基于语义分割的增强现实图像配准技术
2018-02-28卞贤掌费海平李世强
卞贤掌 费海平 李世强


摘要
增强现实(AR)通过分析场景特征,将计算机生成的几何信息通过视觉融合方法添加到真实环境中,以增强对环境的感知。其中图像配准技术是AR技术的核心问题之一,即在三维环境中估计视觉传感器的姿态并理解场景中的对象。近年来,计算机视觉领域取得了巨大的进步,但是AR系统在三维场景中基于自然特征点的配准技术仍然是一个严重的挑战。由于不稳定因素的影响,在三维场景中精确计算移动相机的姿态还存在较大的困难,如图像噪声,光照变化和复杂的背景图案。因此,设计一种稳定、可靠、高效的场景识别算法仍然是一项非常具有挑战性的工作。本文提出了一种结合视觉同步定位与地图构建(SLAM)和基于深度卷积神经网络(语义分割)的语义分割算法来提高AR图像配准性能。基于语义分割的语义分割是一种计算量较大的预测任务,其目的是在应用AR图像配准时预测图像中每个像素的类别,并能够缩小两帧之间特征点的搜索范围,从而提高系统的稳定性。实验结果表明,语义分割的场景信息将大幅提高AR图像配准技术的性能。
【关键词】语义分割 SLAM 深度学习 增强现实
1 介绍
增强现实技术(AR)是一种新型的人机交互技术,它利用计算机系统提供信息来增强人们对真实环境的感知。真实场景将叠加计算机生成的虚拟场景、对象或系统信息,实现对现实的增强。AR技术强调现有虚拟世界与虚拟世界的融合,强调真实对象与虚拟对象的共存与互补。其中图像配准是AR技术的关键内容之一。
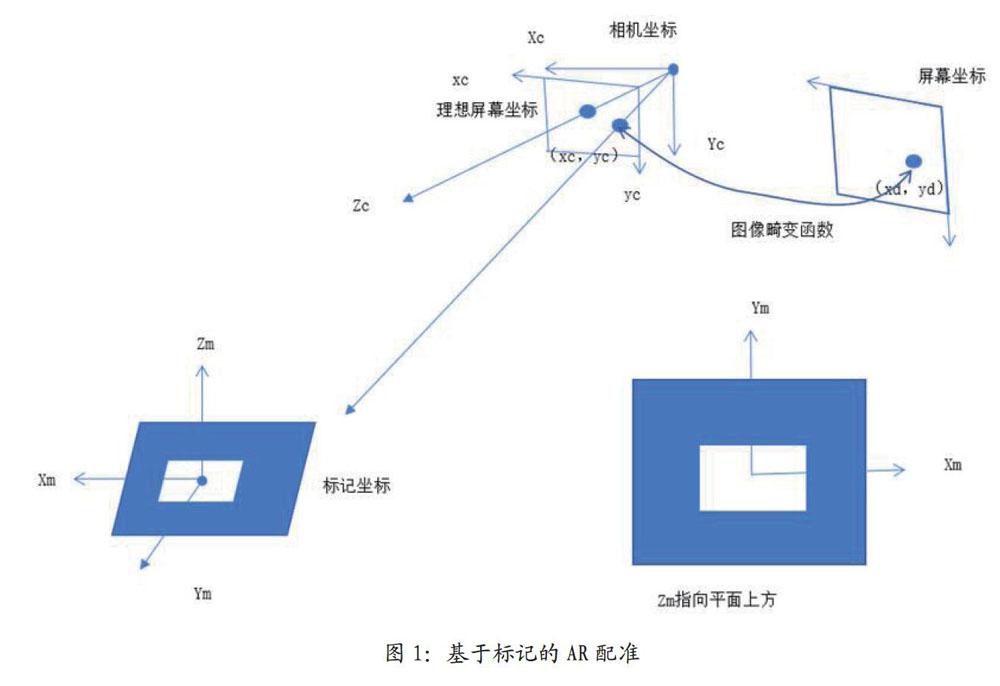
如图1所示,目前大多数川之应用都是通过相机识别已知的标记来计算三维配准的空间位置,将虚拟模型叠加在真实场景中。然而,一般在行业应用中不允许使用标记,因此使用自然特征点进行三维配准是AR应用的必然趋势。
目前,基于自然特征点的三维配准技术主要采用视觉同步定位与地图构建(SLAM)算法[1][2]。图2是视觉SLAM的示意图。利用机器视觉提取图像特征点,计算描述符和匹配特征点。相机捕捉相邻帧的连续视频序列并匹配关键点,并根据相机姿态的匹配结果,最终实现AR的3D配准。
然而,基于自然特征点的三维配准算法目前还不成熟。很容易匹配错误的特征点,从而限制了AR应用的推广。造成不匹配的主要原因是场景中有很多特征点,并且有很多相似的特征,这时当相机采集图像并匹配像素点时,就很容易混淆。本文研究了一种基于语义分割的强鲁棒场景感知技术,在对自然特征点进行匹配的同时对匹配区域进行限制。首先将相机拍摄的场景进行语义分割,即根据对象本身的含义将各阶段的对象进行分割。当对三维配准的自然特征进行匹配时,相邻帧的匹配结果仅限于同一对象的像素区域。
如图3所示,当相邻帧特征点匹配,桌子和椅子分别对应,如果匹配特征点是放在桌子上,其余的是在椅子上,我们可以判断哪些是错误匹配点并删除它们,这将提高自然特征点匹配精度。
2 相关研究
基于自然特征点的AR尚处于初始阶段,大多数基于自然特征点的AR应用配准都使用了视觉SLAM算法。Castle等人[3]的作品是最早将物体识别和单眼关键帧与SLAM相结合的作品之一。在检测到两帧图像中的物体后,他们在地图上计算出物体的位置。但与我们的方法不同,它们只关注点的几何意义,对AR三维配准的语义信息和优化不感兴趣。
Bao等人[4]是第一个从运动(SSFM)中应用语义结构的研究员。SLAM执行视频流使得点云和关键帧的映射逐渐递增,而SSFM可以同时处理所有帧,SSFM的重构与识别是分离与独立的,SSFM使用边框搜索对象并专注于重建。
Fioraio等人[5]展示了一个新的SLAM系统,该系统将3D對象添加到地图中,并通过调整来优化它们的姿态。他们建立了含有7个对象的数据库来描述这些对象,这些对象采用RGB-D摄像机在几个尺度上获得三维特征,并为每个尺度创建了独立的索引。通过寻找3D到3D的对应关系,实现了目标识别,并采用RANSAC算法进行滤波。虽然它们可以生成房间大小的地图,但是它们的应用程序不会实时运行。
Salas-Moreno等人[6]提出了一种结合了RGB-D地图重建和目标识别的新型视觉SLAM系统。他们用KinectFusion预建对象数据库,用点来描述对象的几何形状。这些点都由哈希表索引,并通过计算hough投票来标识。但它对数百个对象的可扩展性尚不清楚。
Abhishek Anand等人[7]提出了一种通过检测点云来获取语义对象的方法。他们训练相应对象的特征点,并匹配新帧的几何信息。Liefeng Bo等人[8]提出了一种利用特征点与RGB-D信息匹配来检测目标的方法。DanielMaier等人[9]利用NAO机器人携带AsusXtion Pro实时传感器,实现了机器人在3D环境下的定位和障碍物识别,重建了3D点云环境,但缺乏场景的语义信息。
为了理解场景,语义分割起着至关重要的作用,引起了越来越多研究者的兴趣[10-13]。在现有的方法中,卷积神经网络(neural network,CNN)在利用RGB图像进行语义分割方面具有很大的优势。典型的CNN,称为全卷积神经网络(FCN),在过去几年中已经取得了重要的进展。文献[14]采用以不同层间融合为代表的编码器式FCNs,大大提高了预测精度的密度。为了在不丢失分辨率的情况下扩展接收域,并在多个分割任务中获得更好的性能,扩展卷积算子取代了码译码器体系结构。尽管做了很多努力去改进,但效果仍然不令人满意,尤其是在物体的边界上。为了解决这个问题,研究者们开始将基于全连通条件随机场(allconnectedconditions random field,CRFs)的RGB模型与CNN相结合,并进行了改进[15][16]。然而,这些方法很难应用于室内环境中颜色相近的物体。
3 系统设计
在本节中,我们将从两个部分介绍我们的方法,视觉SLAM和语义分割。图4是这个系统的简图。本文关注SLAM和语义分割,而不是g2o库的优化。AR的图像配准主要分为语义分割和视觉slam两部分。
3.1 视觉SLAM
可以使用类似于depth camera Kinect的微软Hololens进行图像采集,得到每个像素的RGB和depth值。我们假设坐标系如图5所示。
如图5所示,o-xyz是图像的坐标,o-xyz是摄像机的坐标。假设图中的点为(u,v),对应的3D点为(x,y,z),则它们的坐标变换如式(1)。
首先,我们得到地图的深度数据来代替Z,计算出x和y,其中f代表焦距,c代表中心点。然后,当我们得到图像中每个点的位置时,由于相邻帧之间的差异,我们可以计算出相机的位移和旋转。
在图6中,很容易看出这两个数字已经转向了一个特定的角度。但它会转多少度呢?这个问题被称为相机相对姿态估计。经典的算法是迭代最近点(ICP)。该算法需要两个图像的特征点。我们使用OpenCV进行特征点匹配。这样就可以用PnP算法预测摄像机的姿态。如式(2)所示。
R是摄像机的姿态,C是摄像机的标定矩阵。R是连续变化值,C是稳定常数。一般情况下,只要有四组匹配点,就可以计算出模型。图7为本次实验的图片,结果显示相邻两帧检测到的特征点有317个,出现大量误匹配特征点。
理论上,只要不断地比较新帧和旧帧,就可以解决定位问题。然后,把这些关键点放在一起,就可以生成地图。当然,如果slam如此简单,那就不值得学习超过30年。这主要是由于相邻帧之间有大量相似的特征点,噪声处理非常复杂,导致了不匹配。因此,我们提出了一种优化匹配误差的方法。
3.2 语义分割
本方法需要图像的语义信息的目的是当相邻的帧特征点匹配时,合格的匹配点在同一个像素区域,根据语义分割信息进行筛选。语义分割主要采用全卷积神经网络。全卷积神经网络输入一个图像得到与原始相同大小的输出图像,输出图像具有像素到像素的映射,这是一个像素级的识别,输出图像中每个像素的输入图像在原始图像上都有相应的标记,表示什么对象最有可能是对象或类别。
Jiang[17]提出了一个RGB-D FCN体系结构(DFCN)来生成每个像素上每个类的一元可能性的响应。如图8所示,DFCN部分主要有两个模块:
(1)三个向下样本池的卷积层,用于特征提取和深度融合;
(2)用于上下文推理和稠密预测的膨胀卷积层。
它使用了16层的VGG net第一层 Conv1到Conv4作为基本框架。该基本结构适用于RGB通道和深度通道的特征提取。在网络的两个分支的每次池化之前都将它们与元素求和。然后,在主分支的每个池化层之前添加融合层。为了防止函数映射的进一步减少,VGG-16中的第4池化层被替换为一次最大池化,而第五池化层被替换为一次最大池化和一次平均池化。为了使两个分支中的值兼容并更易于训练,它对深度通道进行了规范化,深度通道的初始范围从0到65535到相同的彩色图像范围从0到255。
4 实验评价
在我们的设计中,利用语义分割的输出来限定两个视频帧之间的匹配点。具体来说,我们将这两种技术的结合定义为式(3)。p和Q是连续帧图像m和n中的特征点,R和t是旋转矩阵和位移向量,PRGB-m和QRGB-n是三个通道在语义分割图对应特征点上的RGB值。
我们使用开放数据集SUN RGBD进行测试。它包含NYUv2图像及其像素级语义注释的数据。在TensorFlow框架中实现了DFCN-DCRF架构,并使用随机梯度下降(SGD)进行端到端训练。如图9所示,左边的RGB,深度在中间和右边的语义分割和不同颜色代表了不同场景的对象。可见,目前显著的目标分割效果是理想的。然而,小对象的分割并不理想
假设有两个相邻的帧图像F1、F2和两组对应的特征点,如式(4)所示。
我们的目标是算出位移矢量的旋转矩阵R和t,如式(5)所示。
然而,在现实中,由于误差的存在,不可能得到等号,所以我们通过最小化误差来求解,如式(6)所示。
这个问题可以用经典的ICP算法来解决。其核心是奇异值分解(SVD)。我们将调用OpenCV中的函数来解决这个问题。接下来,我们将简要介绍实现过程。由于我们需要匹配两个图像并计算它们的旋转和位移关系,所以我们分三部分来做。首先,使用SIFT算法提取图像特征点,用这些关键点周围的像素计算描述子。其次,在前面的描述的基础上,使用快速最近似近邻搜索库(FLANN)进行图像特征匹配,返回DMatch结构,包括queryldx(上一个关键帧)、trainldx(下一个关键帧)、距离。然后根据经验值将距离大于最小范围4倍的点移除。最后,根据语义分割的结果,对匹配的特征点进行RGB值的过滤,保持颜色相同的特征点即相同的对象,反之亦然。最后,用PnP算法估計摄像机的姿态,得到旋转矩阵和位移向量。
5 结果评价
将视觉slam和语义分割相结合是利用视觉SLAM图像处理方法得到的特征匹配结果,判断下一帧匹配的特征点是否在同一目标像素区域内。如果不在同一区域内,则判断为不匹配并删除。图7所示,这是只使用自然特征点为特征点匹配,很明显,有很多错配的结果,一些房子的匹配点误以为伞,一些墙壁误以为路面等等。在使用过本文新的方法后如图10中,我们删除一些相邻帧处在不相同的像素区域内的匹配点,结果明显好了很多。我们的方法在一定程度上提高了匹配的准确性,提高了增强现实图像配准的准确性。
如表1所示,两帧的特征点总数为317,两个匹配特征点之间的最小距离为6.7像素。没有语义信息的匹配特征点有114个,有语义信息的匹配特征点有87个。也就是说,当我们使用语义信息时,我们可以减少21个不匹配特征点。尽管进行了筛选,但仍然存在不匹配的可能性。
本文提出了一种结合语义分割的图像配准方法来提高视觉SLAM的准确性,进而提高增强现实图像配准的准确性。图像特征匹配限制在同一物体在不同帧中的像素区域,以减少噪声对特征匹配的影响。当然,当前的语义分割在场景中不能被充分识别。本文仅在一定程度上提高了SLAM匹配精度。随着语义分割准确率的逐步提高,对阶段的感知将逐步增强,用于AR的图像配准技术将变得更加智能化。
參考文献
[1]赵洋,刘国良,田国会,罗勇,王梓任,张威,李军伟.基于深度学习的视觉SLAM综述[J].机器人,2017,39(06).
[2]江宛谕.基于深度学习的物体检测分$1[J].电子世界,2018,15(05).
[3]R.O.Castle,G.Klein and D.W,Murray,Combining monoSLAM withobject recognition for sceneaugmentation using a wearablecamera,Image Vis.Comput.28(11)(2010)1548-1556.
[4]S.Y.Bao and S.Savarese,Semanticstructure from motion,Comput.Vis.Pattern Recognit.,20-25 June 2011,Providence,R1 pp.2025-2032.
[5]N.Fioraio,G.Cerri and L.Di Stefano,Towards semanticKinectFusion,Lecture Notes inComputer Science(includingsubseries Lecture Notes in Arti cialIntelligence and Lecture Notes inBioinformatics)8157 LNCS(PART 2)(2013)299-308.
[6]R.F.Salas-Moreno,R.A.Newcombe,A.J.Davison and P.H.J.Kelly,SLAM++:Simultaneous localisation andmAPPing at the level of objects,inIEEE Int.Conf.Comput. Vis.PatternRecogni.23-28 June,Portland,OR
[7]A.Anand,H.S.Koppula,T.Joachimsand A. Saxena,Contextually guidedsemantic labeling and search for 3Dpoint clouds,Int.i.Robot.Res,32(1)(2013)19-34.
[8]L.Bo,X.Ren and D.Fox,Learninghierarchical sparse features forRGB-(D)object recognition,Int.J.Robot.Res.33(4)(2014)581-599.
[9]D.Maier,A.Hornung and M.Bennewitz,Real-time navigationin 3d environments based on depthcamera data,in 2012 12th IEEE-RASInt.Conf.Humanoid Robots(Humanoids2012),2012,pp.692-697.
[10]梁明杰,闵华清,罗荣华.基于图优化的同时定位与地图创建综述[J].机器人,2013,35(04):500-512.
[11]王浩.基于视觉的行人检测技术研究[D].辽宁工业大学,2018.
[12]严超华.深度语义同事定位与建图[D].浙江大学,2018.
[13]付梦印,吕宪伟,刘形,杨毅,李星河,李玉.基于RGB-D数据的实时SLAM算法[J].机器人,2015.
[14]V.Badrinarayanan,A.Kendall and R.Cipolla,Segnet:A deep convolutionalencoderdecoder architecture forscene segmentation,IEEE Trans.Pattern Anal.Mach.Intell.39(12)(2017)2481-2495.
[15]L.-C.Chen,G.Papandreou,I.Kokkinos,K.Murphy and A.L.Yuille,Deeplab:Semantic image segmentationwith deep convolutional nets,atrousconvolution,and fully connectedcrfs,arXiv:1606.00915.
[16]J.Dai,K.He and J.Sun,Boxsup:Exploiting bounding boxes tosupervise convolutional networks forsemantic segmentation,in Proc.IEEEInt.Conf.Comput.Via.2015,pp.1635-1643.
[17]J. Jiang,Z. Zhang,Y. Huang andL.Zheng,Incorporating depth intoboth CNN and CRF for indoor semanticsegmentation,arXiv:1705.07383.
