer.Ring Buffer数据结构能够有效避免动态内存分配的开销并为在处理单个stream-window中数据块所生成的update消息提供高效的索引结构.具体地,Ring Buffer由一个大小为η的索引环数组(index ring array)和索引所指向的数据块数组(block array)组成,η取决于stream-windows中grid-shard数量.索引环数组的每个项由3个指针组成,分别指向stream-window中的grid-shard以及其所对应的保存在数据块数组(block array)中的AD和生成的update消息集合.每个数据块数组(block array)采用固定大小页对齐的文件块组成(默认64 MB),一旦一个block填满即可分配新的block.采用Ring Buffer,数据通过PCI-E链路传输能够连续传输,大幅度提升了所生成的update的读写传递效率. 我们对本文策略在GPU环境下进行实现,使用Nvidia GPU的CUDA CC++环境进行算法实现,在实现过程中利用CUDA Stream Object特性对数据从Host到Device之间的传输和Kernel Function的执行流程上进行优化,尽量降低了数据传输所带来的开销,如图9所示流程.进一步,GPU内线程组(warp)的各线程根据各节点的状态进行执行,一旦SD获取的vid对应的状态为inactive,该线程则不需要进行处理,继续获取SD中的active的节点进行下一步处理,从而有效降低了GPU的空闲率.通过对GPU的优化实现,本文所实现的方法极大提高了大规模图数据的处理性能和高并发的可扩展性,能够支持大规模图结构数据集的处理. Fig. 9 Asynchronized data movement and processing phases in GFlow图9 GFlow的异步读写与并行处理步骤 算法4给出了GFlow的并行化执行流程.GFlow在将子图分块strip-shard的属性数据(点的状态数据SD,点边权重数据AD)缓存于各GPU设备后,在启动Stream滑动窗口进行图的拓扑结构化数据(点边集合)至各GPU,进而执行用户Kernel函数,得到迭代计算结果.具体地,初始化的GPU设备缓冲区OVBuf,UVBuf,SDBuf分别保存原节点权值、更新节点权值以及节点状态.tile_window载入strip-shard至主存中,并对标记为未执行的子图块初始化权值和状态集合,构建点与分块索引v2sMap和s2vMap(行④~⑩).进而stream_window读取N个grid-shard载入各GPU访存,执行KGA,KAP,KSC对边集处理得到节点的权值聚合后更新写入UVBuf, 状态写入SDBuf(行~).最后对各GPU设备的缓存导出,并同步更新各节点的最终应用权值和状态值. 在该执行过程中,我们采用了CTA(coopera-tive thread array)的线程组管理(Modern GPU函数库提供)[10,21].通过借鉴Virtual Warp[10]所设计的单个warp,在加载完成grid-shard后,我们将利用Share Memory缓存对应的SD数据,单个warp中的各线程对单个节点所有出边进行同时处理.具体地,在对warp和内部线程的offset进行计算后,在遍历到需要处理的节点时即分配warp对该节点的出边进行线程处理,此外对各节点的聚合更新加入原子性操作(AtomicAdd),各线程处理完毕后采用__threadfence_block()对同一warp内线程同步. 在数据传输过程中,我们利用GPU CUDA Stream Object的特性对数据传输和各GPU之间的计算的重叠以提高并行效率的细节实现.该特性提供了一个GPU的操作队列,使用Stream Object实现了任务级的并行,CUDA的运行时库提供GPU在执行Kernel函数的同时,在Host Memory和Device Memory之间交换数据.在创建若干个Stream的对象管理GPU1:N的计算和Shard的传输后,传入各Stream对象至调用Kernel函数和cudaMemcpyAsync.Stream根据程序的任务执行情况提供运行时优化,来维护该GPU的操作队列的先后顺序. 算法4. GFlow异步Multi-GPU并行处理主流程. 输入:图数据G=(V,E);KGA,KSC,KAP分别表示用户自定义的Gather,Scatter和Apply函数. ① 为设备GPU1:N全局内存中device memory中分别分配EDBuf,OVBuf,UVBuf,SDBuf; ② 调用函数cudaMemcpyFromSymbol转换KGA,KSC,KAP三个Kernel函数标记; ③ while active vertices exist do ④ fortile_window=next strip-shard IDi fromG ⑤ iftile_window标记为已处理 then ⑥ 根据起点状态集合SDi过滤edges; ⑦ else ⑧ 获取起点范围Si权值ADi、状态集合SDi; ⑨ 起点状态集合SDi过滤edges; ⑩ end if 子图; UVBuf; GPUj; UVBuf; stream_window; 在本节中,我们使用本文构建的基于Multi-GPU平台的大规模图数据处理系统GFlow,采用9个公开的现实数据集(如表1所示)进行了对比实验,并且通过性能和GPU上执行情况衡量了算法的高效性和可扩展性. Table 1 The Evaluation Datasets表1 用于实验验证的网络数据集 实验环境采用8块NVIDIA GTX 980 GPU工作站上完成测试,服务器配置2颗10核的Intel Xeon E5-2650 v3的CPU和64 GB大小的GDDR5内存,存储为512 GB PCI-E的SSD硬盘RAID-0配置.考虑到X-Stream和GraphChi采用Direct IO读写数据,在实验过程中,我们对读写过程中采用配置DirectIO避免内存页缓存.操作系统采用Ubuntu 16.04(内核版本v4.4.0-38),配置版本v7.5的CUDA环境.所有的程序编译采用-O3标志,配置目标GPU硬件的streaming多处理器生成器. 为了与现有的大规模图数据处理系统作对比,我们选取了2类系统:1)支持CPU下外存图计算的系统,其中最为广泛应用的GraphChi[15](https:github.comGraphChigraphchi-cpp)和X-Stream[17](https:github.comepfl-labosx-stream);2)支持GPU的大规模图数据计算的系统,此类系统中选择了最新的支持外存图数据计算的单GPU下的系统GraphReduce[6]和支持Multi-GPU下内存内计算的图数据处理系统WS-VR[22]. 另外,在基准算法测试方面,我们采用了广泛认可的PageRank[24]、广度优先遍历算法(BFS)、单源最短路径算法(single source shortest path, SSSP)以及联通子图算法(CC). 下面我们分3个部分进行实验的对比: 1) 对比常用的CPU下的外存计算系统Graph-Chi和X-Stream和支持单GPU下的外存图数据处理系统GraphReduce; 2) 对比支持Multi-GPU平台的图数据处理系统WS-VR; 3) 对GFlow所设计的策略在Multi-GPU下的可扩展性进行验证. 为了对GFlow在Multi-GPU平台上的性能与可扩展性的验证,本文在9个真实的网络数据集(数据集来源http:snap.stanford.edudata)进行测试,其中,coAuthorsDBLP,belgium osm,kron-g500-logn20,amazon,road-CA和webbase-1M用于测试小规模的内存内图数据的计算;其他3个图kron-g500-logn21,uk-2002和twitter用于测试外存存储图数据的计算.这9个数据集合具备各自不同的特征,其中包括有社交网络数据集、路网数据集、商品关联数据集以及网页链接数据集.例如,coAuthorsDBLP,twitter表述了社交网络内的用户的交互行为(协作、相互关注等);webbase-1M,uk-2002为网页链接数据集;amazon代表了亚马逊内的商品之间的关联规则关系;road-CA为路网数据集.在第3节中我们对这些图数据集的多样性特征进行了分析,可以发现各类数据集的点边分布以及稀疏程度都存在特征性的差异.下面我们利用这9个现实网络图数据集对GFlow进行性能的实验对比分析. 我们以twitter图数据在8 GB的Host Memory、4 GB设备访存的服务器上为例对Shard的切分配置参数进行说明如下.twitter图数据(1.4 billion边规模,节点和应用数据大小取16 B)在8 GB可用主存下的分块取区间个数P=10.通过8个GPU设备的分块,总的grid-shard个数为80.设置的tile-window大小为阈值δ×8 GB=6.4 GB,stream-window为global memory总大小32 GB.在加载过程中,twitter图的大小为52.4 GB(CSRCSC格式),对子图分块的索引占用一定的空间,通过tile-window加载一个5.2 GB的strip-shard子图分块到Host Memory后构建各索引(v2sMap和s2vMap)占用,切分为0.65 GB左右的grid-shard. Fig. 10 The comparison results for elapsed time of out-of-core graph parallel-processing systems and GFlow图10 GFlow与其他外存图数据计算系统的性能对比,限制节点内存为8 GB 在本节中,我们首先将GFlow与常用的CPU下的外存计算系统GraphChi和X-Stream的性能进行对比评估,其中GraphChi和X-Stream部署于多核CPU上进行实验,2个系统采用16线程进行对比(X-Stream支持的多线程配比为2n);GraphReduce和本文所设计的GFlow系统部署于GPU平台.为了验证的公平性,GraphReduce只支持单个GPU的执行,我们在对比配置中将GFlow设置为单GPU下的运行状态. 1) 对比X-Stream和GraphChi.如图10所示,GFlow相比GraphChi和X-Stream分别平均能够提升10.3X和3.7X的执行效率.首先,对BFS和SSSP的图遍历算法(图10(a)(d)),GFlow相比其他系统的性能更优,最大的提升来自于uk-2002数据集,相比GraphChi和X-Stream在SSSP算法取得了21X和20.3X的加速比,在BFS算法取得20.8X和7.5X的加速比.同时GFlow在billion边规模的twitter图数据上总体执行时间85.2 s和35.2 s,相对比也能取得2.2~8.0X的执行效率提升.这些性能提升的原因主要来自于2个方面:①GPU的高并行运行时环境提供了GFlow在图数据处理上的性能优势;②通过利用重叠数据传输和计算开销,GFlow充分得到了异步并行计算的性能优势.在PageRank和CC算法上(图10(b)(c)),GFlow仍然能够得到一定的效率优势,例如,在kron-g500-logn21和uk-2002数据集上,GFlow在CC算法上取得了3.8 s和212.2 s执行时间,对比GraphChi和X-Stream分别提升性能2.1~25.6X和4.3~6.5X.值得注意的是在kron-g500-logn21上的PageRank执行效率,GFlow略逊于X-Stream,其中原因在于kron-g500-logn21能够完整地存储于节点的主存中,X-Stream能够充分利用本地性的数据的访问,而GFlow加载到GPU设备内存带来了大量的PCI-E的传输开销,导致性能略有所降低. 2) 对比GraphReduce系统.从图10中结果可以看出,GFlow在单个GPU的执行性能上能够大部分领先于GraphReduce.在大部分的基准测试中,GFlow能够对比GraphReduce得到1.3~2.2X的性能提升,所得到的最大提升性能来自于kron-g500-logn21数据集.这其中的性能优势原因主要来源于GFlow在GPU执行上的性能优化策略,例如,采用Ring Buffer来降低动态Update数据块的读写有效地提升PCI-E的吞吐;利用双层顺序读写窗口以加速数据加载和并行处理的策略等. 进一步,我们也将GFlow与GPU内存计算的图数据系统WS-VR[22]进行了性能对比.WS-VR通过利用GPU内部Warp线程组的调度对GPU在CSR图数据上的执行效率得到了大幅提升,同时提出了节点集约减来提高Multi-GPU上的可扩展性和执行效率.从图11数据所示,我们分析了GFlow与WS-VR在Multi-GPU上的总体执行效率对比(WS-VR配置为Vertex Reduce模式优化).我们可以看出,GFlow的执行性能相对比WS-VR有一定的可对比性,尤其在扩展到采用多个GPU的平台下.例如,在BFS算法belgium图数据上,GFlow执行1.89 ms和1.67 ms在6和7个GPU配置下,相比WS-VR达到1.30~1.51X的加速比.需要注意的是,在多个基准测试算法上(belgium BFS和road-CA SSSP),WS-VR在GPU数量增大的情况下执行的性能反而降低,这也说明多个GPU所带来的数据传输和同步开销增大反而导致整体性能的降低.而GFlow相比来看能够从动态活跃节点集和异步数据传输的策略上得到可扩展性的提升.另外,相比处理这类内存内的数据集,GFlow也能够从所设计的数据结构上得到数据传输的性能提升,从而降低了PCI-E的传输开销和达到多个GPU之间的负载均衡. Fig. 11 Execution time of in-memory system WS-VR and GFlow图11 GFlow与GPU图数据计算系统WS-VR在Multi-GPU上的执行时间对比 最后,我们对GFlow在Multi-GPU上的可扩展性进行了分析.对可扩展性的实验选择了4个图数据集,包括内存内的和外存存储数据集,以及PageRank,BFS和SSSP三个基准测试算法来验证GFlow.从表2中数据可见,GFlow的可扩展性在1个GPU到6个GPU上表现良好.首先,在3个外存存储的图数据集kron-g500-logn21,uk-2002和twitter,随着GPU个数的加速,能够大幅降低整体的执行时间,提升了4.95~5.6X的性能.另外,在2个内存内图数据集webbase,GFlow仍然取得了一定可比性的性能提升,在6个GPU配置下相比提升了3.8X. 综合以上结果可以得到:本文所提出和实现的GFlow系统能够很好地应用于Multi-GPU下的大规模图数据处理应用上.该系统对GPU下图数据的处理得到大幅度的性能提升,尤其在基于外存的大规模图数据的处理上.相对比现有的CPU上的外存计算系统GraphChi和X-Stream,GFlow利用GPU的高性能计算达到了数十倍的性能提升.同时,相对比GPU环境下的GraphReduce和WS-VR,GFlow也能表现出相当的加速比,同时在Multi-GPU平台下得到3.8~5.8X(6个GPU配置)的可扩展性性能提升. Table 2 Speedup of GFlow on Different Graph Applications and Datasets表2 算法在Multi-GPU上的可扩展性性能对比 Note: That speedup ratio is measured onN-GPU vs 1-GPU. 本文主要介绍了一个Multi-GPU平台下高可扩展的大规模图数据处理框架GFlow,支持在有限的计算资源(内存、处理器)下对大规模图数据进行处理.GFlow提出了适用于Multi-GPU平台多层级内存结构的Grid分块存储方式,将大规模图数据转换strip-shard和grid-shard分块,利用顺序数据块的并行读写提升数据传输性能.同时,为了降低数据在PCI-E链路上传输和通信的开销,GFlow设计并实现了双层滑动窗口读写和处理策略以最大化图分块的顺序数据传输,并采用Ring Buffer来合并各GPU所动态生成的Update和节点状态数据从而以聚合的文件块(block)形式提升消息数据的读写能力.从实验验证中可以看出,GFlow能够大幅度提升GPU平台下外存图数据的吞吐和执行性能,并在多个GPU下可扩展性良好. [1]Cheng Xueqi, Jin Xiaolong, Wang Yuanzhuo, et al. Survey on big data system and analytic technology[J]. Journal of Software, 2014, 25(9): 1889-1908 (in Chinese)(程学旗, 靳小龙, 王元卓, 等. 大数据系统和分析技术综述[J].软件学报, 2014, 25(9): 1889-1908) [2]Yu Ge, Gu Yu, Bao Yubin, et al. Large scale graph data processing on cloud computing environments[J]. Chinese Journal of Computers, 2011, 34(10): 1753-1767 (in Chinese)(于戈, 谷峪, 鲍玉斌, 等. 云计算环境下的大规模图数据处理技术[J]. 计算机学报, 2011, 34(10): 1753-1767) [3]Khorasani F, Vora K, Gupta R, et al. Cusha: Vertex-centric graph processing on GPUs[C] //Proc of the 23rd Int Symp on High-Performance Parallel and Distributed Computing. New York: ACM, 2014: 239-252 [4]Fu Z, Personick M, Thompson B. Mapgraph: A high level API for fast development of high performance graph analytics on GPUs[C] //Proc of Workshop on Graph Data Management Experiences and Systems. New York: ACM, 2014: 1-6 [5]Wang Y, Davidson A, Pan Y, et al. Gunrock: A high-performance graph processing library on the GPU[C] //Proc of the 21st ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2016: No.11 [6]Sengupta D, Song S L, Agarwal K, et al. GraphReduce: Processing large-scale graphs on accelerator-based systems[C] //Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2015: No.28 [7]Graph500. The Graph500 list[EB/OL]. [2017-11-03]. http://www.graph500.org/ [8]You Y, Bader D, Dehnavi M M. Designing a heuristic cross-architecture combination for breadth-first search[C]//Proc of the 43rd Int Conf on Parallel Processing (ICPP). Piscataway, NJ: IEEE, 2014: 70-79 [9]Merrill D, Garland M, Grimshaw A. Scalable GPU graph traversal[C] //Proc of the 17th ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2012: 117-128 [10]Hong S, Kim S K, Oguntebi T, et al. Accelerating CUDA graph algorithms at maximum warp [C] //Proc of the 17th ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New York: ACM, 2011: 267-276 [11]Liu H, Huang H H. Enterprise: Breadth-first graph traversal on GPUs[C]//Proc of the Int Conf for High Performance Computing, Networking, Storage and Analysis. New York: ACM, 2015: No.68 [12]Zhong J, He B. Medusa: Simplified graph processing on GPUs[J]. IEEE Trans on Parallel and Distributed Systems, 2014, 25(6): 1543-1552 [13]BenNun T, Sutton M, Pai S, et al. Groute: An asynchronous multi-GPU programming model for irregular computations[C] //Proc of the 22nd ACM SIGPLAN Symp on Principles and Practice of Parallel Programming. New Yor: ACM, 2017: 235-248 [14]Gonzalez J E, Low Y, Gu H, et al. Powergraph: Distributed graph-parallel computation on natural graphs[C] //Proc of the 10th USENIX Symp on Operating Systems Design and Implementation. Berkey, CA: USENIX, 2012: 17-30 [15]Kyrola A, Blelloch G, Guestrin C. Graphchi: Large-scale graph computation on just a PC [C] //Proc of the 10th USENIX Symp on Operating Systems Design and Implementation. Berkeley, CA: USENIX, 2012: 31-46 [16]Cheng J, Liu Q, Li Z, et al. Venus: Vertex-centric streamlined graph computation on a single PC[C] //Proc of the 31st IEEE Int Conf on Data Engineering (ICDE). Piscataway, NJ: IEEE, 2015: 1131-1142 [17]Roy A, Mihailovic I, Zwaenepoel W. X-stream: Edge-centric graph processing using streaming partitions[C] //Proc of the 24th ACM Symp on Operating Systems Principles. New York: ACM, 2013: 472-488 [18]Cheng L, Kotoulas S. Scale-out processing of large RDF datasets[J]. IEEE Trans on Big Data, 2015, 1(4): 138-150 [19]Zhu X, Han W, Chen W. Gridgraph: Large-scale graph processing on a single machine using 2-level hierarchical partitioning[C] //Proc of USENIX Annual Technical Conf. Berkeley, CA: USENIX, 2015: 375-386 [20]Chi Y, Dai G, Wang Y, et al. Nxgraph: An efficient graph processing system on a single machine[C] //Proc of the 32nd IEEE Int Conf on Data Engineering (ICDE). Piscataway, NJ: IEEE, 2016: 409-420 [21]Zhang Jun, He Yanxiang, Shen Fanfan, et al. Two-stage synchronization based thread block compaction scheduling method of GPGPU[J]. Journal of Computer Research and Development, 2016, 53(6): 1173-1185 (in Chinese)(张军, 何炎祥, 沈凡凡, 等. 基于2阶段同步的GPGPU线程块压缩调度方法[J]. 计算机研究与发展, 2016, 53(6): 1173-1185) [22]Khorasani F, Gupta R, Bhuyan L N. Scalable SIMD-efficient graph processing on GPUs[C] //Proc of 2015 Int Conf on Parallel Architecture and Compilation (PACT). Piscataway, NJ: IEEE, 2015: 39-50 [23]Faraji I, Mirsadeghi S H, Afsahi A. Topology-aware GPU selection on multi-GPU nodes[C] //Proc of 2016 IEEE Int Parallel and Distributed Processing Symp Workshops. Piscataway, NJ: IEEE, 2016: 712-720 [24]Page L, Brin S, Motwani R, et al. The PageRank citation ranking: Bringing order to the Web[R]. Stanford, CA: Stanford InfoLab, 19993.2 适用于Multi-GPU下的图数据Grid切分策略
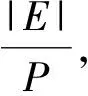
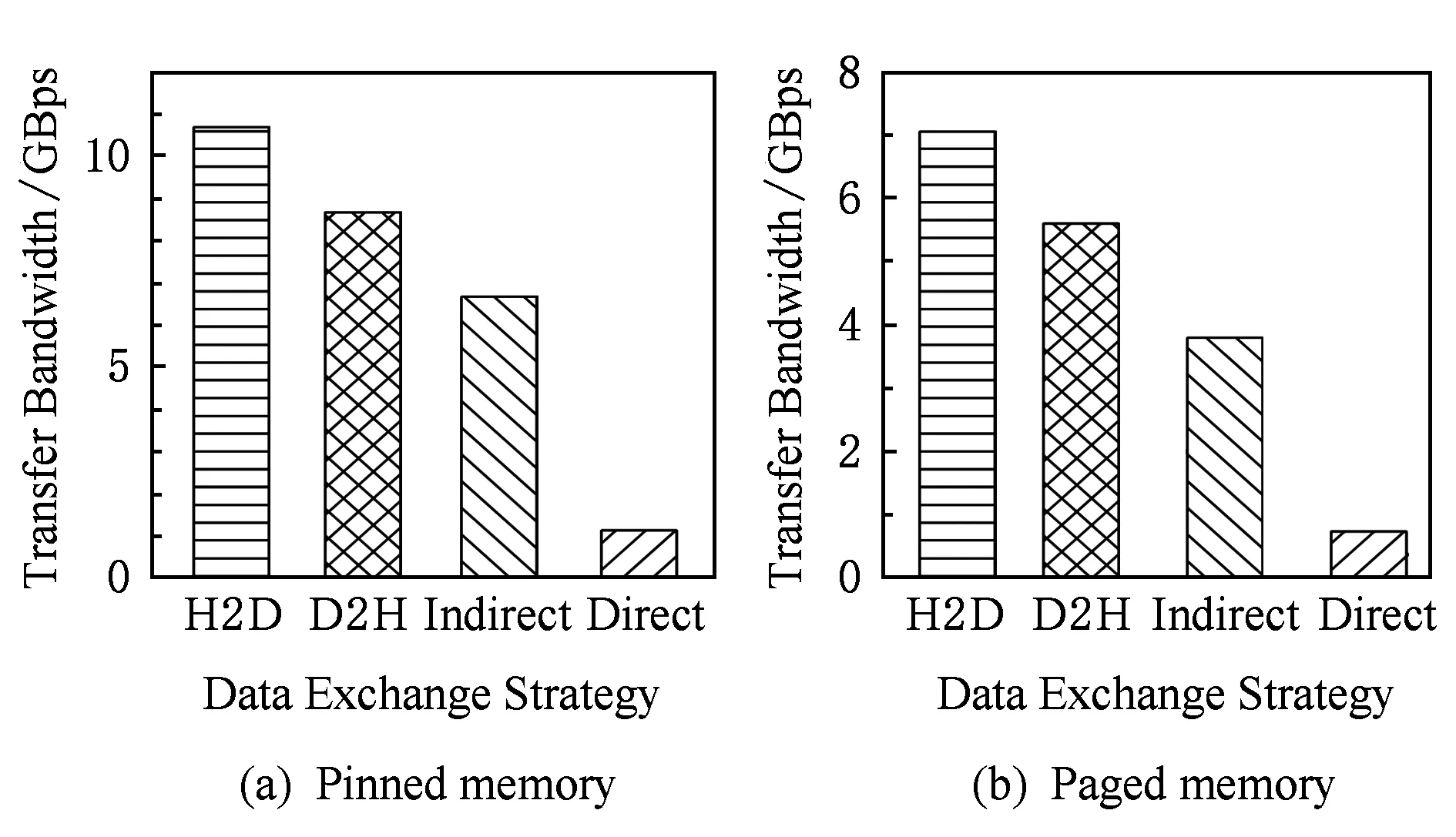
3.3 基于双层滑动窗口的异步数据传输和计算
3.4 GFlow实现细节
4 实验与结果
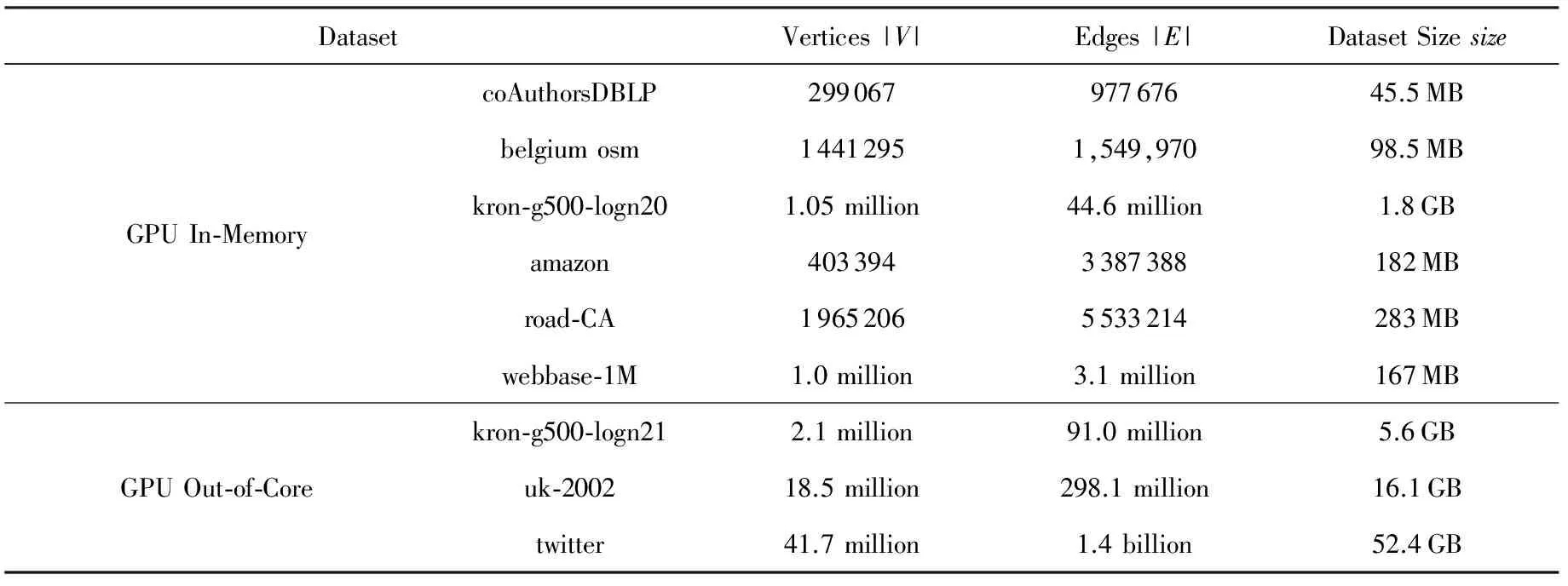
4.1 数据集
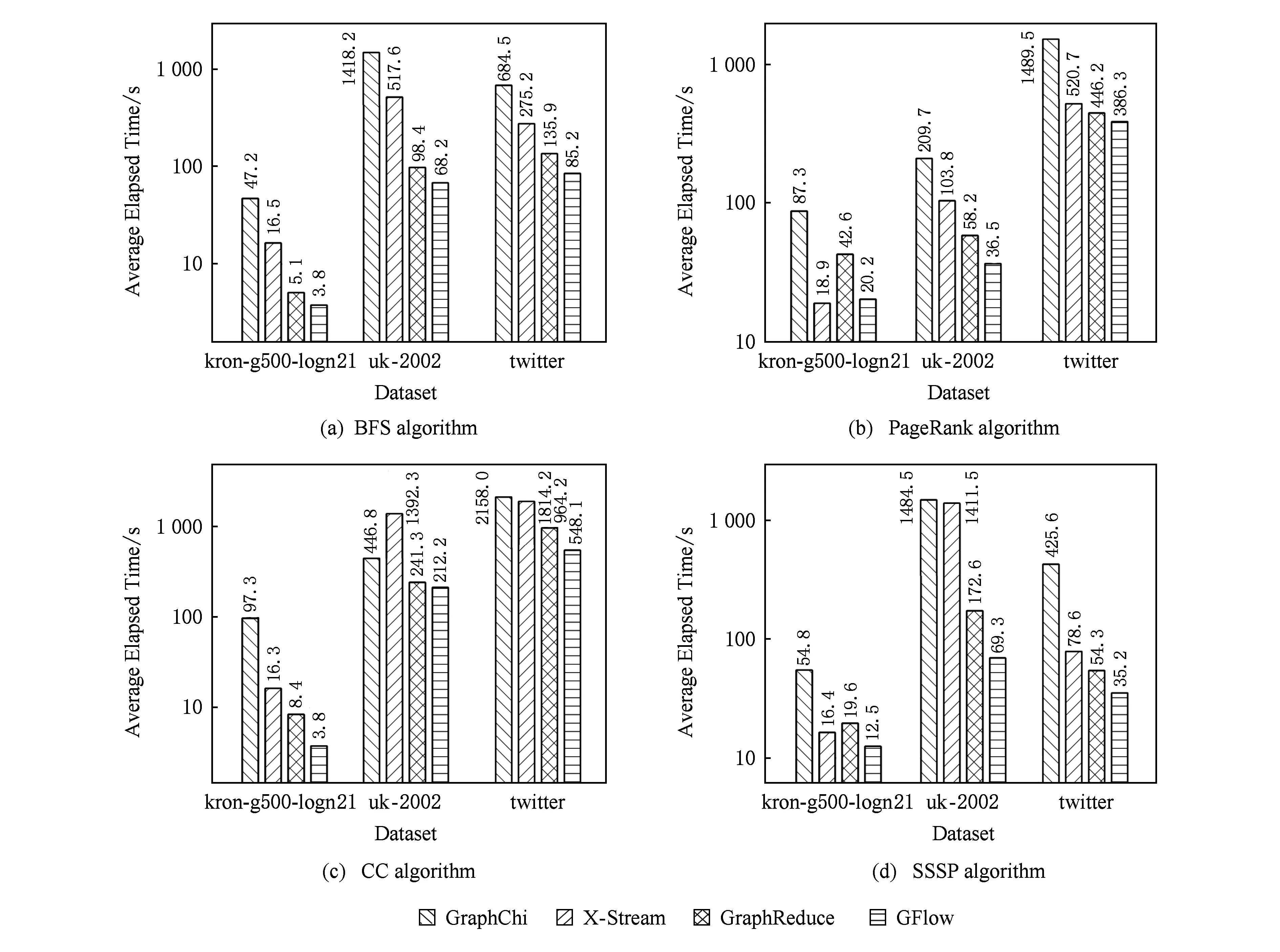
4.2 实验和结果

5 总 结
