基于Minibatch-kMeans和XGBoost算法的大型场所WLAN室内定位的方法
2018-02-14李斌张金焕封靖川
李斌 张金焕 封靖川


摘要:基于RSS的WLAN指纹定位算法,针对大型场所的室内定位数据维数高,计算量大,定位精度不高的问题,本文提出一种基于先聚类再分类的方法.本文用Minibatch-kMeans先聚类分区定位,然后采用XGBoost分类算法在子区域精确定位,解决了大型场所室内定位数据维数高,运算速度慢的问题,并提高了定位的精度。本文提出的算法具有很大的应用价值和应用前景。
关键词:WLAN室内定位; Minibatch-kMeans;XGBoost;数据降维
中图分类号:TP212 文献标识码:A 文章编号:1007-9416(2018)10-0000-00
越来越多的移动互联网应用希望可以获得用户的位置信息来对用户提供更智能更精确的服务,目前相当成熟的GPS技术仅仅限于用于室外。基于802.1lb/g/n协议的无线局域网被广泛部署于全世界不用环境,如商场、写字楼、机场大厅等,几乎覆盖了绝大多数人类活动的室内环境。因此基于WiFi信号的室内定位成为目前十分热门和前景广阔的研究方向。目前基于WiFi信号的定位定位方法中,大致可以分为几何测距法和位置指纹法。由于位置指纹法无需提前获取无线WiFi接入点的位置和定位精度高,因此成为目前更热门的定位方法。
但是在实际应用过程中,特别是针对于大型场所,位置指纹法仍然存在如下两个挑战:
(1)需要参考的AP(无线WiFi接入点)越来越多,如某大型商场可以检测到10000个AP,因此位置指纹库数据维数高,导致计算和存储开销十分巨大。
(2)如何研发出性能更好的匹配算法,取得更高的定位准确率。因此,为了解决这两个挑战,本文提出一种基于结合MiniBatch-kMeans聚类和XGBoost分类算法的定位算法。
1 国内外研究现状
常用的指纹定位匹配算法有神经网络法、KNN法,加权K近邻法等。这些算法都是基于RSS进行指纹的匹配或映射得到最终的定位位置。
1.1 KNN(K 邻近法)算法
在KNN相似度匹配时,选取欧式距离最小的前K个点,将K个点的几何质心作为定位位置的估计。2000年微软研究院P.Bahl等人提出RADAR定位系统就是应用的KNN算法。
1.2 WKNN算法
WKNN法是KNN法的进一步改进,与KNN匹配算法相比.最大的不同在于选择出欧式距离最小的前K个点后,按照每个参考点对定位点的贡献程度,给每个参考点一个权值,最后将K个点加权质心作为定位的估计位置。
1.3 深度学习法
深度学习的概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。Gibran Felix等人应用深度学习的方法来处理复杂环境中室内定位的问题, 提高了算法的泛化能力,得到了较高的准确率。
2方法
2.1 MiniBatch-kMeans先聚类分区
本文采用Mini-BatchKMeans聚类算法法来对数据进行分区降维处理。我们发现很多大型场所内的一定区域范围内,只需部分AP即可实现定位,大部分AP在该区域内获取不到RSS信息,所以我们可以先对大型场所进行分区,剔除对该区域无用的AP,从而达到降维的效果。本文采用Mini-BatchKMeans的方法进行自动聚类分区。
算法在两个主要步骤之间迭代。第一步,从数据集中随机抽取b个样本,形成一个小批量,然后将这些分配给最近的质心。在第二步中,质心被更新。与K-Means相反,这是在每个样本的基础上完成的。对于小批量中的每个样品,指定的质心通过将样品的流动平均值和先前分配给该质心的所有样品进行更新。这具有降低质心随时间变化的速率的效果。执行这些步骤直到达到收敛或预定次数的迭代。
2.2 XGBoost再分类
完成了聚类算法区域划分后,就可以对于每个子区域用分类方法进行训练。运用XGBoost作为我们的分类器。XGBoost是一个端到端的可扩展算法系统,XGBoost就是基于GDBT,并对GDBT做了如下改进:(1)损失函数从平方损失推广到二阶可导的损失。GDBT拟合残差可以逼近到真值,是因为使用了平方损失作为损失函数。XGBoost的方法是,将损失函数做泰勒展开到第二阶,使用前两阶作为改进的残差。(2)加入了正则化项在决策树中,模型复杂度体现在树的深度上。XGBoost使用了一种替代指标,即叶子节点的个数来表示模型的复杂度。并通过正则化来限制模型的复杂度。(3)支持列抽样。列抽样是指,训练每棵树时,是从特征抽取一部分来训练这棵树,而不是使用所有特征。
XGBoost分類过程如下:步骤1:导入RSS训练数据进行训练,根据训练数据的特点,设置模型初始参数设置如:迭代数次、树的最大深度、损失函数等。步骤2:用训练数据训练好的 XGBoost 模型,导入测试集,计算出测试集的结果。步骤3:统计测试集数据预测结果,若预测结果不理想,对XGBoost参数调整,重复1步,第2步,直到达到一定的预测准确率。
2.3 定位阶段算法
XGBoost模型训练好后,就对数据进行预测运算,先进行聚类分区预测,得到分区后,在该区域内做XGBoost再分类预测,最终得到预测结果,定位预测阶段的算法流程如下:
输入:RSS指纹库 ?? = {??1,??2,...,????,...,????},测试集RSS信息T = {??1,??2,...,????,...,??w}。
输出:测试集预测结果
(1)For k=mink->maxk do #枚舉区域个数;
(2)MiniBatchKmeans(聚类个数=K,训练集T) #聚类训练;
(3)为每个区域建立RSS指纹库;
(4)MiniBatchKmeans .Predict(T) #聚类预测每条测试集所属区域;
(5)XGboost.predict(Ti)#预测测试集位置结果;
(6)统计准确率,比较每次的预测率,特征维数,运算时间找到最佳K的取值。
2.4 定位技术总流程
综上所述,本文室内方法分为离线训练阶段和在线定位阶段,定位技术与方法的总流程如图1所示。
3实验与评价
3.1实验环境和数据
本实验的数据集来源是来自阿里天池大数据平台,数据集采集了两个月20多个商场,平均每个商场近90个商铺的RSS指纹数据,实验选取4个商场的数据进行实验。
3.2 数据预处理
(1)去除无用AP:由于数据集存在大量的移动热点,我们通过筛选出现频率大于5次并且出现天数大于一天的AP作为我们参考的AP。(2)归一化处理:由于收集到的RSS数据分布在[-110,0]之间,不利于聚类和分类算法的收敛,我们对WiFi信号数据进行归一化处理。
3.3 实验结果比较评估
我们对不分区和分区方法在特征维数、定位准确率、运行时间三方面进行比较,如表1。
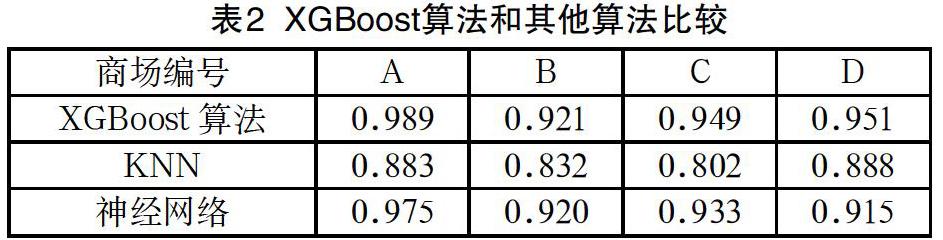
我们发现分区算法在很大程度上降低了数据维数,缩短了运行的时间,并且仍然能保持较高的准确率。将分类算法和KNN、神经网络算法进行比较,如表2所示我们发现我们的算法准确率都在其他算法之上。
4结语
本文针对基于RSS的WLAN室内定位在大型场所中的问题与挑战,提出了先聚类分区再分类定位的方法,在分区阶段使用Minibatch-kMeans聚类算法对数据进行了有效的降维,节省了约90%的运算时间;在分类定位阶段首次使用XGBoost算法进行计算,并和KNN、神经网络算法进行比较,XGBoost算法在准确率上有更优的表现。
参考文献
[1]席瑞,李玉军,侯孟书.室内定位方法综述[J].计算机科学,2016,43(4):1-6+32.
[2]锐,钟榜,朱祖礼,马乐,姚金飞.室内定位技术及应用综述[J].电子科技,2014,27(03):154-157.
[3]Chen T, He T, Benesty M. Xgboost: extreme gradient boosting[J]. R package version 0.4-2,2015: 1-4.
WLAN Indoor Localization Method with Minibatch-KMeans and XGBoost
LI Bin,ZHANG Jin-huan,FENH Jing-chuan
(Central South University, Changsha Hunan 410000)
Abstract:Based on the WLAN fingerprint localization algorithm , this paper proposes a method based on pre-cluster classification algorithm , which is implemented by Minibatch-KMeans clustering and XGBoost classification algorithm. It solve the problem of large-scale data dimension ,problem of slow operation speed and improved positioning accuracy. The algorithm proposed in this paper has great application value and prospects.
Key words:WLAN fingerprint localization;Minibatch-KMeans;XGBoost;Dimensionality reduction
