基于ROSE和C5.0算法的打鼾者OSAHS初筛模型
2018-02-07杜国栋吕云辉邵党国
杜国栋,吕云辉,马 磊,相 艳,邵党国,雷 强,胡 蓉
1.昆明理工大学 信息工程与自动化学院,昆明 650500
2.云南省第一人民医院 呼吸科,昆明 650032
1 引言
阻塞性睡眠呼吸暂停低通气综合征(Obstructive Sleep Apnea Hypopnea Syndrome,OSAHS)以睡眠期紧随打鼾后发生的反复呼吸暂停、低通气及间歇性低氧为特征[1],流行病学调查结果显示,中国人群OSAHS的发病率约为4%[2]。多导睡眠检测仪(Polysomnography,PSG)诊断是目前OSAHS确诊的金标准,但由于检测费用过高,给患者带来的经济负担过重,因此使用简单的初筛方法变得越来越重要。
为解决上述问题,国内外学者进行了不同的实验研究。Peruvemba等[3]使用颈围对打鼾者进行OSAHS筛查,结果表明该模型筛查效果较好。Lisa等[4]通过回顾性研究发现颈围和腰围是预测OSAHS的重要指标,但是这些测量学参数不足以预测病情严重程度。潘凤锦等[5]对广西地区中年打鼾者使用颈围、BMI、Epworth嗜睡量表评分三个参数组合进行OSAHS患者筛查,结果表明在广西地区使用三参数对OSAHS患者进行筛查具有较高的诊断价值。Karamanli[6]等使用性别、年龄、BMI等参数基于人工神经网络构建了OSAHS诊断的预测模型,模型的预测精度较好。因此建立一套由常见症状、问卷调查结果和测量指标结合的OSAHS预测模型是目前研究的重点[7]。
本文主要是从机器学习的方法学角度寻找通过人体测量学指标筛查打鼾者患OSAHS的标准,但由于医疗信息系统中保存的大部分为OSAHS患者的数据,使用分类预测方法虽然模型的总体准确率较高,但是对于少类样本的预测正确率极低,这种模型并不能提供任何有效信息。这是由于目前大部分的分类算法都是运用与假定不同类的样本比例是均衡的数据集,对于不均衡数据集需要进行数据的重构,然后再使用分类算法。因此本文首先采用ROSE算法对医疗信息系统中的数据进行平衡操作,然后对预处理后的数据使用C5.0算法进行建模。实验结果证明,使用ROSE和C5.0算法构建的模型可以有效地提高OSAHS患者的筛查效果。
2 基本概念及定义
2.1 不平衡数据处理算法
目前对不平衡数据的处理方法主要包括两种,一种是从数据层面的重构方法,另一种是算法层面的改进方法,主要包括集成学习、代价敏感学习等方法[8]。本文主要从数据重构的角度进行不平衡数据的处理。
2.1.1 数据集的重构方法
数据集的重构方法主要集中实现数据的平衡,方法包括数据的过采样、欠采样和综合采样(过采样与欠采样结合)的方法[9]。
过采样技术主要是通过增加少类样本的数量,实现数据的平衡策略。欠采样技术通过减少多类样本的数量,实现多类样本和少类样本数量上的均衡。这两种单纯从某类样本数量上采取的平衡措施,都没有从根本上解决问题。对多类样本欠采样,可能存在盲目性,导致大部分有用信息的丢失;而对少类样本的过采样,给样本增加新的信息,导致过拟合。综合采样是通过使用过采样和欠采样结合的方法,对少量样本过采样,同时对多类样本欠采样,实现数据的平衡。
2.1.2 人工数据集的合成方法
人工数据集的合成方法,简单来说就是通过人工合成数据,而不是重复原始的观测值,其本质也是一种过采样技术。
目前大部分对不平衡数据的研究都在寻找合适的解决方案,有部分软件和程序可以专门处理不平衡数据,人工合成数据集。在R语言的工作环境下,DMwR包中的smote()函数,通过少类样本之间的插值合成新平衡数据集;caret包提供了downSample()和upSample()两个函数通过随机抽样来处理不平衡数据;ROSE包基于ROSE算法提供了rose()函数为二分类不平衡数据集问题提供标准和更精确的解决方案。
2.1.3 ROSE算法
ROSE是Random Over Sampling Examples的英文缩写,即随机过采样技术。该算法是2014年Menardi和Torelli提出[10],专门用来处理二分类不平衡数据问题,同时也提供了传统的平衡措施如过采样、欠采样及过采样及欠采样结合的方法。ROSE算法的核心思想[11]是:假设有数据集Tn=(xi,yi),i=1,2,…,n,其中n为数据集的大小,xi为具有随机概率密度函数f(x)的数据子集,yi为类标签代表少类样本和多类样本。合成样本的步骤如
下:从数据集c中选择y*=yj,使得yi=y*的概率为,从xi数据子集中选择概率分布KHj的矩阵Hj中的样本x*。然后基于平滑自助法和核方法,将样本x*从低维特征空间映射到高维空间,在新的特征空间中选择其相邻的观测值,通过条件核密度进行估计合成新的样本。重复执行上述步骤m次,生成新的样本集T*m,其样本集大小为m。m的数值可以为原始样本数据量n或其他数值。生成的效果如图1所示。
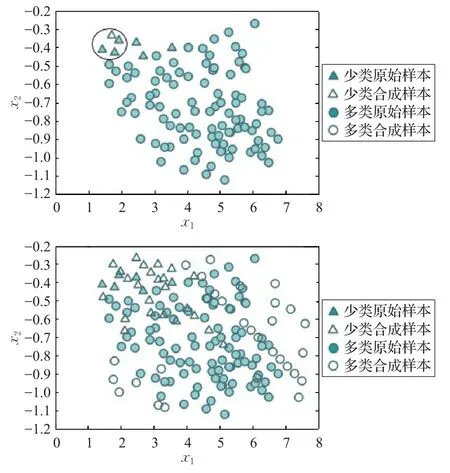
图1 ROSE算法的示意图
Menardi等[10]在提出ROSE算法时,使用UCI数据集的20个不同的公共数据集对不平衡数据处理广泛使用的SMOTE算法与ROSE算法进行测试,比较两者对不平衡数据处理的能力。为此本文也采用UCI数据集的Wine quality、Hypothyroid、Breast cancer、Cylinder bands和Credit screening这五个数据集进行验证,如表1所示ROSE算法在不平衡数据处理能力上显著优于SMOTE算法,并且平衡后的数据比原数据对分类器的划分效果有显著提升。所以本文基于医疗信息系统的不平衡数据进行OSAHS患者筛查模型构建,选用ROSE算法进行数据平衡。
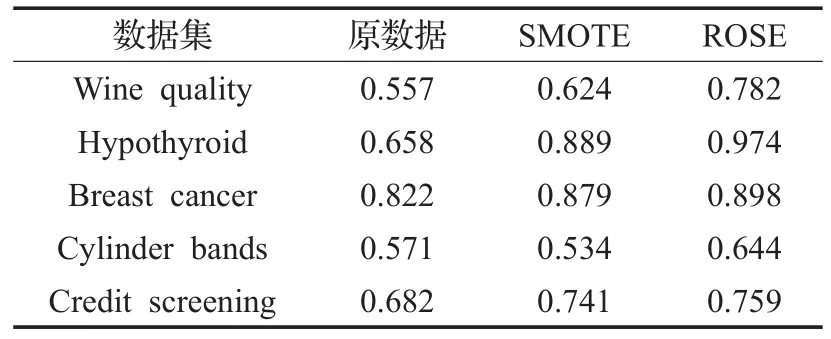
表1 使用SMOTE和ROSE算法进行平衡数据的AUC值对比
2.2 C5.0决策树算法
决策树的一个重要任务是为了从数据中发现所蕴含的知识信息,因此决策树可以使用不熟悉的数据集合,并从中提取出一系列规则。使用决策树进行诊断,其预测结果往往可以优于当前领域具有几十年工作经验的人类专家[12-13]。一个决策树能够方便地转化为若干分类规则,可以根据分类规则直观地对未知类别的样本进行预测。不同的决策树采用的技术不同,但其基本思想都是通过将训练集划分为较纯的子集,以递归的方式建立决策树。目前已经有很多成熟而有效的决策树学习算法,如ID3、C4.5、C5.0、CART、Random Forest等。C5.0算法是由澳大利亚悉尼大学Ross Quinlan教授为改进之前的C4.5算法开发的新版本的决策树算法。目前该算法已经成为了生成决策树的行业标准,因为它适用于大多数类型的问题,而且可以直接使用。与其他的分类算法相比较,其建立的决策树表现得与其他先进的模型几乎一样,并且更容易理解和部署。
3 打鼾者OSAHS初筛模型的构建
目前医疗信息系统收集的数据大部分为就诊的患者数据,仅存有少部分的疑似患者。如果仅对这种不平衡数据进行划分决策树,虽然得到的模型的准确率极高,但是这种忽略其他类的数据对一类数据预测得到的结果会产生较大的偏倚。针对这一问题,可以通过使用ROSE算法对不平衡数据进行平衡,然后再进行构建初筛模型。
3.1 数据预处理
3.1.1 异常值处理
医学数据在收集的过程中,很容易会出现误填,如将患者的性别用0和1表示,在数据录入时输入其他的数值,会使得最后的分析结果出现较大的误差。目前常用的处理方法包括利用中值、均数填充或者删除该条记录[14]。由于本文采用的数据集数据较大,因此采用通过绘制箱线图,寻找到异常值,然后直接删除含有异常值的数据记录。
3.1.2 缺失值处理
数据存在缺失值是个非常棘手的问题,有很多文献[15-16]都致力于解决这个问题。收集到的数据都是耗费人力财力收集的,删掉或者重新获取都是不可取的,必须采用一些方法解决。因此本文采用多重插补的方法对数据集中少量的样本数据进行填充,但是这种插补方法与实际值之间还是存在一定的误差。
使用如下命令,进行缺失值的插补:

其中hyper为医疗信息系统中的患者的相关数据;imp为包含m个插补数据集的列表对象,m默认为5;analysis是一个表达式对象,用来设定应用于m个对插补数据集的统计分析方法;fit为包含m个单独统计分析结果的列表对象;pooled是一个包含m个统计分析平均结果的列表变量。
3.2 不平衡数据的处理
R语言ROSE(Random Over Sampling Example)包提供了ROSE()函数可以帮助人们基于采样和平滑自助法人工合成样本,可以对原数据更好的估计。如果没有安装ROSE包,需要使用install.packages()命令添加。
使用如下的命令,进行不平衡数据的处理:

其中hyper为医疗信息系统中的患者的相关数据,OSAHS为标识打鼾者是否诊断患病。通过人工合成样本生成的数据量与原始数据集数据量相等。
3.3 分类器的构建
3.3.1 样本的分配策略
无监督的分类,将所有的样本都作为评估样本;而有监督的分类,将样本分成训练样本和测试样本。针对有监督样本的分类,样本的分配又分为复用策略(训练样本数=测试样本数),分离策略(将样本分为两组相互独立的两组,一组作为训练样本,另一组作为评估样本),还有一种方法是留一法,即选择一个样本作为评估样本,其他数据作为训练样本。其中复用策略是一种最好的分配策略,可以获得分类器的误差下界,分离策略则是最差的方法,因为其训练样本较少,训练样本和评估样本的相关性最低,可以得到误差上界。虽然效果最差,但是本文仍采用分离策略,使用66%的样本训练数据,剩余数据作为测试数据评估分类器的性能。
使用如下命令,创建随机的训练数据集和测试数据集:

其中,data为原始数据集;runif(n)生成n个随机数的列表,n为记录的个数;order()函数返回一个数值向量,记录了随机数在原来序列的位置,根据位置信息筛选数据框中的行,保存在data_rand数据框内。train为训练数据集,test为测试数据集。
3.3.2 决策树模型构建
本文采用R语言的C50程序包实现C5.0算法训练决策树模型,其中C5.0()函数创建决策树对象。如果还没有安装C50包,使用install.packages()命令添加。
使用如下命令,构建C5.0决策树模型:

其中screening_model表示最后得到的筛查模型,train表示训练数据集,OSASH表示是否患病。
3.4 模型性能的评估
传统分类器学习算法大多数假定类别分布均衡,其性能评估方法一般采用总的识别率。对于非均衡数据,采用经典学习算法的总识别率作为评估标准会导致少类样本的识别率偏低,不能很好地反映分类器的性能。比较常用的非均衡数据分类算法的评估标准有准确率(Precision),召回率(Recall),G-mean,F-measure和ROC曲线下面积(Area Under the Curve,AUC)等[17-20]。本文采用十则交叉验证的AUC值来衡量不平衡数据的分类效果的变化。
4 实验验证
4.1 实验数据集
本文所采用的数据集来自于2006年至2012年在云南省第一人民医院(昆明理工大学附属昆华医院)呼吸科就诊的3 055例打鼾者的人体测量学数据,根据PSG诊断结果分为打鼾者(3.53%)和OSAHS(96.47%)患者两类。两类数据的具体参数指标如表2所示。
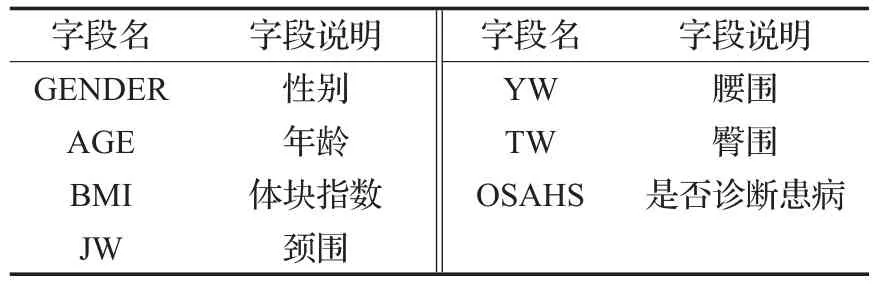
表2 数据集描述
4.2 实验结果及分析
分别对使用ROSE算法平衡前后的数据使用C5.0算法进行训练和测试。实验前后十则交叉验证的分类精评价指标如表3所示,从中可以看出采用ROSE方法平衡数据后筛查模型的预测结果较为理想,AUC值由0.505显著提高到0.722,并且该模型具有更高的分类正确率。得到的筛查模型如图2所示。
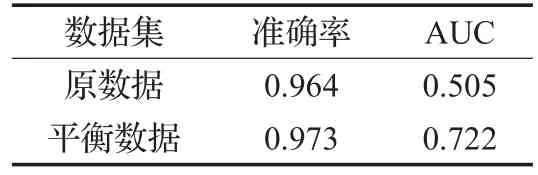
表3 实验前后评价指标
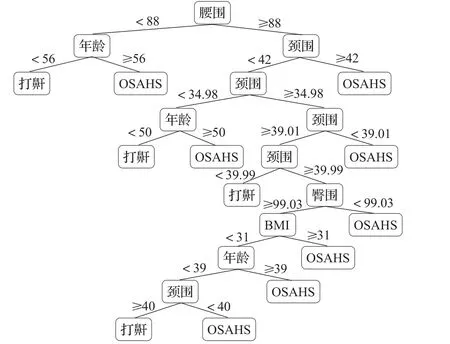
图2 ROSE和C5.0构建的OSAHS初筛模型
由实验最后得到的初筛模型,可以得到决策树生成的相应决策规则,使用这些规则对打鼾患者进行OSAHS初筛后,仍需要后续配合多导睡眠仪进行确诊。本文得到的初筛模型与其他研究[3-6]的结果比较,使用的预测参数更加全面,建立的筛查模型更加细化。
5 结束语
OSAHS是一种与睡眠相关的呼吸疾病,主要表现为睡眠打鼾并伴有呼吸暂停,可导致白天嗜睡及心脑血管等并发症,严重的影响患者的生活质量和寿命。目前虽然PSG诊断是OSAHS确诊的金标准,但由于价格昂贵,因此亟需建立一种简单的测量方法进行疑似患者的筛查。本文在临床医学研究的基础上,提出了基于人体测量学指标数据,采用ROSE和C5.0算法构建筛查模型。经实验验证,使用本文的方法进行初筛较为合理。同时本文基于真实数据研究和预测,模型预测精度较高,泛化能力较强。
虽然本文所提出的决策树模型总体分类正确率较高,但是基于现有的医疗信息数据库进行的机器学习研究,可能受到数据质量的限制,为了更进一步提高诊断结果的敏感性,还需要在下一步实验中结合流行病学研究继续探索。
[1]莫晓云,刘建红,谢宇萍,等.阻塞性睡眠呼吸暂停低通气综合征合并高血压的特点及危险因素[J].中华医学杂志,2016,96(8):605-609.
[2]Liu J,Wei C,Huang L,et al.Prevalence of signs and symptoms suggestive of obstructive sleep apnea syndrome in Guangxi,China[J].Sleep and Breathing,2014,18(2):375-382.
[3]Peruvemba H,Thazhepurayil R,Ponneduthamkuzhi J,et al.Clinical prediction of Obstructive Sleep Apnea(OSA)in a tertiary care setting[J].Journal of Clinical and Diagnostic Research,2012,6(5):835-838.
[4]Prochnow L,Zimmermann S,Penzel T.Predictors of obstructive sleep apnea:Anthropometric measurements and their significance[J].Somnologie,2016(20):113-118.
[5]潘凤锦,刘建红,谢宇萍,等.广西地区中年打鼾者简单三参数筛查OSAHS的多中心研究[J].中华医学杂志,2015,95(2):100-105.
[6]Karamanli H,Yalcinoz T,Yalcinoz M A,et al.A prediction model based on artificial neural networks for the diagnosis of obstructive sleep apnea.[J].Sleep&Breathing,2015(20):509-514.
[7]王钰彧,关建,殷善开.阻塞性睡眠呼吸暂停低通气综合征的筛查诊断研究进展[J].临床耳鼻咽喉头颈外科杂志,2016(6):505-509.
[8]欧阳源遊.基于混合采样的非平衡数据集分类研究[D].重庆:重庆大学,2014.
[9]闫欣.综合过采样和欠采样的不平衡数据集的学习研究[D].长春:东北电力大学,2016.
[10]Menardi G,Torelli N.Training and assessing classification ruleswith imbalanced data[J].Data Mining &Knowledge Discovery,2014,28(1):92-122.
[11]Lunardon N,Menardi G,Torelli N.ROSE:A package for binary imbalanced learning[J].R Journal,2014,6(1):79-89.
[12]陈绍炜,王聪,赵帅.决策树算法在电路故障诊断中的应用[J].计算机工程与应用,2013,49(12):233-236.
[13]范庚,马登武,张继军,等.基于决策树和相关向量机的智能故障诊断方法[J].计算机工程与应用,2013,49(14):267-270.
[14]李静.含异常值的抽样调查数据估计方法比较研究[D].北京:中国人民大学,2011.
[15]马福民,刘涛涛,徐安平.基于模糊加权相似度量的粗糙集数据补齐方法[J].计算机工程与应用,2016,52(9):60-66.
[16]张松兰,王鹏,徐子伟.基于统计相关的缺失值数据处理研究[J].统计与决策,2016(12):13-16.
[17]王超学,张涛,马春森.改进SVM-KNN的不平衡数据分类[J].计算机工程与应用,2016,52(4):51-55.
[18]陈斌,苏一丹,黄山.基于KM-SMOTE和随机森林的不平衡数据分类[J].计算机技术与发展,2015(9):17-21.
[19]张银蜂,郭华平,职为梅,等.一种面向不平衡数据分类的组合剪枝方法[J].计算机工程,2014,40(6):157-161.
[20]Xie Y,Liu Y,Fu Q.Imbalanced data sets classification based on SVM for sand-dust storm warning[J].Discrete Dynamics in Nature and Society,2015,2015(2):1-8.
